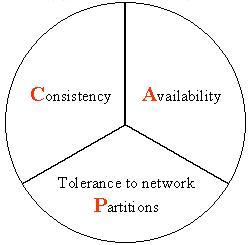
分布式系统先写DB还是先缓存?

本文我们将深入到实际场景中,聚焦「缓存」,来看一下「进程内缓存」、「进程外缓存」运用时的一些最佳实践。
由于篇幅原因,这次先聊三个问题。首先就是我们应该“先写DB还是缓存?”。我想,只要你开始运用缓存,这会是你第一个要好好思考的问题,否则在前方等待你的就是灾难……
一、先写DB还是缓存?
一个程序可以没有缓存,但是一定要有数据库。这是大家的普遍观点,所以数据库的重要性在你的潜意识里总是被放在了第一位。
如果不细想的话你可能会觉得,数据库操作失败了,自然缓存也不用操作了;数据库操作成功了,再操作缓存,没毛病。
但是数据库操作成功,缓存操作的失败的情况该怎么解?(主要在用到Redis、memcached这种进程外缓存的时候,由于网络因素,失败的可能性大增)
办法也是有的,在操作数据库的时候带一个事务,如果缓存操作失败则事务回滚。大致的代码意思如下:
begin trans
var isDbSuccess = write db;
if(isDbSuccess){
var isCacheSuccess = write cache;
if(isCacheSuccess){
return success;
}
else{
rollback db;
return fail;
}
}
else{
return fail;
}
catch(Exception ex){
rollback db;
}
end trans
如此一来就万无一失了吗?
并不是。
除了由于事务的引入,增加了数据库的压力之外,在极端场景下可能会出现rollback db失败的情况。是不是很头疼?
解决这个问题的方式就是write cache的时候做delete操作,而不是set操作。如此一来,用多一次cache miss的代价来换rollback db失败的问题。
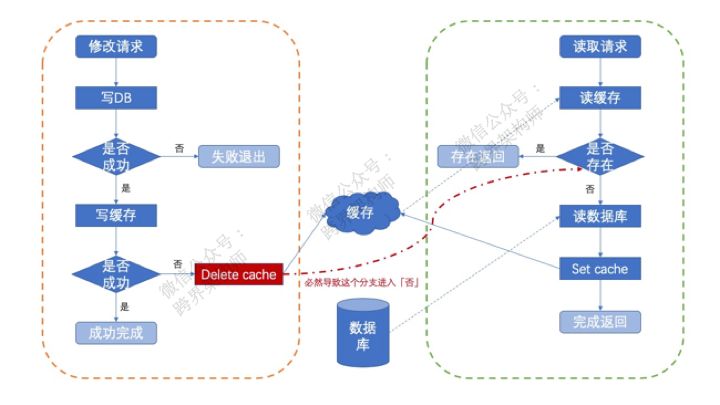
就像图上所示,哪怕rollback失败了,通过一次cache miss重新从db中载入旧值。
题外话:其实这种做法有一种专业的叫法——Cache Aside Pattern。为了便于记忆,你可以和分布式系统的CAP定理同时记忆,叫「缓存的CAP模式」。
是不是看上去妥了?可以开始潇洒了?
▲本文图片来源于网络,版权归原作者所有,侵权删
如果你的数据库没有做高可用的话,的确可以妥了。但如果数据库做了高可用,就会涉及到主从数据库的数据同步,这就有新问题了。
题外话:所以大家不要过度追求技术的酷炫,可能会得不偿失,自找麻烦。
什么问题呢?就是如果在数据还未同步到「从库」的时候,由于cache miss去「从库」取到了未同步前的旧值。
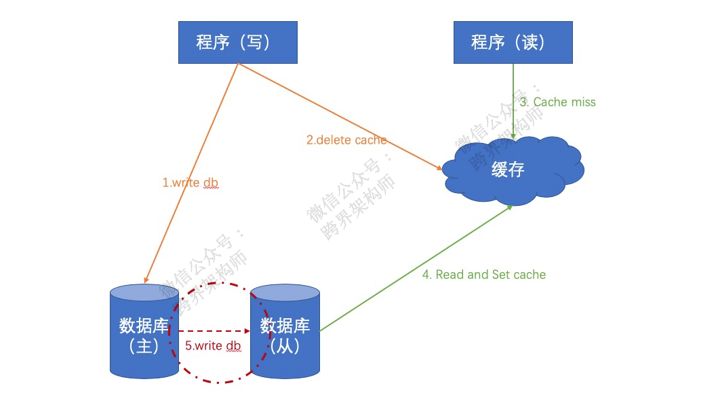
解决它的第一个方式很简单,也很粗暴。就是定时去「从库」读数据,发现数据和缓存不一样了就set到缓存里去。
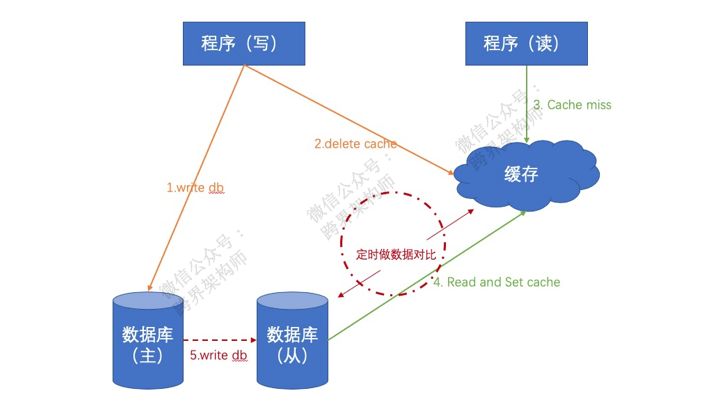
但是这个方式有点“治标不治本”。不断的从数据库定时读取,对资源的消耗大不说,这个间隔频率也不好定义一个比较合适的统一标准。太短吧,会导致重复读取的次数加大;太长吧,又会导致缓存和数据库不一致的时间变长。
所以这个方案仅适用于项目中只有2、3处需要做这种处理的场景,并且还不能是数据会频繁修改的情况。因为在数据修改频次较高的场景,甚至可能还会出现这个定时机制所消耗的资源反而大于主程序的情况。
一般情况下,另一种更普适性的方案是采用接下去聊的这种更底层的方式进行,就是“哪里有问题处理哪里”,当「从库」完成同步的时候再额外做一次delete cache或者set cache的操作。
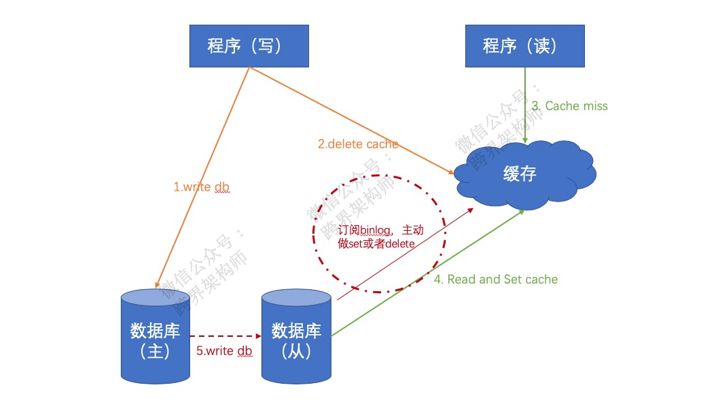
如此,虽说也没有100%解决短暂的数据不一致问题,但是已经将脏数据所存在的时长降到了最低(最终由主从同步的耗时决定),并且大大减少了无谓的资源消耗。
可能你会说,“不行,这么一点时间也不能忍”怎么办?办法是有,但是会增加「主库」的压力。就是在产生数据库写入动作后的一小段时间内强制读「主库」来加载缓存。
怎么实现呢?先得依赖一个共享存储,可以借助数据库或者也可以是我们现在正在聊的分布式缓存。
然后,你在事务提交之后往共享存储中临时存一个{ key = dbname + tablename + id,value = null,expire = 3s }这样的数据,并且再做一次delete cache的操作。
begin trans
var isDbSuccess = write db;
if(isDbSuccess){
var isCacheSuccess = delete cache;
if(isCacheSuccess){
return success;
}
else{
rollback db;
return fail;
}
}
else{
return fail;
}
catch(Exception ex){
rollback db;
}
end trans
//在这里做这个临时存储,{key,value,expire}。
delete cache;
如此一来,当「读数据」的时候发生cache miss,先判断是否存在这个临时数据,只要在3秒内就会强制走「主库」取数据。
可以看到,不同的方案各有利弊,需要根据具体的场景仔细权衡。
你工作中的大部分场景对数据准确性肯定是低容忍的,所以一般不建议选择「先缓存再DB」的方案,因为内存是易失性的。一旦遇到操作缓存成功,操作DB失败的情况,问题就来了。
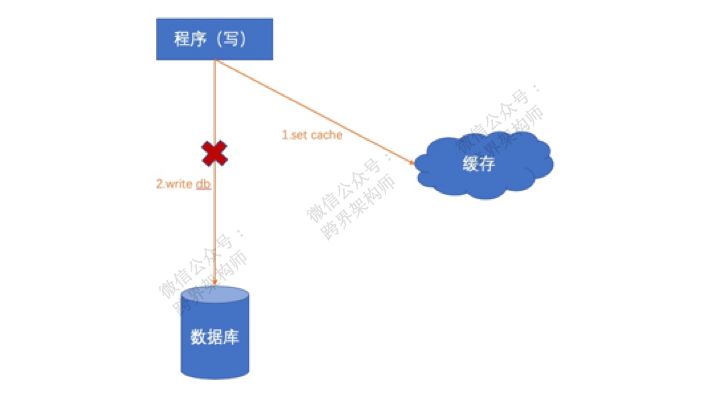
在这个时候最新的数据只有缓存里有,怎么办?单独起个线程不断的重试往数据库写?这个方案在一定程度上可行,但不适合用于对数据准确性有高要求的场景,因为缓存一旦挂了,数据就丢了!
题外话:哪怕选择了这个方案,重试线程应确保只有1个,否则会存在“ABBA”的「并发写」问题。
可能你会说用delete cache不就没问题了?
可以是可以,但要有个前提条件,访问缓存的程序不会产生并发。因为只要你的程序是多线程运行的,一旦出现并发就有可能出现「读」的线程由于cache miss从数据库取的时候,「写」的线程还没将数据写到数据库的情况。
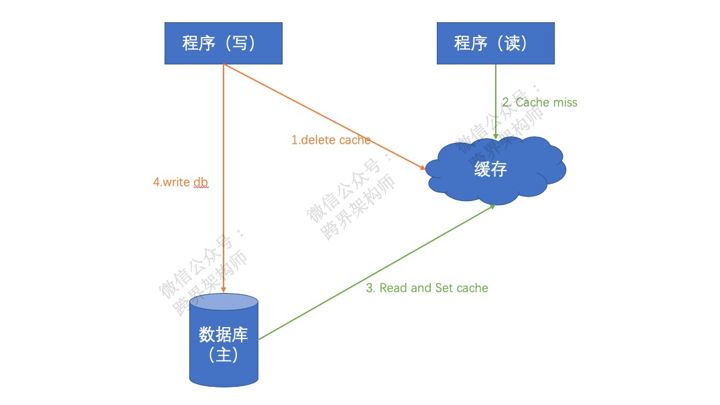
所以,哪怕用delete cache的方式,要么带lock(多客户端情况下还得上分布式锁),要么必然出现数据不一致。
值得注意的是,如果数据库同样做了高可用,哪怕带了lock,也还需要考虑和上面提到的「先DB再缓存」中一样的由于主从同步的时间差可能会产生的问题。
当然了,「先缓存再DB」也不是一文不值。当对写入速度有极致要求,而对数据准确性没那么高要求的场景下就非常好使,也就是「延迟写」机制。
总结来看,相比缓存来说,数据库的「高可用」一般会在系统发展的后期才会引入,所以在没有引入数据库「高可用」的情况下,建议你使用「先DB再缓存」的方式,并且缓存操作用delete而不是set,这样基本就可以高枕无忧了。
但是如果数据库做了「高可用」,那么团队必然也形成一定规模了,这个时候就老老实实的做数据库变更记录(binlog)的订阅吧。
到这里可能有的小伙伴要问了,“如果上了分布式缓存,还需要本地缓存吗?”
二、本地缓存还要不要?
在解答这个问题之前我们先来思考一个问题,一个分布式系统最重要的价值是什么?
是「无限扩展」,只要堆硬件就能应对业务增长。要达到这点的背后需要满足一个特性,就是程序要「无状态」。那么既想引入缓存来加速,又要达到「无状态」,靠的就是分布式缓存。
所以,能用分布式缓存解决的问题就尽量不要引入本地缓存。否则引入分布式缓存的作用就小了很多。
但是在少数场景下,本地缓存还是可以发挥其价值的,但是我们需要仔细识别出来。主要是三个场景:
不经常变更的数据。(比如一天甚至好几天更新一次的那种)
需要支撑非常高的并发。(比如秒杀)
对数据准确性能容忍的场景。(比如浏览量,评论数等)
不过,我还是建议,除了第二种场景,其余尽量还是不要引入本地缓存。根本原因在于在引入了本地缓存后,本地缓存(进程内缓存)、分布式缓存(进程外缓存)、数据库这三者之间的数据一致性该怎么进行呢?
三、本地缓存、分布式缓存、DB之间的数据一致性
如果是个单点应用程序的话,很简单,将本地缓存的操作放在最后就好了。
可能你会说本地缓存修改失败怎么办?比如重复key啊什么的异常。那你可以反思一下为这种数据为什么可以成功的写进数据库……
但是,本地缓存带来的一个巨大问题就是:虽然一个节点没问题,但是多个本地缓存节点之间的数据如何同步?
解决这个问题的方式中有两种。要么是由接收修改的节点通知其它节点变更(通过rpc或者mq皆可),要么借助一致性hash让同一个来源的请求固定落到一个节点上。后者可以让不同节点上的本地缓存数据都不重复,从源头上避免了这个问题。
但是这两个方案走的都是极端,前者变更成本太高,比如需要通知上千个节点的话,这个成本难以接受;而后者的话对资源的消耗太高,而且还容易出现压力分摊不均匀的问题。所以,一般系统规模小的时候可以考虑前者,而规模越大越会选择后者。
还有一种相对中庸一些的,以降低数据的准确性来换成本的方案。就是设置缓存定时过期或者定时往下游的分布式缓存拉取最新数据。这和前面「先DB再缓存」中提到的定时机制是一样的逻辑,胜在简单,缺点就是会存在更长时间的数据不一致。
小结一下,本地缓存的数据一致性解决方案,能彻底解决的是借助一致性hash的方案,但是成本比较高。所以,如非必要还是慎重决定要不要做本地缓存。
四、总结
好了,我们一起总结一下。
这次呢,Z哥先花了大量的篇幅和你讨论「先写DB还是缓存」的问题,并且带你层层深入,通过一点一点的演进来阐述不同的解决方案。
然后与你讨论了「本地缓存」的意义以及如何在「分布式缓存」和「数据库」的基础上做好数据一致性,这其中主要是多个本地缓存节点之间的数据同步问题。
希望对你有所启发。
这次的缓存实践是一个非常好的例子,从中我们可以看到一件事情的精细化所带来的复杂度需要更加的精细化去解决,但是又会带来新的复杂度。所以作为技术人的你,需要无时无刻考虑该怎么权衡,而不是人云亦云。
作者:ZacharyZF
来源:跨界架构师订阅号(ID:Zachary_ZF)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn

掌握数据库管理新思路,获得更优操作启发
不妨来这些技术盛会学点独家技能
↓↓扫码可了解更多详情及报名↓↓
2019 DAMS中国数据智能管理峰会-上海站