KNN算法的机器学习基础

本文为 AI 研习社编译的技术博客,原标题 :
Machine Learning Basics with the K-Nearest Neighbors Algorithm
翻译 | 小哥哥、江舟 校对 | 吕鑫灿 整理 | 志豪
原文链接:
https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761
基于K近邻算法的机器学习基础
k近邻( KNN )算法是一种简单、易于实现的监督机器学习算法,可用于解决分类和回归问题。暂停!让我们从这里入手。

我们接下来将保持它超级简单!
把问题分解
有监督的机器学习算法(与无监督的机器学习算法相反)是一种依靠标记的输入数据来学习函数的算法,当给定新的未标记数据时,该函数会产生适当的输出。
想象一下,一台计算机当做一个孩子,我们是它的主管(例如父母、监护人或老师),我们希望孩子(计算机)能了解猪是什么样子。我们向孩子展示几幅不同的照片,其中一些是猪,其余的可能是任何东西的照片(猫、狗等)。
当我们看到一只猪时,我们喊“猪!”!当它不是猪时,我们喊“不,不是猪!”!和孩子一起做了几次之后,我们给他们看了一张照片,然后问“猪?他们会正确地(大多数时候)说“猪!”!“或者”不,不是猪!“取决于照片是什么。这就是有监督的机器学习。

“猪!”
有监督机器学习算法用于解决分类或回归问题。
分类问题的输出是离散值。例如,“喜欢比萨上的菠萝”和“不喜欢比萨上的菠萝”是离散的。没有中间地带。上面教孩子识别猪的类比是分类问题的另一个例子。
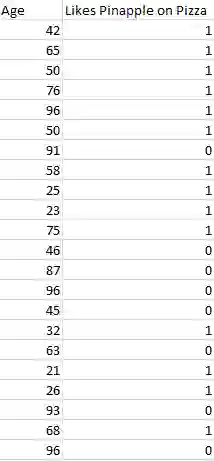
显示随机生成数据的图像
这张图片展示了分类数据可能是什么样子的基本例子。我们有一个预测器(或一组预测器)和一个标签。在这张图片中,我们可能试图根据年龄(预测因子)来预测某人是(1)否(0)喜欢比萨饼上的菠萝。
标准做法是将分类算法的输出(标签)表示为整数,例如1、-1或0。在这种情况下,这些数字纯粹是代表性的。不应该对它们进行数学运算,因为这样做毫无意义。想一想。什么是“喜欢菠萝”+“不喜欢菠萝”?没错。我们不能相加它们,所以我们不应该把数字表示特征相加。
回归问题有一个实数(带有小数点的数字)作为输出。例如,我们可以使用下表中的数据来估计给定身高的人的体重。
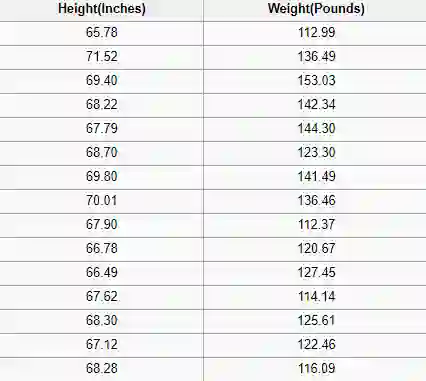
图像显示了SOCR高度和权重数据集的一部分
回归分析中使用的数据看起来类似于上图所示的数据。我们有一个自变量(或一组自变量)和一个因变量(试图在给定自变量的情况下猜测因变量)。例如,我们可以说高度是自变量,而重量是因变量。
此外,每行通常称为示例、观察或数据点,而每列(不包括标签/因变量)通常称为预测值、维度、自变量或特征。
无监督的机器学习算法使用没有任何标签的输入数据——换句话说,没有老师(标签)告诉孩子(计算机)什么时候是正确的,什么时候是错误的,这样它就可以自我纠正。
与试图学习一种函数的监督学习不同,这种函数允许我们在给定一些新的未标记数据的情况下进行预测,无监督学习试图学习数据的基本结构,从而让我们对数据有更多的了解。
最近邻
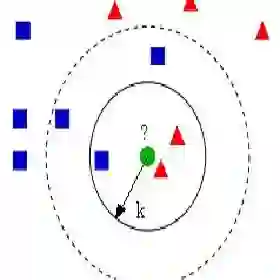
KNN算法假设相似的东西存在于很近的地方。换句话说,相似的事物彼此接近。
“物以类聚。"
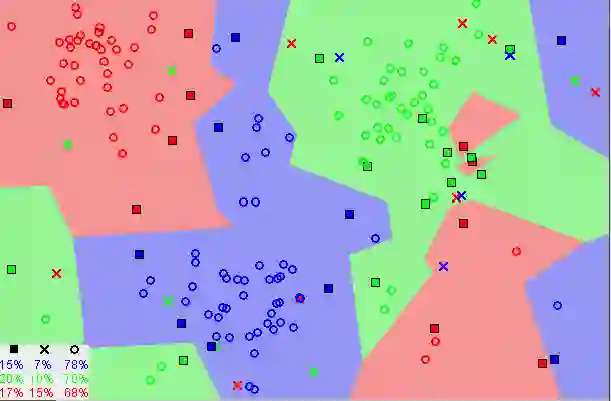
显示相似数据点通常如何彼此靠近存在的图像
请注意,在上图中,大多数情况下,相似的数据点彼此接近。KNN算法就是基于这个假设以使算法有用。KNN利用与我们童年时可能学过的一些数学相似的想法(有时称为距离、接近度或接近度),即计算图上点之间的距离。
注意:在继续之前,有必要了解我们如何计算图表上的点之间的距离。如果你不熟悉或需要复习计算方法,请完整阅读“两点之间的距离”,然后再回来。
还有其他计算距离的方法,其中一种方法可能更好,这取决于我们正在解决的问题。然而,直线距离(也称为欧氏距离)是一个流行且熟悉的选择。
KNN算法(英文)
1. 加载数据
2. 将K初始化为你选择的邻居数量
3. 对于数据中的每个示例
3.1 根据数据计算查询示例和当前示例之间的距离。
3.2 将示例的距离和索引添加到有序集合中
4. 按距离将距离和索引的有序集合从最小到最大(按升序)排序
5. 从已排序的集合中挑选前K个条目
6. 获取所选K个条目的标签
7. 如果回归,返回K个标签的平均值
8. 如果分类,返回K个标签的模式
KNN实现(从头开始)
from collections import Counter
import math
def knn(data, query, k, distance_fn, choice_fn):
neighbor_distances_and_indices = []
# 3. For each example in the data
for index, example in enumerate(data):
# 3.1 Calculate the distance between the query example and the current
# example from the data.
distance = distance_fn(example[:-1], query)
# 3.2 Add the distance and the index of the example to an ordered collection
neighbor_distances_and_indices.append((distance, index))
# 4. Sort the ordered collection of distances and indices from
# smallest to largest (in ascending order) by the distances
sorted_neighbor_distances_and_indices = sorted(neighbor_distances_and_indices)
# 5. Pick the first K entries from the sorted collection
k_nearest_distances_and_indices = sorted_neighbor_distances_and_indices[:k]
# 6. Get the labels of the selected K entries
k_nearest_labels = [data[i][1] for distance, i in k_nearest_distances_and_indices]
# 7. If regression (choice_fn = mean), return the average of the K labels
# 8. If classification (choice_fn = mode), return the mode of the K labels
return k_nearest_distances_and_indices , choice_fn(k_nearest_labels)
def mean(labels):
return sum(labels) / len(labels)
def mode(labels):
return Counter(labels).most_common(1)[0][0]
def euclidean_distance(point1, point2):
sum_squared_distance = 0
for i in range(len(point1)):
sum_squared_distance += math.pow(point1[i] - point2[i], 2)
return math.sqrt(sum_squared_distance)
def main():
'''
# Regression Data
#
# Column 0: height (inches)
# Column 1: weight (pounds)
'''
reg_data = [
[65.75, 112.99],
[71.52, 136.49],
[69.40, 153.03],
[68.22, 142.34],
[67.79, 144.30],
[68.70, 123.30],
[69.80, 141.49],
[70.01, 136.46],
[67.90, 112.37],
[66.49, 127.45],
]
# Question:
# Given the data we have, what's the best-guess at someone's weight if they are 60 inches tall?
reg_query = [60]
reg_k_nearest_neighbors, reg_prediction = knn(
reg_data, reg_query, k=3, distance_fn=euclidean_distance, choice_fn=mean
)
'''
# Classification Data
#
# Column 0: age
# Column 1: likes pineapple
'''
clf_data = [
[22, 1],
[23, 1],
[21, 1],
[18, 1],
[19, 1],
[25, 0],
[27, 0],
[29, 0],
[31, 0],
[45, 0],
]
# Question:
# Given the data we have, does a 33 year old like pineapples on their pizza?
clf_query = [33]
clf_k_nearest_neighbors, clf_prediction = knn(
clf_data, clf_query, k=3, distance_fn=euclidean_distance, choice_fn=mode
)
if __name__ == '__main__':
main()
为K选择正确的值
为了选择适合你的数据的K,我们用不同的K值运行了几次KNN算法,并选择K来减少我们遇到的错误数量,同时保持算法在给定之前从未见过的数据时准确预测的能力。
以下是一些需要记住的事情:
当我们将K值降低到1时,我们的预测会变得不稳定。试想一下,图像K = 1,我们有一个查询点,周围有几个红色和一个绿色(我在考虑上面彩色图的左上角),但是绿色是唯一最近的邻居。合理地说,我们会认为查询点很可能是红色的,但是因为K = 1,KNN错误地预测查询点是绿色的。
相反,随着K值的增加,由于多数投票/平均,我们的预测变得更加稳定,因此更有可能做出更准确的预测(直到某一点)。最终,我们开始看到越来越多的错误。正是在这一点上,我们知道我们把K的价值推得太远了。
如果我们在标签中进行多数投票(例如,在分类问题中选择模式),我们通常会将K设为奇数,以便有一个决胜局。
优势
该算法简单易行。
没有必要建立模型,调整多个参数,或者做额外的假设。
该算法是通用的。它可以用于分类、回归和搜索(我们将在下一节中看到)。
缺点
随着示例和/或预测器/独立变量数量的增加,算法变得非常慢。
KNN在实践中
KNN的主要缺点是随着数据量的增加变得非常慢,这使得在需要快速做出预测的环境中,变成了一个不切实际的选择。此外,有更快的算法可以产生更准确的分类和回归结果。
然而,如果你有足够的计算资源来快速处理你用来预测的数据,KNN仍然有助于解决那些有依赖于识别相似对象的解决方案的问题。这方面的一个例子是在推荐系统中使用KNN算法,这是KNN搜索的应用。
推荐系统
从规模上看,这就像是在亚马逊上推荐产品,在媒体上推荐文章,在Netflix上推荐电影,或者在YouTube上推荐视频。尽管如此,我们可以肯定,由于他们处理的数据量巨大,他们都使用了更有效的方法来提出推荐。
然而,我们可以使用本文中所学的知识,以较小的规模复制其中一个推荐系统。那么让我们构建一个电影推荐系统的核心。
我们想回答什么问题?
给定我们的电影数据集,与电影查询最相似的5部电影是什么?
收集电影数据
如果我们在Netflix、Hulu或IMDb工作,我们可以从他们的数据仓库中获取数据。但因为我们不在这些公司工作,所以我们必须通过其他方式获取数据。我们可以使用来自UCI机器学习库、IMDb数据集的一些电影数据,或者费力地创建我们自己的数据。
探索、清理和准备数据
无论我们从哪里获得数据,都可能存在一些问题,我们需要纠正这些问题,为KNN算法做准备。例如,数据可能不是算法期望的格式,或者在将数据送入算法之前,可能缺少数据,故我们应该填充或删除它们。
我们上面的KNN实现依赖于结构化数据。它需要表格格式。此外,该实现假设所有列都包含数字数据,并且我们数据的最后一列具有可以对其执行某些功能的标签。因此,无论我们从哪里获得数据,我们都需要使其符合这些约束。
下面的数据是我们清理过的数据可能类似的一个例子。该数据包含30部电影,包括七种类型的每部电影的数据及其IMDB评级。标签的列全为零,因为我们没有使用这个数据集进行分类或回归。
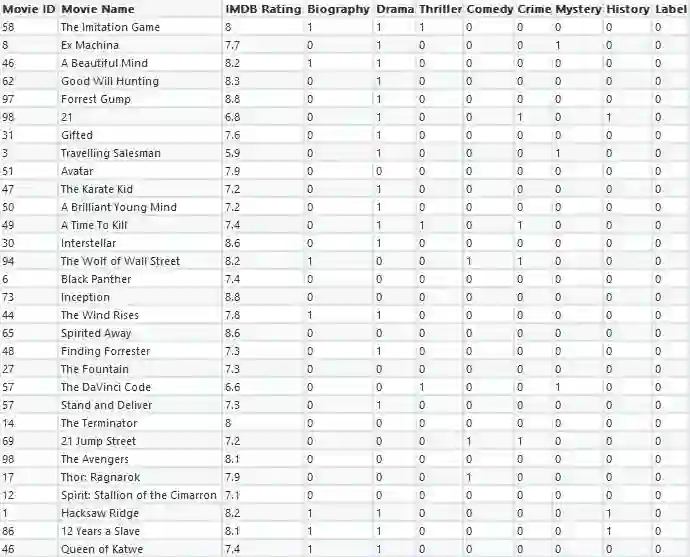
自制电影推荐数据集
此外,在使用KNN算法时,电影之间有一些关系不会被考虑(例如演员、导演和主题),这仅仅是因为数据集中缺少捕捉这些关系的数据。因此,当我们对我们的数据运行KNN算法时,相似性将完全基于包括的类型和电影的IMDB评级。
使用算法
想象一下。我们正在浏览MoviesXb网站,这是一个虚构的IMDb衍生产品,我们遇到了《邮报》。我们不确定是否想看它,但是它的类型吸引了我们;我们对其他类似的电影很好奇。我们向下滚动到“更像这个”部分,看看MoviesXb会提出什么建议,算法齿轮开始转动。
MoviesXb网站向其后端发送了一个请求,要求获得5部最类似《华盛顿邮报》的电影。后端有一个与我们完全一样的推荐数据集。它首先为《华盛顿邮报》创建行表示(被广泛称为特征向量),然后运行类似于下面的程序来搜索与《华盛顿邮报》最相似的5部电影,最后将结果发送回MoviesXb网站。
from knn_from_scratch import knn, euclidean_distance
def recommend_movies(movie_query, k_recommendations):
raw_movies_data = []
with open('movies_recommendation_data.csv', 'r') as md:
# Discard the first line (headings)
next(md)
# Read the data into memory
for line in md.readlines():
data_row = line.strip().split(',')
raw_movies_data.append(data_row)
# Prepare the data for use in the knn algorithm by picking
# the relevant columns and converting the numeric columns
# to numbers since they were read in as strings
movies_recommendation_data = []
for row in raw_movies_data:
data_row = list(map(float, row[2:]))
movies_recommendation_data.append(data_row)
# Use the KNN algorithm to get the 5 movies that are most
# similar to The Post.
recommendation_indices, _ = knn(
movies_recommendation_data, movie_query, k=k_recommendations,
distance_fn=euclidean_distance, choice_fn=lambda x: None
)
movie_recommendations = []
for _, index in recommendation_indices:
movie_recommendations.append(raw_movies_data[index])
return movie_recommendations
if __name__ == '__main__':
the_post = [7.2, 1, 1, 0, 0, 0, 0, 1, 0] # feature vector for The Post
recommended_movies = recommend_movies(movie_query=the_post, k_recommendations=5)
# Print recommended movie titles
for recommendation in recommended_movies:
print(recommendation[1])
当我们运行这个程序时,我们看到MoviesXb推荐了《为奴十二年》,《钢锯岭》,《卡推女王》,《起风了》,还有《美丽心灵》。既然我们完全理解KNN算法是如何工作的,我们就能够准确地解释KNN算法是如何提出这些建议的。恭喜你!
总结
k最近邻( KNN )算法是一种简单的有监督的机器学习算法,可用于解决分类和回归问题。这很容易实现和理解,但是有一个主要缺点,就是随着使用中数据的大小增加速度会明显变慢。
KNN通过查找查询和数据中所有示例之间的距离来工作,选择最接近查询的指定数字示例( K ),然后选择最常用的标签(在分类的情况下)或平均标签(在回归的情况下)。
在分类和回归的情况下,我们看到为我们的数据选择正确的K是通过尝试几个K并选择最有效的一个来完成的。
最后,我们看了一个KNN算法如何应用于推荐系统的例子,这是KNN搜索的一个应用。

KNN就像.....“让我看看你的朋友,我来告诉你谁是。”
附录
[1]为了简单起见,本文中实现的KNN电影推荐器不处理电影查询有可能是推荐数据集的一部分的情况。 在生产系统中可能是不合理的,应该处理相同的问题。
如果你学到了一个新东西或者喜欢这篇文章,请点赞并且分享它,这样可以让更多的人看到。你可以自由地留下你的评论。
想要继续查看该篇文章更多代码、链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1027
AI研习社每日更新精彩内容,点击文末【阅读原文】即可观看更多精彩内容:
良心推荐:一份 20 周学习计算机科学的经验贴(附资源)
如何建立预测大气污染日的概率预测模型
如何基于 Keras, Python,以及深度学习进行多 GPU 训练
7月最好的机器学习GitHub存储库和Reddit线程
等你来译:
2018年25家值得关注的机器学习初创企业
安卓 Smart Links 技术背后的机器学习模型
基于机器学习算法的室内运动时间序列分类
为什么现在人工智能掀起热潮?