不可错过的TensorFlow工具包,内含8大算法,即去即用!

这是来自谷歌的工程师Ashish Agarwal2017 TensorFlow开发者峰会在的演讲,主题是《ML Toolkit》。他认为TensorFlow 是一项很棒的技术,在谷歌,它已经在为很多系统提供支持,包括搜索排名、广告拍卖、YouTube推荐、 翻译、照片 以及很多其他项目。然而,TensorFlow只是很底层的框架,正如马丁在早期的谈话中提到的,我们正在研究高水平的参数,使研究人员和开发人员更易创建自定义模型架构。
TensorFlow 还缺少开箱可用的算法。许多开发者真正想要的是可以快速轻松地融入他们的工作流程的打包解决方案。所以,Ashish为大家介绍了一个工具包(toolkit),里面有很流行的机器学习算法:
线性/逻辑回归
K-means聚类算法
高斯混合模型
沃尔什(WALS)矩阵分解
支持向量机
SDCA,即随机双坐标上升
随机森林和决策树
深层网络的其他各种结构,如DNN,RNN,LSTM,Wide&Deep,...
为了让大家更好地了解这些算法现有和即将具有的功能,Ashish重点介绍了其中一部分算法。
1. 聚类:K-均值和GMM(高斯混合模型)
应用了标准的布局迭代算法以及随机和k-均值++初始化
支持全批/小批量的训练模式
也允许用户指定距离函数,如余弦或欧几里德平方距离

然后是GMMs以高斯分布的混合形式为数据建立模型。这些都是更强大的模型 ,也更难训练:
对于这些我们使用了迭代EM算法
允许用户从一系列的训练方法中选择包括协方差,混合重量等
2. WALS:采用加权交替矩阵分解的最小二乘法
在这里会得到一个非常稀疏的矩阵,注意矩阵是稀疏的,所以不是所有的视频都会得到所有用户的评分。可以用于解决诸如你应该向用户推荐哪个视频,或者找到用户相似或视频相似性的问题。现在,这通常是通过把这个巨大的矩阵分解为由两个密集因素组成的产品。
还要注意的是算法表明损失是有权重的,这可以允许你对未经评级的原始输入进行降级,或者避免垃圾邮件或热门输入等淹没掉总体损失。因此此值是高度非凸的。因此 训练工作以一个迭代的方式运行。首先,你要修复V、计算U,然后修复U ,计算V,以此类推。
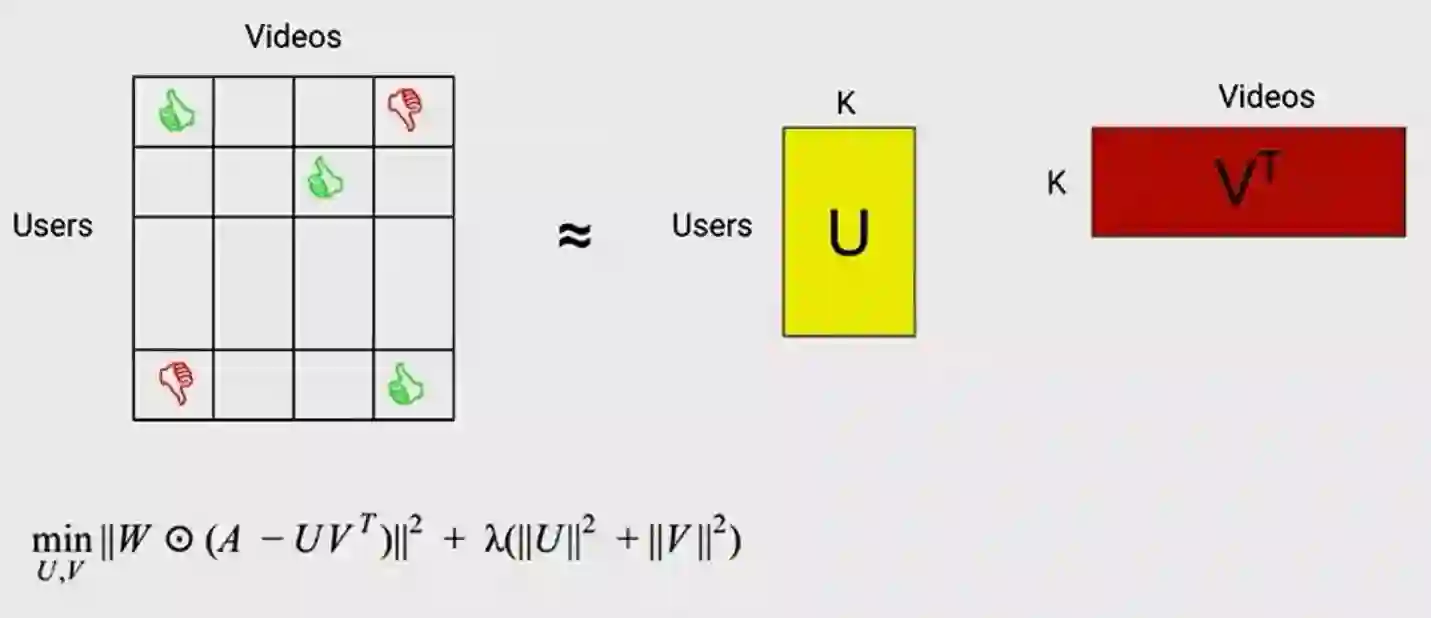
3. 支持向量机(SVM)
工作原理是要找到一个最大限度地提高幅度的决策边界。目前通过线性支持向量机及L1和L2正规化实现。注意,支持向量机变得更强大的非线性核函数(non linear kernel)允许一个更复杂的决策边界。
4. SDCA算法
在L1和L2正规化里有一个凸损失函数,SDCA把这一函数转化为对偶形式。事实证明,对于许多问题用对偶形式求解都是非常有效的,而且结果表明,该算法可以支持从线性和逻辑回归到支持向量机等的模型。

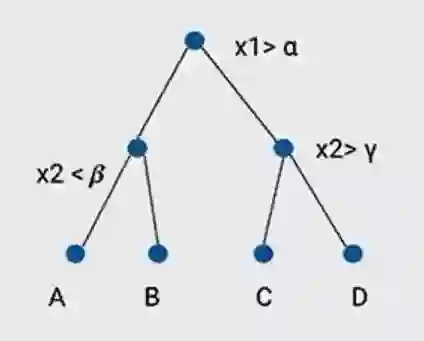
5. 随机森林和决策树
决策树的工作原理是创建特征空间的层次分区。目前,我们的训练方法“极随机森林训练”允许更好的并行化和缩放。通过梯度提升决策树工作,这个也非常受欢迎。
Ashish谈到了不同的算法并想让它们可以很容易的为用户所用。所有这些都是通过高水平的scikit-学习启发的预测API。一个例子是 k-均值聚类,你首先要创建一个k-均值聚类对象,在这里你会通过一系列诸如集群数量、训练方法、初始化方法等等选项。接下来调用拟合函数并通过它的输入来决定。它为你创建图形,将运行训练迭代配置运行时间 ,直到训练完成。当你准备好时就可以开始检查模型参数 ,如集群并开始运行推理,在这里找到分配给集群的任务等等。
开发者希望能保持TensorFlow承诺的灵活性和可扩展性,所以这些不是不透明的仅能通过此API访问的对象。事实上 ,它们可以允许用户检查图形并且也能够把这些图嵌入较大的训练模型。
这里有一个训练—一个例子将k-均值嵌入到更深的网络中。你从输入开始,运行k-均值得到用于k-均值的图形,它会返回training_op来驱动聚类。输出是将输入转换为聚类空间的距离。下一步,把这个放到密集的堆栈层创建监督损失,运行STD得到最后的DNN training_op。现在有这两个training_op,可以把他们加入到一起创建一个单一的training_op,驱动这两个模型的核心训练。
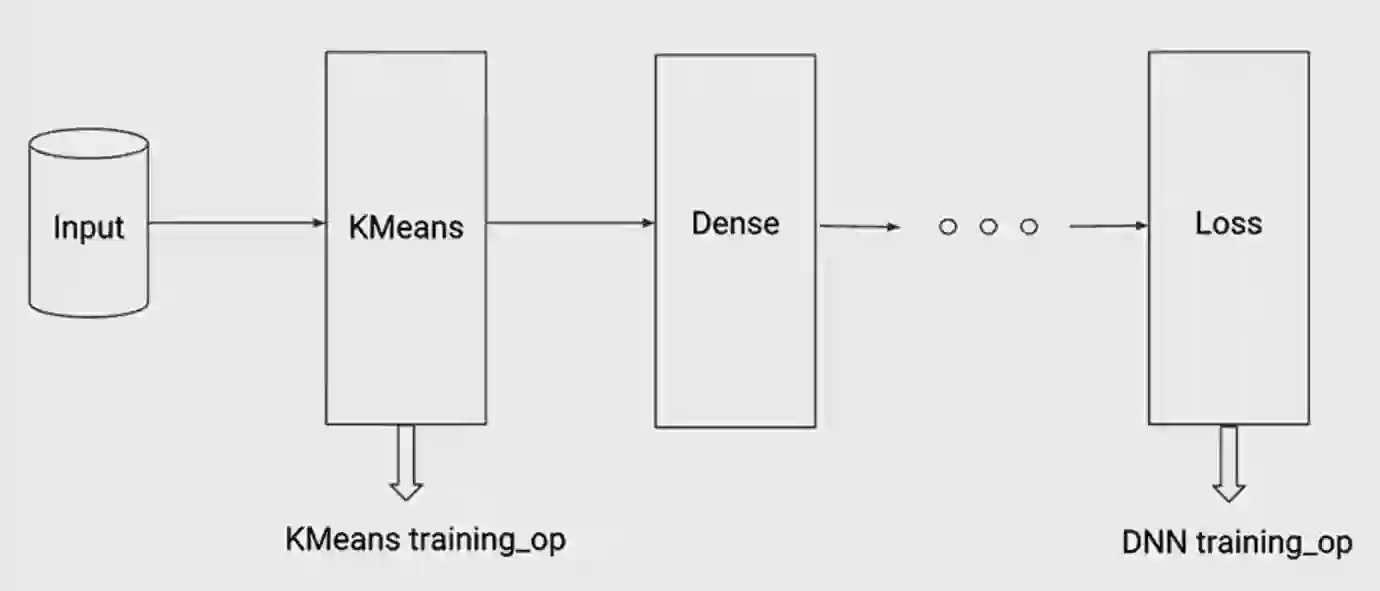
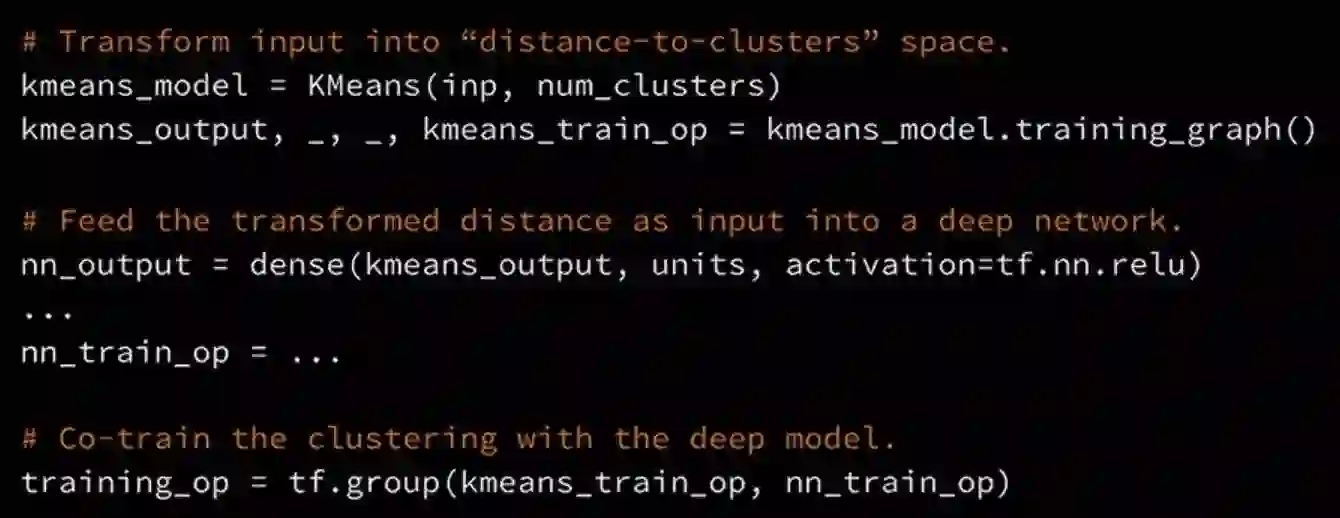
这里有一个相同的代码段,所以你通过创建这个k-均值对象而开始检查训练图,它将返回training_op和输出。下一步,把输出放到密集层,照常创建模型建筑,最后,得到驱动监督损失或密集堆栈的training_op。最后 使用TensorFlow的组操作把这些OP集合到一起会得到一个单一的OP。
以上谈到了不同算法、展示了如何使用高级API访问它们的例子,并讨论了这些算法的灵活性和可扩展性。接下来,Ashish强调了一点:所有这些算法都支持分布式实现。
为了给大家更好地理解这几行代码背后的复杂性,Ashish将执行其中之一的算法。一般来说 ,分布式体系结构做法大致相同,你会有一个参数设置服务器,里面以分散的方式存储着所有参数。您将有一组工人副本将与许多批次的投入一起运行训练步骤。在每个步骤中工人副本将获取一些参数,它将在输入上运行计算去算出参数的新值,最后,它会将这些更新写入参数服务器。
让我们再来看下WALS,运用WALS将非常稀疏的矩阵因式分解成致密的因素。如果希望能够有百万兆字节规模大小的输入,有上百万行上百列的元素,那么如何做呢?
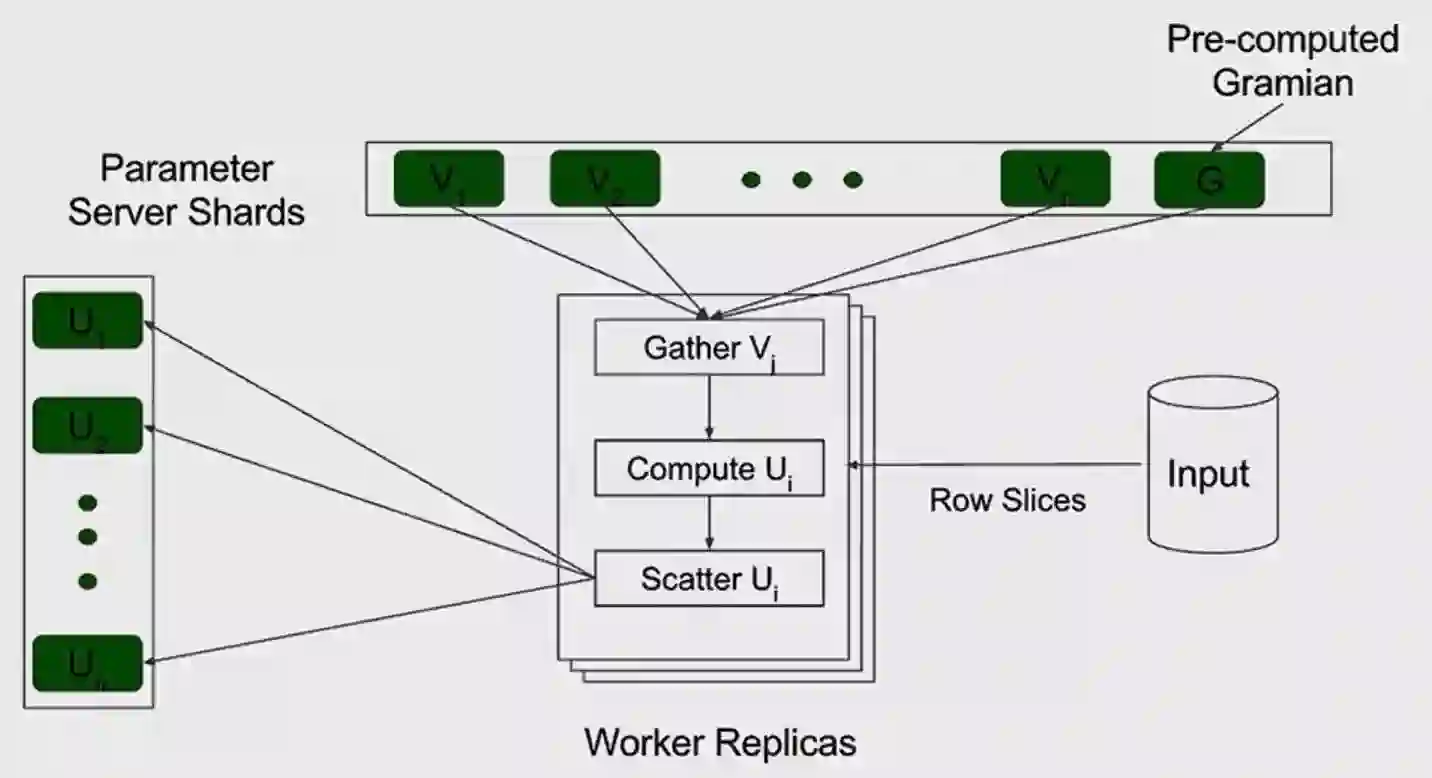
我们做了一些测试,在一般情况下对单台机器,在模型运行的质量和速度与scikit相当,甚至对于中等规模的问题更快。但TensorFlow真正的亮点是,它能够在几十万台机器上无缝运行。事实上,在许多情况下能够训练远大于我们所见到的模型。例如,用随机森林我们能够训练有数十亿的节点的决策树。
我们看到数十亿比谷歌高度优化的对逻辑回归的内部实现快10倍到50倍的例子。运用WALS我们可以把一个巨大的矩阵分解成4亿行6亿列,500列的元素可以在12小时以下完成,注意 ,这是50倍于我们可以用早期的基于MapReduce运行可以实现的量。总而言之,有超高性能分散和可扩展的不同ML算法在TensorFlow中开箱可用。这些算法把scikit与TensorFlow的可扩展性和能力集合在一起使Tensorflow接近一个更完整的ML解决方案。
---------------------------
来聊聊吧
你平时最常用的是什么算法?
为什么?
欢迎在评论区分享
延伸阅读:【教程】看看大神的思路!机器学习界网红7分钟教你如何搭建Chatbot?(中文版)

关注 AI 研习社后,回复【1】获取
【千G神经网络/AI/大数据、教程、论文!】
百度云盘地址!
点这个,看《史上最全的机器学习和 Python(包括数学)速查表》!
▼▼▼