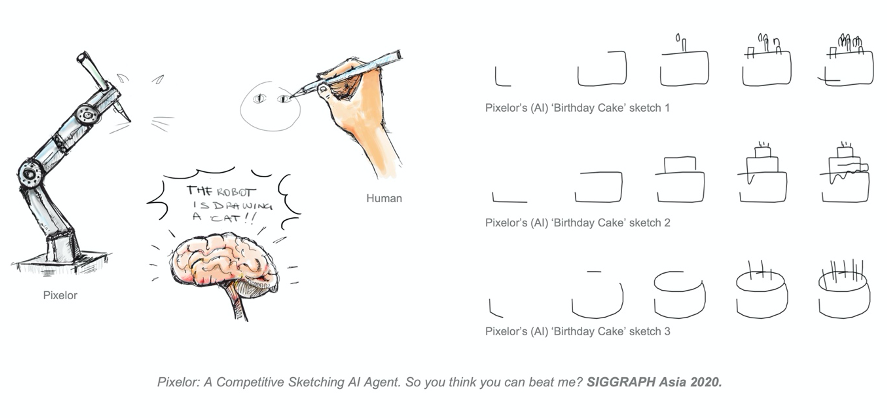
「你画我猜」是一种广泛流传在不同文化中的人类通识游戏,其形式简单但高度体现人类的认知智慧。近日一篇被计算机图形学顶会 SIGGRAPH ASIA 2020 接收的论文提出了一种基于草图的生成优化方法。在给定一个视觉概念的前提下,相较于人类竞争者,该模型能够以相似或更快的速度实现可识别的草图渲染。
![]()
近几十年来,AI 在越来越多的游戏中逐渐达到了能够与人类同台竞技的水平。从 1997 年在国际象棋比赛中胜出的 Deep Blue 到 2011 年在电视智力竞赛项目 Jeopardy 中大放异彩的 IBM Watson,从 2013 年 DeepMind 开发的能够胜任各种 Atari 小游戏的程序到 2016 年所向披靡战胜职业围棋选手的 AlphaGo。至少对于公众来说,每一个实例都把技术的突破和抽象计算的进步变成了一场具有观赏性的运动。
在这样的背景下,AI 能在你画我猜(Pictionary)游戏中表现优异的消息也就没有那么令人难以置信了。Pictionary 是一个受猜字游戏启发的游戏,需要一个人粗略地勾勒出视觉画像,其他人则试图以最快的速度猜出他/她画的是什么。这正是英国萨里大学 SketchX 实验室的研究人员近期的研究成果:
一种对速度敏感并以竞争驱动的草图生成 AI——Pixelor。即给定一个视觉概念,Pixelor 能够像人类竞争者一样快速甚至更快地画出一幅人类和机器均能识别的目标对象草图。
![]()
将现实世界复杂的图像还原成草图,是令人印象深刻的。这需要很强的抽象能力:把人脸看作一个椭圆形,并由两个更小的椭圆形组成眼睛,一条弯曲的线段作为鼻子以及一个半圆形去模拟嘴巴。这种感知图像的方式通常是孩子们快速发展认知理解能力的重要特征之一。然而就像莫拉维克悖论 (Moravec's Paradox) 所总结的那样,「对人类十分棘手的问题对计算机来说通常较为简单,而对人类来说非常容易的事计算机则极难处理」。抽象感知,这种看似大多数两岁孩童与生俱来的基本技能,对于机器智能来说则是一项巨大的挑战。
与人类草图相关的计算机视觉工作主要集中于判别性任务的分析,包括基于草图的识别 [1]、语义分割 [2]、美化 [3]、3D推理 [4],以及在检索框架下与现实图片的联系 [5,6]。直至近期在开创性的工作 SketchRNN 中 [7],AI 首次展示出可以适应不同的风格和抽象水平、并且像人类一样逐笔渲染出可识别草图的能力。
但这对于 Pixelor 来说仍然是不够的。你画我猜是一个竞速类游戏。你可能是一个伟大的艺术家,但是如果花费 12 个小时去画一只完美的猫,那么你将是一个糟糕的你画我猜玩家。
正如Pixelor工作的通讯作者、来自萨里大学视觉语音和信号处理中心 (CVSSP) 的教授、SketchX实验室主任宋一晢 (Yi-Zhe Song) 所言:
「对于Pixelor来说,最重要的是推理出哪些是对视觉识别最重要的笔画,并保证这些笔画能够被优先尽早地渲染出来。我们已经发布了面向公众的Pixelor版本。我们希望人类玩家能够击败我们的AI模型,甚至通过与AI的博弈来逐渐提高他们的游戏策略并成为更好的你画我猜玩家。」
在第一阶段,研究人员输入一个给定的训练草图集,并将每个个体草图以随机的笔画顺序打乱,其目的是希望学习推断出能够最大化该训练集早期识别度的笔画级排序。这样做是因为人类数据中的原始排序并不是最优的,这也是人类在你画我猜的游戏中会被精心设计训练的 Pixelor 打败的深层原因。
想要实现更优草图笔画顺序的目标,一个显而易见的策略是详尽地评估所有可能的笔画顺序,然而这会在计算上产生难以处理的巨大搜索空间。Pixelor 采用了 NeuralSort [8],一种可微分的允许直通梯度 (Straight-through gradients) 反向传播的排序算法,并用更先进的可学习感知特征代替了启发式损失函数。
总而言之,该框架通过学习笔划评分策略避开了笔划顺序的组合搜索,进而实现了早期识别。
在第二阶段,Pixelor 根据上述经过最佳笔画顺序更新的数据集,来训练序列到序列的草图生成模型。不同于之前 SketchRNN 模型的是,研究人员提出用最佳传输距离 (optimal transport) 替代基于KL散度的方式(常见于变量自编码器中)来约束嵌入特征空间。这种设计选择是基于对人类手绘行为的直观观察。面对同一个视觉概念,虽然不同的个体可能在你画我猜游戏中展现相似的竞技性,但他们仍然会有不同的草图策略。这使得笔画序列空间本质上是多模态分布的,而最佳传输距离可以更好地捕捉这种分布。
Pixelor 的意义,不仅仅是又一个会玩游戏的新 AI。就像计算机系统既有我们交互的用户界面,又有后台代码一样。每一个重要的 AI 游戏里程碑背后都有着更深层次的考量。实验室花费大量的时间和人力物力,不是为了在人类不再擅长的事情列表上再增加一项,而是为了完善人工智能的基础能力,以用于解决现实问题。
在 Pixelor 的案例中,
研究人员的最终目标是让机器能够更好地弄清楚在特定场景中什么对人类来说是重要的。当我们看一张图片时,我们马上就能知道最需要注意的部分是什么。
比如,当你下班开车回家的时候。虽然路边的风景如画,远处的广告牌也可能很有趣,但这都不如你面前可能随时出现的行人重要。在你有意识地处理这些信息之前,大脑就已经把最重要的细节挑了出来。
![]()
而如何教会计算机做到这一点呢?一个好的起点就是寻找人类在手绘时如何优先考虑头脑影像中突出的可识别细节。
「传统照片中并没有人类的主观输入,我们想要的是人类数据。而手绘的过程正是体现了人类理解与表达视觉场景的方式。」
宋一晢教授如是说。
一个优秀的你画我猜玩家,就像一个优秀的拳击手一样,需要知道达成某一目标所需要的绝对最短路径。从宏观上看,这一点正是这篇 SIGGRAPH AISA 2020 论文的更大意义。这不仅仅是教会 AI 玩一项游戏那么简单,而是怀有一种更大的愿景:让AI学会推理图像场景中的重要之处,并能够更好地泛化。从自动驾驶到智能机器人,这都是一项亟需解决的任务。
![]()
论文地址:https://ayankumarbhunia.github.io/pixelor/image/pixelor.pdf
Pixelor项目主页:http://sketchx.ai/pixelor
SketchX实验室主页:http://sketchx.ai
萨里大学CVSSP主页:https://www.surrey.ac.uk/centre-vision-speech-signal-processing
[1] Qian Yu, Yongxin Yang, Yi-Zhe Song, Xiang Tao, and Timothy M. Hospedales. Sketch-a-net that beats humans. BMVC 2015. (Best Science Paper Prize)
[2] Rosália G Schneider and Tinne Tuytelaars. Example-based sketch segmentation and labeling using crfs. SIGGRAPH 2016.
[3] Mikhail Bessmeltsev and Justin Solomon. Vectorization of line drawings via polyvector fields. SIGGRAPH 2019.
[4] Wanchao Su, Dong Du, Xin Yang, Shizhe Zhou, and Hongbo Fu. Interactive sketch-based normal map generation with deep neural networks. ACM on Computer Graphics and Interactive Techniques 2018.
[5] Qian Yu, Feng Liu, Yi-Zhe Song, Tao Xiang, Timothy M. Hospedales, and Chen Change Loy. Sketch Me That Shoe. CVPR 2016.
[6] Patsorn Sangkloy, Nathan Burnell, Cusuh Ham, and James Hays. The sketchy database: learning to retrieve badly drawn bunnies. SIGGRAPH 2016.
[7] David Ha and Douglas Eck. A Neural Representation of Sketch Drawings. ICLR 2018.
[8] Aditya Grover, Eric Wang, Aaron Zweig, and Stefano Ermon. Stochastic Optimization of Sorting Networks via Continuous Relaxations. ICLR 2019.
Amazon SageMaker实战教程(视频回顾)
Amazon SageMaker 是一项完全托管的服务,可以帮助机器学习开发者和数据科学家快速构建、训练和部署模型。Amazon SageMaker 完全消除了机器学习过程中各个步骤的繁重工作,让开发高质量模型变得更加轻松。
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下:
![]()
第一讲:Amazon SageMaker Studio详解
黄德滨(AWS资深解决方案架构师)主要介绍了Amazon SageMaker的相关组件,如studio、autopilot等,并通过在线演示展示这些核心组件对AI模型开发效率的提升。
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
第二讲:使用Amazon SageMaker 构建一个情感分析「机器人」
刘俊逸(AWS应用科学家)
主要介绍了情感分析任务背景、使用Amazon SageMaker进行基于Bert的情感分析模型训练、利用AWS数字资产盘活解决方案进行基于容器的模型部署。
视频回顾地址:https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d38e4b0e95a89c1713f
第三讲:DGL图神经网络及其在Amazon SageMaker上的实践
张建(AWS上海人工智能研究院资深数据科学家)主要介绍了图神经网络、DGL在图神经网络中的作用、图神经网络和DGL在欺诈检测中的应用和使用Amazon SageMaker部署和管理图神经网络模型的实时推断。
视频回顾地址:
https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715d6fe4b005221d8eac5d
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com