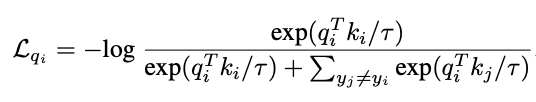随着 MoCo 的提出,无监督学习在计算机视觉领域已经取得了不错的效果,其在七项检测分割任务上完胜有监督预训练。这也引起众多研究者的思考:为什么不用标签的学习可以超越有标签的学习呢?近日,来自微软亚洲研究院和香港城市大学的一项研究对此作出了解答。
![]()
论文链接:https://arxiv.org/pdf/2006.06606.pdf
利用带有大量人工标注标签的数据集(ImageNet)进行预训练曾经是大多数视觉应用的标准做法。然而,随着 MoCo 在多项检测分割任务上完胜有监督预训练,成本高昂的人工标注似乎不再像以往那么重要。在微软亚洲研究院和香港城市大学的一项研究中,作者从 MoCo 预训练和目标检测的迁移出发,深入探讨了为什么无监督训练在迁移任务上更有优势?结合新的发现,是否有可能改进有监督的预训练?
MoCo 是一种通过区分不同实例 (instance discrimination)的 pretext task 进行无监督训练的方法。此类方法在训练时希望可以将当前实例的特征与其他实例拉开,同时拉近当前实例不同变换(比如裁剪和平移)的特征表示。
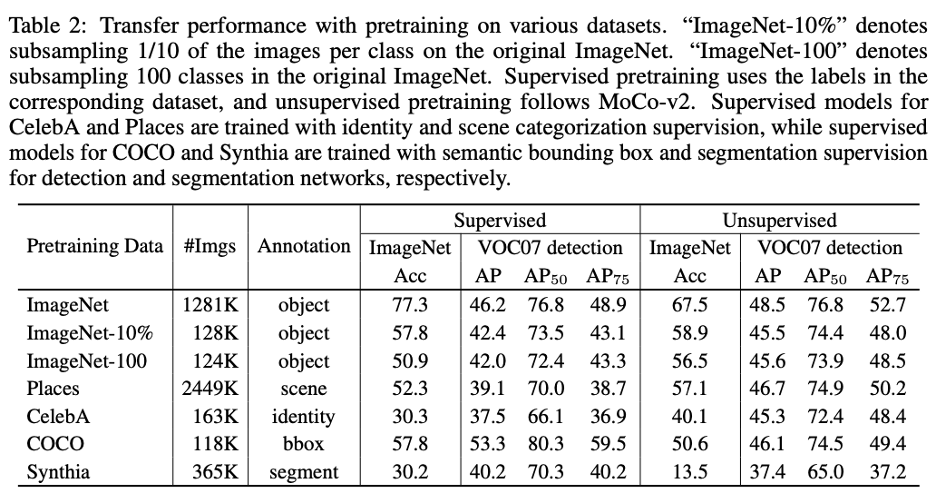
首先,为了确认是否无监督学习在目标检测上存在绝对的优势,作者在考虑多种因素下进行了公平的比较(很遗憾的是,MoCo 原始论文并没有很公正的比较有监督预训练)。考虑因素有:预训练时间、微调时间以及图像变换 / 增广方法。
如下表所示,(1)增加某些图像增广方法(color jittering and random grayscaling)对有监督预训练也是有用的,但还是不如无监督预训练,尤其在 AP 和 AP75 上。(2)两种预训练方法都没有过拟合的现象,预训练时间越长,迁移后性能也越高。微调时,虽然有监督预训练收敛更迅速,但并没有得到最优解。可以肯定的是,在目标检测上,MoCo 确实是比有监督预训练有性能上的优势。
![]()
结论二:无监督的预训练模型主要迁移了低层和中层的特征,而非高层语义
无监督在线性分类任务上取得了不错的性能,似乎印证了无监督学习也学习到了高层次的语义信息,但该文通过实验质疑了这个结论。当尝试在不同数据集上进行预训练,即使这些数据和 Pascal VOC 包含的图像大相径庭 (比如人脸),也能取得不错的迁移性能。尝试的数据集如下所示。
相反,当预训练数据集和下游数据集的底层信息不同时,比如利用游戏合成的驾驶场景数据集,性能有一定程度的下降。因此验证 MoCo 主要迁移了 low-level 和 mid-level 的特征表示。
![]()
为了进一步解释为何无监督预训练在目标检测上效果更好,作者又做了如下实验:
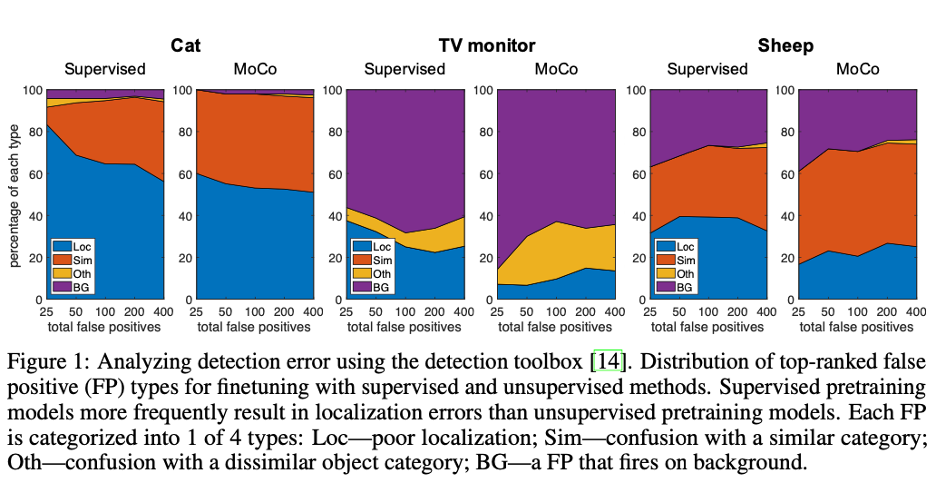
(1)通过分析检测错误(false positive), 无监督预训练能得到更准确的位置信息。
(2)当利用 Deep image prior 从 layer4 进行图像重建时,无监督重建的图像更接近于原图并且更加完整。虽然 MoCo 训练时也包含了位置尺度不变性,但却能在重建中保持正确的尺度和位置。相反,有监督的学习过度关注物体的局部区域, 丢失了很多对于精确定位的重要信息。该文认为 instance discrimination 方法为了保证当前实例区别与其他所有实例,尽可能的保留了更多的信息。
![]()
![]()
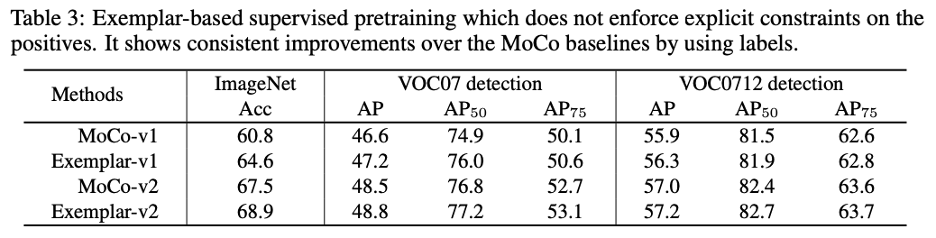
大量的标注数据包含了丰富的语义信息,应该对下游任务有所帮助。但传统的有监督预训练是通过减小 intra-class variation 进行学习的,模型会更多关注对特定类有识别力(discriminative)的区域,从而忽略了其他可能包含有用信息的区域。一个更好的有监督预训练方法应该仅仅拉远不同类(true negative)的实例,而不对同类样本加以任何约束。这样可以更好地保留每个实例的特征。参考 examplar SVM 的方法,作者在 instance discrimination 的损失函数上进行了改进。对于一个属于类别 y_i 的实例 x_i, 它的特征表示为 q_i, 该函数在特征空间上拉远了当前实例与其他不同类的实例 (true negative)。
![]()
实验证明,这种方式(Exemplar)在图像分类和目标识别两个下游任务上都相对于 MoCo 得到了提升。
![]()
(1)小样本学习(Mini-ImageNet dataset, Exemplar 明显在基础类和新的类别上都取得了更好地准确度。
(2) 人脸关键点检测(MAFL dataset),有监督预训练相对较差的结果表明身份识别和关键点检测两个任务存在一定差异,一个人的身份不能决定他在照片中的姿态。此文提出的 Exemplar 预训练方法可以减弱这种差异,取得和 MoCo 一样的性能。
![]()
7月11日09:00-12:00,机器之心联合百度在WAIC 2020云端峰会上组织「开发者日百度公开课」,为广大开发者提供 3 小时极致学习机会,从 NLP、CV 到零门槛 AI 开发平台 EasyDL,助力开发者掌握人工智能开发技能。扫描图中二维码,加机器之心小助手微信邀您入群。
![]()