炸裂!MySQL 82 张图带你飞!


锁定语句
lock table cxuan005 read;

select * from cxuan005 where id = 111;

select * from cxuan005;

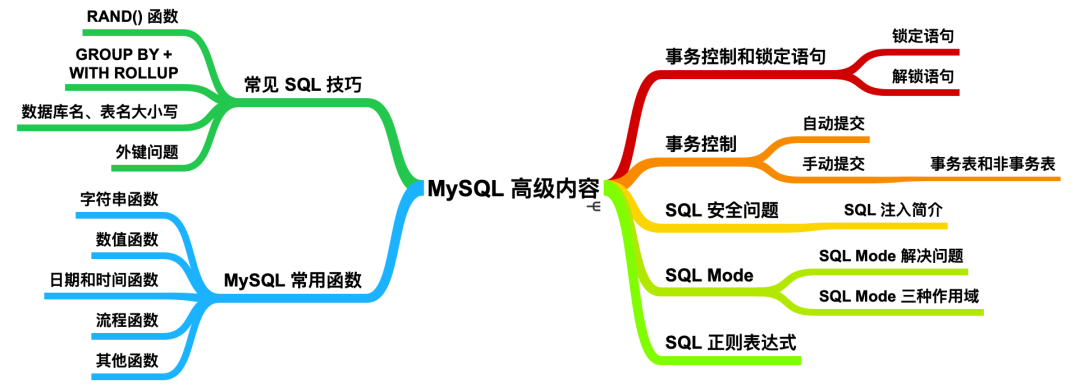
update cxuan005 set info='cxuan' where id = 111;
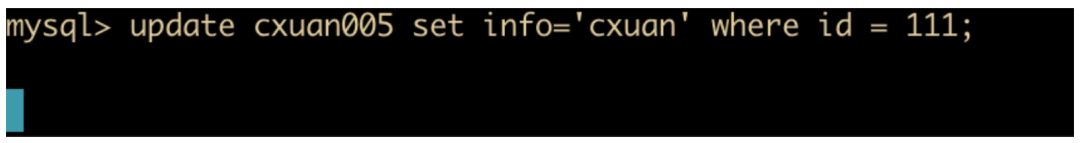
解锁语句
unlock tables;


select * from cxuan005 where id = 111;

事务控制
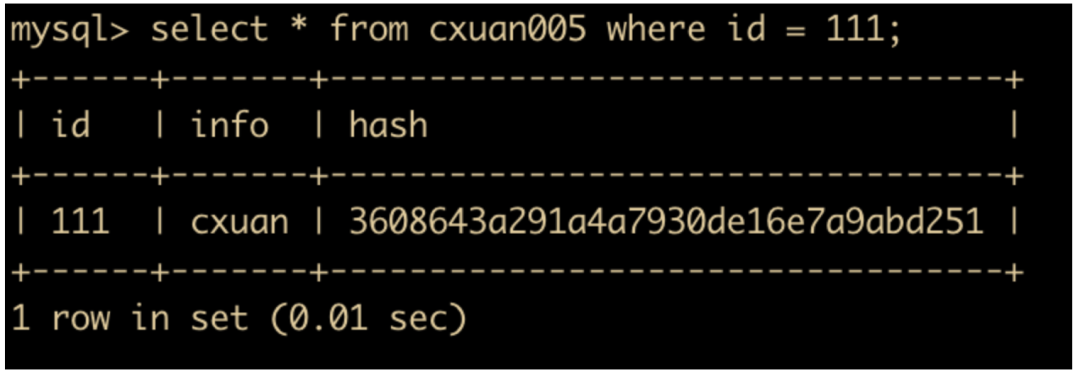
自动提交
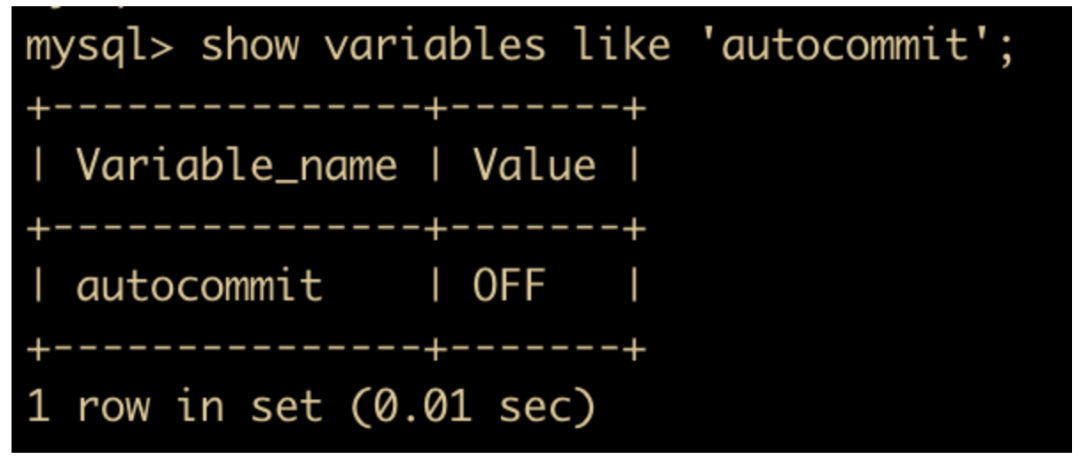
show variables like 'autocommit';
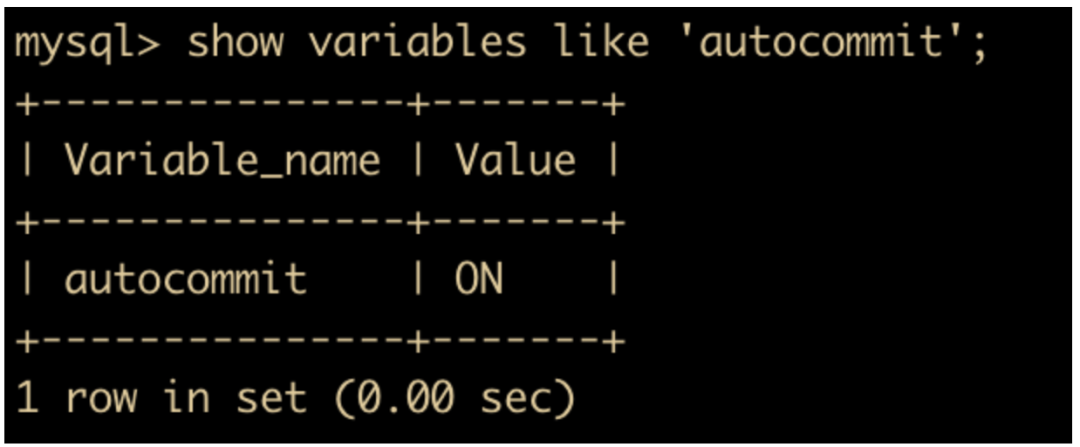
update cxuan005 set info='cxuan' where id = 111;
如果想要关闭数据库的自动提交应该怎么做呢?
set autocommit = 0;

set autocommit = 1;
这里注意一下特殊操作。 在 MySQL 中,存在一些特殊的命令,如果在事务中执行了这些命令,会马上强制执行 commit 提交事务;比如 DDL 语句(create table/drop table/alter/table)、lock tables 语句等等。 不过,常用的 select、insert、update 和 delete命令,都不会强制提交事务。
手动提交
start transaction;
... # 一条或者多条语句
commit;

start transaction;

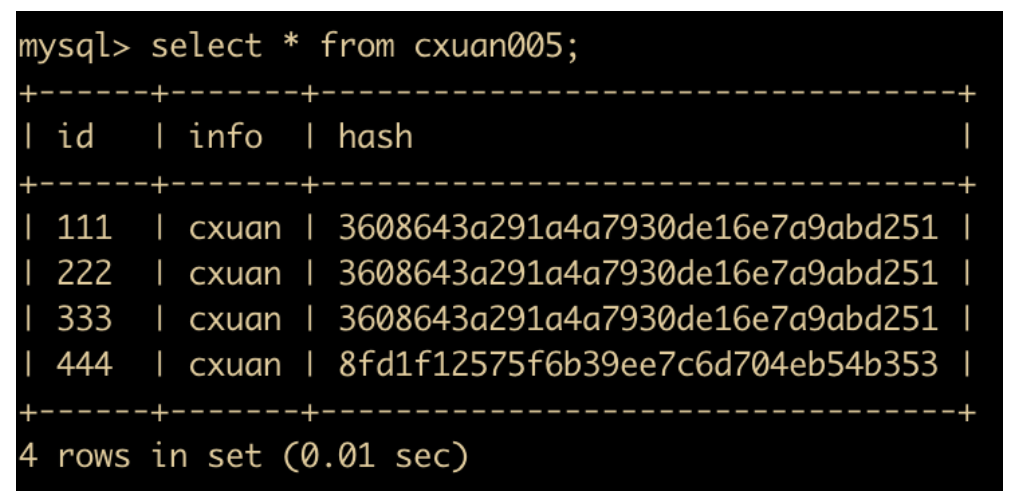
select * from cxuan005;

update cxuan005 set info='cxuan';

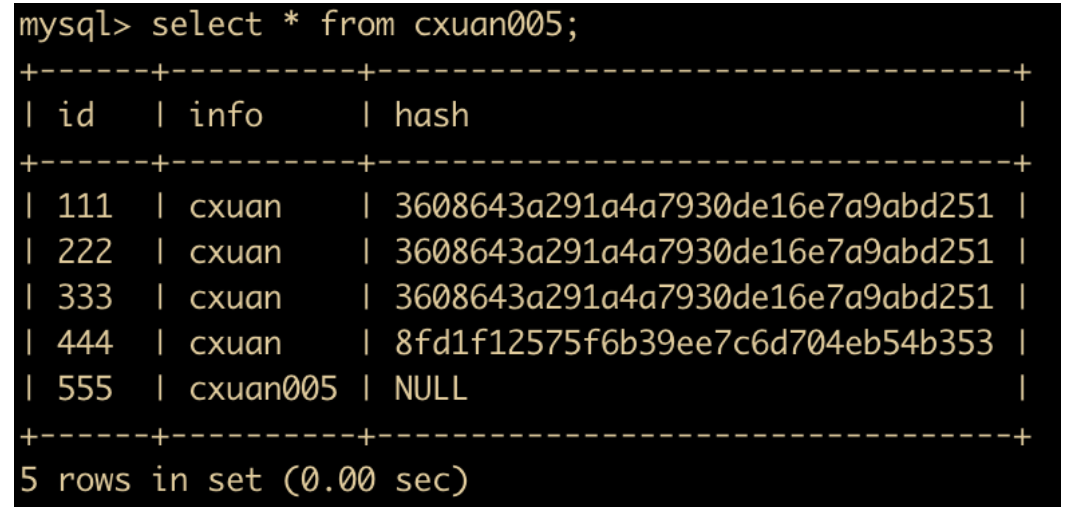
start transaction; # 开启一个新的事务
insert into cxuan005(id,info) values (555,'cxuan005'); # 插入一条数据
commit and chain; # 提交当前事务并重新开启一个事务
update cxuan005 set info = 'cxuan' where id = 555;
commit;
select * from cxuan005;
start transaction;
delete from cxuan005 where id = 555;
rollback;
这里切忌一点:delete 删除语句一定要加 where ,不加 where 语句的删除就是耍流氓。
事务表和非事务表
start transaction;
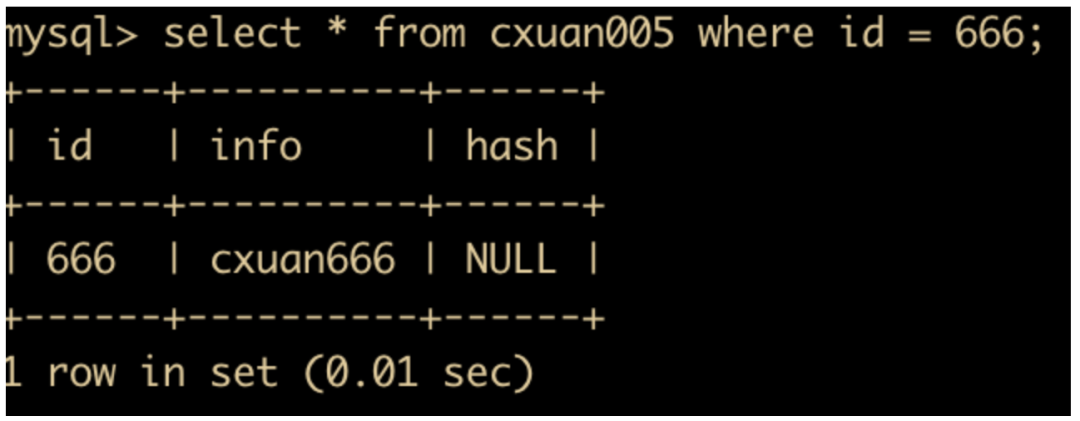
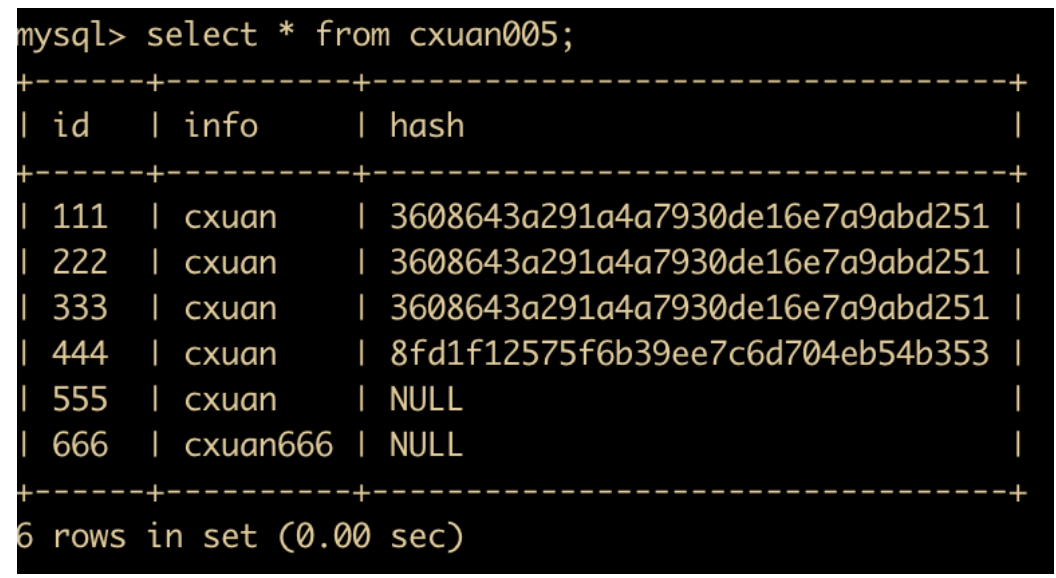
insert into cxuan005(id,info) values(666,'cxuan666');
select * from cxuan005 where id = 666;
savepoint test;
insert into cxuan005(id,info) values(777,'cxuan777');
select * from cxuan005 where id = 777;
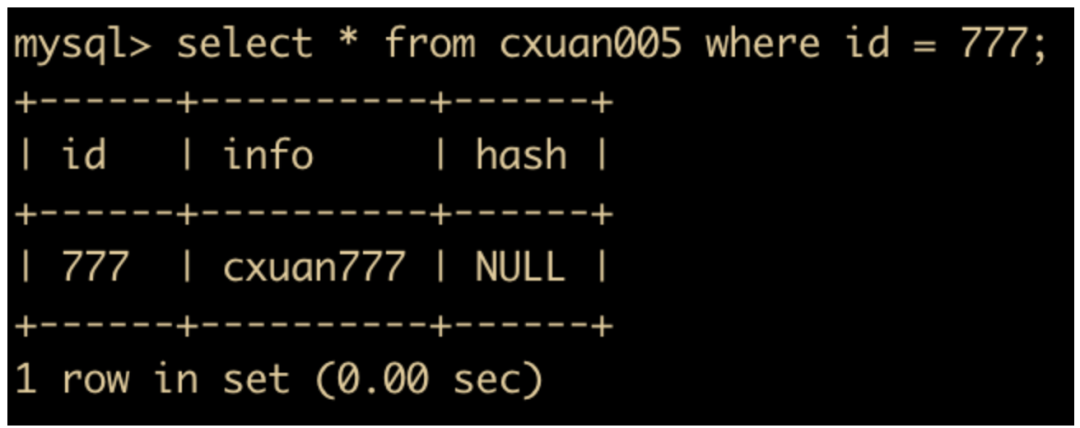
rollback to savepoint test;

SQL 注入简介

SQL Mode 解决问题
-
通过设置 SQL Mode,可以完成不同严格程度的数据校验,有效保障数据的准确性。 -
设置 SQL Mode 为 ANSI 模式,来保证大多数 SQL 符合标准的 SQL 语法,这样应用在不同数据库的迁移中,不需要对 SQL 进行较大的改变 -
数据在不同数据库的迁移中,通过改变 SQL Mode 能够更方便的进行迁移。
select @@sql_mode;

select id,info from cxuan005;
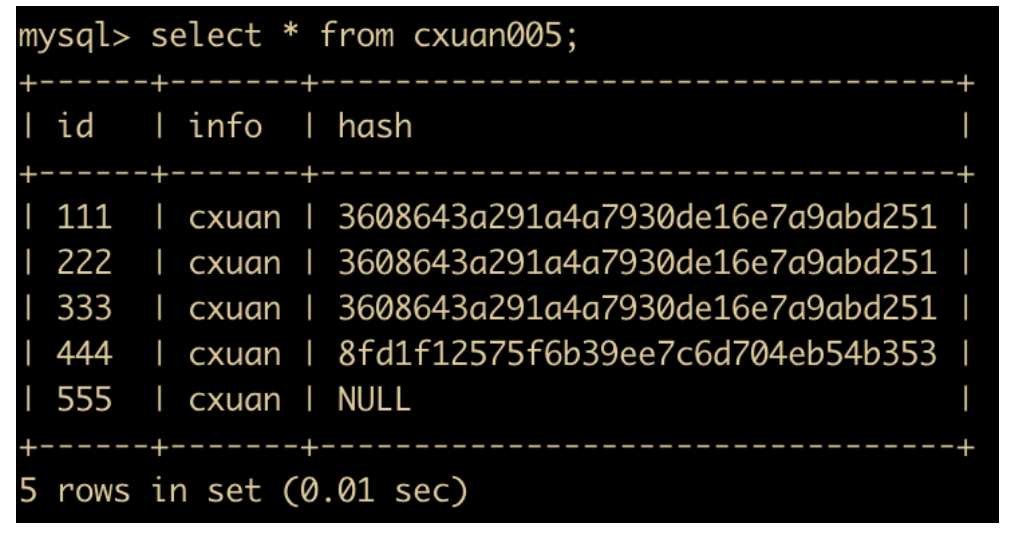
select id,info from cxuan005 group by info;

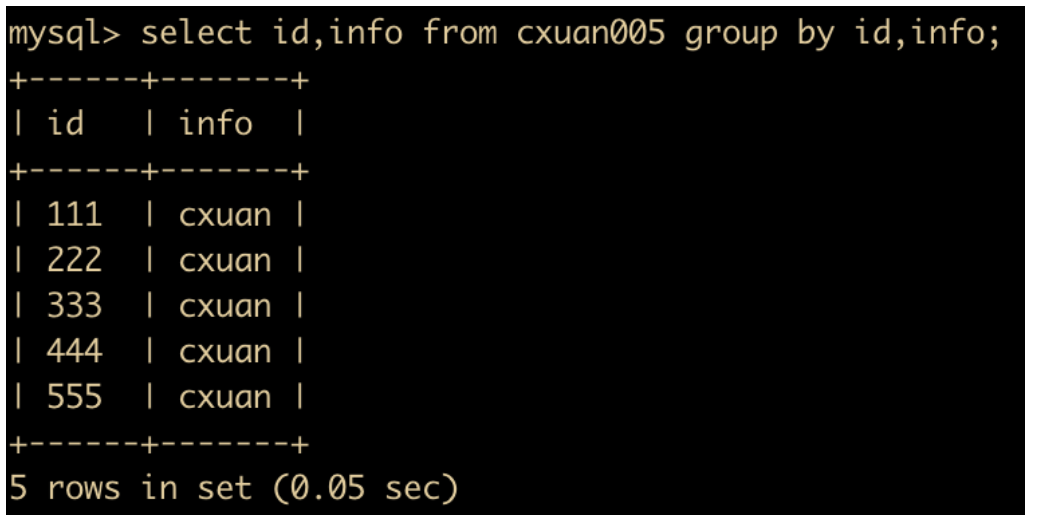
select id,info from cxuan005 group by id,info;
SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
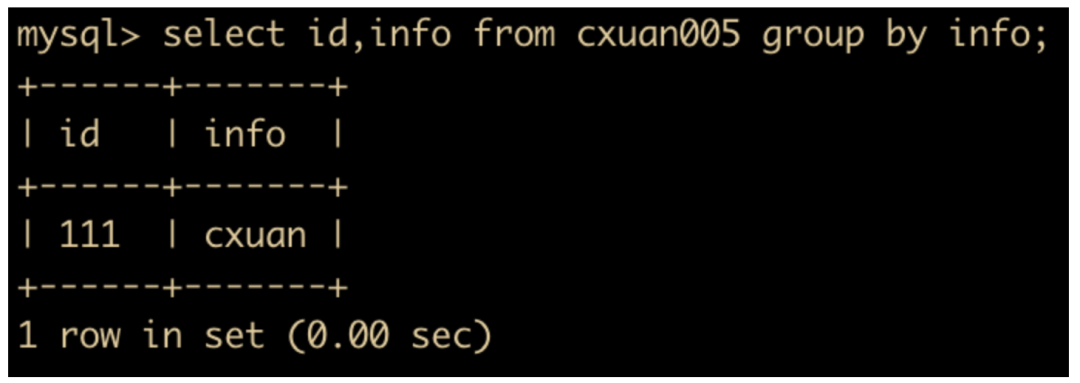
select id,info from cxuan005 group by info;
当使用 innodb 存储引擎表时,考虑使用 innodb_strict_mode 模式的 sql_mode,它能增量额外的错误检测功能。
set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE';
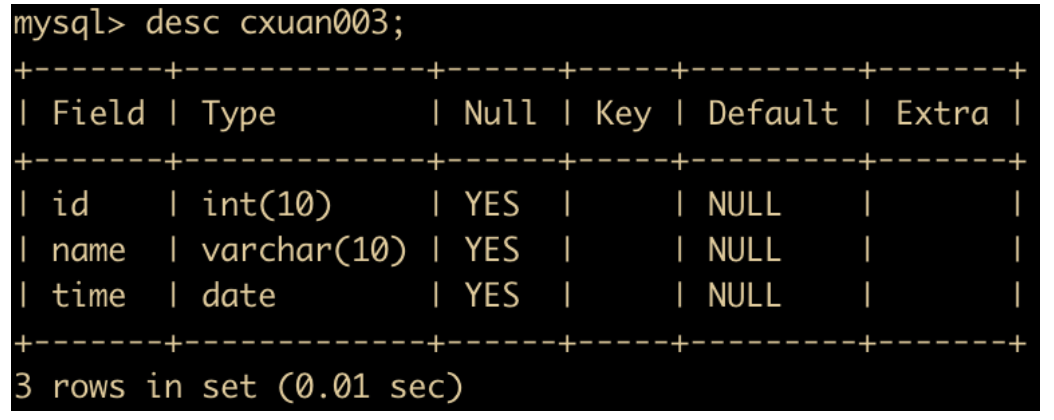
insert into cxuan003 values(111,'study','0000-00-00');
insert into cxuan003 values(111,'study','2021-00-00');

insert into cxuan003 values(111,'study','2021-01-00');

SQL Mode 三种作用域
set @@session.sql_mode='xx_mode'
set session sql_mode='xx_mode'
set global sql_mode='xx_mode';
set @@global.sql_mode='xx_mode';
[mysqld]
sql-mode = "xx_mode"

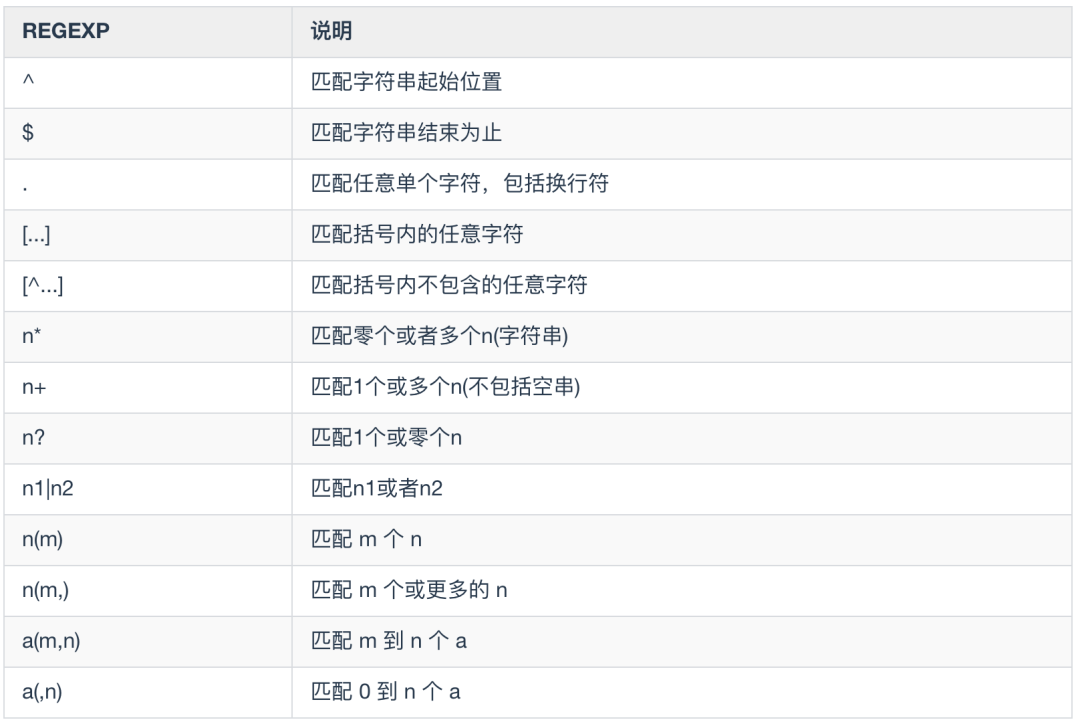
SQL 正则表达式
-
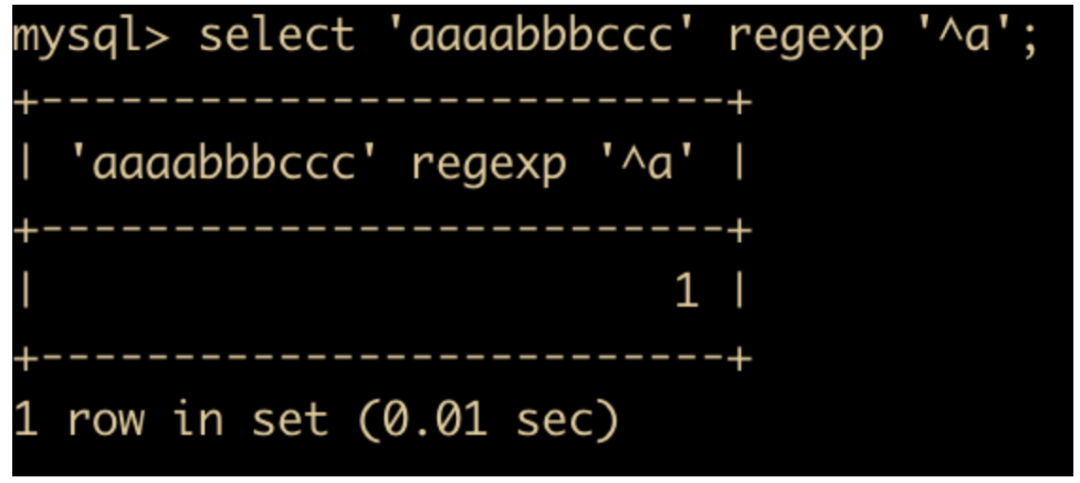
^ 在字符串的开始进行匹配,根据返回的结果来判断是否匹配,1 = 匹配,0 = 不匹配。下面尝试匹配字符串 aaaabbbccc 是否以字符串 a 为开始
select 'aaaabbbccc' regexp '^a';
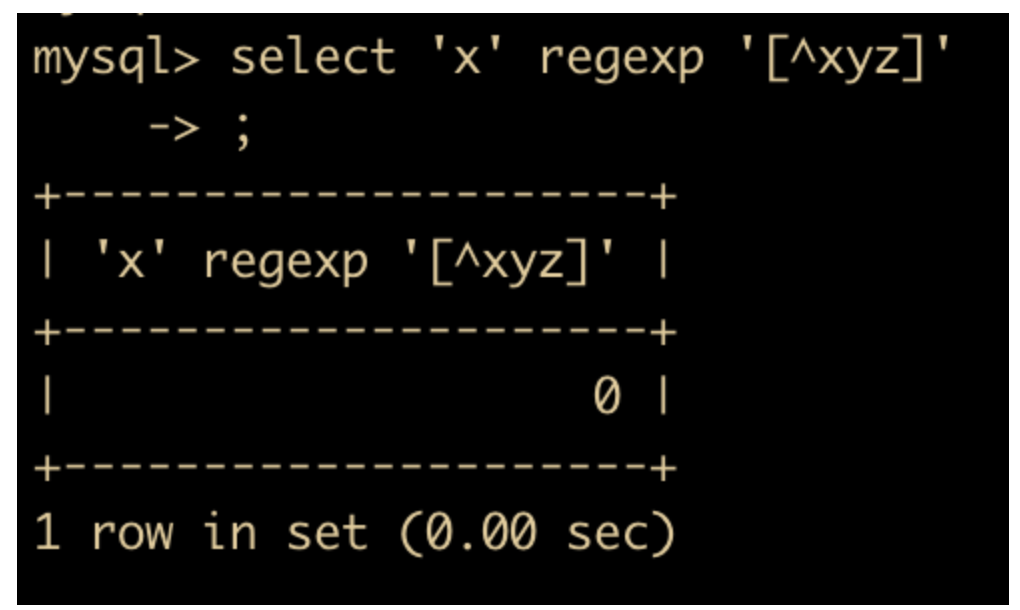
同样的,$ 会在末尾处进行匹配,如下所示
select 'aaaabbbccc' regexp 'c$';
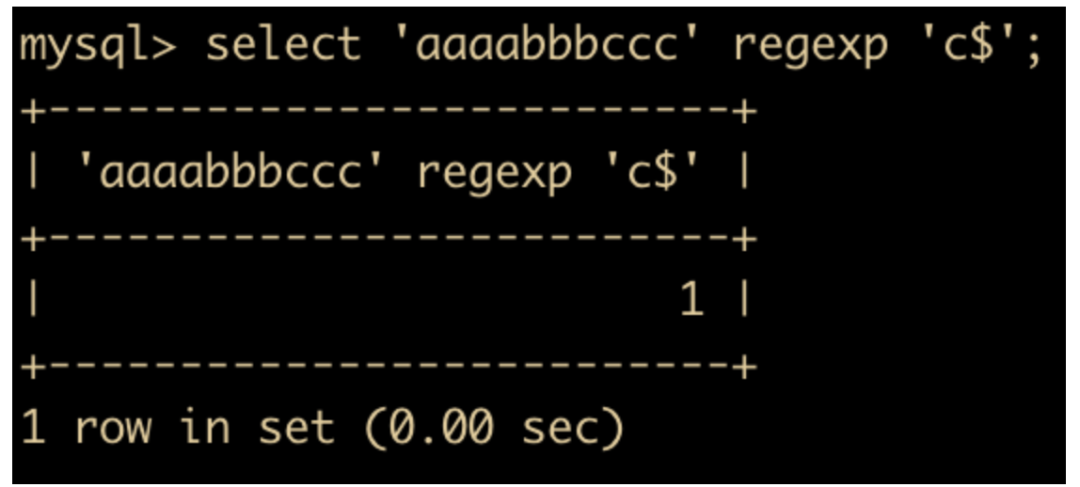
.匹配单个任意字符
select 'berska' regexp '.s', 'zara' regexp '.a';
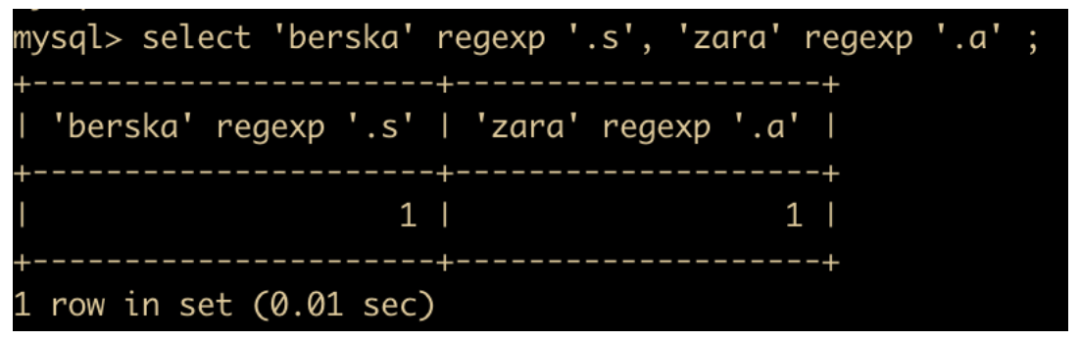
[...] 表示匹配括号内的任意字符,示例如下
select 'whosyourdaddy' regexp '[abc]';
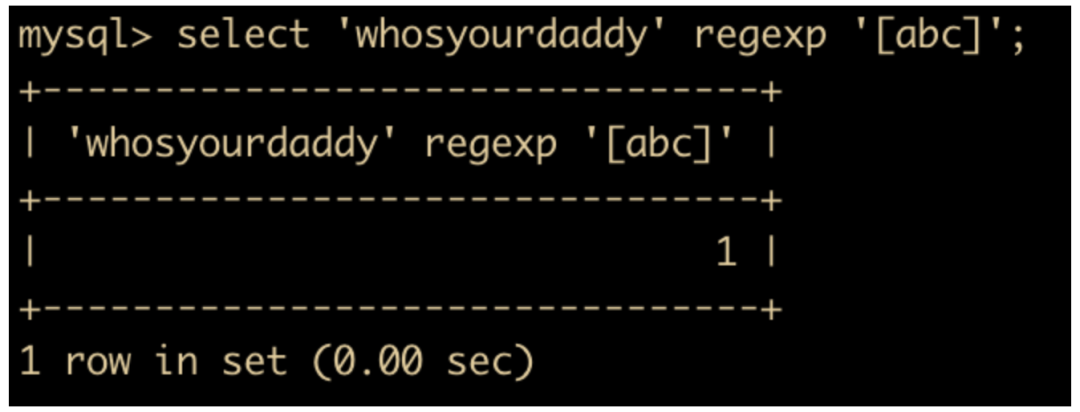
[^...]匹配括号内不包含的任意字符,和[...]是相反的,如果有任何匹配不上,返回 0 ,全部匹配上返回 1。
select 'x' regexp '[^xyz]';
n*表示匹配零个或者多个 n 字符串,如下
select 'aabbcc' regexp 'd*';
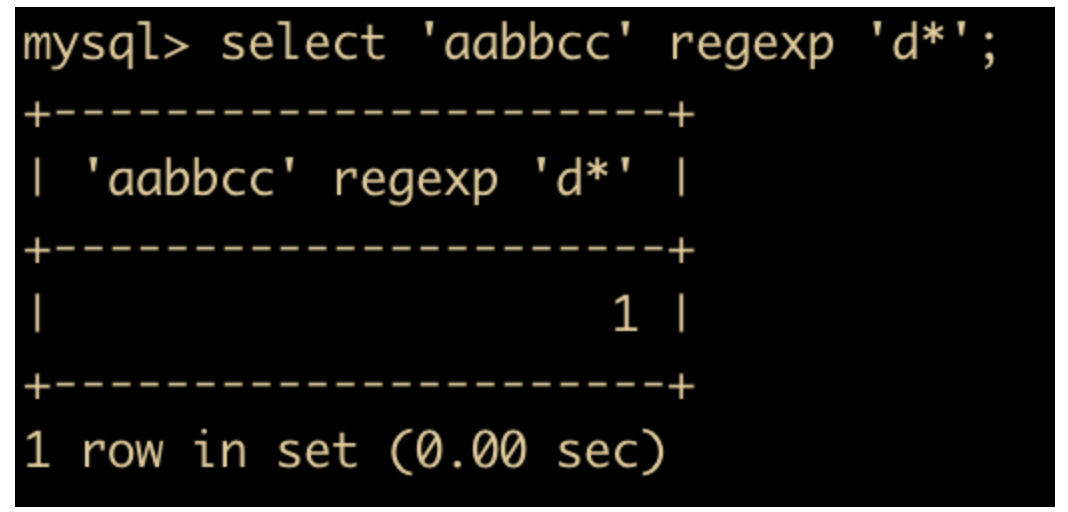 没
有 d 出现
也可以返回 1 ,因为 * 表示 0 或者多个。
没
有 d 出现
也可以返回 1 ,因为 * 表示 0 或者多个。
n+表示匹配 1 个或者 n 个字符串
select 'aabbcc' regexp 'd+';
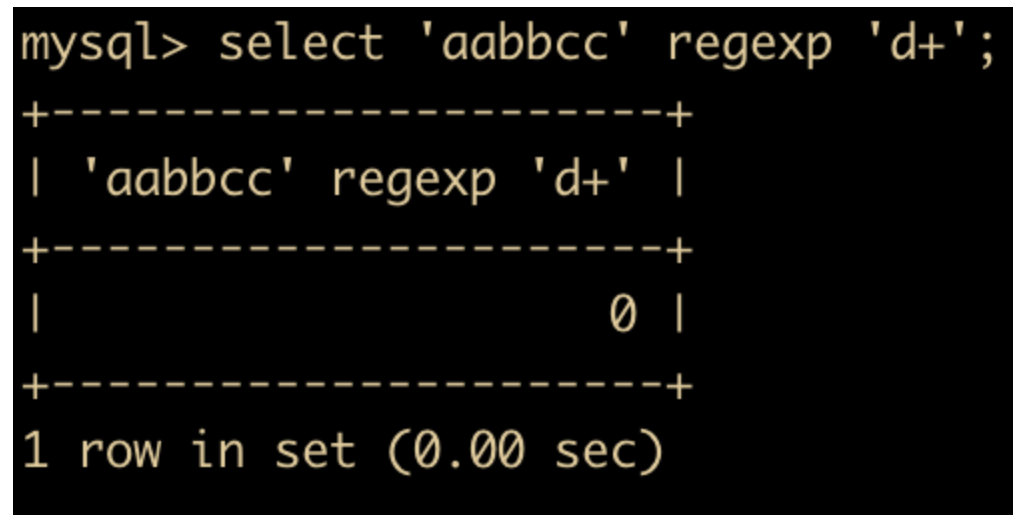
-
n?的用法和 n+ 类似,只不过 n? 可以匹配空串

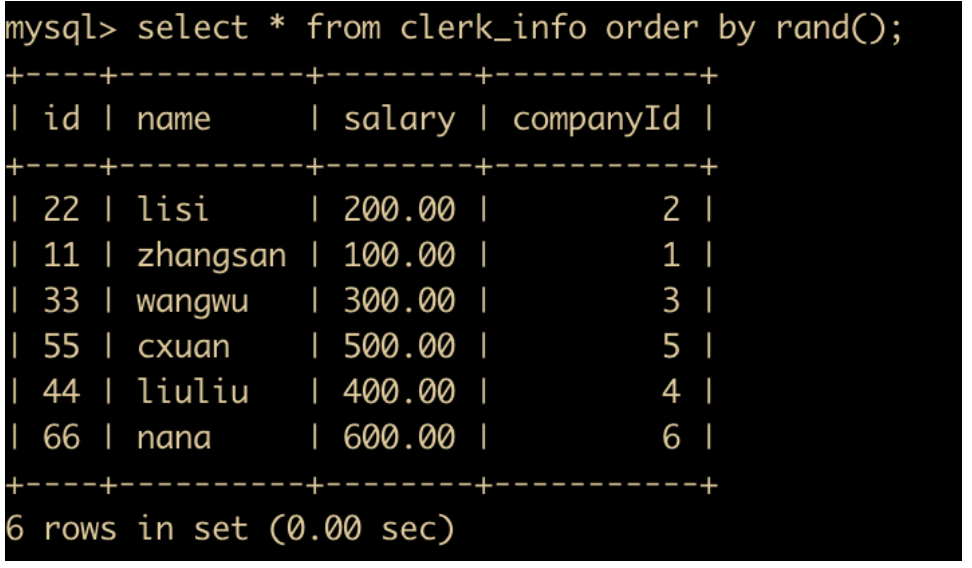
RAND() 函数
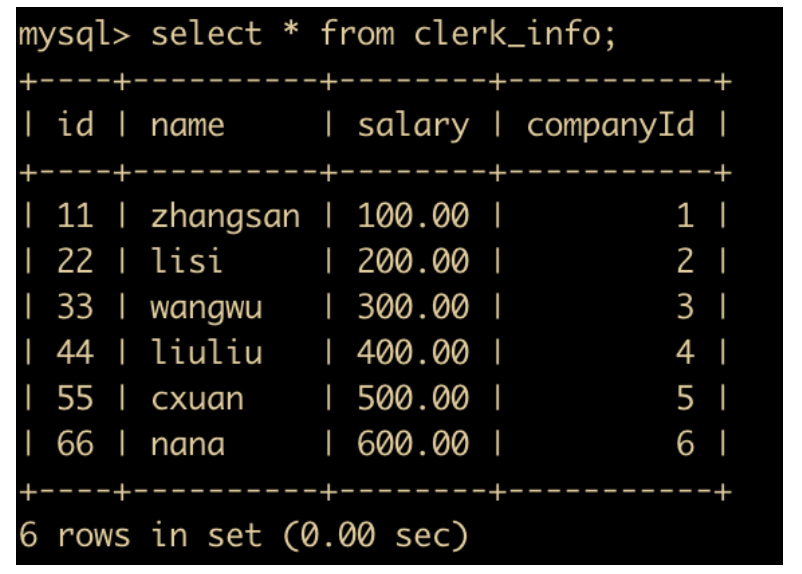
CREATE TABLE `clerk_Info` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
`companyId` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
select * from clerk_info order by rand();
GROUP BY + WITH ROLLUP
select name,sum(salary) from clerk_info group by name with rollup;
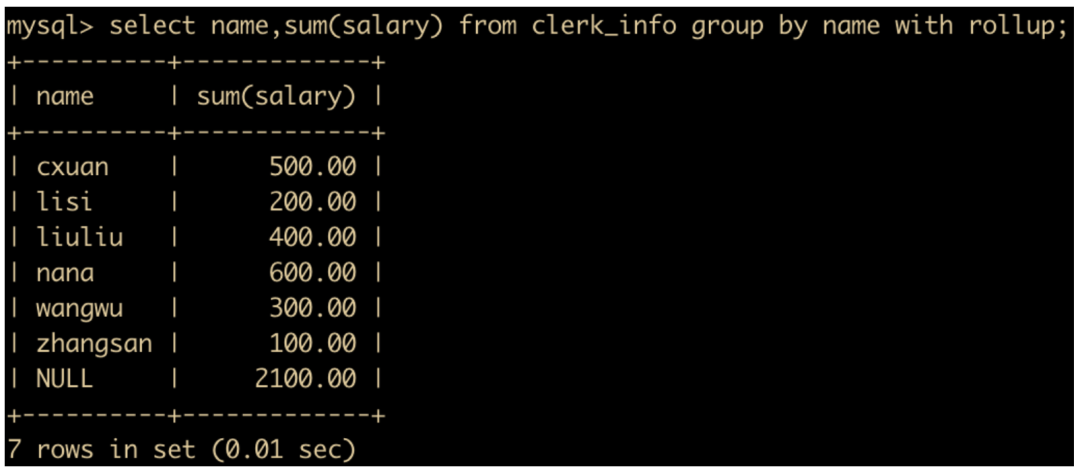
这里需要注意一点,不能同时使用 ORDER BY 字句对结果进行排序,ROLLUP 和 ORDER BY 是互斥的。
数据库名、表名大小写问题

外键问题

MySQL 常用函数
字符串函数
-
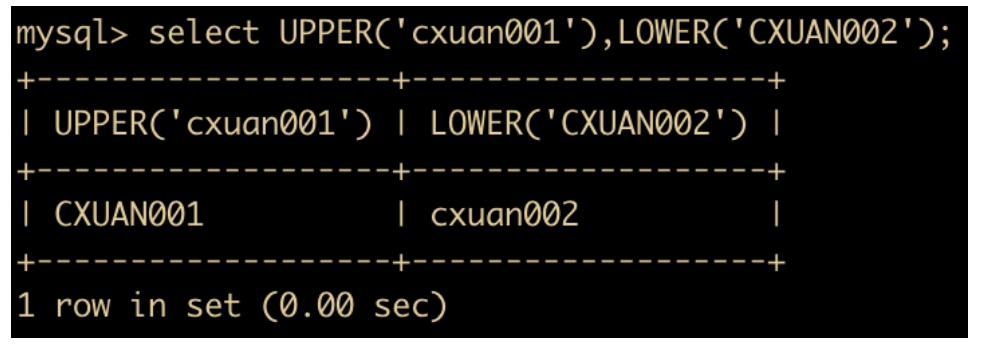
LOWER(str) 和 UPPER(str) 函数:用于转换大小写
-
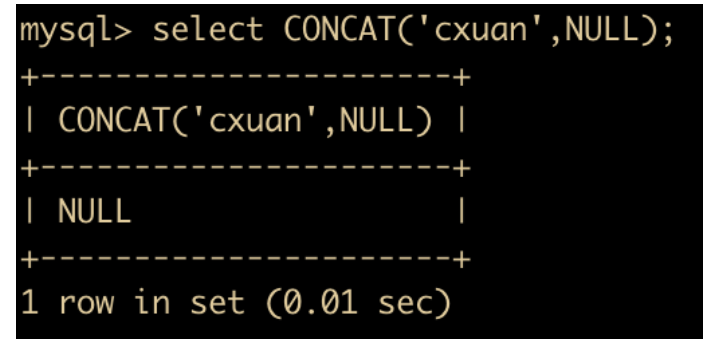
CONCAT(s1,s2 ... sn) :把传入的参数拼接成一个字符串
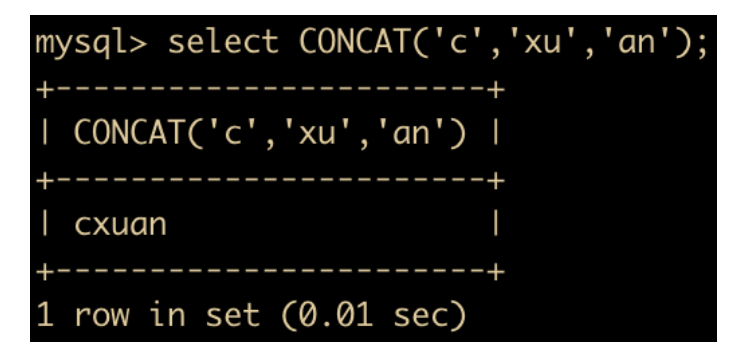
c xu an
拼接成为了一个字符串,另外需要注意一点,任何和 NULL 进行字符串拼接的结果都是 NULL。
-
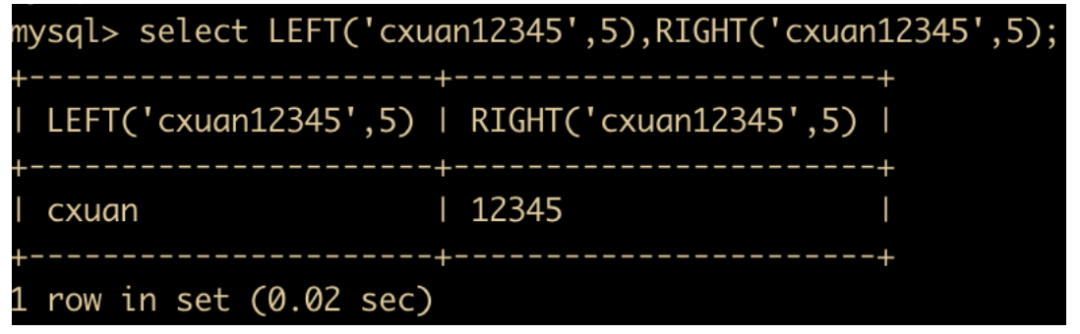
LEFT(str,x) 和 RIGHT(str,x) 函数:分别返回字符串最左边的 x 个字符和最右边的 x 个字符。如果第二个参数是 NULL,那么将不会返回任何字符串
-
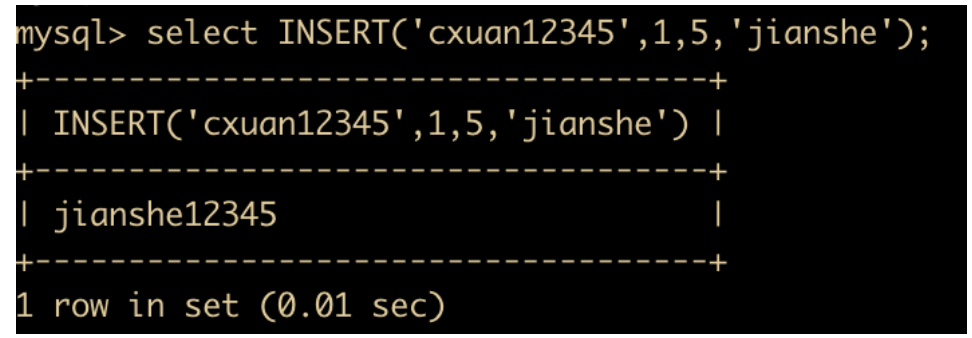
INSERT(str,x,y,instr) :将字符串 str 从指定 x 的位置开始, 取 y 个长度的字串替换为 instr。
-
LTRIM(str) 和 RTRIM(str) 分别表示去掉字符串 str 左侧和右侧的空格

-
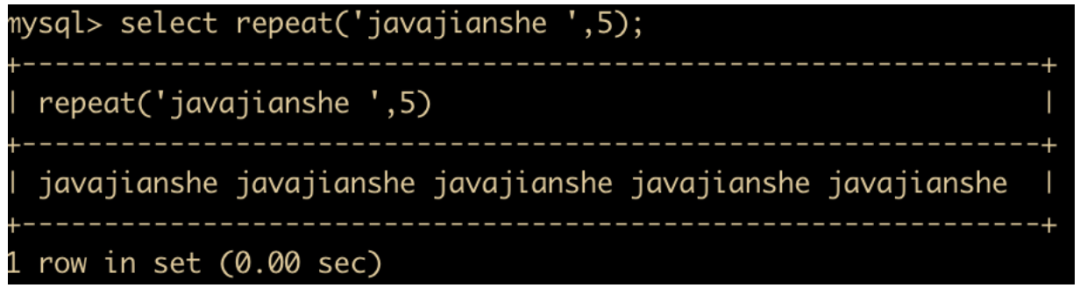
REPEAT(str,x) 函数:返回 str 重复 x 次的结果
-
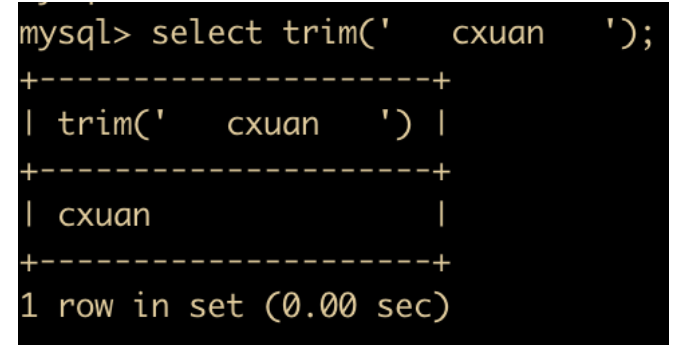
TRIM(str) 函数:用于去掉目标字符串的空格
-
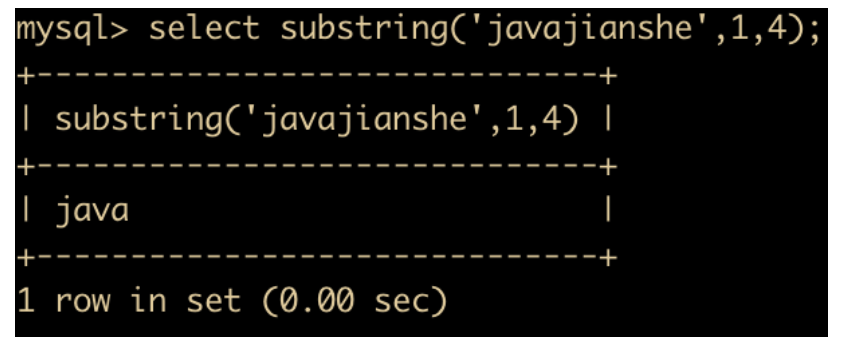
SUBSTRING(str,x,y) 函数:返回从字符串 str 中第 x 位置起 y 个字符长度的字符串
-
LPAD(str,n,pad) 和 RPAD(str,n,pad) 函数:用字符串 pad 对 str 左边和右边进行填充,直到长度为 n 个字符长度

-
STRCMP(s1,s2) 用于比较字符串 s1 和 s2 的 ASCII 值大小。如果 s1 < s2,则返回 -1;如果 s1 = s2 ,返回 0 ;如果 s1 > s2 ,返回 1。

-
REPLACE(str,a,b) : 用字符串 b 替换字符串 str 种所有出现的字符串 a

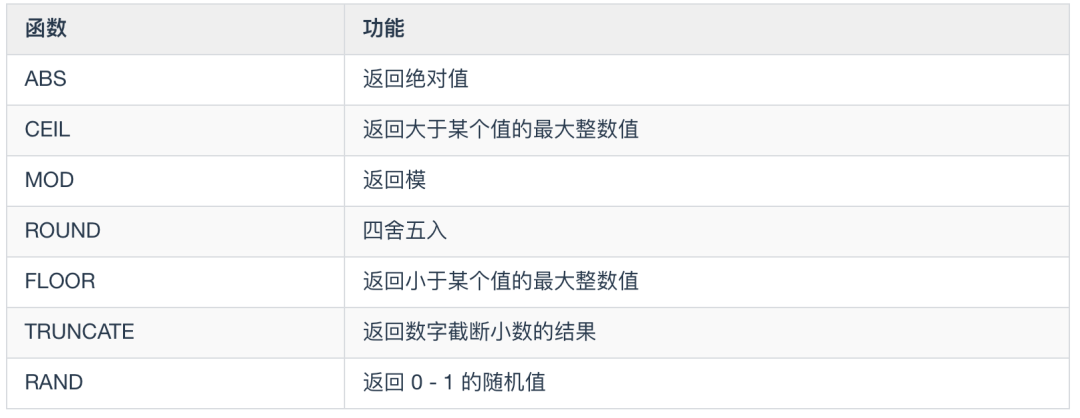
数值函数
-
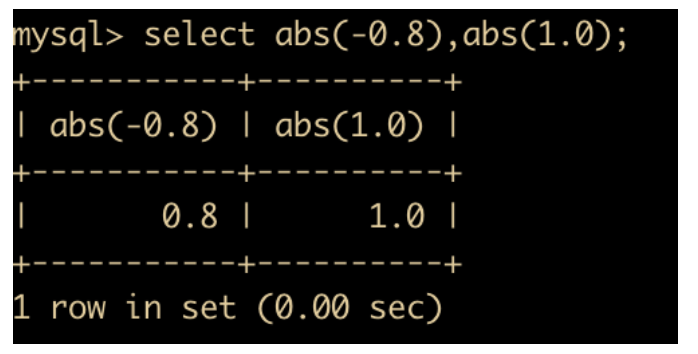
ABS(x) 函数:返回 x 的绝对值
-
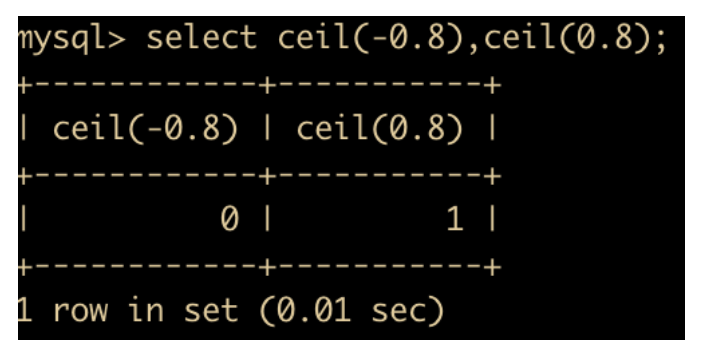
CEIL(x) 函数:返回大于 x 的整数
-
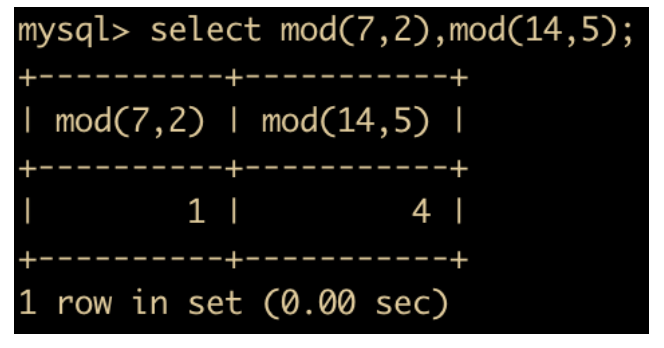
MOD(x,y),对 x 和 y 进行取模操作
-
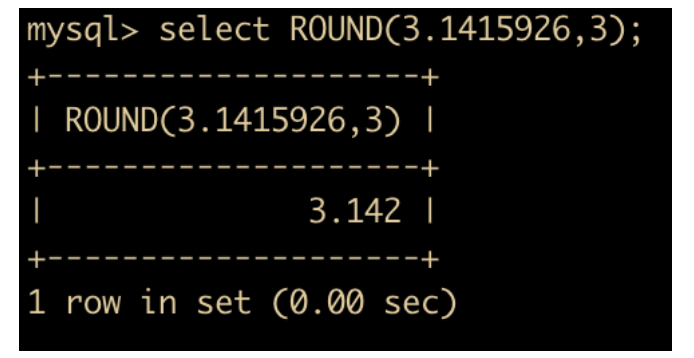
ROUND(x,y) 返回 x 四舍五入后保留 y 位小数的值;如果是整数,那么 y 位就是 0 ;如果不指定 y ,那么 y 默认也是 0 。
-
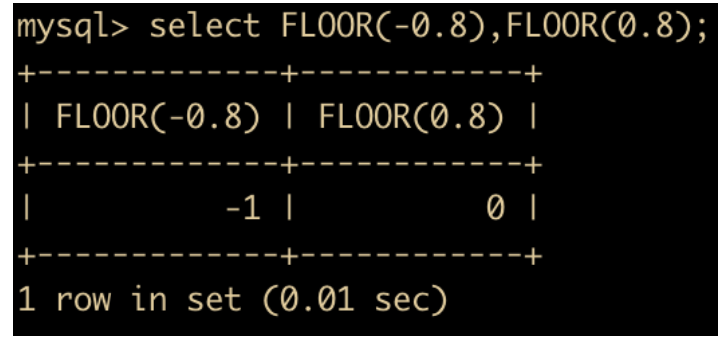
FLOOR(x) : 返回小于 x 的最大整数,用法与 CEIL 相反
-
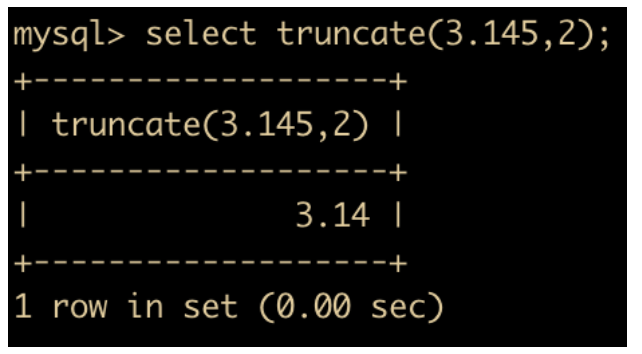
TRUNCATE(x,y): 返回数字 x 截断为 y 位小数的结果, TRUNCATE 知识截断,并不是四舍五入。
-
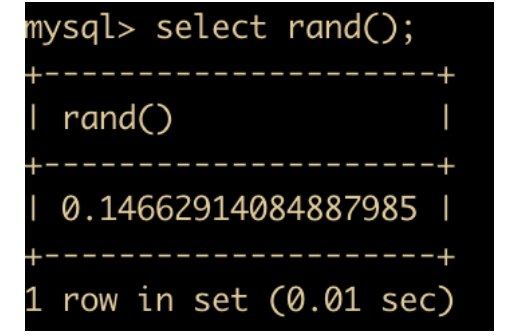
RAND() :返回 0 到 1 的随机值
日期和时间函数
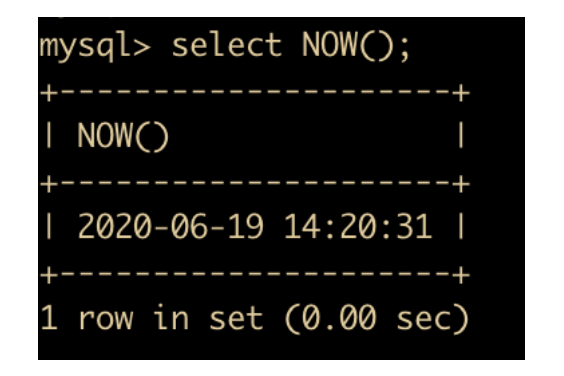
NOW(): 返回当前的日期和时间
-
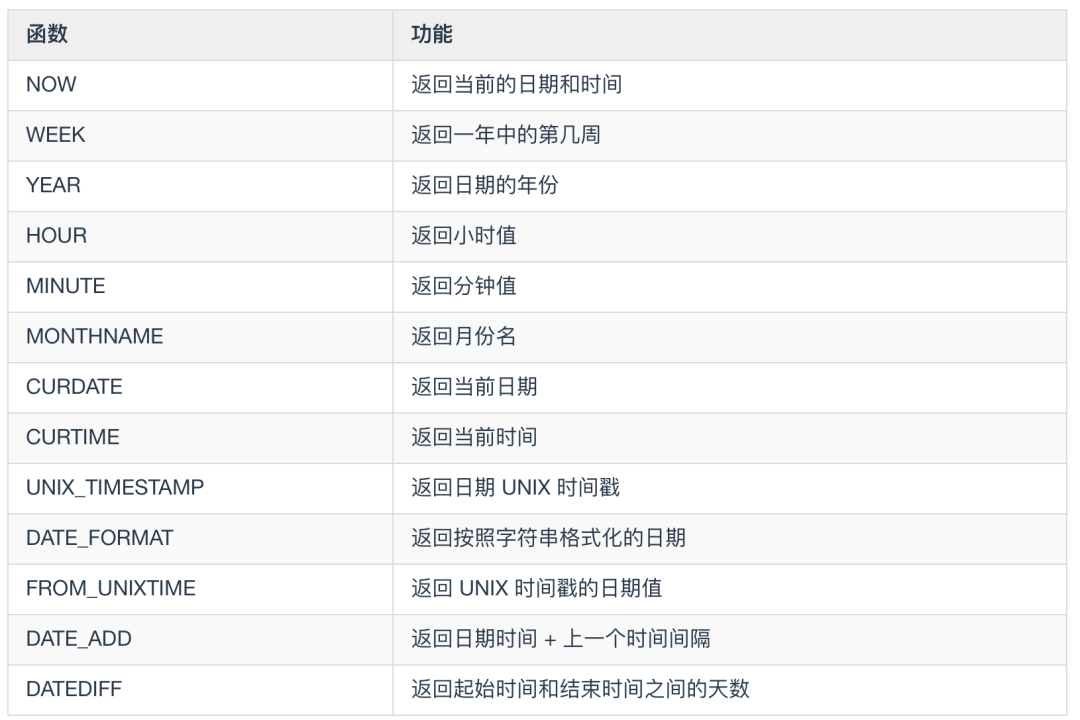
WEEK(DATE) 和 YEAR(DATE) :前者返回的是一年中的第几周,后者返回的是给定日期的哪一年
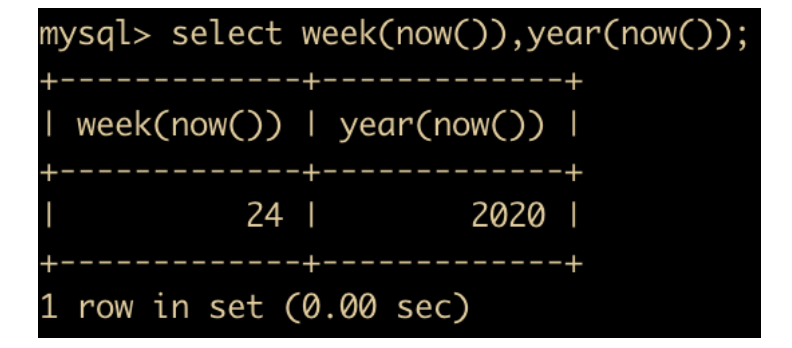
-
HOUR(time) 和 MINUTE(time) : 返回给定时间的小时,后者返回给定时间的分钟
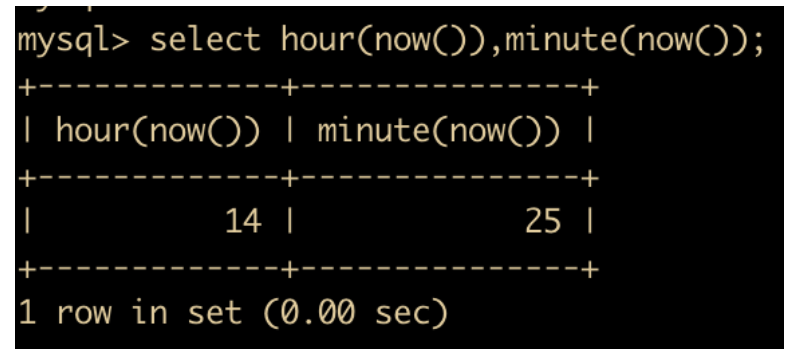
-
MONTHNAME(date) 函数:返回 date 的英文月份
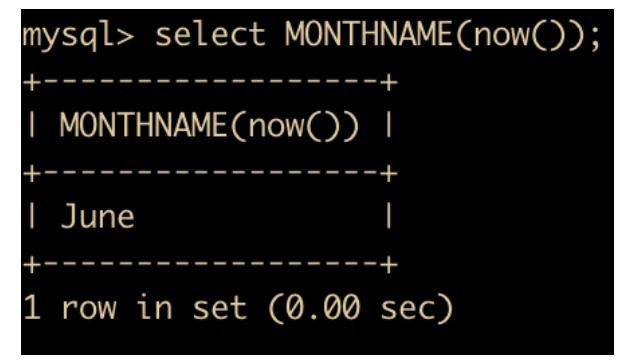
-
CURDATE() 函数:返回当前日期,只包含年月日
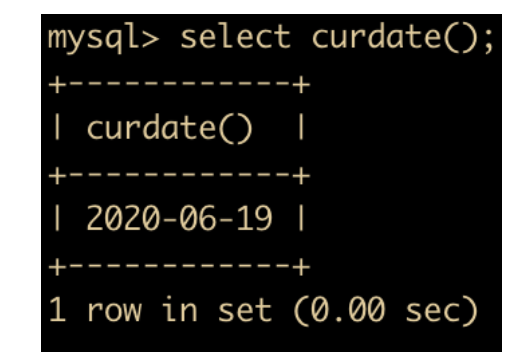
-
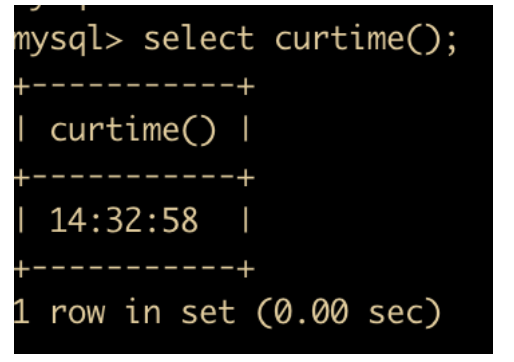
CURTIME() 函数:返回当前时间,只包含时分秒
-
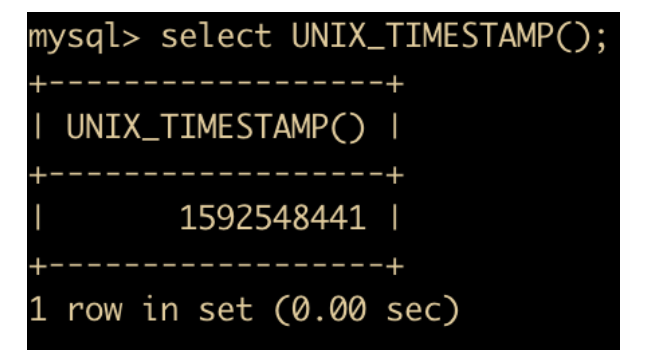
UNIX_TIMESTAMP(date) : 返回 UNIX 的时间戳
-
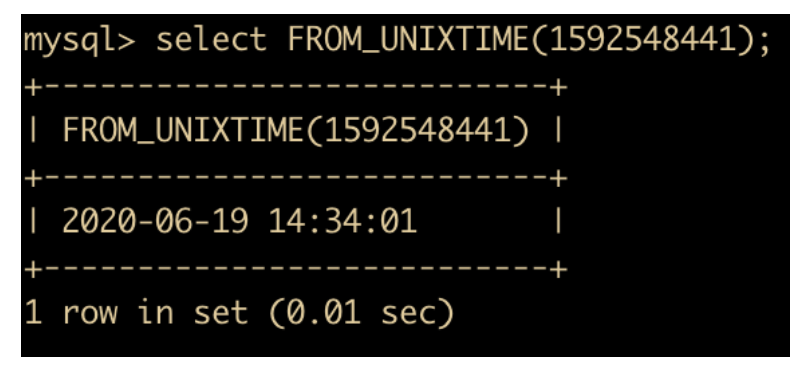
FROM_UNIXTIME(date) : 返回 UNIXTIME 时间戳的日期值,和 UNIX_TIMESTAMP 相反
-
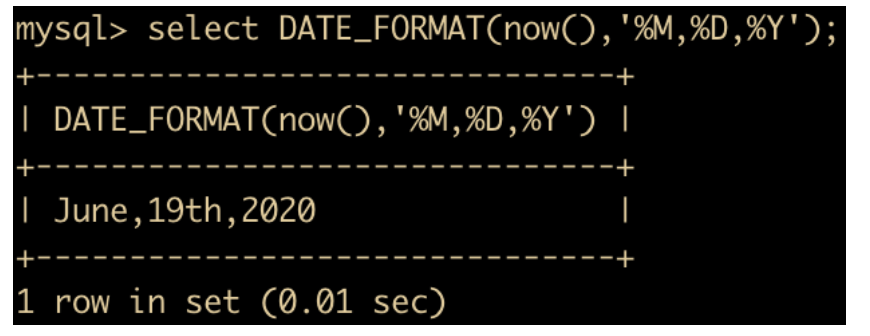
DATE_FORMAT(date,fmt) 函数:按照字符串 fmt 对 date 进行格式化,格式化后按照指定日期格式显示
-
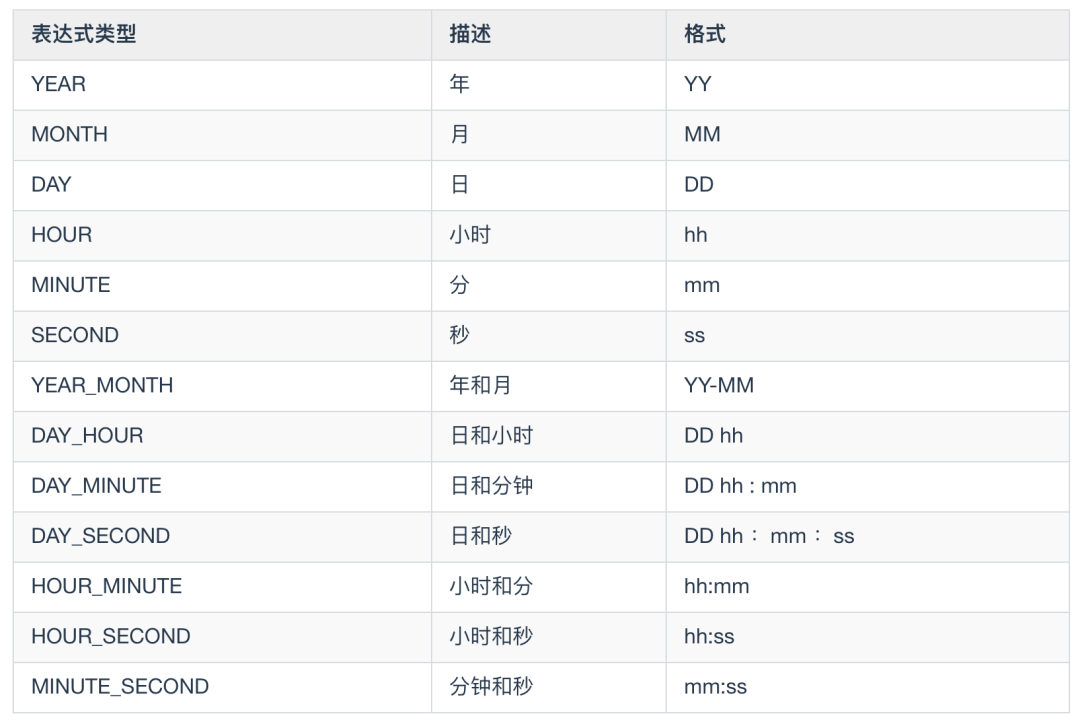
DATE_ADD(date, interval, expr type) 函数:返回与所给日期 date 相差 interval 时间段的日期
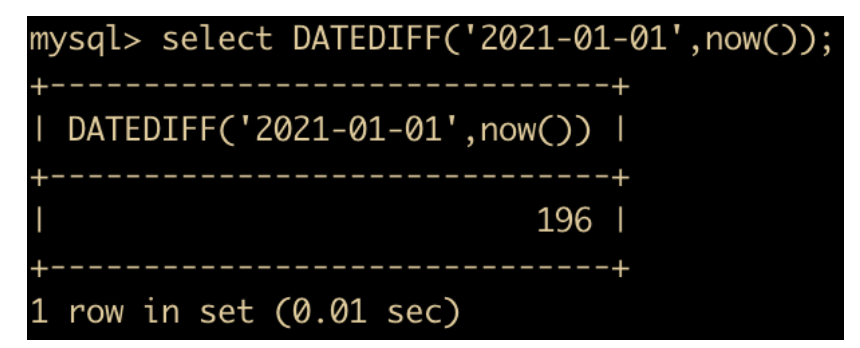
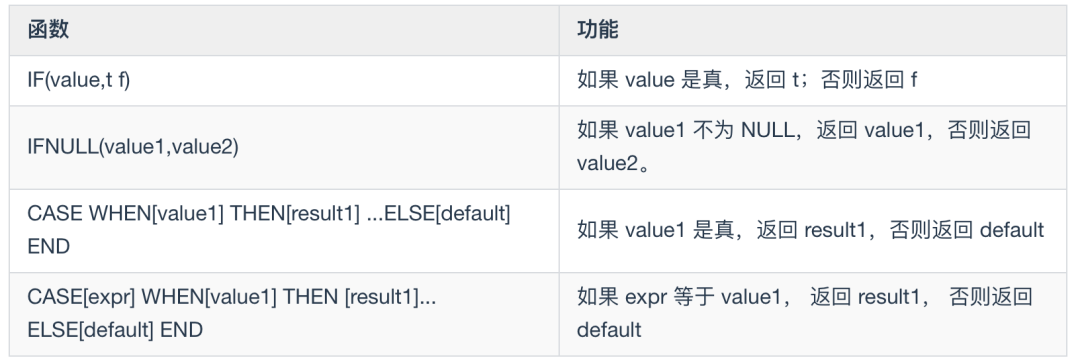
流程函数
-
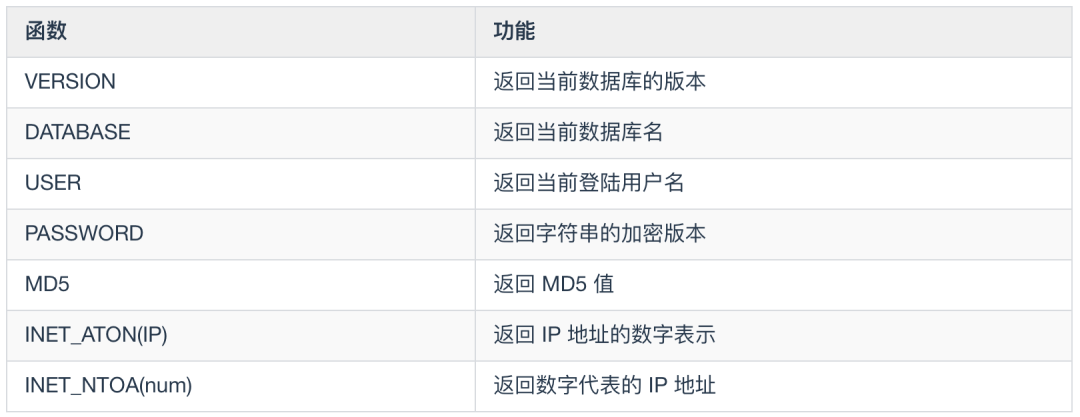
VERSION: 返回当前数据库版本
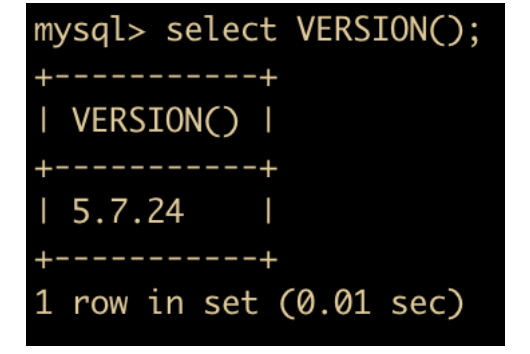
-
DATABASE: 返回当前的数据库名
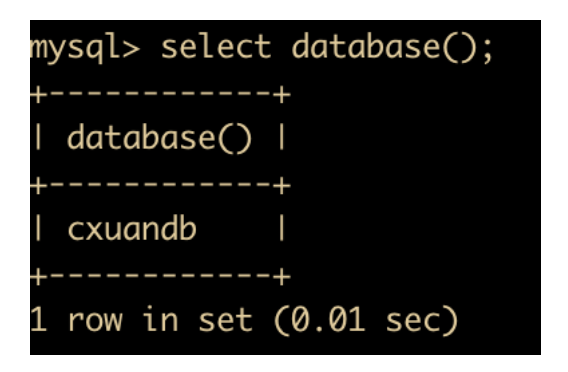
-
USER : 返回当前登录用户名
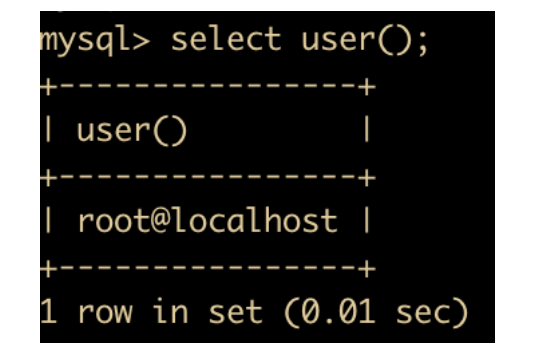
-
PASSWORD(str) : 返回字符串的加密版本,例如
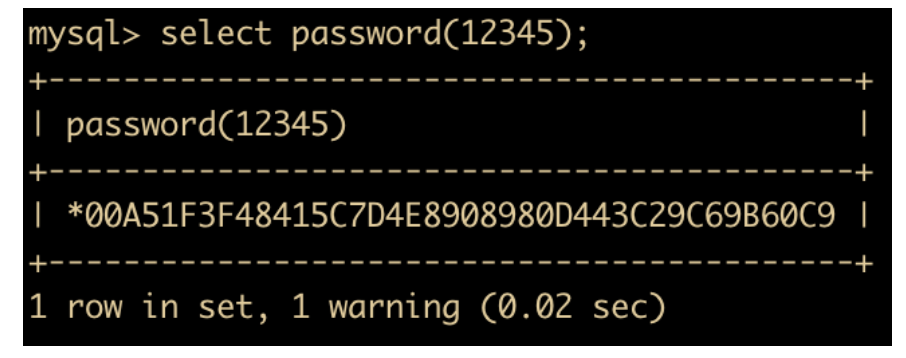
-
MD5(str) 函数:返回字符串 str 的 MD5 值
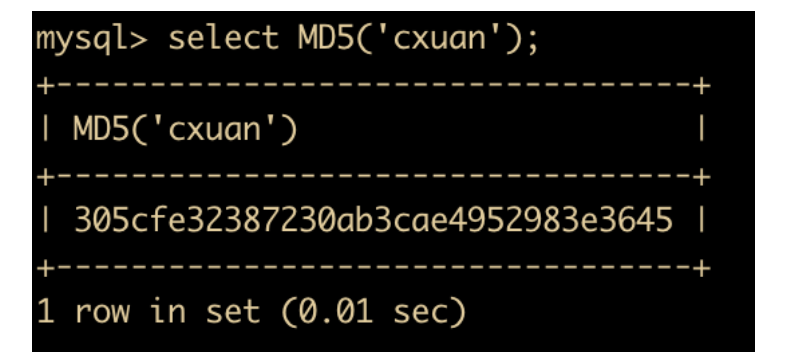
-
INET_ATON(IP): 返回 IP 的网络字节序列
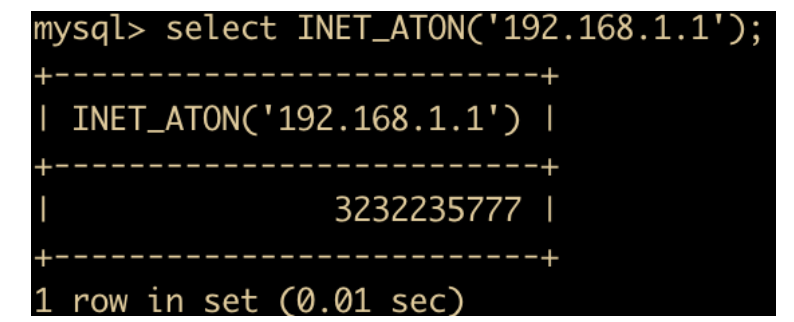
-
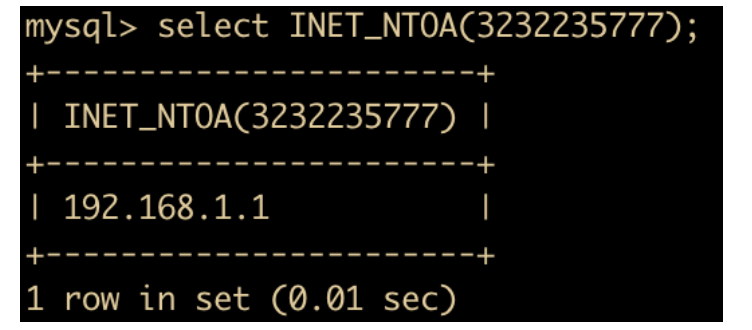
INET_NTOA(num)函数:返回网络字节序列代表的 IP 地址,与 INET_ATON 相对


☞新的一年,这7个“菜鸟坑”千万别再踩了!


登录查看更多
相关内容

Arxiv
0+阅读 · 2021年4月23日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年4月23日