斯坦福&Adobe CVPR 19 Oral:全新通用深度网络架构CPNet
新智元原创
新智元原创
作者:Xingyu Liu
编辑:金磊
【新智元导读】斯坦福大学和Adobe研究院的研究者们提出了全新的通用深度网络架构CPNet,用于学习视频中图片之间的长程对应关系,来解决现有方法在处理视频长程运动中的局限性。在三大视频分类数据集上取得了优于之前结果的性能。相关论文获CVPR 2019 oral。
这是一款全新的通用深度网络架构。
现有的视频深度学习架构通常依赖于三维卷积、自相关、非局部模块等运算,这些运算难以捕捉视频中帧间的长程运动/相关性。
近日,来自斯坦福和Adobe的研究人员,受到点云上深度学习方法的启发,提出了一个通用的深度网络架构CPNet,用于学习视频中图片之间的长程对应关系,来解决上述问题。

arXiv地址:
https://arxiv.org/abs/1905.07853
研究人员们所提出的CPNet是一个全新的通用的视频深度学习框架。该网络通过寻找对应的表征来学习视频中图片之间稀疏且不规则的对应模式,并且可以融合进现有的卷积神经网络架构中。
研究人员在三个视频分类数据集上进行了实验,结果表明,CPNet在性能上取得了较大的突破。
CPNet:对应提议网络
视频是由一串图片组成。然而,视频并不是任意图片随机的堆砌,其前后帧有强烈的相关性,表现为一帧图片中的物体通常会在其它帧中出现。
相比于单张静态的图片,这样的对应关系构成了视频中动态的部分。我们总结视频中图片之间的对应关系有如下三大特点:
对应位置有相似的视觉或语义特征。这也是我们人类判定两帧中的像素是否属于同一物体的标准之一。
对应位置在空间维和时间维上都可以有任意长的距离。空间维上,物体可以很快从图片的一端运动到另一端;时间维上,物体可以在视频中存在任意长的时间。
潜在的对应位置所占比例为少数。对于一个像素/表征,在其它帧中通常只有极少的相似像素/表征是可能的对应,其它明显不相似的像素/表征则可以忽略掉。换言之,对应关系存在不规则性和稀疏性。
那么什么样的网络架构可以满足上述特点呢?
三维卷积无法检测相似性;自相关是局部操作,无法胜任长程对应;非局部模块侧重于注意力机制,无法适应稀疏性和不规则性,也无法学到长程运动的方向。因此我们需要全新的网络架构。
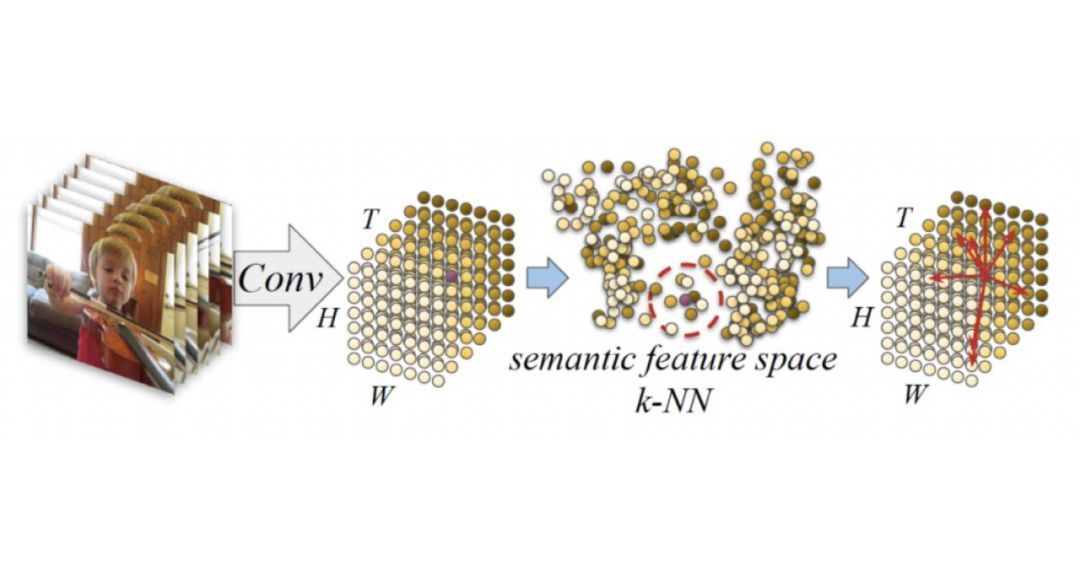
图1
我们提出了对应提议网络CPNet(Correspondence Proposal Network),其架构能同时满足上述三种特点。
核心思想如图1所示:深度网络架构中,我们将视频表征张量视为一个点云,在语义特征空间中(而非一般的时空空间),对于表征张量中的每一个表征即“点”,我们寻找其在其它帧里最近的k个“点”,并将其视为该表征的潜在对应。然后类似于点云上的深度学习,对于这k对“点”中的每一对,我们使用相同且互相独立的神经网络处理他们的特征向量和位置,然后用最大池化操作从k个输出中提取出最强的响应。本质上,我们的网络架构可以学到从这k对潜在对应中选择出最有趣的信息。如此一来,最后的输出表征向量就包含了视频中的动态信息。
CPNet的架构
我们将网络的核心命名为”CP模块“,其结构如下,大致分为两个部分。输入和输出都是一个THW x C的视频表征张量,我们将这两者都视为一个THW个点的带C维特征向量的点云。
第一个部分为语义特征空间k最近邻算法,如图2所示。我们先求出所有表征对之间的负L2语义距离得到THW x THW形状的矩阵;然后将对角线上的T个HW x HW子矩阵的元素置为负无穷,这样位于同一帧的表征就可以排除在潜在对应表征之外了。之后对每一行进行arg top k操作就可以得到潜在对应表征的下标。
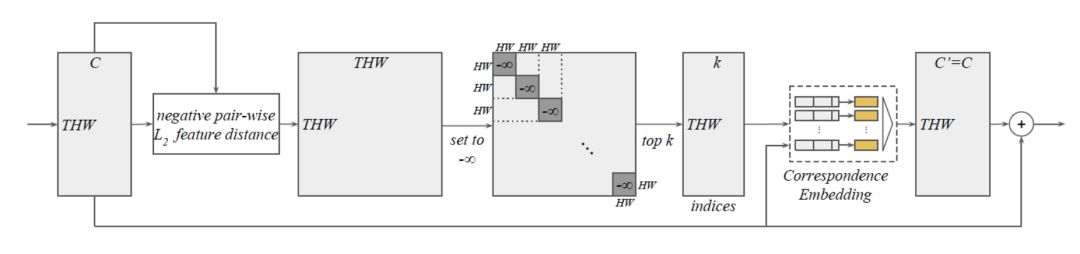
图2
第二个部分为对应关系的学习。我们用上一步得到的下标从输入视频表征张量中提取出表征。对于每一个输入表征和其k个最近邻表征组成的k对表征对中的一对,我们将这一对表征的语义特征向量以及其之间的时空相对位置连在一起,得到k个长向量。然后我们将这k个长向量送入相同且互相独立的多层感知器(MLP),然后再用元素级的最大池化操作(element-wise max-pooling)得到输出向量,也就是输出视频表征张量该表征位置的语义特征向量。

图3
为了防止训练时梯度爆炸或消失,类似于ResNet中的跳跃连接,我们将上一步的输出表征张量加回到了输入表征张量中。可以看到,该模块可以无缝衔接进现有的卷积神经网络架构如ResNet中。在实验中,所有CP模块一开始初始化为全等操作,这样我们就可以使用ImageNet预训练模型来初始化网络其它部分的参数。
实验结果
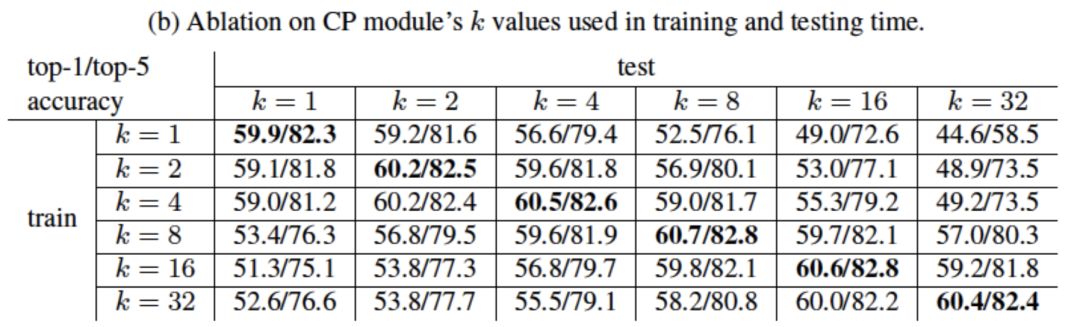
我们在大规模视频分类数据集上进行了实验。首先,我们在Kinetics数据集上进行了小规模模型的实验来研究CP模块的数量、位置以及k值的大小对视频分类结果的影响。由结果可知,模型的性能随CP模块数量增多而提高并趋于饱和;CP模块放置的位置对性能有影响;k值在训练时和推理时保持一致且合适的值可以得到最佳性能。
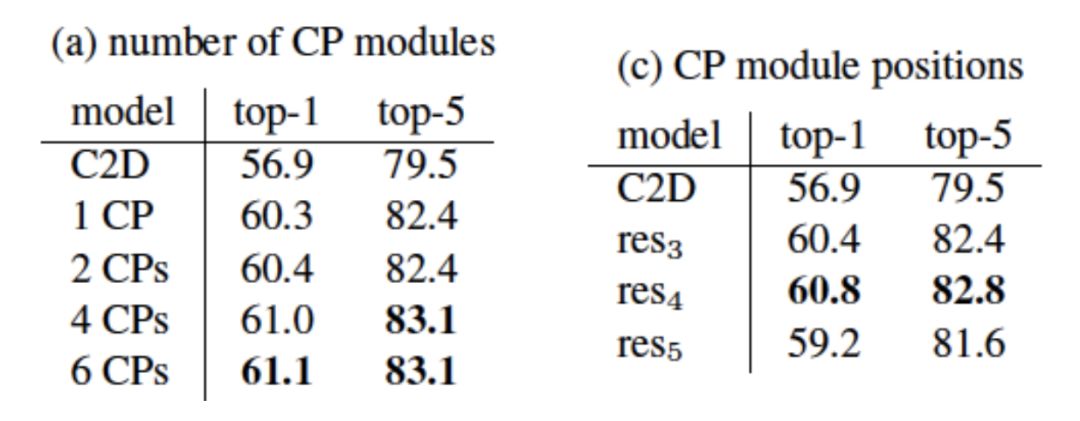
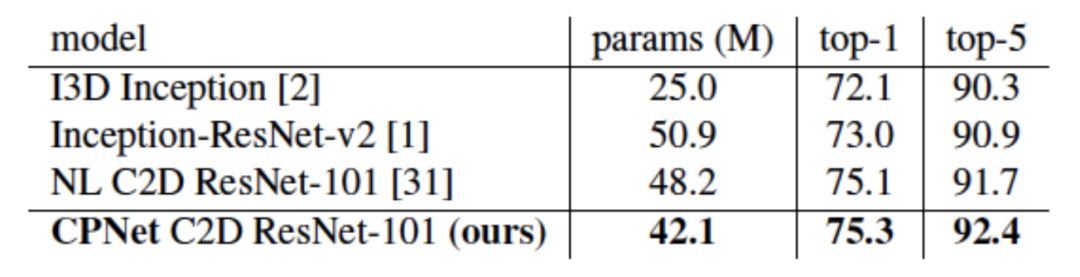
我们在Kinetics数据集上与其它已发表结果进行了比较。我们同时比较了小规模和大规模模型。CPNet在参数数量更少的情况下取得优于之前结果的性能。
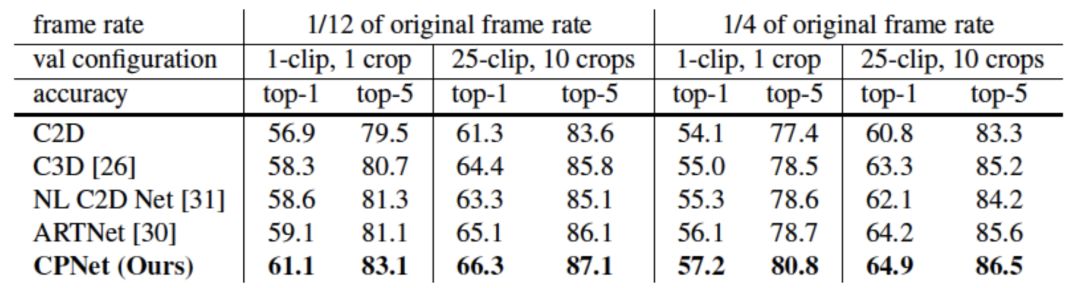
我们也在Something-Something和Jester数据集上与其它已发表结果进行了比较。相比于Kinetics,这两个数据集更偏重动态信息对分类的影响。CPNet同样在参数数量更少的情况下取得优于之前结果。
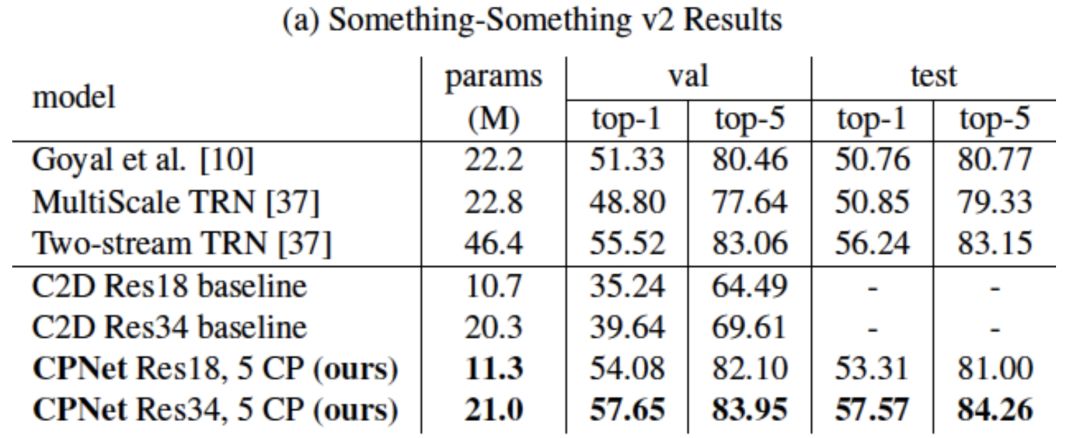
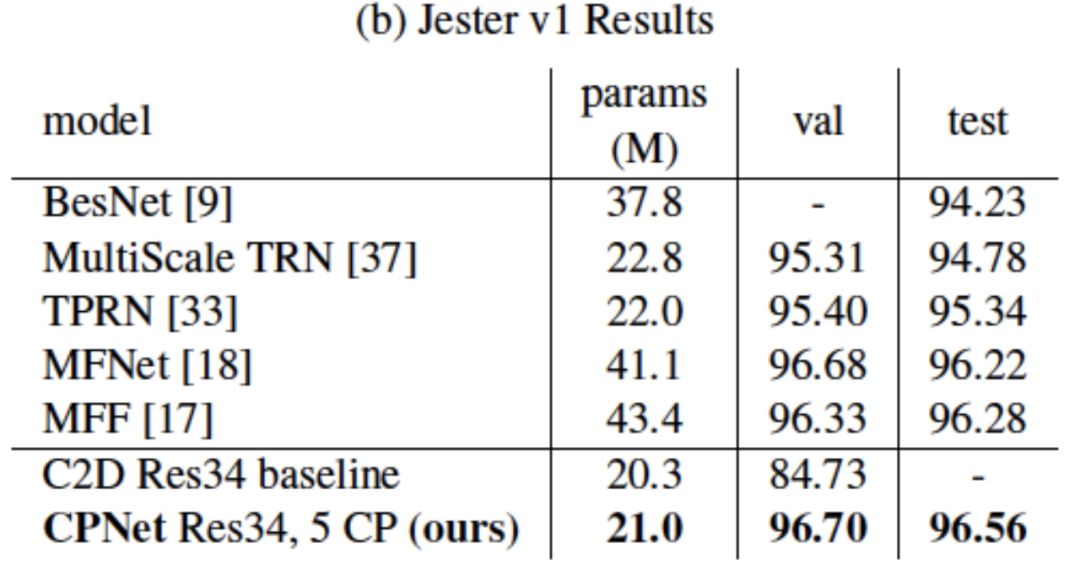
值得注意的是,相比于没有CP模块的基准二维卷积ResNet,CPNet仅仅额外加入了极少的参数,就在这两个数据集上得到了极大的性能提升,进一步证明了其学习视频中动态信息的强大能力。
模型的可视化
我们对训练好的模型进行了可视化来理解其工作原理。
我们选取了一个表征的位置,然后在图片中用箭头标注出其k个最近邻表征的位置。特别地,我们用红色箭头标注出哪些最近邻表征在最大池化过程中被选中。我们同时用热图来显示表征图在经过CP模块后的变化。

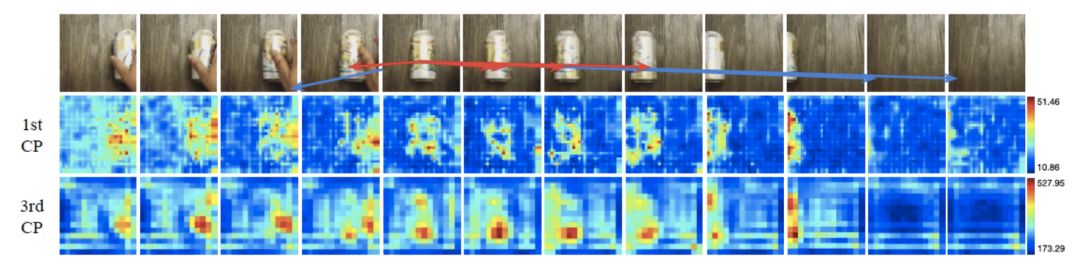
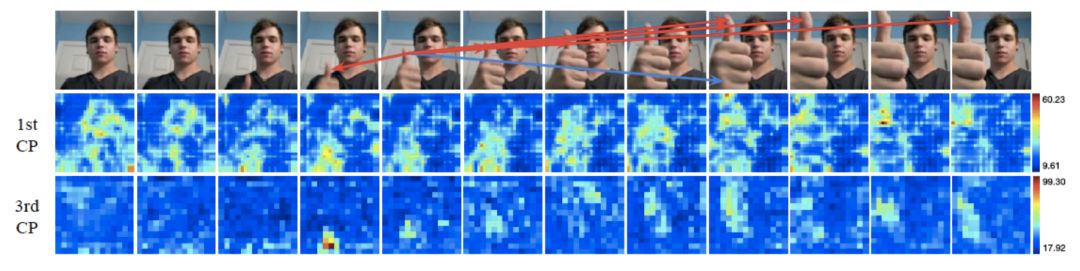
可以看到,通过语义特征的距离,CP模块可以大致找到正确的潜在对应位置,例如上图中的篮球、易拉罐和大拇指。
在上述例子中,对于错误的对应提议,CP模块也能在最大池化过程中忽略掉它们。同时,热图显示CP模块对于处于运动状态的图片部分更加敏感。
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
.png")
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




