终于!TensorFlow引入了动态图机制Eager Execution
选自Google Brain
作者:Asim Shankar & Wolff Dobson
机器之心编译
PyTorch 的动态图一直是 TensorFlow 用户求之不得的功能,谷歌也一直试图在 TensorFlow 中实现类似的功能。最近,Google Brain 团队发布了 Eager Execution,一个由运行定义的新接口,让 TensorFlow 开发变得简单许多。在工具推出后,谷歌开发人员 Yaroslav Bulatov 对它的性能与 PyTorch 做了横向对比。
今天,我们为 TensorFlow 引入了「Eager Execution」,它是一个命令式、由运行定义的接口,一旦从 Python 被调用,其操作立即被执行。这使得入门 TensorFlow 变的更简单,也使研发更直观。
Eager Execution 的优点如下:
快速调试即刻的运行错误并通过 Python 工具进行整合
借助易于使用的 Python 控制流支持动态模型
为自定义和高阶梯度提供强大支持
适用于几乎所有可用的 TensorFlow 运算
Eager Execution 现在处于试用阶段,因此我们希望得到来自社区的反馈,指导我们的方向。
为了更好地理解 Eager Execution,下面让我们看一些代码。它很技术,熟悉 TensorFlow 会有所帮助。
使用 Eager Execution
当你启动 Eager Execution 时,运算会即刻执行,无需 Session.run() 就可以把它们的值返回到 Python。比如,要想使两个矩阵相乘,我们这样写代码:
import tensorflow as tf
import tensorflow.contrib.eager as tfe
tfe.enable_eager_execution()
x = [[2.]]
m = tf.matmul(x, x)
使用 print 或者 Python 调试器检查中间结果非常直接。
print(m)
# The 1x1 matrix [[4.]]
动态模型的构建可使用 Python 控制流。下面是使用 TensorFlow 算术操作的考拉兹猜想(Collatz conjecture)的一个示例:
a = tf.constant(12)
counter = 0
while not tf.equal(a, 1):
if tf.equal(a % 2, 0):
a = a / 2
else:
a = 3 * a + 1
print(a)
这里,tf.constant(12) 张量对象的使用将把所有数学运算提升为张量运算,从而所有的返回值将是张量。
梯度
多数 TensorFlow 用户对自动微分(automatic differentiation)很感兴趣。因为每次调用都有可能出现不同的运算,可以理解为我们把所有的正向运算录到「磁带」上,然后在计算梯度时进行「倒放」。梯度计算完成后,「磁带」就没用了。
如果你熟悉 autograd 包,我们提供的 API 与之非常类似。例如:
def square(x):
return tf.multiply(x, x)
grad = tfe.gradients_function(square)
print(square(3.)) # [9.]
print(grad(3.)) # [6.]
gradients_function 的调用使用一个 Python 函数 square() 作为参数,然后返回 Python callable,用于计算输入的 square() 偏导数。因此,为了得到输入为 3.0 时的 square() 导数,激活 grad(3.0),也就是 6。
同样的 gradient_function 调用可用于计算 square() 的二阶导数。
gradgrad = tfe.gradients_function(lambda x: grad(x)[0])
print(gradgrad(3.)) # [2.]
如前所述,控制流(control flow)会引起不同的运算,下面是一个示例:
def abs(x):
return x if x > 0. else -x
grad = tfe.gradients_function(abs)
print(grad(2.0)) # [1.]
print(grad(-2.0)) # [-1.]
自定义梯度
用户或许想为运算或函数自定义梯度。这可能有用,原因之一是它为一系列运算提供了更高效、数值更稳定的梯度。
下面的示例使用了自定义梯度。我们先来看函数 log(1 + e^x),它通常用于计算交叉熵和 log 似然。
def log1pexp(x):
return tf.log(1 + tf.exp(x))
grad_log1pexp = tfe.gradients_function(log1pexp)
# The gradient computation works fine at x = 0.
print(grad_log1pexp(0.))
# [0.5]
# However it returns a `nan` at x = 100 due to numerical instability.
print(grad_log1pexp(100.))
# [nan]
我们可以将自定义梯度应用于上述函数,简化梯度表达式。注意下面的梯度函数实现重用了前向传导中计算的 (tf.exp(x)),避免冗余计算,从而提高梯度计算的效率。
@tfe.custom_gradient
def log1pexp(x):
e = tf.exp(x)
def grad(dy):
return dy * (1 - 1 / (1 + e))
return tf.log(1 + e), grad
grad_log1pexp = tfe.gradients_function(log1pexp)
# Gradient at x = 0 works as before.
print(grad_log1pexp(0.))
# [0.5]
# And now gradient computation at x=100 works as well.
print(grad_log1pexp(100.))
# [1.0]
建立模型
模型可以分成几类。此处我们要提的模型可以通过创建一个简单的两层网络对标准的 MNIST 手写数字进行分类。
class MNISTModel(tfe.Network):
def __init__(self):
super(MNISTModel, self).__init__()
self.layer1 = self.track_layer(tf.layers.Dense(units=10))
self.layer2 = self.track_layer(tf.layers.Dense(units=10))
def call(self, input):
"""Actually runs the model."""
result = self.layer1(input)
result = self.layer2(result)
return result
我们推荐使用 tf.layers 中的类别(而非函数),这是因为它们创建并包含了模型参数(变量,variables)。变量的有效期和层对象的有效期紧密相关,因此需要对它们进行追踪。
为什么要使用 tfe.Network?一个网络包含了多个层,是 tf.layer.Layer 本身,允许将 Network 的对象嵌入到其它 Network 的对象中。它还包含能够协助检查、保存和修复的工具。
即使没有训练模型,我们也可以命令式地调用它并检查输出:
# Let's make up a blank input image
model = MNISTModel()
batch = tf.zeros([1, 1, 784])
print(batch.shape)
# (1, 1, 784)
result = model(batch)
print(result)
# tf.Tensor([[[ 0. 0., ...., 0.]]], shape=(1, 1, 10), dtype=float32)
注意我们在这里不需要任何的占位符或会话(session)。一旦数据被输入,层的参数就被设定好了。
训练任何模型都需要定义一个损失函数,计算梯度,并使用一个优化器更新参数。首先定义一个损失函数:
def loss_function(model, x, y):
y_ = model(x)
return tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y_)
然后是训练的循环过程:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
for (x, y) in tfe.Iterator(dataset):
grads = tfe.implicit_gradients(loss_function)(model, x, y)
optimizer.apply_gradients(grads)
implicit_gradients() 计算损失函数关于计算使用的所有 TensorFlow 变量的导数。
我们可以按往常使用 TensorFlow 的方式将计算转移到 GPU 上:
with tf.device("/gpu:0"):
for (x, y) in tfe.Iterator(dataset):
optimizer.minimize(lambda: loss_function(model, x, y))
(注意:我们简化然后保存损失损失函数并直接调用 optimizer.minimize,但你也可以使用上面的 apply_gradients() 方法,它们是等价的。)
使用 Eager 和 Graphs
Eager execution 使开发和调试互动性更强,但是 TensorFlow graph 在分布式训练、性能优化和生产部署中也有很多优势。
启用 eager execution 时,执行运算的代码还可以构建一个描述 eager execution 未启用时的计算图。为了将模型转换成图,只需要在 eager execution 未启用的 Python session 中运行同样的代码。示例:https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/mnist。我们可以从检查点保存和修复模型变量值,这允许我们在 eager(命令式)和 graph(声明式)编程之间轻松转换。这样,启用 eager execution 开发出的模型可以轻松导出到生产部署中。
在不久的将来,我们将提供工具,可以选择性地将模型的某些部分转换成 graph。用这种方式,你就可以融合部分计算(如自定义 RNN 细胞的内部)实现高性能,同时还能保持 eager execution 的灵活性和可读性。
如何改写我的代码?
Eager execution 的使用方法对现有 TensorFlow 用户来说应是直观的。目前只有少量针对 eager 的 API;大多数现有的 API 和运算需要和启用的 eager 一起工作。请记住以下内容:
一般对于 TensorFlow,我们建议如果你还没有从排队切换到使用 tf.data 进行输入处理,请抓紧做。它更容易使用,也更快。查看这篇博文(https://developers.googleblog.com/2017/09/introducing-tensorflow-datasets.html)和文档页(https://www.tensorflow.org/programmers_guide/datasets)会有所帮助。
使用目标导向的层(比如 tf.layer.Conv2D() 或者 Keras 层),它们可以直接存储变量。
你可以为大多数模型写代码,这对 eager execution 和图构建同样有效。也有一些例外,比如动态模型使用 Python 控制流改变基于输入的计算。
一旦调用 tfe.enable_eager_execution(),它不可被关掉。为了获得图行为,需要建立一个新的 Python session。
开始使用
这只是预发布,还不完善。如果你想现在就开始使用,那么:
安装 TensorFlow 的 nightly 版本(https://github.com/tensorflow/tensorflow#installation)
查看 README(包括 known issues),地址:https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/README.md
从 eager execution 用户指南(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/g3doc/guide.md)中获取详细的指导
在 GitHub 中查看 eager 示例(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples)
及时查看变更日志(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/README.md#changelog)查看是否有更新
性能测试
Eager Execution 目前仅处于开发的前期,它的性能究竟如何?Google Brain 的工程师 Yaroslav Bulatov 对这一新工具做出了评测。
TensorFlow 此前最令人诟病的问题就是它必须将计算定义为静态图。
我们在谷歌大脑的工作之一就是解决这类需求,并最终以命令式版本开源。但是这依赖于私有/不稳定的 API,而且这些 API 的维护成本会越来越高昂。
幸运的是,PyTorch 满足了研究员的需求,并且如今的 TensorFlow 也官方支持执行模式而不需要定义图。
目前,Eager Execution 仍在积极开发中,但在最近发布的可用版本非常有用,我们可以试用一下:
pip install tf-nightly-gpu
python
from tensorflow.contrib.eager.python import tfe
tfe.enable_eager_execution()
a = tf.random_uniform((10,))
b = tf.random_uniform((10,))
for i in range(100):
a = a*a
if a[0]>b[0]:
break
print(i)
请注意,此操作并不需要处理图,Session 就可以立即执行。若想应用 GPU 加速,请先将 tensor 拷贝至指定设备。
a = a.gpu() # copies tensor to default GPU (GPU0)
a = a.gpu(0) # copies tensor to GPU0
a = a.gpu(1) # copies tensor to GPU1
a = a.cpu() # copies tensor back to CPU
端口命令代码
你可以将一个已有的 numpy/pytorch/matlab 的命令式代码重写成正确的 API 调用。例如,
torch.sum -> tf.reduce_sum」
array.T -> tf.transpose(array) 等
我已使用 PyTorch 实现的 l-BFGS 作为练习,第一次在 GPU 上并行跑两个实验时(PyTorch & Eager),我得到前 8 位小数相同的结果。这使我大吃一惊,前所未闻。

使用已有的基于图的代码
如果你的代码不依赖于特定的 API,例如 graph_editor,你可以使用现有的代码并在 eager execution 模式下运行。
还有一个实验性的函数「graph_callable」,可以将任意 tensorflow 子图作为一个可以调用的函数。它仍然处于开发阶段,但我能得到一个有效的例子来说明,该例子将 tensorflow /models 中的 resnet_model 包装成一个 graph_callable。下面是一个随机批大小训练这个模型的例子。
一旦该功能上线,它应该有助于提高程序性能,具体可参考下文的性能部分。
拓展了梯度
原始 tf.gradients_function 的新衍生版本反映了autograd 的梯度。你可以调用在一个已有函数内调用「gradients_function」N 次获得 N 阶导数,即
# expensive way to compute factorial of n
def factorial(n):
def f(x):
return tf.pow(x, n)
for i in range(n):
f = tfe.gradients_function(f)
return f(1.)
还有一个原始「custom_gradient」函数,这使得创建自定义梯度更容易。例如,假设我们想要平方函数,但在后向传播时增加了噪声。
@tfe.custom_gradient
def noisy_square(x):
def grad(b):
true_grad = 2*b*x
return true_grad+tf.random_uniform(())
return (x*x), grad
grad = tfe.gradients_function(noisy_square)
x = 2.
points = []
for i in range(20):
x -= .9*grad(x)[0]
print(x, loss(x))
效果如下:
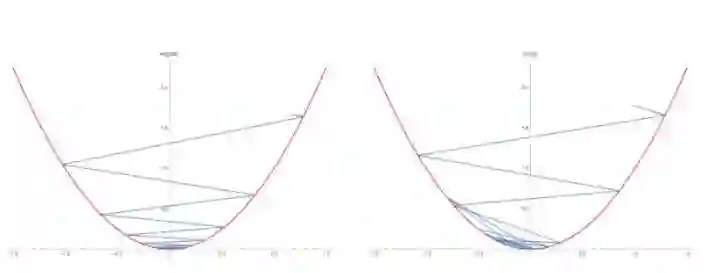
你会看到版本二收敛更慢,但是一旦收敛,它的泛化能力更好。
这种梯度修正对于实现如 KFAC 的高级优化算法时十分有用。想想我早期所讲,KFAC 在简单网络中相当于激活函数和反向传播值白化的梯度下降。
这就可以理解为梯度在其两边乘上了白化的矩阵
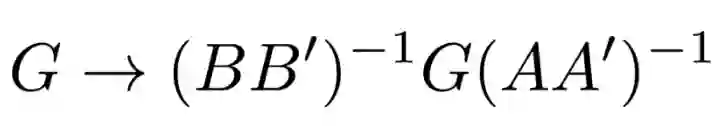
假设你已经将这些矩阵保存为 m1,m2,那么你自定义的乘操作可以是这样的:
@tfe.custom_gradient
def kfac_matmul(W, A):
def grad(B):
true_grad1 = B @ tf.transpose(A)
true_grad2 = tf.transpose(W) @ B
return [m1 @ true_grad1 @ m2, true_grad2]
return W @ A, grad
注意,true_grad1, true_grad2 函数是乘法操作的反向传播实现,请参考 Mike Giles 的第 4 页「An extended collection of matrix derivative results for forward and reverse mode algorithmic differentiation」(https://people.maths.ox.ac.uk/gilesm/files/NA-08-01.pdf)
你可以通过使用 kfac_matmul 替代采用梯度下降算法恢复原来的 kfac,或者你可以尝试新的变种方法,利用动量和 Adam。
这里(https://gist.github.com/yaroslavvb/eb02440272ddcbea549f1e47e4023376)有一个端到端的运行在 Eager execution 模式下的 KFAC 样例。
性能
Eager Execution 模式使你的程序执行慢一点或慢很多的程度取决于你的计算高运算强度的卷积还是矩阵相乘。
做纯矩阵乘法(超过 1 毫秒的时间)是没有太大的差别,无论你用 tensorflow 快速模式,pytorch 或 tensorflow 经典模式。
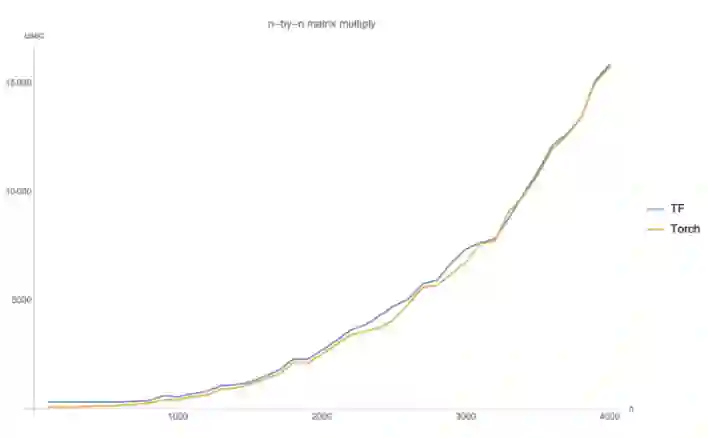
另一方面,端到端的例子更易受影响。
在测试中,当运行环境设置为 O(n^(1.5)) 操作,如 matmul/conv 时,Eager Execution 的速度要比 PyTorch 慢 20%,或者在大量 O(n) 操作如矢量添加的例子中,比 PyTorch 慢 2-5 倍。
作为一个简单的例子,我们使用吴恩达提出的 UFLDL 来训练 MNIST 自编码器。在批尺寸=60k,I-BFGS 的 history=5 时,大量的计算效能都被花在了自编码器正向传播上,Eager 的版本要比 PyTorch 慢 1.4 倍。
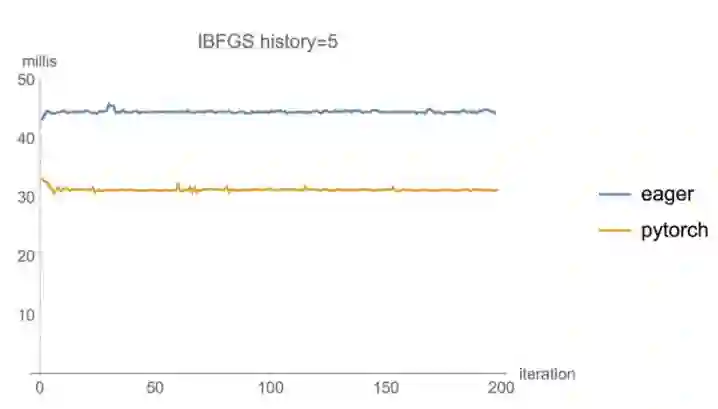
在批尺寸为 60k,I-BFGS 的 history=100 的设置下,两个回环在每一步 I-BFGS(点积和向量增加)中执行「两步递归」,Eager 版本的模型速度降低了 2.5 倍,而 PyTorch 仅受轻微影响。
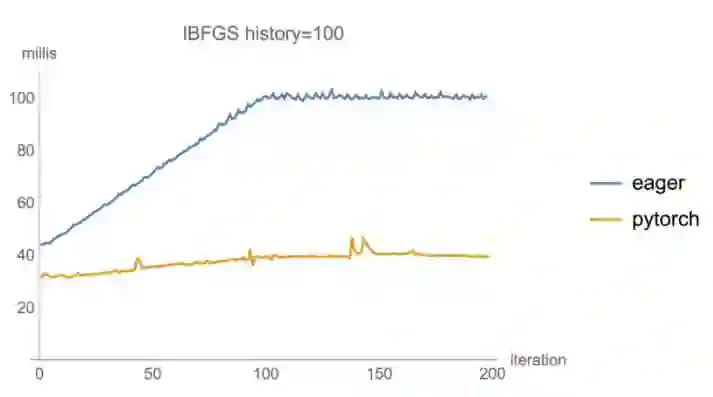
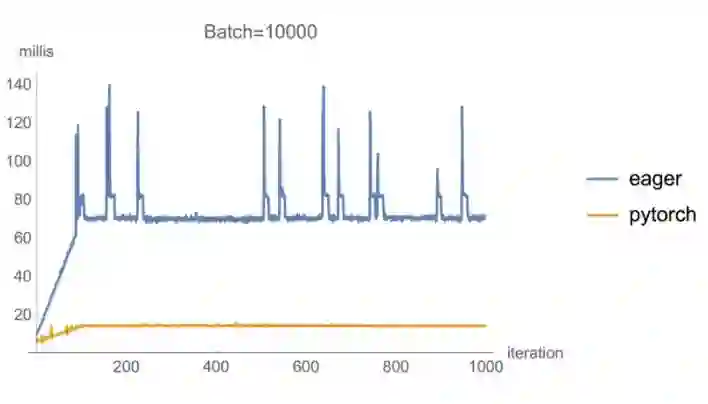
最后,如果我们将批尺寸减少到 10k,我们可以看到每次迭代的速度都要慢 5 倍,偶尔甚至会慢 10 倍,这可能是因为垃圾回收策略造成的。
结论
虽然目前 Eager Execution 的表现还不够强大,但这种执行模式可以让原型设计变得容易很多。对于在 TensorFlow 中构建新计算任务的开发者而言,这种方式必将很快成为主流。
原文地址:
https://research.googleblog.com/2017/10/eager-execution-imperative-define-by.html
https://medium.com/@yaroslavvb/tensorflow-meets-pytorch-with-eager-mode-714cce161e6c
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



