谷歌推出 Bigtable 联邦查询,实现零 ETL 数据分析

最近,谷歌宣布 Bigtable 联邦查询普遍可用,用户通过 BigQuery 可以更快地查询 Bigtable 中的数据。此外,查询无需移动或复制所有谷歌云区域中的数据,增加了联邦查询并发性限制,从而缩小了运营数据和分析数据之间长期存在的差距。
BigQuery 是谷歌云的无服务器、多云数据仓库,通过将不同来源的数据汇集在一起来简化数据分析。Cloud Bigtable 是谷歌云的全托管 NoSQL 数据库,主要用于对时间比较敏感的事务和分析工作负载。后者适用于多种场景,如实时欺诈检测、推荐、个性化和时间序列。
在以前,用户需要使用 ETL 工具(如 Dataflow 或者自己开发的 Python 工具)将数据从 Bigtable 复制到 BigQuery。现在,他们可以直接使用 BigQuery SQL 查询数据。联邦查询 BigQuery 可以访问存储在 Bigtable 中的数据。
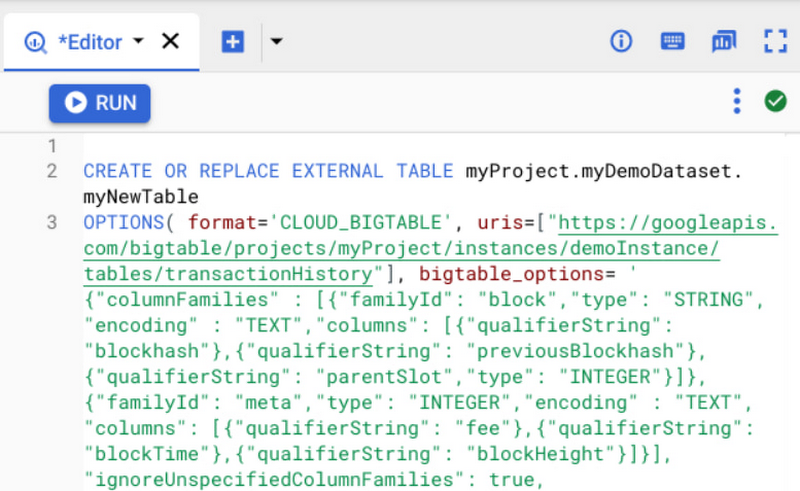
要查询 Bigtable 中的数据,用户可以通过指定 Cloud Bigtable URI(可以通过 Cloud Bigtable 控制台获得)为 Cloud Bigtable 数据源创建一个外部表。URI 包含以下这些内容:
包含 Cloud Bigtable 实例的项目 ID——project_id;
Cloud Bigtable 实例 ID——instance_id;
要使用的应用程序配置文件 ID——app_profile(可选);
要查询的表名——table_name。
来源:https://cloud.google.com/blog/products/data-analytics/bigtable-bigquery-federation-brings-hot--cold-data-closer
在创建了外部表之后,用户就可以像查询 BigQuery 中的表一样查询 Bigtable。此外,用户还可以利用 BigQuery 的特性,比如 JDBC/ODBC 驱动程序、用于商业智能的连接器、数据可视化工具(Data Studio、Looker 和 Tableau 等),以及用于训练机器学习模型的 AutoML 表和将数据加载到模型开发环境中的 Spark 连接器。
大数据爱好者 Christian Laurer 在一篇文章中解释了 Bigtable 联邦查询的好处。
你可以使用这种新的方法克服传统 ETL 的一些缺点,如:
更多的数据更新(为你的业务提供最新的见解,没有小时级别甚至天级别的旧数据);
不需要为相同的数据存储支付两次费用(用户通常会在 Bigtable 中存储 TB 级甚至更多的数据);
减少 ETL 管道的监控和维护。
最后,关于 Bigtable 联邦查询的更多详细信息,请参阅官方的文档页。此外,所有受支持的 Cloud Bigtable 区域都可以使用新的联邦查询。
原文链接:
https://www.infoq.com/news/2022/08/bigtable-bigquery-zero-etl/
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
“华为 30 岁以下员工仅占 28%”上热搜;腾讯二季度净利润腰斩,员工减少超 5500 人;百度网盘回应人工审核用户照片|Q 资讯



