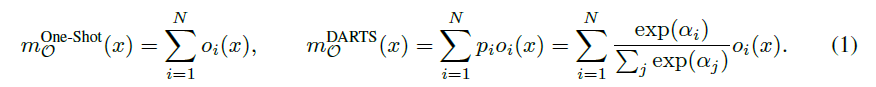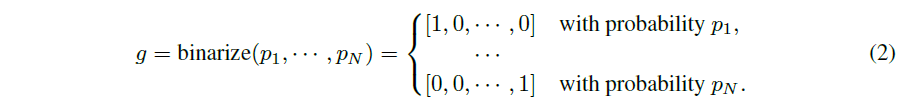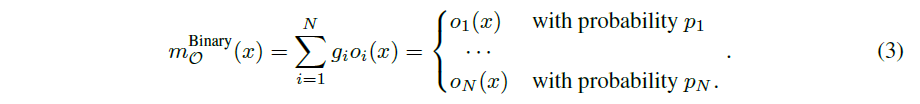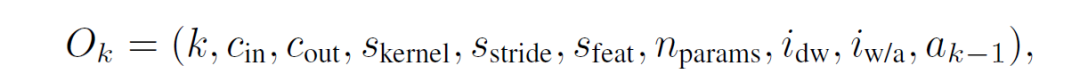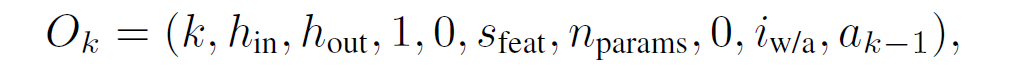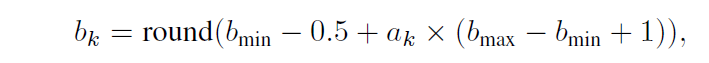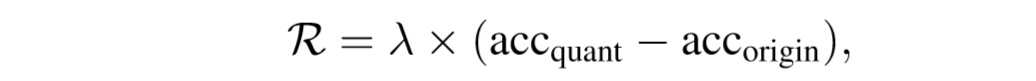MIT 韩松组一直走在深度模型剪枝,压缩方向的前沿。最近他们也开始尝试运用 NAS 神经框架搜索技术来推进研究。
第一篇是利用 NAS 技术直接为特定的硬件在特定的任务上搜索最优的网络框架结构。
第二篇则是利用强化学习自动寻找在特定 latency 标准上精度最好的量化神经网络结构,它分别为网络的每一层搜索不同 bit 的权值和激活,得到一个经过优化的混合精度模型。两篇文章的相同之处在于,都直接从特定的硬件获得反馈信息,如 latency,energy 和 storage,而不是使用代理信息,再利用这些信息直接优化神经网络架构 (或量化 bit 数) 搜索算法。这也许会成为工业界未来的新范式。
PROXYLESSNAS: DIRECT NEURAL ARCHITECTURE SEARCH ON TARGET TASK AND HARDWARE
2018 年 12 月份在 arxiv 上发布 v1 版本时,之心就已经出过一篇本论文的讲解啦,2019 年 2 月份作者上传了 v2 版本,最终该论文收录于 ICLR2019。相比于 v1 版本,v2 版本在 4.2 节中增加了部分 CNN 架构和多目标 NAS 任务的文献引用,在附录部分增加了基于梯度的算法的实现说明。2019 年 8 月 10 日,训练代码新鲜出炉,已上传至 Github 中。让我们再来重温一下韩松组所做的工作吧~
一、NAS 是什么?此前的研究有哪些待解决的问题?
神经结构搜索 (NAS) 是一种自动化设计人工神经网络 (ANN) 的技术,被用于设计与手工设计的网络性能相同甚至更优的网络。目前 NAS 已经在图像识别和语言模型等任务的自动化神经网络结构设计中取得了显著成功。
但传统的 NAS 算法需要消耗极高的计算资源,通常需要在单个实验中训练数千个网络模型进行学习从而完成目标任务。虽然在小型数据集上有较好表现,但直接在大规模任务(如 ImageNet)上自动设计体系结构仍旧非常困难。
随后的 NAS 算法广泛采用了在代理任务 (训练更少的 epoch,使用更小的数据集,学习更少的 block) 上搜索 building block 的思想。将表现最好的 block 堆叠起来,然后迁移到大规模目标任务中。但是在代理任务上优化的体系结构无法保证在目标任务上是最优的,尤其是在考虑到延迟等硬件指标时。并且,为了实现可迁移性,这种方法仅搜索少数结构模式,重复堆叠相同的结构,限制了 block 的多样性,从而对性能造成了影响。
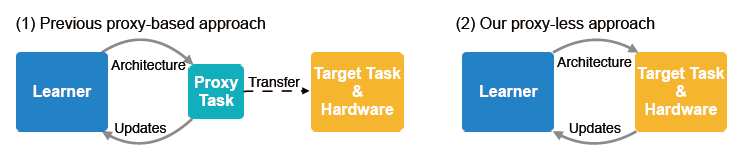
![]()
图 1 :基于 proxy 的方法和本文 proxyless 方法对比示意图
二、ProxylessNAS 是什么?怎样解决上述问题?
ProxylessNAS,顾名思义,是一种不通过代理任务,而直接从目标任务和硬件上学习网络结构的神经结构搜索方法。它没有先前 NAS 工作中重复 block 的限制,允许学习和指定所有的 block。
为了减少结构搜索的 GPU 小时数,作者将 NAS 制定为一个路径级修剪过程,直接训练一个包含所有候选路径的过参数化网络。在训练期间,明确地引入结构参数以学习哪些路径是冗余的,而在训练结束时修剪这些冗余路径以获得紧凑的优化结构。通过这种方式,只需要在结构搜索期间训练单个网络而无需任何元控制器,从而减少搜索花费的 GPU 小时数。
用 N(e,...,en) 表示神经网络,e_i 表示有向无环图(DAG)中的一条边。让 O={o_i} 作为 N 的候选操作集(如卷积,池化等)。为了使得搜索空间包括任何结构,作者并没有将每条边设置成确定的操作,而是让每条边拥有 N 条可选择的路径,可以执行不同的操作,即为 Mo。因此,过参数化网络就可以表示为 N(e=mo~1,...,e_n=mo~n)
给定输入 x,混合操作 mo 的输出是基于 N 条路径 d 输出得到的。与本文方法最相关的 one-shot 方法和 DARTS 方法都是通过将 NAS 建模为一个过参数化网络的单一训练过程,去除了元控制器 (或超网络),该网络由所有候选路径组成。在 One-Shot 方法中,mo(x) 是 {o_i(x)} 的总和,在 DARTS 中 mo(x) 是 {o_i(x)} 的加权求和,权重是由在 N 个实值结构参数 {α_i} 上运用 softmax 计算得到的。
![]()
如等式 (1),当训练仅包含一条路径的模型时,N 条路径的输出特征图都被存储在内存中进行计算,因此,相比训练一个紧凑的模型,One-shot 方法和 DARTS 方法需要消耗 N 倍的 GPU 内存和 GPU 小时数。如果只是简单的包括所有候选路径,会导致 GPU 内存爆炸,因为内存消耗会随选择的数量线性增长,在大规模数据集上,这就很容易超出硬件设计的最大内存限制。
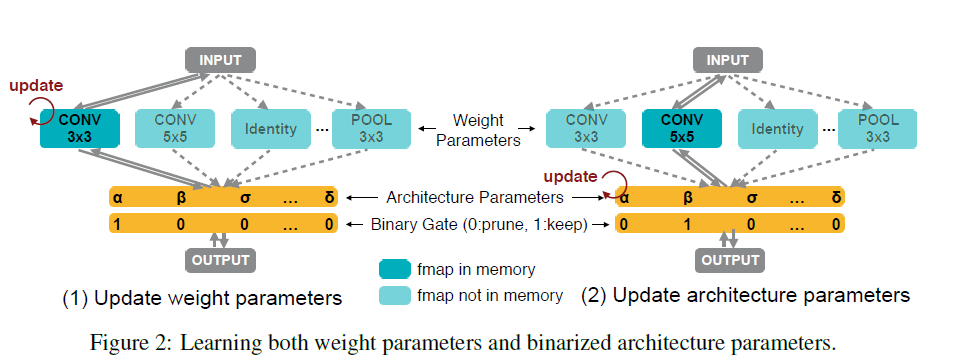
为了减少所需消耗的 GPU 内存,作者将网络结构参数二值化,并强制在运行时仅激活一条路径,这就将所需内存减少到训练常规模型的相同级别。作者引入了 N 个实值结构参数 {α_i},把实值路径权重转换成了二进制门 (binary gates),即式 (2) 中的 g。
![]()
基于 g,混合操作的输出就可以通过 (3) 进行计算:
![]()
如式 (3) 和图(2)所示,通过使用 binary gates 而不是实值路径权重,只激活一条路径训练过参数化网络所需的内存量即可减少到和训练紧凑模型相同级别。此外,作者基于 BinaryConnect 提出了一种基于梯度的方法来训练这些二值化结构参数。在训练权重参数时,首先对每批输入数据冻结结构参数,根据式 (2) 随机采样二进制门。然后通过训练集上的标准梯度下降更新激活路径的权值参数 (图 2 左)。当训练结构参数时,将权值参数冻结,然后重置二进制门并更新验证集上的结构参数 (图 2 右)。这两个更新步骤交替执行。一旦完成了体系结构参数的训练,我们就可以通过修剪冗余路径得到紧凑的网络结构。在这项工作中,作者简单地选择路径权值最高的路径。
![]()
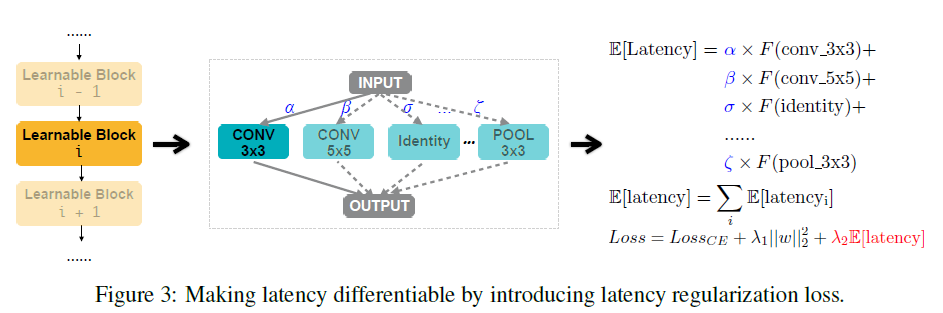
为了针对硬件平台设计专用的高效网络结构,作者将神经网络的硬件性能(如延迟)纳入到优化目标中。延迟(Latency)是一项不可忽视的重要硬件指标,然而它是不可微的。为了解决这一问题,作者将网络延迟建模为连续函数并将其优化为正则化损失,如图 3 所示。此外,作者还提出了一种基于 REINFORCE 的算法作为处理硬件指标的一种替代策略。
![]()
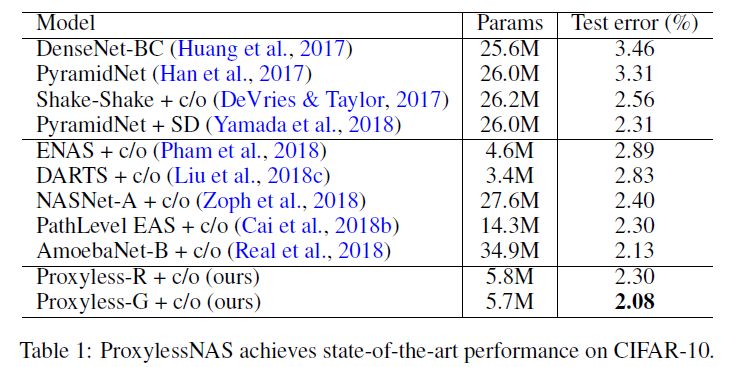
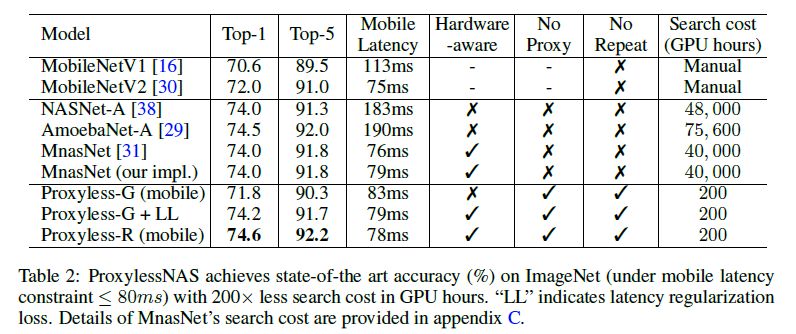
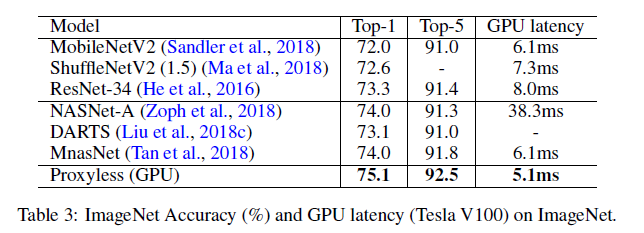
作者分别在 CIFAR-10 和 ImageNet 上进行了实验。在 CIFAR-10 上,作者的模型只有 5.7M 参数, 达到 2.08%的测试误差,与之前最优的模型 AmoebaNet-B 相比,仅使用了六分之一的参数量达到了更好的结果。在 ImageNet 上,作者的模型实现了 75.1%的 top-1 精度,比 MobileNetV2 高 3.1%,同时速度快 1.2 倍。在 74.5% 的 top-1 准确率下, ProxylessNAS 的手机实测速度是约是 MobileNetV2 的 1.8 倍。结果展示如下:
![]()
![]()
![]()
四、如何使用 ProxylessNAS,来愉快的动手吧!
Github:_https://github.com/MIT-HAN-LAB/ProxylessNAS_ (https://github.com/MIT-HAN-LAB/ProxylessNAS)
作者发布了 PyTorch 和 Tensorflow 的预训练模型,并且最新公布了 ProxylessNAS 的训练代码。
克隆 github 项目后,可下载并使用作者发布的预训练模型。
from proxyless_nas import proxyless_cpu, proxyless_gpu, proxyless_mobile, proxyless_mobile_14
net = proxyless_cpu(pretrained=True)
from proxyless_nas_tensorflow import proxyless_cpu, proxyless_gpu, proxyless_mobile, proxyless_mobile_14
tf_net = proxyless_cpu(pretrained=True)
如果使用上述脚本下载预训练模型失败,可以从 Google Drive
https://drive.google.com/drive/folders/1qIaDsT95dKgrgaJk-KOMu6v9NLROv2tz?usp=sharing
上进行手动下载,并放置于路径「$HOME/.torch/proxyless_nas/"下。
进入到该 github 项目的根目录,运行对应命令进行评估
python eval.py --path 'Your path to imagent' --arch proxyless_cpu
python eval_tf.py --path 'Your path to imagent' --arch proxyless_cpu
作者的实现是基于 PyTorch(> = 1.0)和 Horovod(0.15.4),通过以下脚本可以复现论文中的准确率。其中 arch 的选择可以有: proxyless_cpu,proxyless_gpu,proxyless_mobile,proxyless_mobile_14
mpirun -np 8 \
-H localhost:8\
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
python main.py --arch proxyless_gpu --fp16-allreduce \
--color-jitter --label-smoothing --epochs 300
HAQ: Hardware-Aware Automated Quantization with Mixed Precision
论文链接:https://arxiv.org/pdf/1811.08886.pdf
本篇论文是 CVPR2019 Oral 论文,附 Youtube 视频录像: https://www.youtube.com/watch?v=25pIprMDEgc
模型量化是对深度神经网络(DNN)进行压缩和加速的一种广泛使用的技术。在许多实时机器学习应用(如自动驾驶)中,DNN 受到延迟、能量和模型大小的严格限制。为了提高硬件的效率,许多研究者都提出将权值和激活值量化到低精度。
![]()
随着混合精度硬件的出现,需要提出混合精度量化方法。
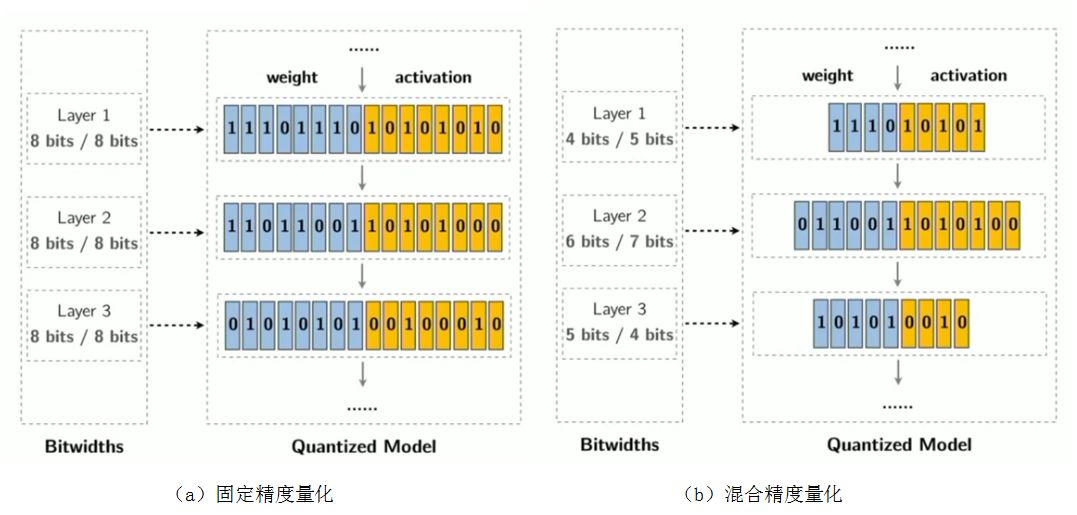
在传统的量化方法中,DNN 所有层的权重和激活值使用固定数目的 bit 位,如图 1(a) 所示,固定精度量化为每层的权重和激活值都分配了 8bit。但是由于不同层有不同的冗余,并且在硬件上表现不同,为每层分配相同数量的 bit 位并不是最优的,因此需要对不同层使用混合精度量化,如图 1(b) 所示。
在 18 年 8 月 NVIDIA 推出了支持 1-bit,4-bit,8-bit 和 16-bit 精度操作的图灵 GPU 架构;在 18 年 9 月,苹果发布了支持神经网络推理混合精度的 A12Bionic 芯片;除了工业界,学术界也开始研究 bit 级的灵活硬件设计:BISMO 提出了位串行乘法器以支持 1-8bits 的乘法;BitFusion 支持 2,4,8,16bits 的乘法。随着这些混合精度硬件及算法的出现,急需提出混合精度量化方法!
如何确定在不同的硬件加速器上每一层的权重和激活的位宽。
这些硬件加速器的出现是为了进一步提高计算效率,然而也为寻找每层的最佳位宽提出了巨大挑战:它需要领域专家 (既有机器学习知识又有硬件体系结构知识) 用基于规则的启发式算法巧妙地探索巨大的设计空间,并且在延迟、能耗、模型尺寸等方面进行权衡。例如:我们应该在提取低层特征的第一层和计算最终输出的最后一层保留更多的 bit;
此外,我们应该在卷积层使用更多的 bit,而不是在全连接层,因为从经验上来说,卷积层更敏感。随着神经网络变得越来越深,搜索空间呈指数级增长,这使得依赖手工制作的量化策略变得不可行。因此,这些基于规则的量化策略通常是次优的,不能从一个模型推广到另一个模型。如果我们有 M 个不同的神经网络模型,每一个模型有 N 层,在 H 个不同的硬件平台上,可能的解决方案就有 O(H×M×8^(2N))。如何简化这一步骤,自动化探索不同硬件加速器上每一层权重和激活的位宽,是迫切需要的解决的!
如何在硬件上优化给定模型的延迟和能量消耗。
一种被广泛采用的方法是依赖一些 Proxy 信号 (FLOPs,内存引用的数量)。然而,由于不同的硬件表现非常不同,模型在硬件上的性能并不总是能够由这些 Proxy 信号准确地反映出来。因此,直接涉及硬件体系结构,在硬件上优化给定模型的延迟和能量消耗就显得尤为重要!
作者提出了硬件感知自动量化(HAQ)框架(如图 2 所示),将量化任务建模为强化学习问题,自动搜索量化策略。通过深度确定性策略梯度 (DDPG) 来监督 agent,依赖于 actor-critic 模型,在给定计算资源量(延迟,能耗和模型尺寸)的情况下,agent 依赖硬件加速器的直接反馈(延迟和能耗),而不是依赖 proxy 信号(如 FLOPs 和模型尺寸),按层处理给定的神经网络,接收相应信息作为 observation,给出每个层的 action:即每层的 bits,并将准确率作为 reward 反馈给 critic,从而确定最佳位宽分配策略。
Agent 将按层处理给定的神经网络。对于每个层,agent 接收层配置和统计信息作为 observation,用一个十维特征向量 O_k 表示,如果第 k 层是卷积层,那么 O_k 是:
![]()
![]()
对于 O_k 中的每个维度,作者都归一化到了 [0,1],使得它们的规模相同。
根据 Observation,作者使用连续 action 空间来确定位宽,在第 k 个 time step,作者会将 a_k 四舍五入为离散的位宽值 b_k:
![]()
其中 bmin 和 bmax 表示最小和最大位宽(在实验中,作者将 bmin 设置为 2,bmax 设置为 8)。
在实际应用中,具有有限的计算预算(即延迟,能量和模型大小)。作者希望找到具有约束条件的最佳性能的量化策略,因此鼓励 agent 通过限制 action 空间来满足计算资源预算。在 agent 向所有层提供 action{a_k} 之后,测量量化模型将使用的资源量。直接从硬件加速器获得反馈,如果当前量化策略超出资源预算(延迟,能耗或模型尺寸),则将按顺序减小每个层的位宽,直到最终满足约束。
对 agent 的直接反馈可以是 proxy 信号 (Flops 或模型尺寸),然而由于 proxy 信号是间接的,它们不等同于硬件上的性能(延迟,能耗)。同时局部缓存,内核调用次数,内存带宽等信息也都很重要。而 Proxy 反馈无法对这些硬件功能进行建模以找到特定的量化策略。因此,作者使用来自硬件加速器的直接延迟和能量反馈作为资源约束,这使得 agent 能够根据不同层之间的细微差别来确定位宽分配策略。在量化所有层之后,作者将量化模型微调一个 epoch,并在短期再训练之后将验证准确率作为 reward 提供给 agent。reward 的计算如下所示:
![]()
其中,acc_quant 是微调后量化模型的准确率,acc_origin 是 full-precision 模型在训练集上的 top-1 准确率,λ是缩放因子,在实验中作者设置为 0.1。
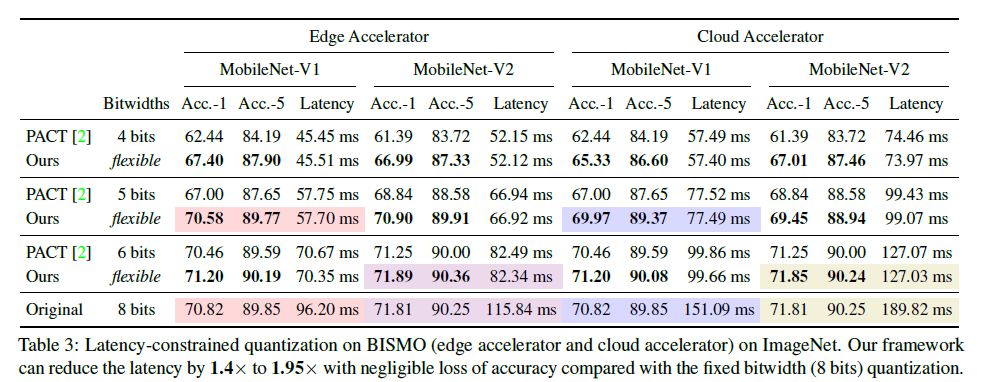
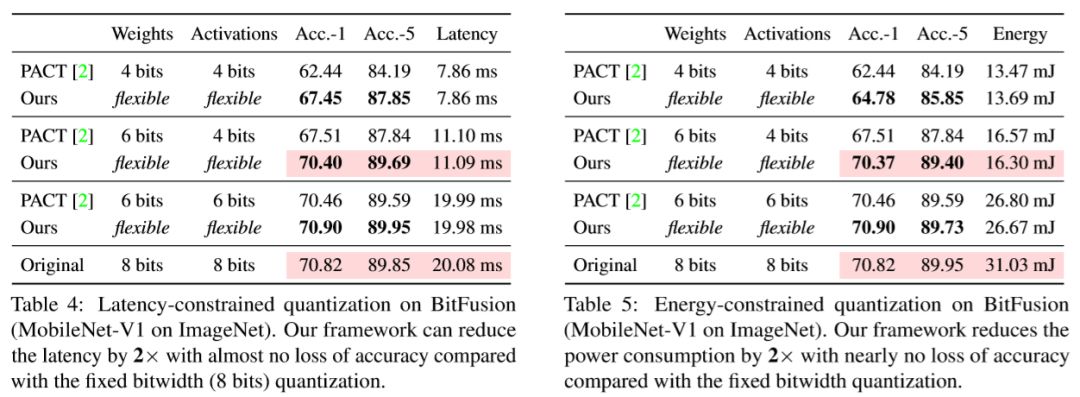
与传统方法相比,作者的框架是完全自动化的,可以对不同的神经网络架构和硬件架构进行专门的量化策略。与固定位宽(8 位)量化相比,作者的框架有效地将延迟减少了 1.4-1.95 倍,能耗减少了 1.9 倍,并且精度损失可忽略不计,结果如下所示:
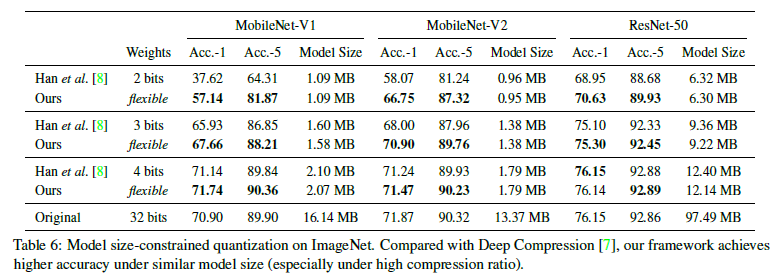
作者在 MobileNet 和 ResNet50 上评估 HAQ 和 Deep Compression 方法,发现 HAQ 在相同的模型尺寸约束下实现了更高的精度。对于像 MobileNet 这样的紧凑型模型,在较为激进的量化策略下,Deep Compression 会显著降低性能,而使用 HAQ 框架可以更好地保持准确性。例如,当 Deep Compression 将 MobileNet-V1 的权重量化为 2 位时,准确度从 70.90 显著下降到 37.62; 而 HAQ 框架在相同的模型尺寸下仍可达到 57.14 的精度。结果如下所示:
![]()
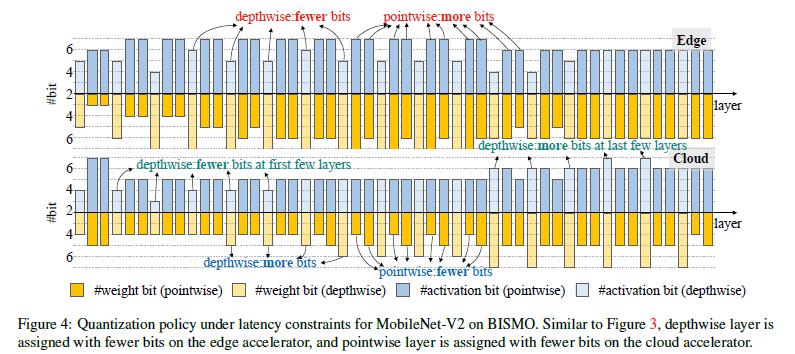
作者的框架揭示了在不同资源约束(延迟,能耗和模型尺寸)下的不同硬件架构(edge 和 cloud 架构)上的最优策略是截然不同的,并且解释了不同量化策略的含义。图 4 展示了 MobileNet-V2 在 BISMO 架构上给定延迟约束后的量化策略。对于激活的位宽分配,在 edge 加速器上,HAQ 为 pointwise 层分配更多位宽,为 depthwise 层分配更少位宽。在 cloud 加速器上,前几层分配的位宽与 edge 加速器相近,但是对于最后几层,HAQ 为 depthwise 层分配更多位宽,这与 edge 加速器完全相反。这种现象再次证实了针对对不同硬件需要有专门的量化策略。
![]()
Github:_https://github.com/mit-han-lab/haq-release_ (https://github.com/mit-han-lab/haq-release)
作者使用的是 Pytorch 1.1(cuda10)和 torchvision 0.3.0
conda install -y pytorch torchvision cudatoolkit=10.0 -c pytorch
bash run/setup.sh
3. 如果已有 pytorch 的 ImageNet 数据集,则可以创建指向数据文件夹的链接并使用它。
ln -s /path/to/imagenet/ data/
如还没有 ImageNet,可以下载 ImageNet 数据集并将验证图像移动到标记的子文件夹。
可供使用的脚 本:https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh
4. 运行 bash 文件,以搜索特定模型的量化策略
bash run/run_search.sh
python rl_quantize.py --help
6. 进行搜索后得到量化 strategy list,用它替换 finetune.py 中的 strategy list 以微调和评估 ImageNet 数据集的性能。替换 strategy list 后,执行如下命令
bash run/run_finetune.sh
通过如下命令可查看 finetune 的 help
python finetune.py --help
mkdir -p checkpoints/resnet50/
cd checkpoints/resnet50/
wget https://hanlab.mit.edu/files/haq/resnet50_0.1_75.48.pth.tar
cd ../..
bash run/run_eval.sh
作者介绍:罗赛男,西安电子科技大学计算机学院研究生,主要研究神经网络安全、验证码安全。关注学术前沿,喜欢文字分享,希望通过机器之心和大家一起学习,共同进步。比心 (ノ゚▽゚)ノ♡!
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com