数据算法 | 主要算法的概念、分类及应用
数据算法 | 主要算法的概念、分类及应用(元方、沈浩)
前段时间有关部门请我介绍算法,什么是算法?有时候简单的问题真要说明白还不容易。我请我的博士生元方同学整理了算法的一些基本概念和分类,已经有段时间了,分享给同学们!
一、什么是算法
算法是一系列有助于解决问题和实现目标的规则。按照一定步骤建立这些规则时,我们可以使用这些算法,通常也叫做程序或构建人工智能(其实人工智能的狭义特指一种计算机程序算法)。如果把用计算机程序解决一个问题看做做菜,那么算法就是菜谱,从一个操作开始,按照既定的顺序执行完所有操作,最终结束并得到结果,在做菜的时候,得到的结果是一盘菜,而在程序中,得到的是问题的解决。

维基百科定义:算法/演算法/算则法(algorithm)为一个计算的具体步骤,常用于计算、数据处理和自动推理。
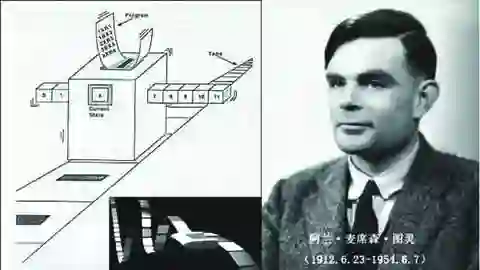
英文名称“algorithm”欧几里得算法被人们认为是史上第一个算法。
邱奇-图灵论题认为“任何在算法上可计算的问题同样可由图灵机计算”并提出一种假想的计算机的抽象模型,这个模型被称为图灵机。图灵机的出现解决了算法定义的难题,图灵的思想对算法的发展起到了重要的作用。
算法一般具有如下四大特征:
确定性:算法中每个步骤都是明确的,对结果的预期也是确定的,仍然用我们做菜的比喻,菜谱中一定会说明,这一步是把菜切成丝还是切成丁,是用水煮还是用油炒,同时,拿到一个菜谱,我们就一定知道照这个菜谱做出来的是一盘什么菜,宫保鸡丁或者鱼香肉丝需要的操作是不同的。
有穷性:算法必须是有限个步骤组成的过程,步骤的数量可能是几个,也可能是几百个,但是必须有确定的结束条件。就像菜谱也不可能无限做下去,原材料熟了菜就做好了一样。
可行性:算法中的每一个步骤都是可行的,只要有一个不可行,算法就是失败的,或者不能被称为算法。我们可以把萝卜切成块,切成丝,但是不可能把生鸡蛋切成任何形状,除非先把它煮熟。因此如果一个菜谱中要求切一个生鸡蛋,它就不能算作一个菜谱。
输入和输出:算法解决特定的问题,问题来源是算法的输入,期望结果是算法的输出,没有输入的算法,就像没有原材料的菜谱,没有任何意义,而没有输出的算法,就像没有成品的菜谱,也没有任何作用。
算法是用来解决问题的,那么,世界上存在的问题千千万,当然算法也很多,从简单的排序、查找,到复杂的数据挖掘、机器学习,现今的深度学习,无不对应着算法的存在或不断的优化。

在这里,我们借用与数据相关的算法的常见分类方式,介绍几种典型的数据挖掘与机器学习算法。
1. 预测算法
预测算法,顾名思义就是对某个问题做出预测,通常说来预测的目标是数字形式的连续值,例如房价、GDP等等。根据预测方法的不同,又可以分为外生预测和内生预测。例如预测房价,外生预测是根据会影响房价的外部因素,例如位置、居民收入等对房价进行估计,典型的例子是线性回归,将希望预测的房价作为因变量,位置和居民收入作为自变量,用一个算式将二者之间的关系表示出来,房价=a*位置+b*收入,求a和b的过程就是线性回归算法的过程。很多监督类算法都具有数值预测能力,例如:神经网络、决策树、贝叶斯网络、KNN、SVM等。
而内生预测,主要是指时间序列分析,则是通过房价自身的历史变化估计其未来趋势,通过分解历史变化中的总体趋势、周期性、季节性、波动性等要素,预测未来值。例如ARIMA,移动平均、指数平滑等。

备注:还有一种是主观预测法,例如德尔菲法,层次分析法AHP等
2. 分类算法
分类算法,也被称作有监督算法,在某些方面与预测算法类似,都是对一个预先存在的目标变量进行估计。但是,预测算法的目标通常是数字形态的值,而分类算法则是一个类别。一个典型的例子是电子商务网站预测他们的用户是否会流失。这时候,目标是用户“是/否”流失,也就是说是一个类别。我们可以利用网站已有的用户行为建立一个分类模型,这部分已有的用户中包含那些已经流失的用户,然后就可以用这个分类模型判断新的用户是否会流失。用来建立模型的那部分数据叫做“训练数据”。

分类算法是数据挖掘和机器学习中应用最广的一类算法,它包含经典的决策树算法、逻辑回归、判别式,也包含支持向量机、神经网络这些较新的方法。分类算法的模型在实际应用中经常表现为一个“黑箱”,只要能得到满意的分类结果,模型内部的细节可能是不可见的。
3. 细分算法
与监督算法相对应的是也被称为无监督算法的一类细分算法,它和分类算法相类似的地方是,它们的目的都是把数据分成几个不同的类别。但是,分类算法的类别是已经存在的,就像前面提到的用户流失,我们能够对网站已有的客户标记“流失”或“未流失”。但细分算法不同,它没有这样一个预先分好的类别,而是根据数据本身的分布特点,“自然而然”地划分出类。细分算法最常见的应用是客户细分,购物中心根据会员的消费金额、消费频次和最近一次消费时间将会员划分为不同价值的群体。在实施细分算法之前,我们并不知道这些会员可能被分为几类,每个类别是什么,只有建立细分模型之后,才能根据划分出类别在这三个方面表现出的特点归纳出每一类具体是什么。

细分算法中最主要的就是聚类,主要有基于距离的层次聚类和k-means聚类,基于密度的DBSCAN聚类,以及模糊聚类和核聚类等方法。
4. 关联规则算法
关联规则的主要目标在于发现数据中所存在的关系,这种关系会以规则的形式表现出来。例如购物篮分析就是最典型的关联规则算法的应用场景。它的目标是发现消费者在超市购买商品时哪些商品同时购买的机会比较高,或者购买某一项商品时,同时购买哪个商品的几率比较高。通过这样的分析,我们就可以发现购买商品之间的关联关系,从而实现优化货架摆放、提升销售额的目的。

关联规则最常用的是Apriori算法,此外还有一些考虑了时间先后因素在内的序列关联规则算法。
5. 个性化推荐算法
推荐算法主要应用在互联网中,用于向受众推荐他们可能感兴趣的内容。目前最常用的推荐多是基于一种叫做协同过滤的技术,它通常的做法是对一大群人进行搜素,从中找出与推荐对象品味相近的一小群人,然后对这些人偏爱的其他内容进行考察,并组合起来构造一个经过排名的推荐列表。

在第三部分中,将通过今日头条和一点资讯的例子对推荐算法进行更详细的阐述。
6. 其他算法
a- PageRank算法:一个网页的价值是由链接这个网页的网页价值决定的,这是google的基本算法。由此推演出一个人的价值是由链接这个人的人的价值决定的,PersonRank微博微信的互粉关系呈现了整个算法;由此推演一篇文章的价值是由关键词的相互引用决定的价值TextRank
b- 电子围栏算法:通过空间位置的经纬度落在某个区域内的匹配算法,由此可以实现地理空间的算法,由此导航、打车软件、共享单车和无人机禁飞区域可以实现,当然还包括需要位置信息的各种APP提供地域性限制或个性化内容。
c- 社会网络算法:今天的微博微信都是社会网络或社会化媒体,都呈现了影响力、传播力和效果研究的一些算法需求,表现在网络结构和传播路径等算法。
d- 自然语言算法:如何实现自然语言的处理,表现在语言和文本的中文处理算法,分词技术、情感分析算法、用户画像算法、性格分析算法等等
e- 深度学习算法:主要解决计算机进行视频、图像、文字、语言、声音等处理算法,这是当前最前沿的算法,也是人工智能得以实现的基础算法,主要包括卷积神经网络、LSTM、生成对抗神经网络,自循环神经网络算法等。
f- 可视化算法:目前很多算法都为了能够可视化,图形、地理、文本、关系、网络等为了达到可视化目的和实时在线传播需要各种算法进行数据处理,以便可以让人们更容易理解和探查结构。很多舆情可视化技术都需要用到这些算法。
g- 图像识别算法:主要用于图片或视频的鉴黄鉴恐等,也包括车牌号码、手写文字、人脸识别等
h- 时间序列算法:包括股票预测、经济走势、舆情走势等时间演化过程的规律和预测。
i- 综合评测算法:加法原则是互有补充取长补短,乘法原则是一算俱损不可或缺,主要用于网站的综合评价,多指标综合方法等。
j- 多变量统计算法:统计上最基本的两个算法是回归分析或logistics回归和主成分分析或因子分析。
k- 各种加密算法:在互联网上需要安全性,各种加密算法能够保证通信协议或数据安全性,包括各种认证和密码算法,加密或解密等都需要算法。
三、算法的实际应用案例
1. 今日头条的推荐算法
有3个同一类用户看过3篇文章,现在要给相似喜好的第四个用户推荐文章,那么应该推荐哪一篇呢?投票代表用户喜欢这篇文章,那么显而易见,应该给第四个用户推荐得到3票的第一篇文章。今日头条的个性化推荐就是这种基于用户投票的方法,统计同一个人群中每个用户最喜欢的文章,得到的结果可能就是这个人群中最好的文章,那么把这些文章再推荐给这个人群中没看过这篇文章的人,这就是个性化推荐。实际上,个性化推荐并不是机器给用户推荐,而是用户之间互相推荐。

根据投票的思路,推荐文章被简化为一个相同群体中的投票问题。那么,这种群体又是如何划分出来的呢?假定今日头条的用户中有一个8万人的人群,在这个人群中有4万人喜欢科技,4万人喜欢娱乐,这样就把这个人群分成了两类,接下来再放进来一个维度地域,喜欢科技和喜欢娱乐的人都有北京和上海的,那么8万人群又被分成了四组,每组两万,然后我们看年龄,这样就有了8个人群,第一个是喜好科技,位置在北京,年龄30岁以上,有1万人,再下来是喜欢娱乐,地点在上海,年龄30岁以下,这又是1万人。

实际上,除了地区和年龄以及广义的喜好,还有更多属性,例如性别、职业,以及用户在阅读文章过程中显示出来的更加细分的偏好都可以作为用户特征。用户的手机在什么区域,就可以认为用户是什么地域的;用户经常看科技文章,就可以判断用户属于爱好科技的人群;用户的好友都是娱乐圈的人,那么他自身可能也是娱乐圈的,通过许许多多这样的判断,用户就被打上了标签,分成了不同的群体。

除此之外,今日头条也使用了一些基于内容的推荐技术,借助自然语言处理、词向量和主题模型等技术,结合文章的发布时间、发布地区、文章中提到的名人等属性形成对新闻的特征描述,然后利用用户的正反馈和负反馈(如点击、阅读时长、分享、收藏、评论、不感兴趣等)建立用户和新闻特征之间的关系,找出用户喜欢看的文章,从而进行建模实现推荐。
2. 一点资讯中推荐技术的主要特点
同样作为资讯推荐类的应用,一点资讯和今日头条在推荐实现的主要思路上没有体现出太大的区别,但是比起今日头条侧重机器算法的路线,一点资讯的特点在于在推荐中更多体现了人工的干预,这主要体现在用户端“搜索+推荐”和应用端“机器+人工”两个方面。

搜索+推荐
与今日头条相比,一点资讯最大的不同在于模式上,今日头条的核心在用户兴趣与推荐算法,而一点资讯的方式则是订阅+推荐。通俗的说,就是今日头条是“你爱看什么我给你看什么”,一点资讯则是“你搜索了什么我给你看什么”。也就是说,两家app定义用户兴趣的方式不同,一点资讯定义“用户主动搜索的关键词是用户寻求的兴趣资讯入口”。在一定程度上,对用户来说,这样的方式要优于今日头条的推荐逻辑。例如有一个人最近要买车,他会在不同的app上搜索有关汽车的信息,这时候,一点资讯向他推荐了有关他搜索的关键词的信息。然后一段时间后,他已经买好了车,不再继续搜索相关信息了,那么这种推荐也就结束了。而如果在今日头条中,因为首页会不停的出现汽车信息,用户处于下意识的心态点击了推送的信息,那么今日头条会一直推荐类似的信息,而事实上用户可能已经并不需要了。这是一种潜在的硬伤。

机器+人工
一次推荐一般经过召回、排序、策略几个阶段,召回指从一个非常大的内容候选集合中挑出用户可能感兴趣的文章,排序则需要对这些文章做精确的估计,判断用户的点击可能性,策略则指从用户体验出发进行的一些控制。一点资讯在召回阶段不是完全依赖算法,而是引入了专家和知识库的知识,以价值为导向,用高质量的先验知识和用户搜索这样的主动表达形成的特征参与其中。同时,这样不光依靠机器算法,也强调了编辑的价值,形成所谓的“人机结合”。

在机器学习时代大量的数据要比算法重要,但在人工智能时代的深度学习,在有足够量的数据基础上,往往算法比数据重要!
当今大数据时代,人们通常说:软件定义一切,数据驱动未来,算法统治世界!
对于融媒体时代,我们可以说:软件定义媒体、数据驱动新闻、算法重构渠道!
稍后会整理一篇推荐算法的综合指南!
照片都是俺拍的!
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号




欢迎关注:灵动数艺
——数艺智训




