摩尔定律不管用了!AI算力3.43个月翻一倍 6年增长30万倍
看点:算力发展超越芯片发展,趋势还将继续。

智东西5月17日消息,昨天,OpenAI发布了一份名为《AI与计算》的分析报告,自2012年以来,AI训练任务所运用的算力每3.43个月就会翻倍,这一数字大大超越了芯片产业长期存在的摩尔定律(每18-24个月芯片的性能会翻一倍)。自2012年以来,AI算力增长了超过 300,000 倍(而如果是以摩尔定律的速度,只应有12倍的增长)。
硬件算力的提升一直是AI快速发展的重要因素。因此,OpenAI表示,如果我们希望目前的发展趋势持续下去,我们就需要为研发远超当前算力的全新系统做好准备。
OpenAI是2015年成立的AI非营利组织,由以埃隆·马斯克为首的诸多硅谷大亨联合建立,致力于推动AI发挥积极作用、避免AI带来的问题。
以下是OpenAI此次分析报告中的一些重点。

为何要从算力角度来看AI的发展?
推动AI发展的动力有三个:算法、数据、算力。算法是否有创新发展难以量化跟踪,而数据的巨大体量也难以计算,但算力是可以量化的,这为我们探究AI的发展进程提供了机会。
OpenAI认为,虽然使用大量的算力暴露出了当前AI算法不够高效的问题,但是,重要的技术突破依然必须在足够的算力基础上才能实现。所以,从算力的角度来审视AI的发展是合理的。
在算力的分析中,OpenAI认为起决定作用的数字并不是单个CPU的速度,也不是数据中心的最大容量,而是用于训练单个模型所需的算力——这一数值最有可能代表当前最佳算法的强大程度。
以模型计的算力需求与总算力有很大不同,因为并行计算的限制(硬件和算法上)使得模型不可能太大,训练的效率也不会太高。
OpenAI发现,目前,算力发展的趋势是每年大约增加10倍。这种增长的实现,部分是因为有更为专业的硬件(如GPU和TPU)使得芯片每秒能够执行更多操作,但主要还是因为有研究人员们不断寻找更好的并行计算方法,并花费大量资金才实现的。

OpenAI是如何计量算力的?
AI深度学习模型需要耗费大量时间和算力,若有足够的信息,就可以估计出已知训练结果的总算力需求。
这份分析报告中,OpenAI使用petaflop/s-day(pfs-day)作为算力的计量单位。一个单位的petaflop/s-day(pfs-day)代表在一天时间内每秒执行10^15 次,总计约为10^20次神经网络操作(operations)。这种计量方法类似于电能的千瓦时。
OpenAI不测量硬件FLOPS数的理论峰值,而是尝试估计执行的实际操作数量。OpenAI将任何加法或乘法计为单个操作,而不考虑数值精度,同时忽略集成模型。
通过OpenAI的计算,目前每次算力翻倍的时间为3.43个月。

OpenAI在分析报告中给出了两张图表,展示了最为人熟知的几个AI机器学习模型以petaflop/s-days计的计算总量,即其所需的算力。
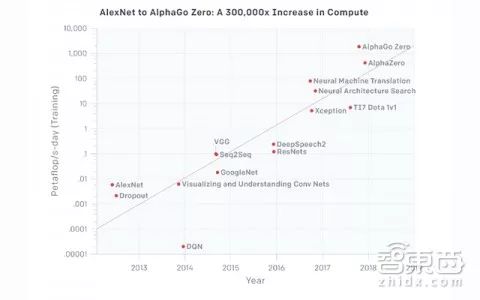
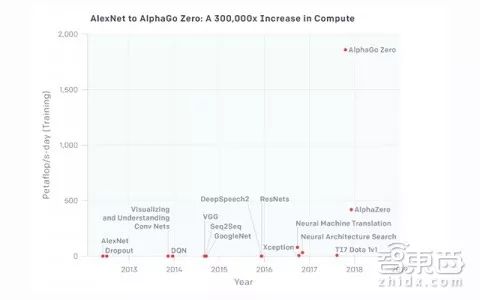
▲几个最为人熟知的AI机器学习模型以petaflop/s-days计的计算总量,即其所需的算力
从图表中我们可以发现AI算力发展分为4个时期。
2012年之前:使用GPU进行机器学习还不常见,因此,在这个时期,图中显示的最小算力都难以达到。
2012年-2014年:使用很多个GPU进行模型训练的基础架构还不常见,这个时期多使用1-8个速度为1-2TFLOPS的GPU进行训练,可达到0.001-0.1 pfs-days的算力水平。
2014年-2016年:普遍使用10-100个速度为5-10 TFLOPS的GPU进行大规模的模型训练,可达到0.001-0.1 pfs-days的算力水平。这个时期的数据说明,减少数据并行化的返回值带来的收益会递减,这意味着更大规模的模型训练带来的价值是有限的。
2016年-2017年:出现可以实现更大规模算法并行化的方法(如较大的批量规模、架构搜索和专家迭代)以及使用专用硬件(如TPU和更快速的网络连接),极大地突破了算力的限制,尤其是对某些模型来说。
AlphaGo Zero和AlphaZero是大家熟悉的大型算法并行化例子,而很多其他同等规模的应用现在在算法层面上也是可行的,而且也可能已经投入了应用。

算力会继续快速发展,我们该未雨绸缪
OpenAI认为,人类的算力需求每3.43个月就会翻倍,每年大约增加10倍,这样的发展趋势将会继续。
很多创业公司都在开发AI专用的芯片,一些企业声称他们将在接下来一两年大幅提高芯片的算力。这样一来,人们就可以仅仅通过重新配置硬件,以更少的经济成本得到强大的算力。而在并行性方面,很多近期出现的新算法在原则上也可以结合,例如,架构搜索和大规模并行SGD。
另一方面,并行化算法的发展会被经济成本限制,而芯片效率的发展将会被物理上的局限所限制。OpenAI认为,虽然如今最大规模的AI模型训练使用的硬件,仅单个硬件就要花费百万美元的采购成本(尽管摊销下来,成本已经低了很多)。但今天的神经网络计算的主体部分仍然在于推理阶段,而不是模型训练阶段,这意味着企业可以重新改装或采购更多的芯片用于模型训练。
因此,如果有足够的经济基础,我们甚至可以看到更多的大规模并行训练,从而使这一趋势持续数年。全世界的总体硬件预算是每年1万亿美元,可以看到,经济成本对并行化算法的发展限制仍然远未达到。
OpenAI认为,对于这种趋势将持续多久,以及持续下去会发生什么,用过去的趋势来预测是不足够的。
但是,即使算力增长的潜力目前处于我们可以掌控的范围,也必须从今天就为研发远超当前算力的全新系统做好准备,并开始警觉AI的安全问题和恶意使用问题。
这种远见对于负责任的政策制定和负责任的技术发展都至关重要,我们必须走在这些趋势前面,而不是对这些趋势置之不理。
本账号系网易新闻·网易号“各有态度”签约帐号
延伸阅读

加入社群
智东西“人工智能专业社群”开始招募工程师及研究者
AI行业解读、技术交流、企业追踪
微信加zhidx009递交名片入群
合作勾搭
文章转载微信:zhidx_com
媒体合作:marketing@zhidx.com
商务合作微信:hillsmart




