研究者开发的框架可以根据视频输入发现物体的动态和静态物理属性,进而推理时序物理事件以及预测未来视频帧。
![]()
人类感知和理解周围环境通常要借助于物理常识:直觉物理 (Intuitive Physics),这种常识的建立从婴儿时期就已开始,依托于对物体物理属性 (object-centric representation) 的探索和理解,比如物体的大小、形状、质量、材料、运动速度等。
对于深度神经网络而言,模型缺乏像人类一样以自监督的方式去将场景里的物体拆分表示以更好地理解场景的能力:无法将红色、绿色、黄色等属性正确地分配给所属物体,缺少属性与物体之间的对应关系,而这种理解场景的方式对于抽象常识的建立以及因果关系的发现十分重要。
![]()
通过对输入的观测分离表示场景中各个物体的静态属性,进一步借助物理事件推断物体的动态物理属性 可以赋予模型类人的物理常识,从而更好地理解场景以处理更为上层的任务:因果推理、决策、规划等。
中科院自动化所 2035 创新团队
基于不同的视角提出两种因果关系与物理属性发现框架,在视频预测、反事实预测、视频推理多个基准数据集取得优异的性能
。相关工作先后被 AAAI2022 及 ICLR2022 接收。
用于反事实预测的物理动力学解混杂(AAAI 2022)
![]()
发现潜在的因果关系是推理周围环境和预测物理世界未来状态的基础能力。基于视觉输入的反事实预测根据过去未出现的情况推断未来状态,是因果关系任务中的重要组成部分。现有研究方法缺乏对因果链的深入挖掘,致使不能够有效建模物体之间的关联并估测动力学系统中的物理属性。
对此,团队研究了物理动力学中的混杂影响因子,包括质量、摩擦系数等,建立干预变量和未来状态可能改变变量之间的关联关系,提出了一种包含全局因果关系注意力(GCRA)和混杂因子传输结构(CTS)的神经网络框架。
![]()
GCRA 寻找不同变量之间的潜在因果关系,通过捕获空域和时序信息来估计混杂因子,确保模型能够有效建模长距离跨帧物体之间的关联。CTS 以残差的方式整合和传输学习到的混杂因子,利用空序信息加强层,时序信息聚合层以及时空信息传输层来高效编码和利用混杂因子信息和物体状态信息,进而加强反事实预测的能力。
实验证明,在混杂因子真实值未知的情况下,本文的方法能够充分学习并利用混杂因子形成的约束,
在相关数据集的预测任务上取得了目前最优的性能,并可以较好地泛化到新的环境,实现良好的预测精度
。
![]()
基于物体动态特征蒸馏的场景分解与表示(ICLR 2022)
![]()
论文地址:https://openreview.net/forum?id=1iWoD04yVZU
从生成模型的角度来说,已有的一些方法可以通过 VAE 框架对简单场景中的每个物体进行解耦表示,包括物体的形状、大小、位置等静态物理属性,这种对场景中不同物体的分离并解耦的表示方式对于下游任务有着很大的促进作用,增强模型对场景的理解和推理能力。
但是,此类方法大多关注图像输入,即便是对于视频输入也要分解为对单帧图像的分别处理,由于缺乏物理事件的引入,物体的动力学属性(运动方向、速度等)无法被网络学习并编码。
团队提出物体动态特征蒸馏网络 (Object Dynamic Distillation Network,ODDN)。
![]()
基于 VAE 架构的编码器分解每帧图像的场景为多个物体,并将物体的静态物理属性解耦表示,以解码器重建为原图作为监督;
通过 Transformer 的架构自适应匹配不同帧的物体静态物理表示,并根据这个不同帧物体表示的差 异性通过一个前向网络蒸馏出物体的动态特征;
结合编码器编码的物体静态物理属性以及蒸馏网络蒸馏得到的物体动态物理属性,显式的建模物体对之间的交互作用以更新每个物体的动态表示。每个物体更新后的动态表示和静态表示预测下一帧的物体状态并解码为下一帧图像。
以动态属性作为额外的物体表示在 CLEVER 数据集 (基于物理事件推理、问答) 取得了 SOTA 的效果,表明物体的动态属性对于视频理解和推理很有帮助,这个结果也符合物理常识。
此外,ODDN 显式建模了物体间的交互,结合生成模型,赋予了模型直接预测未来视频帧的能力。团队在 CLEVRER 以及 Real Tower 数据集上做了视频预测的实验,结果表明在多物体场景 ODDN 的预测精度优于现阶段其他方法,尤其是包含物理事件 (碰撞、相互作用力) 的场景。
![]() 图 4:基于输入的两帧预测后续视频帧效果对比。
相比于 Baseline 模型,ODDN 最核心的改进是引入了的物体运动相关的线索,这不仅使得模型在其场景表征以及视频预测能力获益,还改善了其图像重建以及自监督分割的性能,主要表现在物体与物体之间分的更开,细节刻画更为精细。
图 4:基于输入的两帧预测后续视频帧效果对比。
相比于 Baseline 模型,ODDN 最核心的改进是引入了的物体运动相关的线索,这不仅使得模型在其场景表征以及视频预测能力获益,还改善了其图像重建以及自监督分割的性能,主要表现在物体与物体之间分的更开,细节刻画更为精细。
![]()
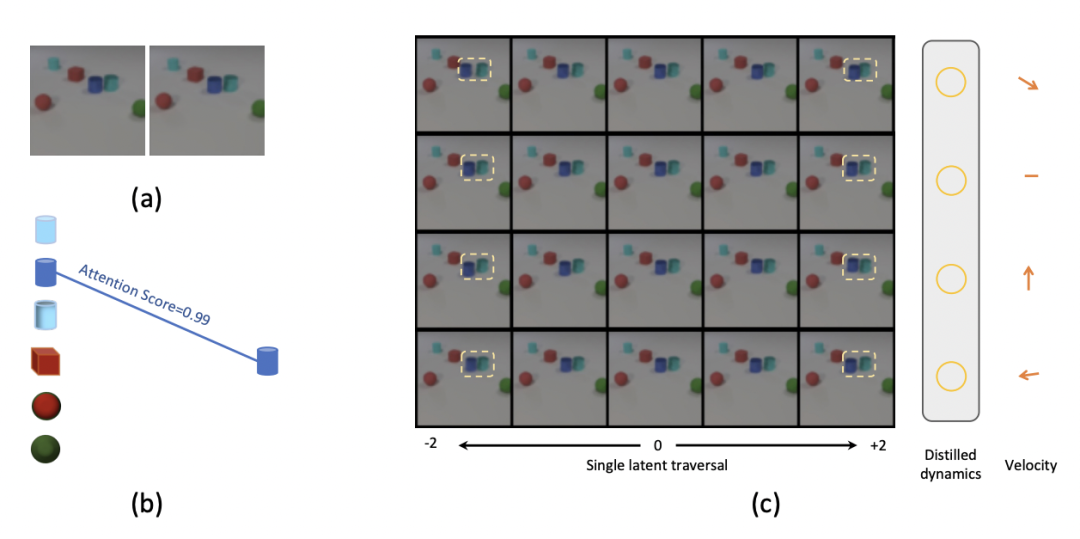
可视化表明,ODDN 自适应学习推理得出的物体动态物理属性编码了物体在不同方向的运动速度,验证了模型发现物理属性的解耦性。
![]()
图 6:动态物理属性解耦可视化:基于给定两帧预测第三帧,调节物体属性值会改变其对应方向的速度值。
人类对物理世界的常识、语言、交互和认知通常以物体为基本单位,所以一种自监督的以物体为中心的表示非常有意义。目前相关的工作都关注在简单的 toy 场景,团队希望未来会有在复杂真实场景有效分割表示场景的方法出现。另外,团队希望把以物体为中心的表示做到解耦合,并在此基础上进一步探索场景中物体与事件的因果关系,相信这是现阶段人工智能从 System 1 迈向 System 2 的重要一步。
欢迎同学们加入自动化所智能感知与计算中心张兆翔老师课题组(https://zhaoxiangzhang.net),稳定输出各大AI/CV顶会顶刊。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



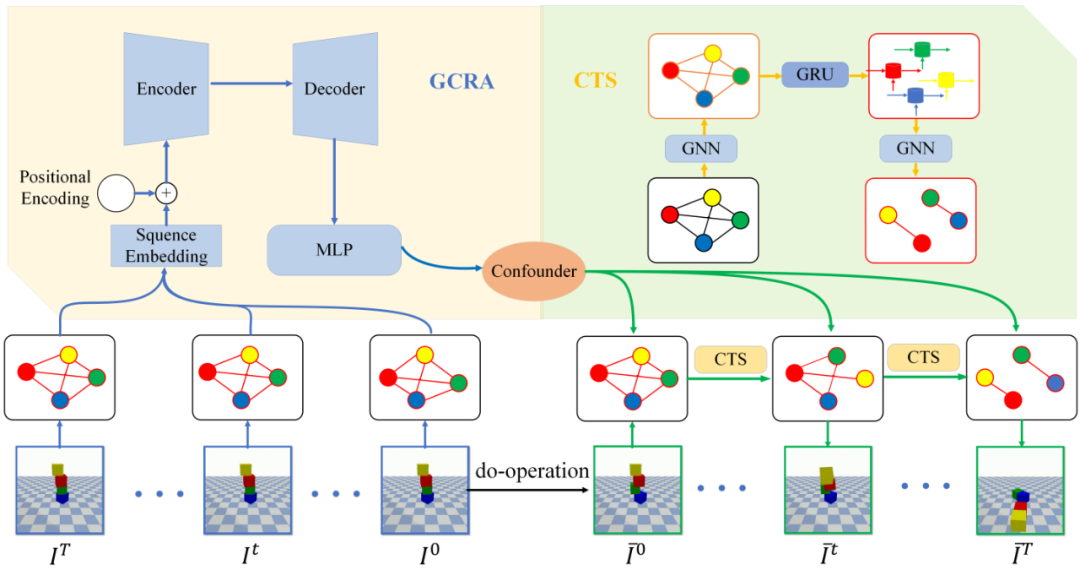
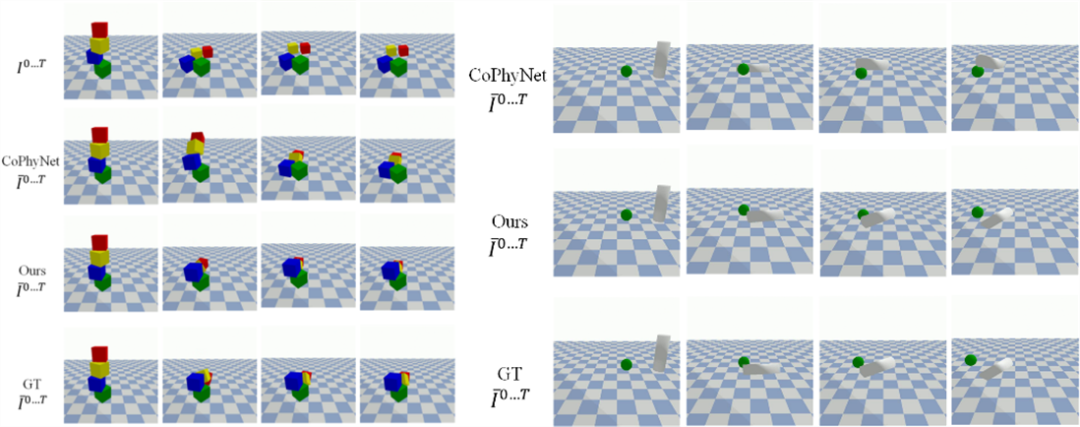

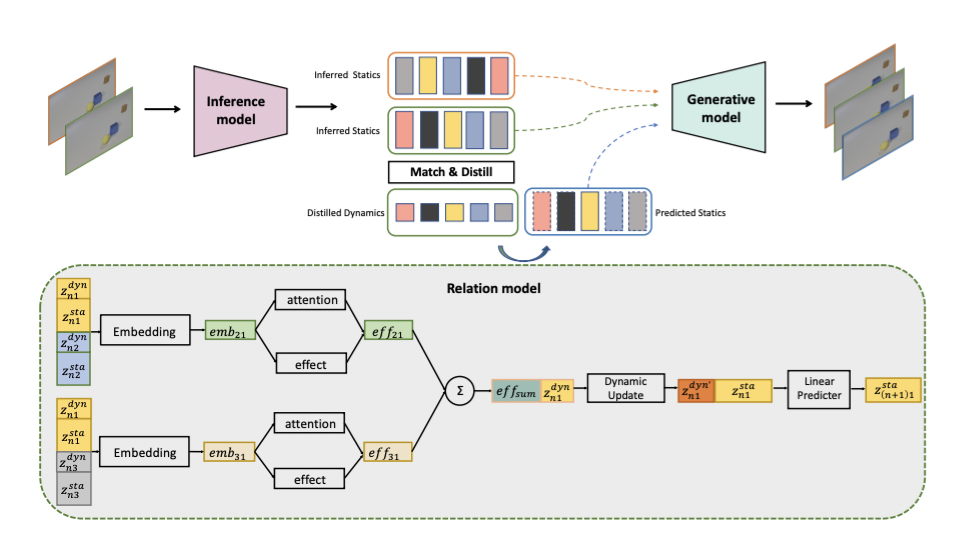
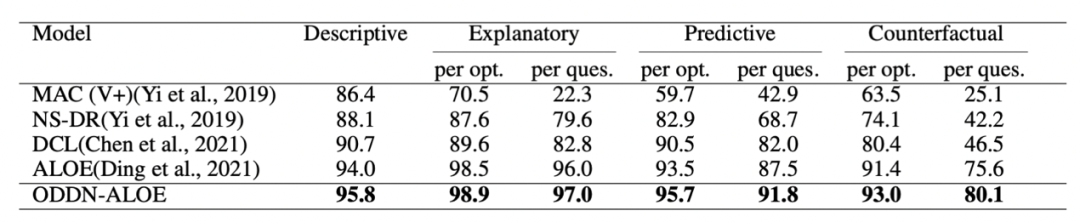
 图 4:基于输入的两帧预测后续视频帧效果对比。
图 4:基于输入的两帧预测后续视频帧效果对比。