卷积神经网络失陷,CoordConv来填坑(附代码&视频)

来源: 机器之心
本文约5632字,建议阅读10分钟。
本文讲述了卷积神经网络在涉及坐标建模等方面的缺陷,但是提出了CoordConv 作为解决方案。
[ 导读 ] 卷积神经网络拥有权重共享、局部连接和平移等变性等非常优秀的属性,使其在多种视觉任务上取得了极大成功。但在涉及坐标建模的任务上(如目标检测、图像生成等),其优势反而成为了缺陷,并潜在影响了最终的模型性能。Uber 在这项研究中揭示出问题的本质就在于卷积的平移等变性,并据此提出了对应的解决方案 CoordConv。CoordConv 解决了坐标变换问题,具有更好的泛化能力,训练速度提高 150 倍,参数比卷积少 10-100 倍,并能极大提升多种视觉任务的表现。
Uber 利用卷积神经网络解决许多方面的问题,其中就包括坐标变换。从自动驾驶汽车的设计到路标的自动检测、再到地图的绘制,Uber 都需要使用卷积网络完成坐标变换。
在深度学习领域,没有一种构想的影响力可与卷积匹敌。几乎所有机器视觉领域的最新成果都依赖堆叠大量的卷积层,并作为不同模型的基本构建块。既然这样的架构非常普遍,我们应该期望它们在一些简单的任务上表现出色,比如在一个微小的图像中绘制一个像素。
然而,事实证明,卷积神经网络在完成一些小型简单任务时也会遇到困难。我们的论文《An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution》揭示并分析了卷积神经网络在变换两种空间表征(笛卡尔空间坐标 (i, j) 和 one-hot 像素空间坐标)时的常见缺陷。结果出人意料,因为这项任务看起来如此简单,但其重要性非同一般,因为解决很多常见问题(如在图像中检测目标、训练图像生成模型、从像素中训练强化学习智能体等)都要用到此类坐标变换。结果表明,这些任务可能一直受到卷积缺陷的影响,而我们在使用之前提出的一个名为 CoordConv 的层作为解决方案时,展示了各方面的性能提升。
我们将自己的发现总结成了以下视频:
视频时长约9分钟,建议WIFI条件下阅读。
第一个发现:监督渲染对于 CNN 来说并非易事
我们来设想一个简单的任务——监督渲染,在该任务中,我们给出一个 (i, j) 位置作为网络的输入,使其生成一个 64x64 的图像,并在确定位置绘制一个正方形,如图 1a 所示,你要使用何种类型的网络来完成这个任务?
我们可以选用许多图像生成研究论文中使用的方法,使用一堆解卷积(转置卷积)层绘制这个正方形。为了测试这一想法,我们创建了一个数据集,该数据集包含一些随机放置的 9x9 的正方形和一个 64x64 的画布,如图 1b 所示。穷举所有可能的完全可见的正方形得到一个含有 3136 个样本的数据集。为评估模型的泛化能力,我们定义两种训练/测试分割:一种是均匀分割,即将所有可能的中心区域随机分为训练集和测试集,二者的比例为 8:2;另一种是象限分割,即画布被分为四个象限:集中在前三个象限中的小方块被放入训练集,最后一个象限中的小方块被放入测试集。两种数据集分割方法的分布见下图 1c:
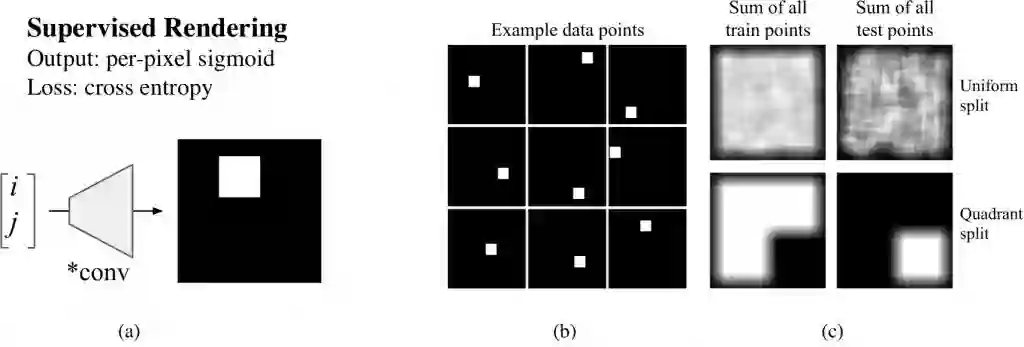
图 1:(a)监督渲染任务要求网络根据正方形的 (i, j) 位置绘制正方形。(b)为示例数据点和、(c)展示了按均匀或象限分割训练集与测试集的可视化。
我们原本以为 CNN 可以轻而易举地完成该任务,因为第一,这一任务如此简单(整个数据集可能只需要两行 Python 代码就能生成,如我们的论文所示),第二,这个数据集如此之小,我们可以轻易使用过参数化的模型。但结果表明,CNN 的表现令人大跌眼镜。即使参数高达 1M 且训练时间超过 90 分钟的模型(图 2b)也无法在均匀分割的测试集上获得 0.83 以上的 IOU,或在象限分割上获得 0.36 以上的 IOU(图 2a)。
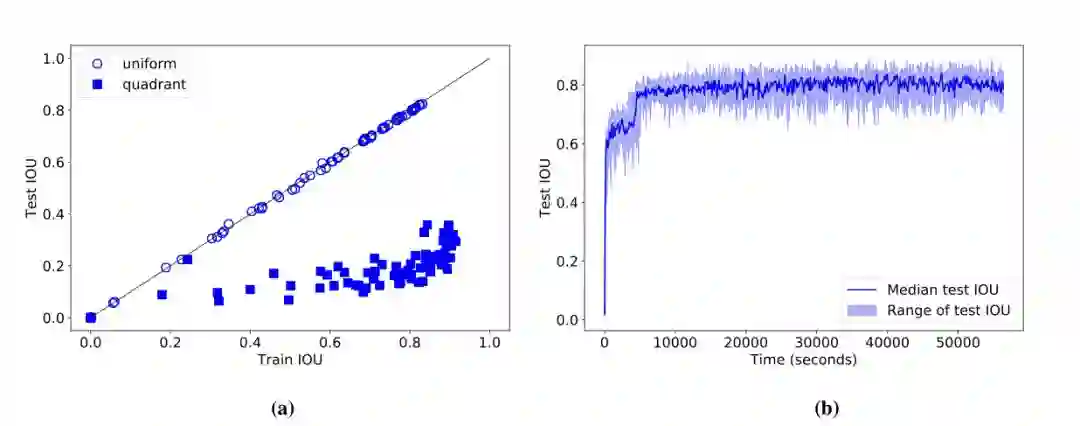
图 2:(a)在均匀分割和象限分割时的训练和测试的监督渲染任务的 IOU 结果。没有模型能达到 1.0 的 IOU,(b)训练最好的模型之一需要花 90 分钟来达到 0.8 的 IOU。
简化任务和第二个发现:CNN 很难解决有监督坐标分类
那么为什么有监督渲染如此困难?这一个问题值得我们更深入地探讨以全面了解根因所在。因此如果通过直接监督训练渲染如此困难,那么当转换为无监督学习将使问题变得更加具有挑战性,例如在相同数据上通过由鉴别器提供的损失训练生成对抗网络(GAN)。
现在我们可以缩小问题范围,以找出哪些因素给这个问题带来了挑战。我们现在要求网络生成一个简单的像素而不再是 9×9 的像素。其实给定解决单像素任务的方法,我们可以进一步使用转置卷积将这一个像素扩展到拥有较多像素的方块,这一直观想法也通过我们的实验得到证实。因此我们建立了有监督坐标分类任务(图 3a),其中数据集由成对的(i, j)坐标轴和带有单个激活像素的图像组成,如下图 3b 所示:
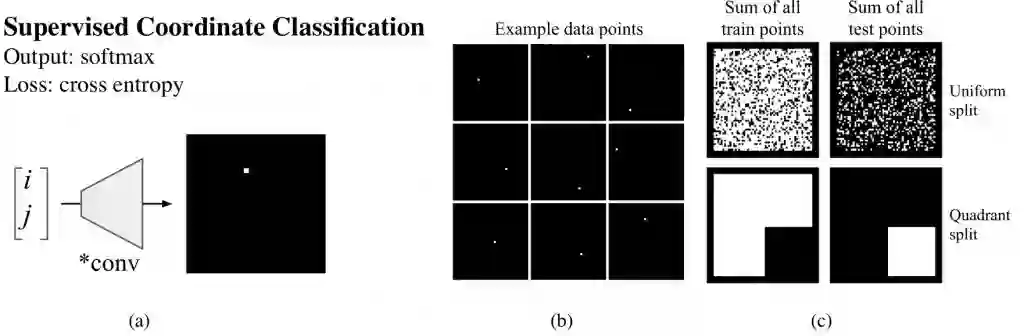
图 3:(a)有监督坐标轴分类要求网络在给定位置(i, j)的情况下生成单个像素。(b)展示了样本数据点,(c)展示了分割训练和测试集的可视化。
我们使用不同的超参数训练了非常多的网络,并观察到即使一些网络能记住训练集,但它们从没有超过 86% 的测试准确率(图 4a)。这样的准确率花了一个多小时进行训练才得到。
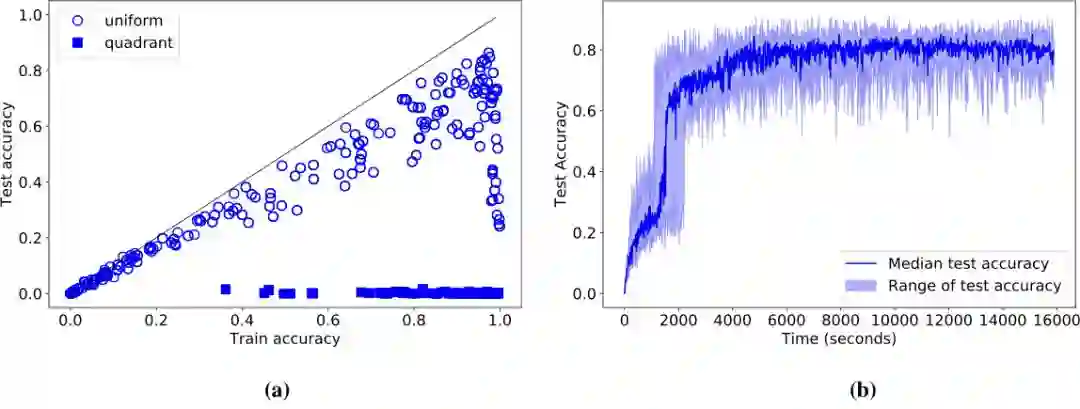
图 4:(a)有监督坐标分类任务中的训练与测试准确率,训练与测试集使用了均匀和按象限分割。虽然一些模型记住了训练集,但在使用简单的均匀分割下,它们在测试集上最高只能达到 86% 的准确率。这意味着即使只是用一个像素,卷积也不能泛化到这种情况。(b)训练这种网络达到 86% 的准确率需要花费一个多小时。
我们期望卷积能完美地处理这个问题,但实际上它并不行。为了弄清楚卷积网络到底是在做什么,我们采用已训练最好的网络并检验它的预测。
我们要求网络生成一张只有一个像素的图像,即采用 one-hot 的方式生成的位置。为了查看网络到底做了什么,我们可以放大目标像素周围的小区域。在图 5 中,目标像素以红色标出,我们展示了模型经过 SoftMax 激活与直接使用 Logits 作为预测的结果。第一个像素(顶行)是训练集中的结果,如预期那样模型有比较正确的预测,虽然在目标像素外还是存在一些概率。下一个像素(中间行偏右)在测试集中也是正确的,但因为目标的周围像素捕获了相差不大的概率,所以模型仅仅只是勉强正确。而最后的像素(底部偏右)则是完全错误的。这是非常令人惊讶的,因为作为 80/20 的分割结果,几乎所有测试像素都围绕着训练像素。
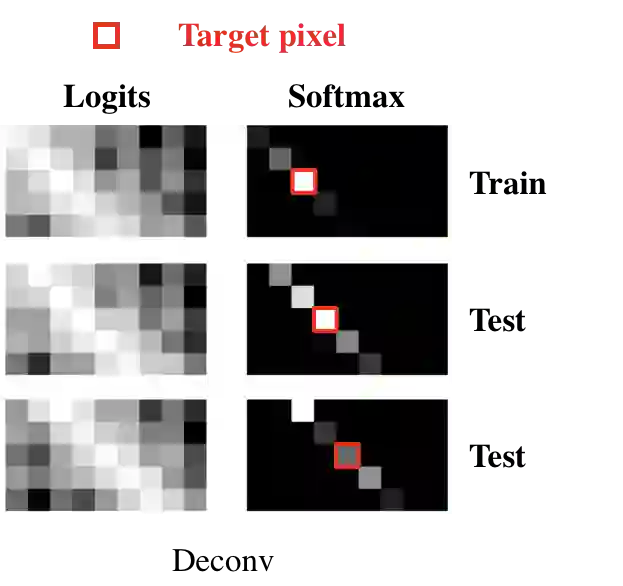
图 5:模型在较少相邻像素上的预测。网络出现了过拟合现象,即训练准确率非常完美,而测试准确率最高才 86%。这极为惊人,因为几乎所有测试像素都被训练像素所围绕。此外,网络很难拟合训练集,因为除目标像素外其它像素还存在着显著的概率。
逆向任务和第三个发现:监督回归对 CNN 来说也很难
那么,在给定位置的情况下,为什么高亮显示一个像素对网络来说如此困难?是因为将信息从一个小空间扩展到较大空间比较困难吗?在逆向任务上是否会容易一些?如果我们训练卷积网络来将图像信息压缩为标量坐标——更接近普通的图像分类,会怎样?
结果发现,在监督回归任务上同样效果不佳。在图 10 中,左边的点表示正确的像素坐标,中间的点表示模型预测。抛开一些细节不说,整个模型在测试集上也表现不佳,并且明显难以预测训练集。
总之,任务类型并不重要。
看似简单的坐标转移任务在两类任务上展现卷积的问题:从笛卡尔(i, j)空间到 one-hot 像素空间以及反过来,即从 one-hot 像素空间至笛卡尔空间。即使在监督下训练,在只画一个像素的情况下,当训练样本均围绕测试样本时,卷积仍然无法学习笛卡尔空间和像素空间之间的平滑函数。并且,性能最好的卷积模型很大,充其量只能勉强工作,而且需要很长的时间来训练。
解决办法:CoordConv
结果发现,有一个简单的办法可以解决这个问题。
卷积是等变的,意味着当每个滤波器被应用于输入以产生输出时,它并不知道每个滤波器的位置。我们可以通过让滤波器了解自己的位置来帮助卷积。为此,我们在输入中添加了两个通道——一个 i 坐标,一个 j 坐标。我们将由此产生的层称为 CoordConv,如下图所示:
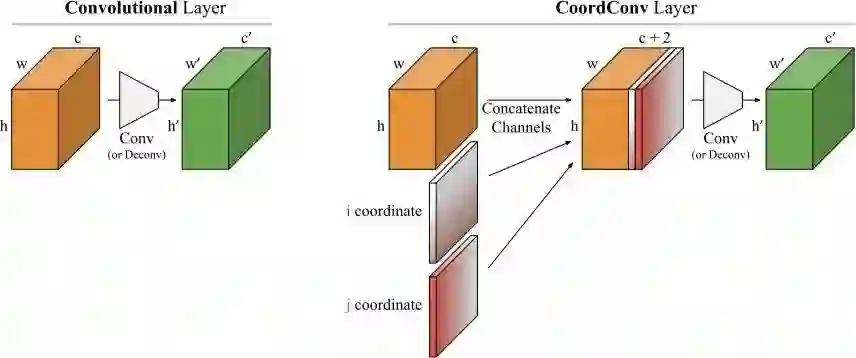
图 6:卷积层和 CoordConv 的对比。CoordConv 层将带有坐标信息的附加通道作为输入,此处指 i 坐标和 j 坐标。
提出的 CoordConv 层是对标准卷积层的简单扩展,其中卷积以坐标为条件。允许卷积滤波器观察到坐标会破坏平移等变性,这似乎是个坏主意。平移等变性不是卷积的标志性优势吗?
我们认为,卷积获得成功的重要因素有三:使用的学习参数相对较少;在现代 GPU 上计算速度快;学习了平移等变性函数。
CoordConv 层保留了前两个属性——参数较少和计算效率高,并且它的等变程度也可以学习。如果坐标中的权重学习为零,CoordConv 的表现将与标准卷积一样。另一方面,如果平移依赖对下游任务有用,那它也能学习这个。
CoordConv 涉及很多已有方法,如局部连接层、组合模式生成网络以及语言建模中使用的位置嵌入。以下展示了作者实现的核心代码,查看原论文可以了解有关此概念的更多讨论。
from tensorflow.python.layers import base
import tensorflow as tf
class AddCoords(base.Layer):
"""Add coords to a tensor"""
def __init__(self, x_dim=64, y_dim=64, with_r=False):
super(AddCoords, self).__init__()
self.x_dim = x_dim
self.y_dim = y_dim
self.with_r = with_r
def call(self, input_tensor):
"""
input_tensor: (batch, x_dim, y_dim, c)
"""
batch_size_tensor = tf.shape(input_tensor)[0]
xx_ones = tf.ones([batch_size_tensor, self.x_dim], dtype=tf.int32)
xx_ones = tf.expand_dims(xx_ones, -1)
xx_range = tf.tile(tf.expand_dims(tf.range(self.x_dim), 0), [batch_size_tensor, 1])
xx_range = tf.expand_dims(xx_range, 1)
xx_channel = tf.matmul(xx_ones, xx_range)
xx_channel = tf.expand_dims(xx_channel, -1)
yy_ones = tf.ones([batch_size_tensor, self.y_dim], dtype=tf.int32)
yy_ones = tf.expand_dims(yy_ones, 1)
yy_range = tf.tile(tf.expand_dims(tf.range(self.y_dim), 0), [batch_size_tensor, 1])
yy_range = tf.expand_dims(yy_range, -1)
yy_channel = tf.matmul(yy_range, yy_ones)
yy_channel = tf.expand_dims(yy_channel, -1)
xx_channel = tf.cast(xx_channel, ’float32’) / (self.x_dim - 1)
yy_channel = tf.cast(yy_channel, ’float32’) / (self.y_dim - 1)
xx_channel = xx_channel*2 - 1
yy_channel = yy_channel*2 - 1
ret = tf.concat([input_tensor, xx_channel, yy_channel], axis=-1)
if self.with_r:
rr = tf.sqrt( tf.square(xx_channel-0.5) + tf.square(yy_channel-0.5))
ret = tf.concat([ret, rr], axis=-1)
return ret
class CoordConv(base.Layer):
"""CoordConv layer as in the paper."""
def __init__(self, x_dim, y_dim, with_r, *args, **kwargs):
super(CoordConv, self).__init__()
self.addcoords = AddCoords(x_dim=x_dim, y_dim=y_dim, with_r=with_r)
self.conv = tf.layers.Conv2D(*args, **kwargs)
def call(self, input_tensor):
ret = self.addcoords(input_tensor)
ret = self.conv(ret)
return ret
CoordConv 解决之前的监督任务
首先我们回顾一下以前的任务,然后看 CoordConv 如何发挥作用的。
如图 7、8 所示,CoordConv 模型在监督式坐标分类和监督式渲染任务的两种训练/测试分割中都具备完美的训练和测试性能。此外,CoordConv 模型的参数数量是性能最好的标准 CNN 参数数量的 1/100 - 1/10,且训练时间仅需数秒,比后者快 150 倍(标准 CNN 训练时间需要一个多小时)。
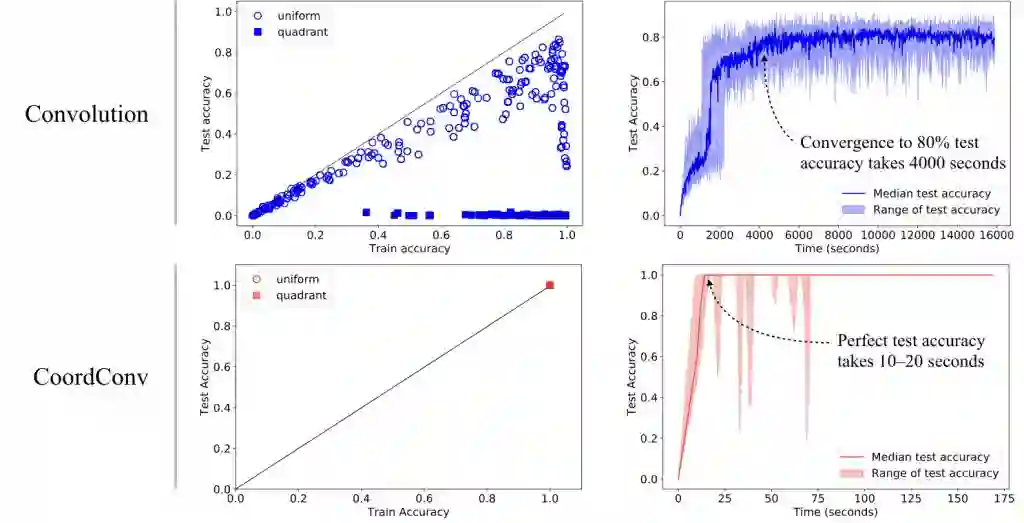
图 7:在监督式坐标分类任务上,CoordConv 在训练集和测试集上均可以快速获得完美的性能。

图 8:在监督式渲染任务中,很多 CoordConv 模型在训练集和测试集上均可以快速获得完美的性能。
为了进一步验证,图 9 展示了在绘制相邻像素时普通解卷积与 CoordConv 的性能对比。

图 9:如前所示,解卷积在监督式坐标分类任务上性能不好,而 CoordConv 获得了 100% 的训练和测试准确率。解决方案从视觉上看也简单得多。
在使用卷积来绘制像素时,我们观察到伪影和过拟合。而 CoordConv 在训练集和测试集上都取得了完美的性能。同样的事情还发生在相反的任务上。卷积在回归坐标时遇到困难,而 CoordConv 可以很好地建模函数,如图 10 所示:

图 10:卷积在建模监督式回归任务时遇到困难,而 CoordConv 可以实现很好的建模。
CoordConv 在多个领域中都能提供帮助
至此 Uber 展示了卷积网络在解决某类简单问题时的失败,并提出了 CoordConv 层形式的修正。很自然地,我们会想知道:该缺点仅存在于这个简单问题中吗?还是说这是一个在其它任务中隐匿存在的核心问题,并阻碍了性能优化?为了回答这个问题,Uber 将 CoordConv 层嵌入多种任务的网络架构中训练。以下是 Uber 研究发现的总结,在论文中有更详尽的细节。
目标检测
由于目标检测通过观察图像像素在笛卡尔坐标空间上输出边框,它们似乎天然地适合应用 CoordConv。并且研究者发现他们的直觉是正确的:在一个简单的检测空白背景中零散 MNIST 数字的问题中,他们发现,使用 CoordConv 时 Faster R-CNN 的 IOU 提升了大约 24%。
图像分类
在所有视觉任务中,当使用 CoordConv 替代卷积时,我们期望图像分类的性能变化尽可能的小,因为分类任务中更加关心「是什么」而不是在哪里。实际上当添加一个 CoordConv 层到 ResNet-50 的底层并在 ImageNet 上训练时,我们发现仅有小量的提高。
生成模型
在诸如 GAN 和 VAE 的生成式模型中,像素是从隐参数空间中「画」出来的,在理想情况下或许能编码高级概念,例如位置。直观来说,CoordConv 也可能提供帮助。使用基于 Sort-of-CLEVR 形状的简单数据集,我们训练了 GAN 和 VAE 并展示了潜在空间之间的插值。
以一个简单的生成彩色形状的任务为例。插值的视频如图 11 所示,左边是普通的 GAN,右边是 CoordConv GAN,展示了 CoordConv 如何提升了生成模型的性能。
在生成模型中,我们在潜在空间的点之间使用插值,以探究 CoordConv 的影响,这是用于评估生成模型泛化能力的常用方法。
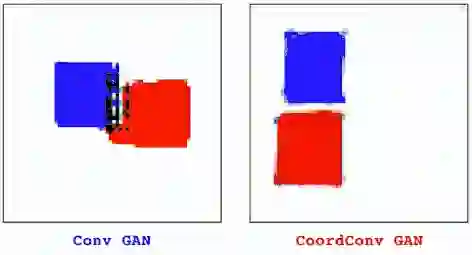
图 11:普通 GAN(左)和 CoordConv GAN(右)在潜在空间中的移动(插值)。在普通的 GAN 中,我们观察到很明显的失真(就像黏在背景上),以及少量的目标伪影。通过 CoordConv GAN,目标变得连贯,并且移动变得更加平滑。
对于左边的普通 GAN,目标的运动在起初还好。但当更仔细观察的时候,可以注意到目标的所有部分不是一起运动;视觉失真很高(就像黏在背景上),并且目标的某些部分出现褪色(消失)。当把 CoordConv 放入生成器和判别器时,移动变得更加平滑了。可以看到目标保持连贯,并平滑地移动。
训练 VAE 的时候也能发现类似的问题。通过卷积,我们发现图像中的目标部分出现了伪影,但利用 CoordConv,目标移动变得更加平滑。

图 12:普通卷积 VAE(左)和 CoordConv VAE(右)在潜在空间中的插值(移动)。在普通 VAE 中,目标会出现伪影,而在 CoordConv VAE 中它们的移动更加平滑。
当使用更大型的 GAN 来生成大规模房间场景的场景理解(LSUN)时,通过卷积我们再次观察到了僵硬的目标伪影。加入 CoordConv 后,几何变换变得更加平滑,包括平移和变形。

图 13:在 LSUN 房间数据集上训练的利用普通的卷积 GAN(左)和 CoordConv GAN(右)实现的潜在空间变换。通过卷积我们再次观察到了僵硬的目标在图像中的伪影。加入 CoordConv 后,几何变换变得更加平滑,包括平移和变形。
强化学习
强化学习是一个有趣的研究领域,CoordConv 可能对其有所帮助。我们训练了一些智能体来玩 Atari 游戏,例如吃豆人。我们认为如果一个卷积滤波器能够同时识别吃豆人且提取她在迷宫中的位置,它就有助于学习更好的策略。
我们尝试在《Distributed Prioritized Experience Replay》(Ape-X)论文实现中加入 CoordConv,但 CoordConv 并没有即刻表现出性能提升。我们也在策略梯度方法 A2C 上尝试了 CoordConv,有助于提升结果的时候比较多。这可能反映了学习显性策略和学习 Q 函数两种方法之间的不同。在测试的 9 种游戏中,使用 CoordConv 的 A2C 在 6 种游戏上的表现优于常规卷积网络(训练更快或得分更高)。也如同预期的那样,我们注意到 CoordConv 在吃豆人游戏上的得分有极大的提升。在两种游戏上,CoordConv 表现差不多。在一种游戏上,CoordConv 表现变得更差。整体来说,这些结果表明,CoordConv 对强化学习非常有帮助。

图 14:使用 A2C 在 Atari 游戏上训练的结果。在 9 个游戏中,(a)CoordCov 改进了卷积在 6 种游戏上的表现,(b)在 2 种游戏上的表现差别不大,(c)在一种任务上结果变的更差。
展望
本文证明了 CNN 不能对坐标变换任务进行建模,且我们以 CoordConv 层的形式做了简单的修整。我们的结果表明,加入这些层后可以极大地提升网络在大量应用中的表现。未来研究将进一步评估 CoordConv 在大规模数据集中的优势,探索其在检测任务、语言任务、视频预测,以及配合空间 transformer 网络、前沿生成模型时的影响。
原文链接:https://eng.uber.com/coordconv/





