阳振坤:当我们在谈论金融级分布式数据库的时候,其实是在说性能的代价


在开始说正题之前,我想先说说激光照排、服务器和操作系统。
我是1965年生人,在做分布式系统和数据库的研发之前,跟着老师王选,做了十多年的激光照排,亲身经历了北大方正激光照排系统从无到有,从小到大的过程,也看到了王选老师的创新对媒体出版产业、对亿万大众的信息消费产生了多么巨大的影响。王选老师的一句话让我铭记至今:“高科技产业应实现‘顶天立地’模式。‘顶天’就是不断追求技术上的新突破;‘立地’就是把技术商品化,并大量推广应用。”这让我清楚地知道,如果要做一个好的创新,不仅要技术上牛,更要真正应用到生产和生活的实际场景中去。就像CPU的国产自主研发,我们十几年前就能做出来“狗剩”(Godson),如今更有寒武纪,但都还没有机会得到大规模商用化,这是让人扼腕叹息的事情。
所以当我们2010年前后开始做分布式数据库,也就是设计OceanBase架构的时候,一开始瞄准的目标,就是要把它做成一个通用的关系数据库产品,而不是一个仅仅在公司内部使用的产品。2017年,让我们团队最高兴的是,通过8年研发抗战,我们不仅做到了承担蚂蚁金服“双十一”全部核心业务的重压,还在6家商业银行落地,成为他们互联网金融类新业务系统的数据核心。
站在这样一个有纪念意义的时间点上顾盼今昔,我发现,虽然数据库已是一个看起来不那么性感的研发领域,但当我们看看,在企业级系统里,和数据库分不开的服务器和操作系统的演进后,就会知道,分布式数据库引发的创新变革,尤其是金融服务领域的变革,或许才刚刚开始。
当年研究分布式系统的时候,对一篇2005年Google首席工程师Luiz André Barroso发表在美国计算机学会学报上的论文印象颇深,那篇文章就叫做《The Price of Performance》,所以我这篇文章的标题也是向他致敬。在该文里,Luiz的主要观点就是表达了,Google作为当时全球最大规模计算基础架构的技术平台,需要在设计基础架构的时候,更好地平衡性能和价格,而他作为首席工程师,首先必须回答的问题就是:对于业务部门所需要的计算能力,在经济上是否能够承受?他开发出一套思路,能深入理解计算的总体成本,并且不断地寻找合适的硬件/软件设计来优化每个成本单位的性能。Luiz将Google计算基础设施的TCO(总体拥有成本)分解为四个组件:硬件成本、能源消耗、数据中心的建设及运营成本,以及软件成本。在云还没有诞生的年代,最昂贵的TCO组件是软件,Luiz将TPC-C测试中使用的系统价格进行粗略分解后发现,平均到每个CPU,操作系统和数据库引擎的成本约为4000~20000美元,如果再算上其他操作系统组件、应用和管理软件的授权费用,成本还得增加许多。性能第二大的代价是能源消耗,根据Luiz测算,Google自行组装的贴牌PC服务器,TCO的40%来自电能消耗,即使他明明知道有70%以上的CPU时间是被浪费掉的。至于硬件采购成本和IDC的运营成本,相比前两个单项,只占到10%不到的比例,都可以忽略。
所以,当我们一开始想做OceanBase,这个从架构上就和Oracle、DB2完全不一样的“分布式”数据库的时候,首先想实现的也是帮助业务部门降低TCO,尤其是在更加便宜的分布式硬件+操作系统上,用最低的代价,实现最高级别金融级数据库的性能和可用性。
这个想法在当时,被许多同行看成是异想天开,因为这和我们在大学里学过的数据库基本常识违背,分布式系统怎么可能实现CAP的要求呢?而且那个时候,大多数金融机构,包括阿里自己用的都是IOE架构,虽然当时IOE架构的并发交易处理能力已经不能满足“双十一”的需求,但胜在稳健;虽然IOE架构临时扩容收费的都是天文数字,但胜在阿里挣得更多,支付得起。所以我们要干这件事情,先不说成功的概率有多大,而是它重不重要,紧不紧急?
为了回答这些问题,我们不仅和业务部门做了两周的紧急调研,确认了这件事情的重要性,也看到了一些行业的大趋势——从2004年开始,全球每年约450-500亿美元规模的服务器市场,已经从x86+Windows/Linux与RISC&大型机+AIX/HP-UX/Solaris/Mainframe各占一半销售额,快速变换为2010年的x86占据80%以上份额,出货量更是相差两个数量级;而早在2006年,就已经有建设银行这样的国有大银行,已经在尝试“总行用主机+省行用小机”的尝试,而且表示不排斥在关键业务系统里用Linux,前提是得有成熟的、兼容性好的应用。作为互联网公司,我们更不应该落后于传统金融行业的老大哥。
所以,不管是内部要求,还是外部环境,在当时都发生了一些微妙的变化,这也给了我们一些信心,能够做出一个先满足内部业务需求,进而满足金融行业需求的数据库产品。
基于应用场景,挑战不可能
光有信心没用,还得撸起袖子加油干。正如李国杰院士所说:Database之所以难,不只是难在Data上,而是难在后面的Base上。OceanBase能做成金融级数据库,主要是做了五个关键创新。
第一点,我们做到了CAP的最佳平衡。单机数据库要做到既满足事务ACID特性,又可扩展已经非常困难了,而OceanBase则是在做三个库或者五个库的时候,要多台机器同时来做,在具备高可用、高可扩展的同时,追求数据强一致,保证事务ACID,这个是OceanBase系统里面最复杂的部分之一,也是今天其他人很难在这块领域出彩的原因。
第二点,我们重新设计了数据存储模式。数据库有两种性能,一种读,一种写,读可以缓存而写是无法缓存的,即使是固态硬盘,随机写的能力也是受到限制的。所以OceanBase在关系数据库领域首创了把写操作放到内存中,改几个字节就记录几个字节,再把日志放到硬盘上,如果出现类似电脑掉电重启的情况,只需要回放日志做恢复就可以了。因为日志在硬盘上是顺序写入,所以性能不是问题。因为不需要在硬盘上随机写,用能够随机读的廉价硬盘就可以,最终结果就是把性能提高一半以上,同时把成本又降一半。但有人会问,内存那么贵,你用来做数据库是不是太奢侈,还谈什么降低一半成本?的确,受制于内存成本和IDC机架的功耗限制,我们没有把全部写操作都放到内存里,而是采用内存与硬盘都用的折中方案,只把一些最常用的数据和最近的修改数据保存在内存里面,这样既维持了一个适当的成本,又得到一个很好的性能。
第三点,我们实现了变长数据块存储。传统数据库的块是定长块,块的大小从几个KB到十几个KB不等,并且是原地修改,如果修改后的数据总长度超过块大小,需要链接到新的块,后续对该记录的访问就会跨块,会有性能损失;如果一页剩余空间不足以存下一行,就只能空闲。而OceanBase的块大小是2MB,在块内,记录是顺序存放的,由于没有原地更新,数据紧凑存放,空间利用率会更高。还有一点就是,数据库其实也是CPU占用率很高的应用系统,它的业务在高峰期的时候,CPU是没有多少空闲的,所以只能用一些很简单的压缩算法,而OceanBase因为第二点的优势,白天不做大规模写入,到夜里再会把数据写入硬盘,可以更加充分、均衡的利用CPU和硬盘,这样做的效率比商业数据库的数据库效率要高一倍以上,而且是一次性写入,出错的几率也会降低很多。
第四点,我们用校验和的方式,做到了高一致性。蚂蚁金服和银行一样,最关键的业务就是交易系统,也就是记账和转账。作为记账系统的核心基础,OceanBase的账本不能出错。对此,我们做了个类似CRC的“校验和”机制,每天晚上对每一条数据、每一台机器进行大合并,合并完了之后,检查这个“校验和“是不是一样,如果不一样肯定有问题了。我们对“事务”也加了这个校验和,因为事务中包含的对数据表的修改也是一种数据,把这些数据每次都累计生成一个校验和,在备机回放日志的时候,一旦发现这个校验和不对,我们的系统就会报警。在新版本的OceanBase里,校验和做的更严格,会对每张表的每一行都做一个校验,每一列也做一个校验,整个表再做个校验,一旦有任何一点的不一致,就会被发现,这样的操作能让业务部门充分放心。
第五点,我们做到了数据库主库故障后数据无损(RPO=0)。单机数据库通常是一主一备,最大的问题就是没有仲裁,数据库主库要是出问题了,服务器产商和数据库提供商会不惜代价救回主库,实在救不回来了,银行要开会决策用不用备库,因为备库数据是有损的,损失要由银行自行承担,所以银行都有自己的人工对账系统用来应对这种紧急情况。OceanBase采用了Paxos协议(一种分布式一致性协议),即使用了三个都有可能出错的库,但通过多数派赢的表决的方式,对外提供稳定可靠的服务,很好地兼顾了数据一致性与服务可用性。所以,当支付宝和首批六家合作银行用了OceanBase之后,容灾演习就不再需要人工对账系统。
从支付宝到商业银行,天时地利人和
金融级分布式数据库能够在行业生产场景中真正用起来,需要天时、地利和人和。
天时,就是随着互联网,尤其是移动互联网的爆发式增长,对金融行业的在线事务并发处理能力、数据处理能力和系统弹性提出了再上一个数量级的要求。举个例子,网点最多的中国工商银行号称是“你身边的银行”,也不过几万个网点,每个网点一般10多个服务柜台,每天能服务的企业和个人客户是相对有限的,所以在那个时代,大型主机足以满足业务需求,一个分行的TPS、IOPS一般在几百,峰值一两千就够了,数据量级一般在若干GB;但到了PC网银时代,网络开户、交易和转账的需求就多了一个数量级,这个时候就有一些省级分行或者城市商业银行开始尝试小型机+Unix的方案,数据库的TPS、IOPS在三四千到一万左右,数据量上升到TB级,系统整体成本就比用大型主机便宜很多了。到了2010年之后的移动互联网大爆发时代,大型主机或小型机+Unix+传统商业数据库就都hold不住了——且不说能不能处理动辄百万、千万的并发请求,就算能完成,在传统架构上获得千万级并发处理能力、PB级数据库管理能力、一天之内系统扩容百倍并在业务高峰期后立即释放,要获得这样的性能,又该付出怎样的代价?放眼全球金融行业,我们还没有看到任何一个这样的先例。
地利,就是从淘宝到蚂蚁金服的内部环境。数据库跟手机不同,只要有一次死机就没人用了,所以超高的要求和复杂的系统都是阻碍。而OceanBase从淘宝收藏夹到承载蚂蚁金服100%业务的每一步进展,让一个新产品,从不是特别重要的应用场景开始尝试,一步步地将这个数据库做成了关键系统。而且从互联网公司做出来的产品,和传统数据库有一个特别大的有点就是性价比高,理由就是我们特别关注“性能的代价”,我们利用高性价比的PC服务器和Linux,便可实现金融级业务需求。相对于一台几十万到几百万的小型机,甚至几千万、几亿的银行总部用大型机,用5%的成本,做到了商业数据库性能。
人和方面,就是人才和人心都正当时。人才正当时,是说能做分布式系统研发、运维和调优的人才已经遍地开花,不再是很高门槛的高精尖。正如开头提到的,2005年玩好了分布式系统,有了自己的方法论和工程经验,写篇论文都是可以上ACM的;如今的互联网公司里,还有核心业务不是分布式架构的吗?那些勇于创新并尝到甜头的金融机构新业务部门里,还有不是分布式架构的吗?人心正当时,是说金融行业客户的心理需求也产生了变化,比如南京银行就是期望通过打造互金平台,将交易与消费和生活场景结合,提升用户量和活跃度,更加普惠,更加服务民生,这跟蚂蚁金服要做“助力普惠金融的科技公司“的愿景是高度一致的,所谓“独行快,众行远“,和价值观相同的同事和客户谋事,才更容易彼此成就,走得更远。
变局:谁能真的千秋万载,一统江湖?
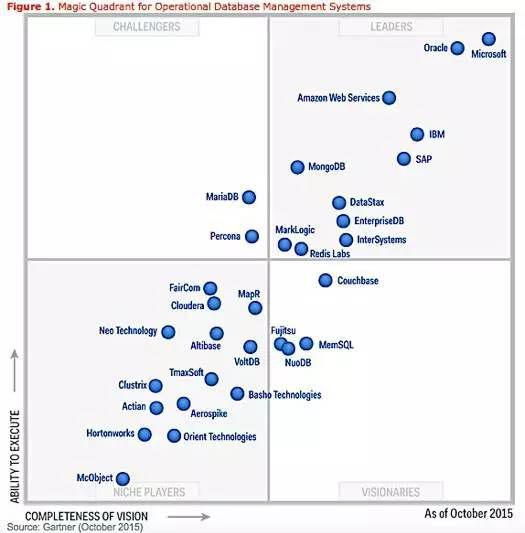
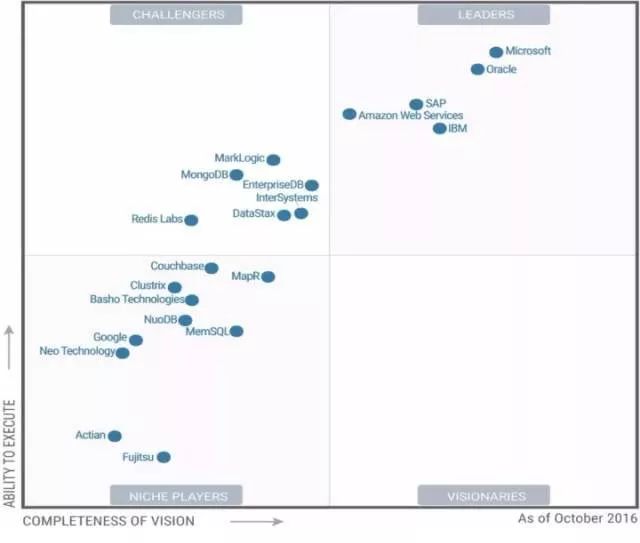
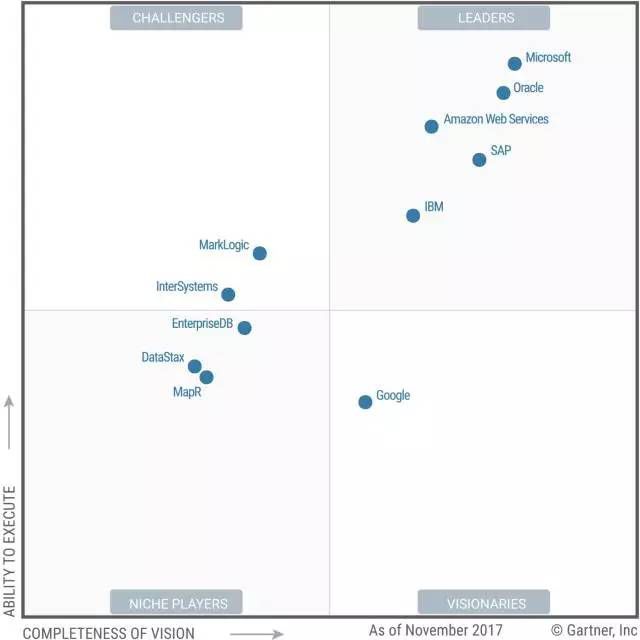
在谈论OceanBase未来的时候,我想先聊聊上面这三张图。这是Gartner的魔力象限图,对最近三年操作型数据库管理系统的分析。有意思的是,2015年收录了31家公司,其中一大堆领导者;第二年还有21个,基本上领导者就只剩下微软SQL Server,Oracle,SAP,亚马逊和IBM了,去掉了一半不赢利(死掉)的;到了2017年,只剩下11家,微软和Oracle仍然稳如磐石,亚马逊继续上升,SAP落到第四,IBM与前三名差距拉大。因为推出了Spanner,谷歌从一招鲜玩家杀入到远见者。因为不赢利,MongoDB居然都能被干掉。从上面可以看到,在数据库这样一个非常成熟的细分领域里,最近三年居然产生了如此剧烈的变化,这意味着什么?会不会像当年分布式计算和虚拟化催生了云计算一样,数据库领域也会产生类似的变化?这一现象背后的趋势,值得我们深思。
特别想说说Spanner,谷歌认为Spanner是一个具备跨数据中心、跨全球事务处理能力的数据库平台,但问题是Spanner不兼容ANSI/ISO SQL标准,导致兼容性和行业普及会成问题。其实心情很复杂,一方面,做了这么多年分布式数据库,好不容易找到一个有共鸣的Google,有他乡遇知音的感觉。但或许是Google的业务部门过于强势,数据库的设计开发应用基本是为满足自身需求,所以有上面的问题存在,如果Spanner商用前景不好,那也是很让人痛心的。
整体来说,OceanBase走的是基于互联网场景,加上金融交易数据库类型,支持标准数据库接口、标准数据库语言的标准化研发道路,也通过这些年在容灾、业务流程、零故障的表现,受到蚂蚁金服内部和各大银行的认可,我们还是有信心走得更快、更远。
最后放两张图,与同事、同行、客户共勉,但愿若干年后,经过我们的共同努力,也能达到HPC领域里联想、曙光、浪潮、华为这样的地位,成为数据库领域里的Top Tier!
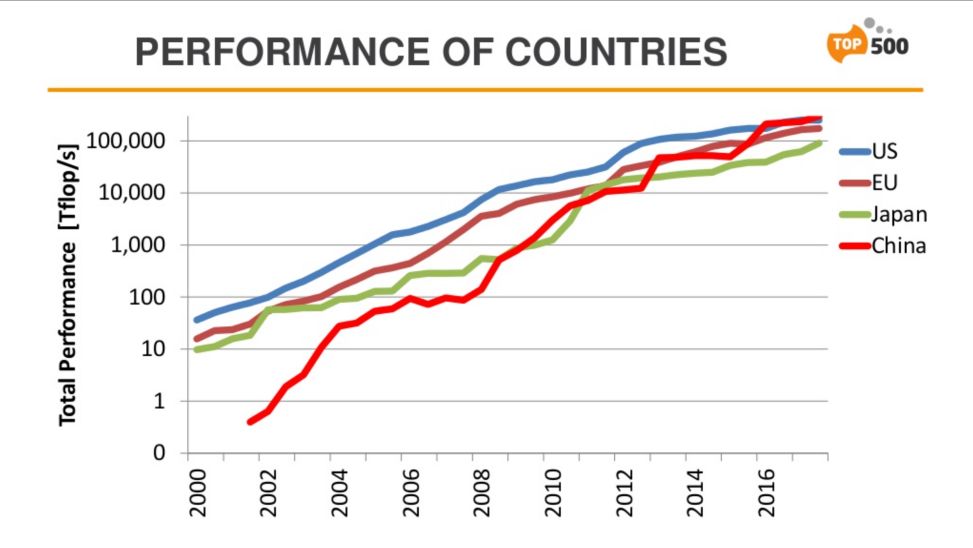
▲2000年-2017年,HPC Top500主要国家和地区的系统性能总和走势图
福利区:
想加入OceanBase团队创造不同?
蚂蚁金服OceanBase团队诚招下列岗位:解决方案架构师、分布式数据库研发、数据库平台Java研发、数据库质量专家。
请点击文末的阅读原文了解详情,立即申请!
— END —










