澎思科技首席科学家申省梅:视频图像智能化,打造完善有效的智慧安防局面
 作者 | Camel
作者 | Camel

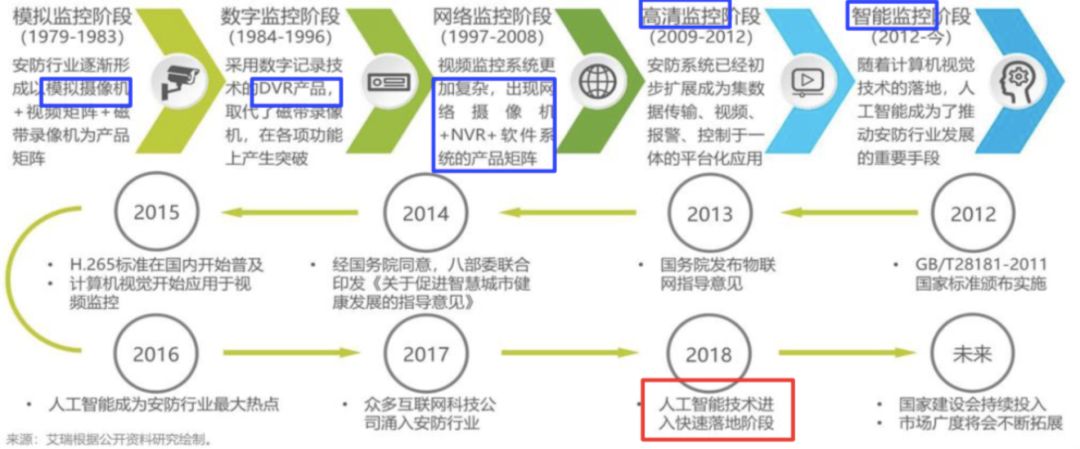
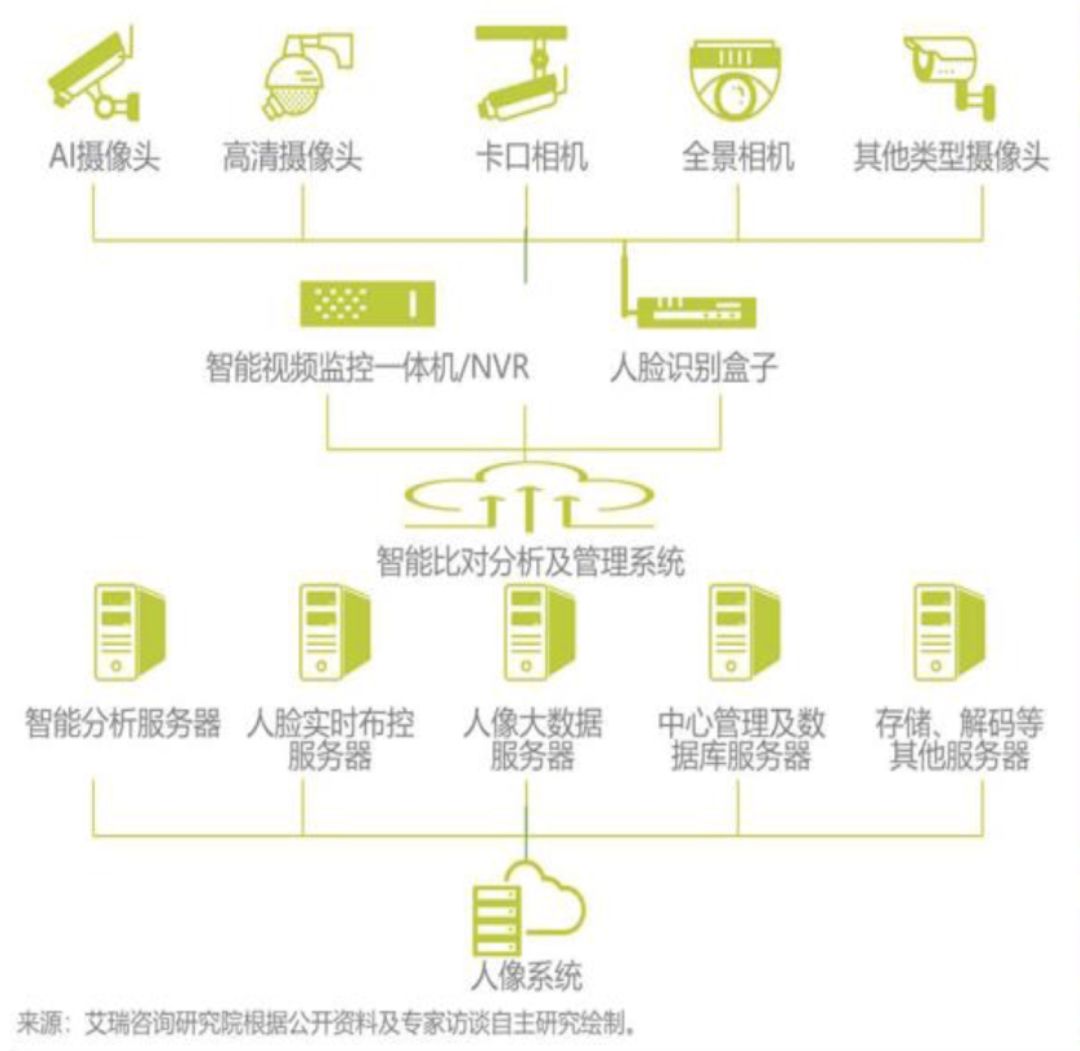
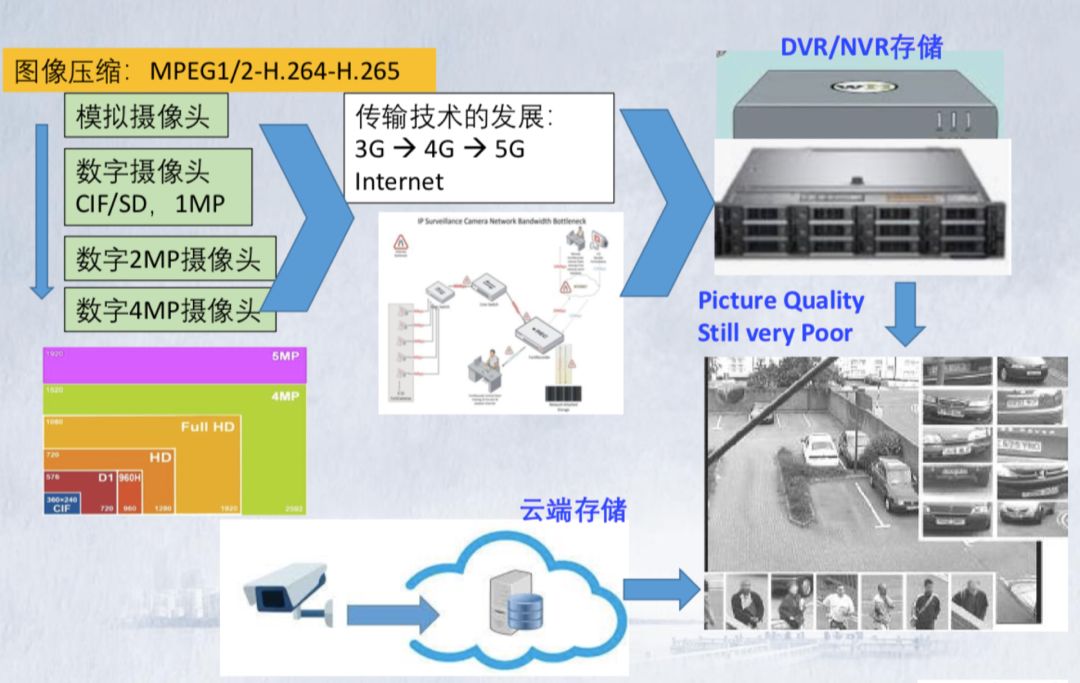
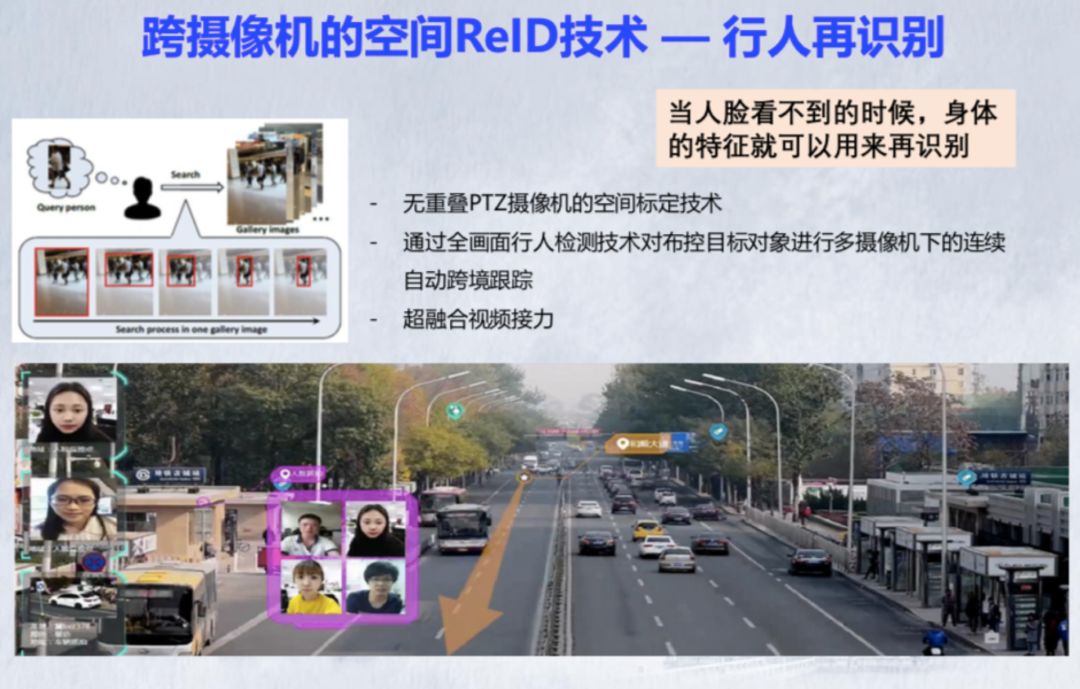
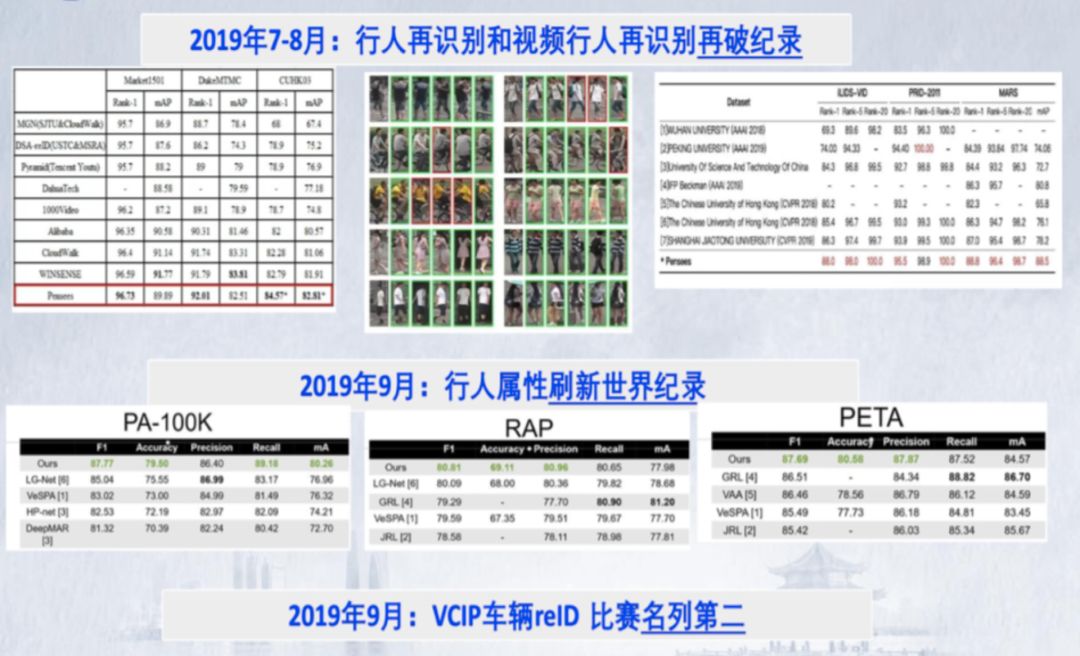
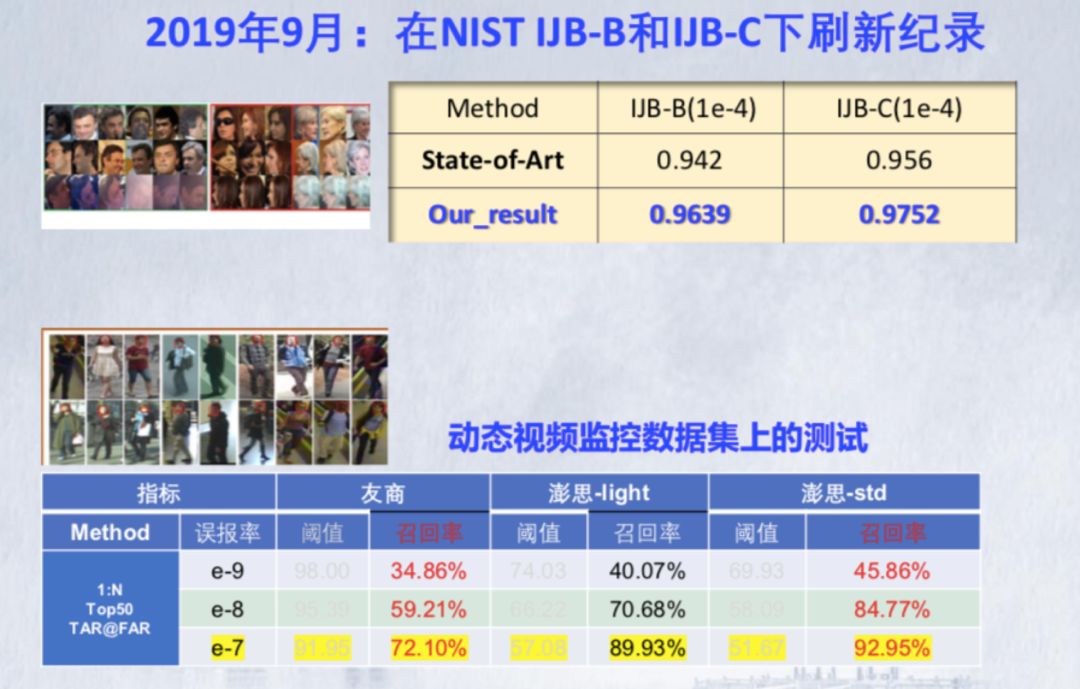
视频图像智能化
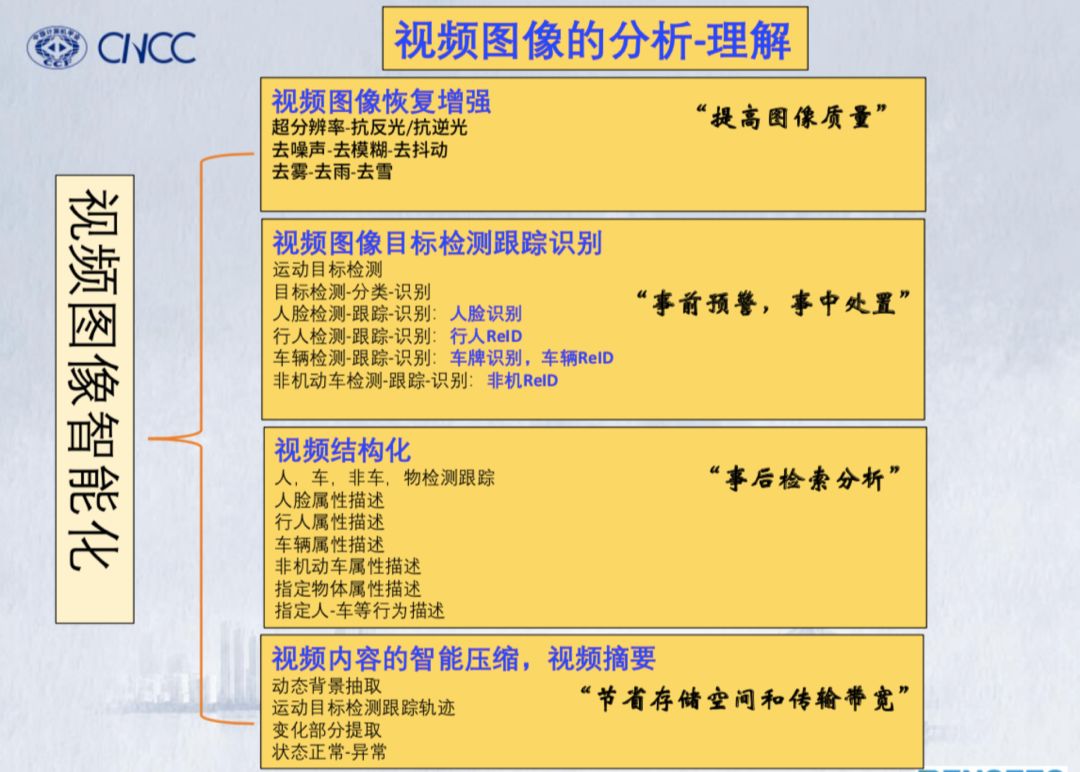
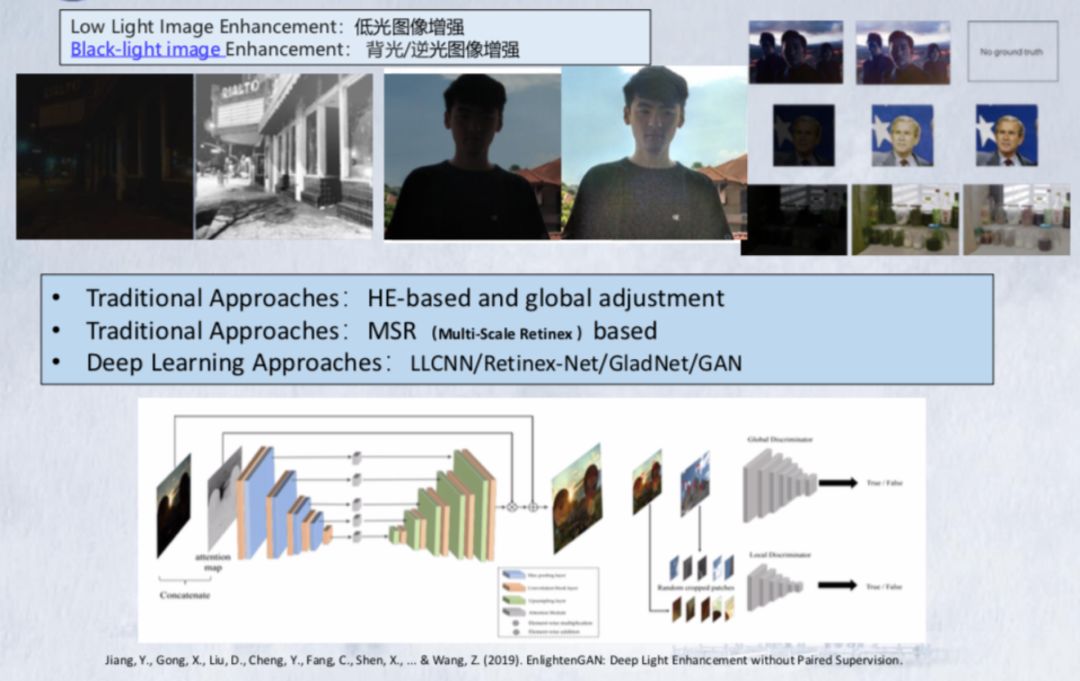
1、视频图像恢复增强








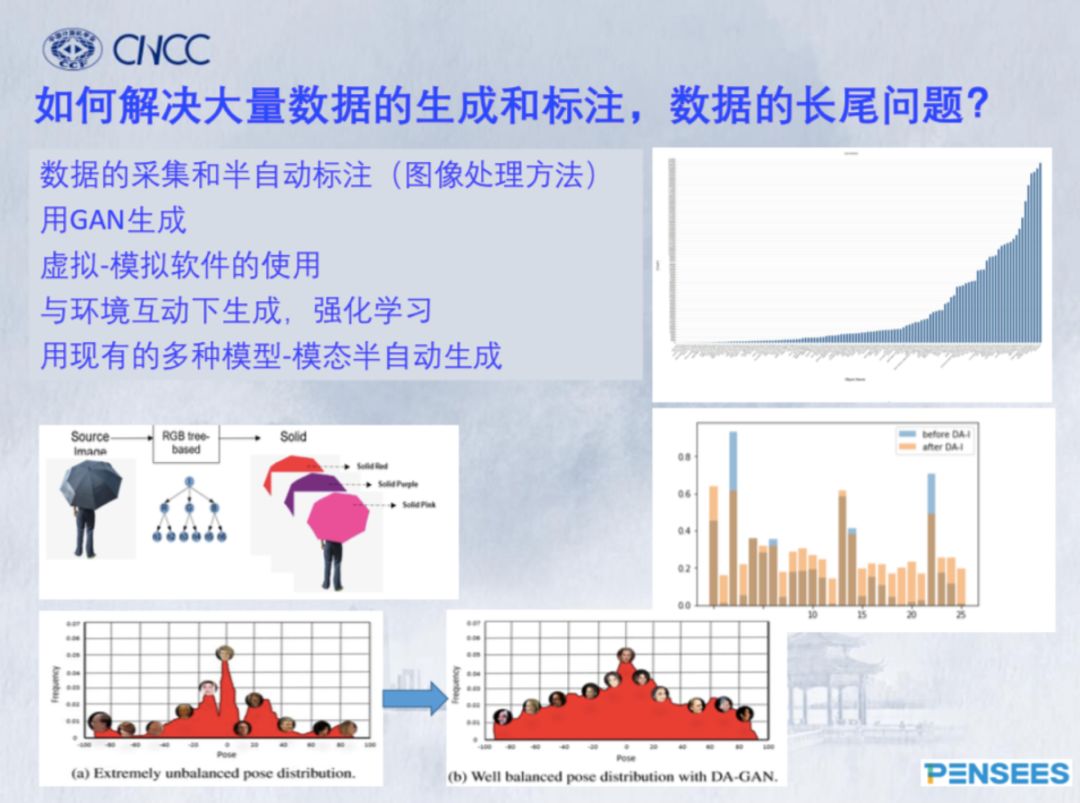
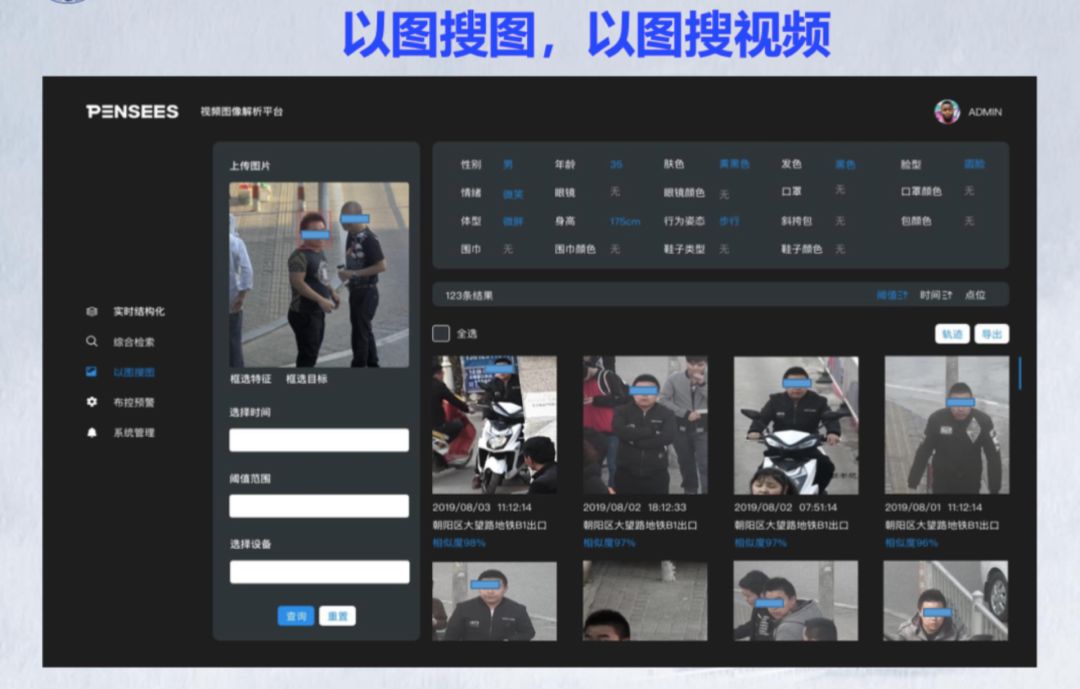


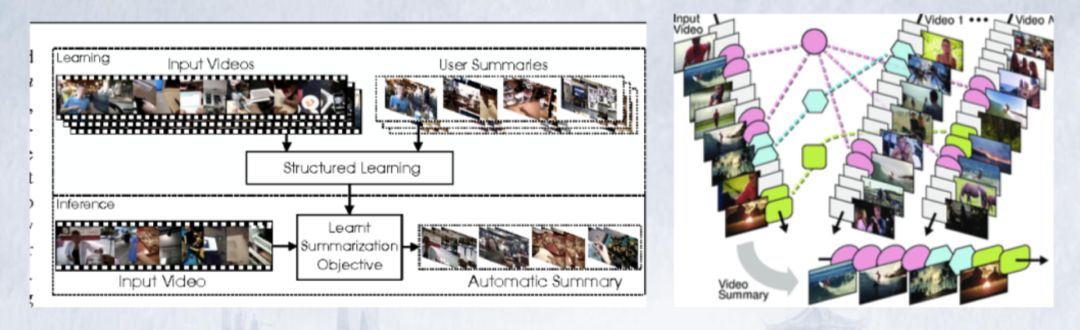



登录查看更多
相关内容

专知会员服务
33+阅读 · 2019年10月23日
Arxiv
5+阅读 · 2018年7月5日




相关VIP内容
专知会员服务
33+阅读 · 2019年10月23日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年7月5日