NaturalSpeech模型合成语音在CMOS测试中首次达到真人语音水平

(本文阅读时间:10分钟)
文本到语音合成(Text to Speech,TTS)是一项根据文本生成可懂且自然的语音的计算机技术 。近年来,随着深度学习的发展,TTS 在学术界和工业界取得了快速突破并且被广泛应用。在 TTS 的研究和产品上,微软一直有着深厚的积累。
在研究方面,微软曾创新提出了多个 TTS 模型,包括基于 Transformer 的语音合成(TransformerTTS)、快速语音合成(FastSpeech 1/2、LightSpeech)、低资源语音合成(LRSpeech)、定制化语音合成(AdaSpeech 1/2/3/4)、歌声合成(HiFiSinger)、立体声合成(BinauralGrad)、声码器(HiFiNet、PriorGrad)、文本分析、说话人脸合成等,而且推出了 TTS 领域最详尽的文献综述。同时,微软亚洲研究院还在多个学术会议上(如 ISCSLP 2021、IJCAI 2021、ICASSP 2022)举办了语音合成教程,并在 Blizzard 2021 语音合成比赛中推出了 DelightfulTTS,获得了最好成绩。此外,微软还推出了开源语音研究项目 NeuralSpeech 等。
在产品方面,微软在 Azure 认知服务中提供了强大的语音合成功能,开发人员可以借助其中的 Neural TTS 功能将文本转换为逼真的语音,用于众多场景之中,例如语音助手、有声读物、游戏配音、辅助工具等等。利用 Azure Neural TTS,用户既可以直接选择预置的音色,也可以自己录制上传声音样本自定义音色。目前,Azure Neural TTS 支持超过120种语言,包括多语言变体或方言,同时该功能也已整合到了多个微软产品中,并且被业界诸多合作伙伴所采用。为了持续推动技术创新,提高服务质量,微软 Azure 语音团队与微软亚洲研究院密切合作,让 TTS 在不同场景下听起来更多样、更悦耳,也更自然。
近日,微软亚洲研究院和微软 Azure 语音团队研发出了全新的端到端 TTS 模型 NaturalSpeech,该模型在广泛使用的 TTS 数据集(LJSpeech)上使用 CMOS (Comparative Mean Opinion Score) 作为指标,首次达到了与自然语音无明显差异的优异成绩。这一创新性的科研成果未来也将集成到微软 Azure TTS 服务中供更多用户使用。
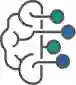
NaturalSpeech 是一个完全端到端的文本到语音波形生成系统(见图1),能够弥合合成语音与真人声音之间的质量差距。具体而言,该系统利用变分自编码器(Variational Auto-Encoder, VAE),将高维语音 (x) 压缩成连续的帧级表达 z(记作后验 q(z|x)),用于对语音波形 x(记作 p(x|z))的重构。相应的先验(记作 p(z|y))则从文本序列 y 中获取。
图1:NaturalSpeech 系统概览
考虑到来自语音的后验比来自文本的先验更加复杂,研究员们设计了几个模块(见图2),尽可能近似地对后验和先验进行匹配,从而通过y→p(z|y)→p(x|z)→x实现文本到语音的合成。
在音素编码器上利用大规模音素预训练(phoneme pre-training),从音素序列中提取更好的表达。
利用由时长预测器和上采样层组成的完全可微分的时长模块(durator),来改进音素的时长建模。
基于流模型(flow)的双向先验/后验模块(bidirectional prior/posterior),可以进一步增强先验 p(z|y) 以及降低后验 q(z|x) 的复杂性。
基于记忆的变分自编码器(Memory VAE),可降低重建波形所需的后验复杂性。
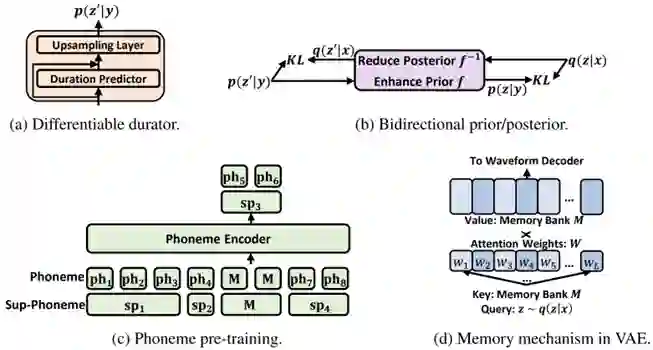
图2:NaturalSpeech 关键模块
据微软亚洲研究院主管研究员谭旭介绍,与之前的 TTS 系统相比,NaturalSpeech 有以下几大优势:
1)减少训练和推理的不匹配。先前的级联声学模型/声码器系统和显式时长预测都受到了训练推理不匹配的影响。其原因在于声码器使用了真实的梅尔谱以及梅尔谱编码器使用了真实的时长,而推理中使用了相应的预测值。NaturalSpeech 完全端到端文本到波形的生成以及可微时长模块,则能够避免训练推理的不匹配。
2)缓解了一对多的映射问题。一个文本序列可以对应多个不同的语音表达,例如音高、持续时间、速度、停顿、韵律等方面的变化。以往的研究仅额外预测音高/时长,并不能很好地处理一对多的映射问题。NaturalSpeech 中基于记忆的 VAE 和双向先验/后验则能降低后验的复杂性并增强先验,有助于缓解一对多的映射问题。
3)提高表达能力。此前的 TTS 模型往往不足以从音素序列中提取良好的表达以及学习语音中复杂的数据分布。NaturalSpeech 通过大规模音素预训练、带有记忆机制的 VAE、强大的生成模型(如Flow/VAE/GAN)可以学习更好的文本表达和语音数据分布。
此前的工作通常采用“平均意见分”(Mean Opinion Score, MOS)来衡量 TTS 质量。在 MOS 评测中,参与者通过听取真人说话录音和 TTS 的合成语音,分别对两种声音的特征进行五分制评分,包括声音质量、发音、语速和清晰度等。但是 MOS 对于区分声音质量的差异不是非常敏感,因为参与者只是对两个系统的每条句子单独打分,没有两两互相比较。而 CMOS(Comparative MOS)在评测过程中可以对两个系统的句子两两对比并排打分,并且使用七分制来衡量差异,所以对质量差异更加敏感。
因此,在评测 NaturalSpeech 系统和真实录音的质量时,研究员们同时进行了 MOS 和 CMOS 两种测试(结果如表1和2所示)。在广泛采用的 LJSpeech 数据集上的实验评估表明,NaturalSpeech 在语句级别与真人录音的对比上实现了-0.01 CMOS,在 Wilcoxon 符号秩检验中实现了 p>>0.05。这表明在这一数据集上,NaturalSpeech 首次与真人录音无统计学意义上的显著差异。这个成绩远高于此前在 LJSpeech 数据集上测试的其它 TTS 系统。

表1:NaturalSpeech 和真人录音之间的 MOS 比较,使用 Wilcoxon 秩和检验(Wilcoxon rank sum)来度量 MOS 评估中的 p 值。

表2:NaturalSpeech 和真人录音之间的 CMOS 比较,使用 Wilcoxon 符号秩检验(Wilcoxon signed rank test)来度量 CMOS 评估中的 p 值。
下面分别展示 NaturalSpeech 合成的语音和对应的真人录音:
内容1:Maltby and Co. would issue warrants on them deliverable to the importer, and the goods were then passed to be stored in neighboring warehouses.
内容2:who had borne the Queen's commission, first as cornet, and then lieutenant, in the 10th Hussars.
了解更多技术细节,请参阅 NaturalSpeech 论文和 GitHub 主页:
NaturalSpeech 论文:NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
https://arxiv.org/pdf/2205.04421.pdf
NaturalSpeech GitHub 主页:
https://speechresearch.github.io/naturalspeech/
在微软 Azure 认知服务语音首席研发总监赵晟看来,NaturalSpeech 系统首次达到了与真人录音没有显著差异的效果,是 TTS 研究上的一个新的里程碑。从长远角度来讲,虽然借助新模型能够实现更高质量的合成语音,但这并不意味着彻底解决了 TTS 所面临的问题。目前,TTS 仍然存在很多具有挑战性的场景,如充满情感的语音、长篇朗诵、即兴表演的语音等,这些都需要更先进的建模技术来模拟真人语音的表现力和多变性。
随着合成语音质量的不断提升,确保 TTS 能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低包括 TTS 在内的人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”6个负责任的人工智能原则(Responsible AI Principles),随后又发布负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。我们正在与全球的研究人员和学术机构合作,继续推进负责任的人工智能的实践和技术。
Azure AI Neural TTS 目前共提供340多种声音,支持120多个语种和方言。此外,Neural TTS 还能帮助企业以多种语言和风格,打造专属的品牌声音。现在,用户可以通过 Neural TTS 试用版来探索更多功能和特色声音。
相关链接:
微软 Azure 认知服务 TTS
https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/
微软亚洲研究院语音相关研究
https://speechresearch.github.io/
微软开源语音研究项目 NeuralSpeech
https://github.com/microsoft/neuralspeech
NaturalSpeech 论文:NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
https://arxiv.org/abs/2205.04421
-
Responsible AI principles from Microsoft https://www.microsoft.com/en-us/ai/responsible-ai -
Our approach to responsible AI at Microsoft https://www.microsoft.com/en-us/ai/our-approach -
The building blocks of Microsoft’s responsible AI program https://blogs.microsoft.com/on-the-issues/2021/01/19/microsoft-responsible-ai-program/
你也许还想看: