AI 技术需要开源、开放。就在刚刚结束的中关村论坛旷视平行论坛中,旷视正式发布了天元 1.0 预览版。
9 月 18 日,中关村论坛旷视平行论坛中,
旷视研究院院长、首席科学家孙剑正式发布了开源深度学习框架天元 1.0 预览版
,并对天元的技术特性与发展方向进行了深入解读。
旷视 2014 年开始研发深度学习框架天元。目前,旷视 1400 多名研发人员全员使用天元 MegEngine,旷视所有算法均通过天元 MegEngine 进行训练和推理。
旷视天元 1.0 预览版,历经 8 次迭代 5 大升级
2020 年 3 月,旷视正式将天元开源,提供给全球开发者使用。开源以来,天元从 3 月的 Alpha 版本升级到 6 月的 Beta 版本、到 9 月的 1.0 版本,
期间实现了 8 次迭代
。
此次天元 1.0 预览版,相比之前的版本,实现了 5 项重要的技术升级。
![]()
首先,天元 1.0 预览版提供了全新的 Imperative Runtime。天元通过重写动态执行引擎,打破过去几个版本中动态图的限制,解决了一系列资源释放的问题,并大幅提升了动态自由度,让使用 GPU 计算像 NumPy 一样方便自如。
其次,天元 1.0 预览版新增自动代码裁剪功能。在实际的 AI 应用开发中,用户经常面临模型大小的问题。自动代码裁剪功能让用户可以全自动的针对自己网络使用的算子进行代码裁剪,不用手工配置就能最小化推理时的代码体积,极大提升端侧推理的竞争力。
此外,天元 1.0 预览版进行了 10 余项推理侧性能优化,进一步提升了端侧推理性能。同时,天元支持了更多的国产硬件。天元对于主流的一些国产硬件进行了接入,方便在国产 NPU 芯片上进行推理工作。
最后,天元实验性的开发了一套基于 MLIR 的 JIT 引擎,尝试利用 MLIR 这一项非常有前景的方案进行计算图的进一步融合、优化来整体提升深度学习训练和推理的速度。
经过了半年的开源工作,现在天元拥有了完整的功能体系。天元希望能依靠训推一体这一特性,让产业应用可以更快、更高效的落地。让深度学习也可以简单开发。
从开源到现在经过半年的技术迭代,
天元拥有了三大核心优势:训练推理一体、全平台高效支持、动静结合的训练能力
。
![]()
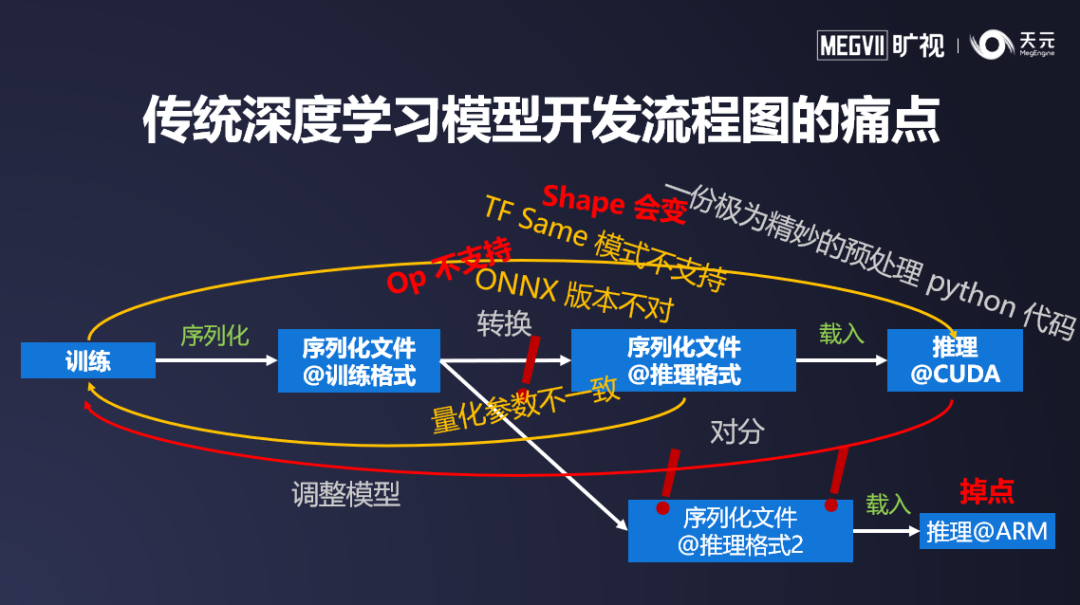
所谓训练推理一体,就是让训练与推理不再是完全孤立的两个步骤。为什么训推一体如此重要?在传统深度学习模型开发流程中,从训练到推理,开发者需要经过一系列格式转换。但随之而来的也会有种种复杂难题,比如推理框架对算子不支持、作为中间转换格式的 ONNX 版本不一致,转换成 Caffe 过程中存在一些层的中间形状变化导致无法转换,涉及到量化模型时量化参数的定义不一致等,都会增大转换的难度。
![]()
除了转换难外,由于各个平台的差异性和预处理逻辑的复杂性,训练侧提供的预处理逻辑很有可能与推理侧实现的结果不一致,推理和训练的精度对齐变得非常困难。
传统深度学习模型开发环境下,在不断地对分配、适配和微调的过程中,一个模型的落地工作往往需要数天到数周时间。如果还涉及到多平台的部署,则以上问题复杂度和难度会成倍增加,让模型交付变得非常困难。
![]()
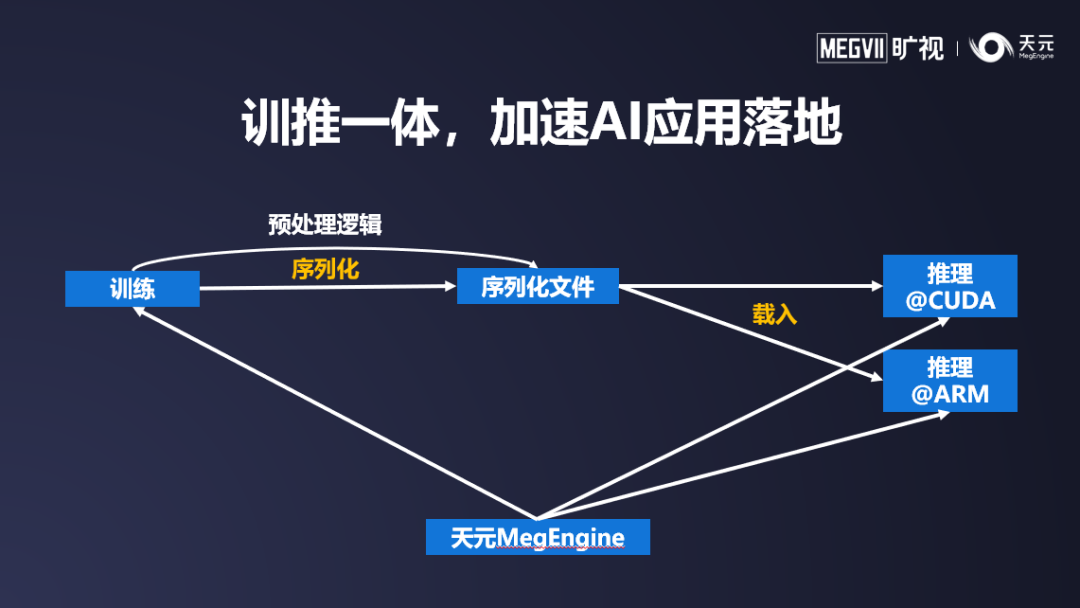
为了解决传统模型开发的一系列痛点,天元在训练和推理侧均是一套底层框架提供支持,对算子的支持、量化参数的理解均高度一致。同时,天元支持各类常用的 CV 算子操作,便于开发者将预处理的代码逻辑直接写入模型结构当中,从而让训练和推理间的差距大幅度缩小,开发者不再需要为了模型转换而头疼。
经过各方用户一段时间的实际验证,使用天元整个模型,可以将从训练到推理的交付时长缩短至传统方案的十分之一以下,真正做到天级交付。
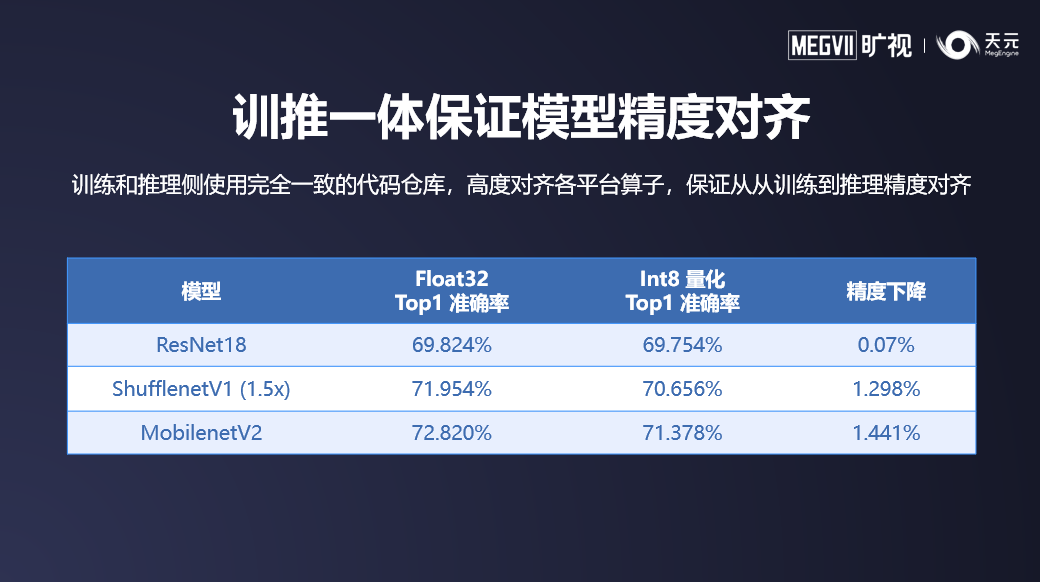
另外,由于训推一体化,模型在训练阶段与推理阶段可以高度对齐,这使得量化感知训练产生的模型可以无风险的在端侧应用。同时天元拥有精心设计的量化训练模块,大大降低了量化感知训练模型的使用门槛。
![]()
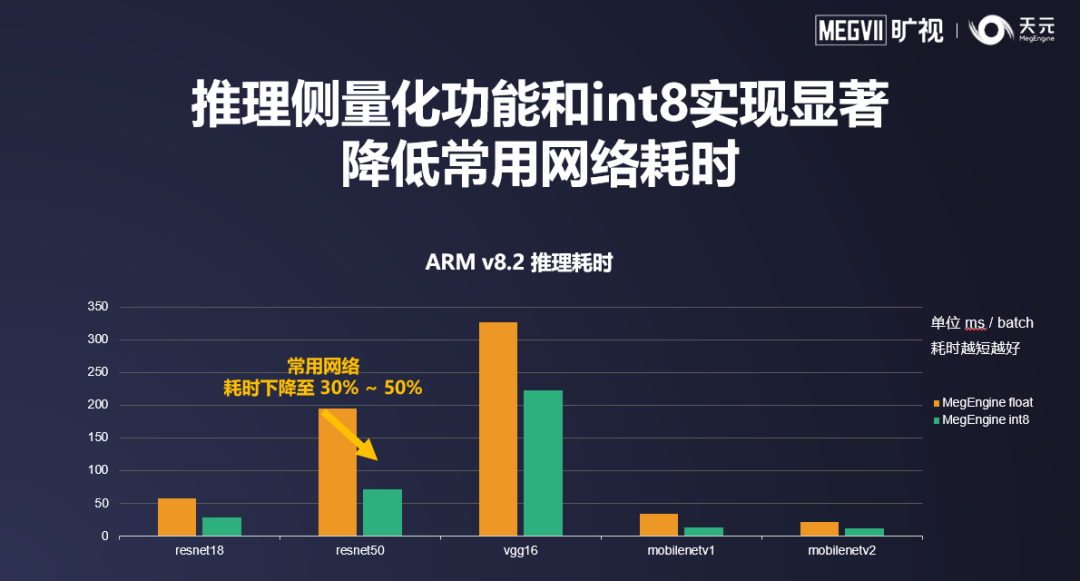
以上表格中,在各类模型上,通过应用量化感知训练,可以在极小的精度下降前提下,使用 int8 推理。量化感知训练产生的高精度模型,配合上天元经过高度优化的 int8 算子,可以将各个常见网络的推理耗时降至浮点模型的 30%~50% 以内,有效带来性能加速。
![]()
广泛而高效的平台支持,是实现训推一体的前提。只有在各个平台上都提供足够高效便捷的推理能力,才能真正的免除模型转换工作。
对于开发者常用的各类 CPU、GPU 和 NPU,天元均提供了全面而高效的支持,让用户无需为每个平台重新学习重新开发,可以让用户一套模型、一套代码走天下。
天元支持的设备包括 NVIDIA GPU、ARM、X86 和 AMD GPU 平台以及各类国产 NPU 芯片。同时,测试表明,相比其他一些框架,天元在 CUDA、ARM、X86 平台上都具备性能优势。
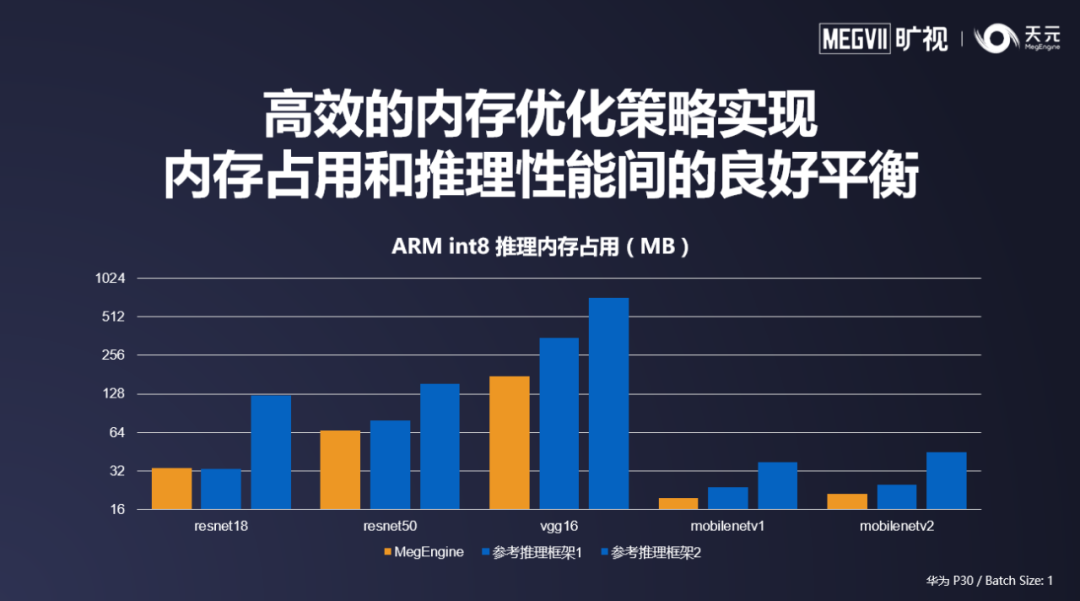
深度学习应用中,运行时的内存占用是一个重要的指标。由于天元的自动内存优化策略在训练侧得到了充分的打磨,天元可以在内存占用和推理性能之间取得良好的平衡。
![]()
仅依靠通用的优化策略,天元对于任意的模型结构都有足够良好的优化表现,框架无需针对网络结构特殊优化。这保证了天元可以在开发者自己的模型结构也保持较低的内存占用,让天元可以帮助各个领域的开发者降低内存占用量,提高竞争力。
端侧推理时,推理程序的二进制体积同样是一项非常重要的指标,对于端侧的 SDK 竞争力非常重要。
![]()
对此,天元提供了自动代码裁剪机制,根据模型的结构,将不需要的 kernel 实现和代码片段裁减掉的过程全自动,从而将代码体积大幅度缩小,大幅度提升端侧 SDK 的竞争力。
动态图训练对程序员友好,可以随时停下来 Debug;而静态图的训练好处是可以让训练的精度、内存消耗和训练速度达到最优。如何兼得动态图训练和静态图训练的好处?天元通过动静结合支持快速模型设计。动态模式下,天元可以方便的排查模型问题,在遇到错误后及时停下,便于分析模型结构上的异常问题。通过添加一行 trace,模型可以被直接转换为静态图模式,获得静态图所独有的图优化,一方面可以更好的对显存进行复用,提高显存利用率,另一方面可以优化计算顺序,提升模型的训练性能。
![]()
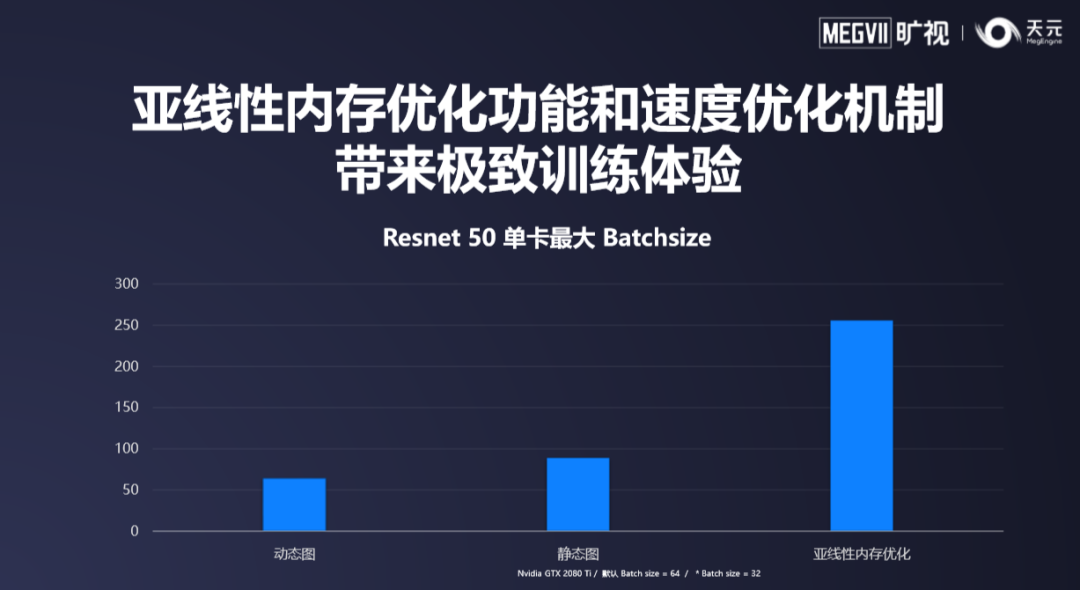
在 Beta 版天元推出了亚线性内存优化技术。目前天元是唯一一个支持全自动亚线性内存优化技术的框架。静态模式下,在静态图的基础上,额外添加一个配置项,则可以便捷的启用亚线性内存优化。天元内置的 Sublinear 亚线性内存优化功能,可以对任意的模型结构进行内存优化,在相同的显卡下,可以训练出更大更准确的模型。
![]()
亚线性内存优化的特点是参数量越大,从而节省下的显存量越多。因此越庞大的模型,从中获得的收益就越大。由于算法的普适性,无论是任何的模型结构,都可以全自动的被亚线性内存优化机制处理。
![]()
在使用上,天元模型中心 Model Hub 提供了丰富的预训练模型,包括图像分类、目标检测、图像分割等模型,并且每个模型都提供了 SOTA 级别准确率,让使用者可以便捷的上手天元,站在巨人的肩膀上开始自己的科研工作。
![]()
此外,天元已经与小米 MACE、OpenAI Lab Tengine 进行了深度的集成,用户可以将 MegEngine 的模型直接转换到 MACE 或 Tengine 中执行,从而获取在各类异构设备上执行深度学习模型的能力。
天元 1.0 预览版的发布意味着天元已经迭代成为一个完备的深度学习框架。未来天元将如何迭代发展?旷视天元技术团队认为深度学习未来会继续蓬勃发展,在不断涌现新技术新方案的同时,现有的方案和技术会进一步的范式化,简化整个流程,像传统软件开发一样精确分工、快速迭代。因此天元会持续在易用性和整个深度学习落地的流程化上努力,让深度学习应用的流程更加清晰易懂,从而大幅提高 AI 的生产力。
此外,在过去的一段时间中,深度学习框架从编译器中借鉴了相当一部分的内容,旷视天元技术团队认为随着 MLIR 等新兴技术的产生,框架将会进一步向编译器化发展,从而获得更大幅度的性能提升。
最后,随着大量云、端上的 AI 芯片的衍生以及各类神经网络加速器应用的愈加广泛,每家芯片自身的推理框架越来越强大。训推一体的核心是在训练阶段对芯片的充分了解和兼容,因此如何让用户能从一开始就训练出一个适用于最终要用到的芯片的模型,才是让整个落地流程最高效的重点。天元希望能够与芯片协同演进,协同发展,让整个生态能够更加健康蓬勃的发展。
AI 产业落地浪潮中,开发者只有在友好、开放、创新的开发环境中,才能更好地进行 AI 的价值设计与开发,为全球输送 AI 动能。欢迎全球开发者,加入天元社区,一起让深度学习也可以简单开发。
MegEngine Website:https://megengine.org.cn
MegEngine GitHub(欢迎 Star):https://github.com/MegEngine
天元 1.0 预览版安装方式:复制命令 pip3 install megengine==1.0.0rc1 -f https://megengine.org.cn/whl/mge.html
加入「天元开发者交流 QQ 群」,一起看直播学理论、做作业动手实践、直接与框架设计师交流互动。
![]()
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com