【支撑20亿人的机器学习】Jeff Dean、贾扬清等ScaledML大会演讲

精彩回顾
2018新智元产业跃迁AI技术峰会圆满结束,点击链接回顾大会盛况:
爱奇艺 http://www.iqiyi.com/l_19rr3aqz3z.html
腾讯新闻 http://v.qq.com/live/p/topic/49737/preview.html
新浪科技 http://video.sina.com.cn/l/p/1722511.html
云栖社区 https://yq.aliyun.com/webinar/play/419
斗鱼直播 https://www.douyu.com/432849
天池直播间 http://t.cn/RnQPhuY
IT大咖说 http://www.itdks.com/eventlist/detail/1992
新智元编译
来源:ScaledML
作者:文强
【新智元导读】如何利用GPU,TPU,CPU等不同计算平台,如何从数据、模型等多个维度扩展机器学习?可扩展是机器学习接下来的攻关重点之一。谷歌大脑负责人Jeff Dean日前在ScaledML大会发表演讲《系统与机器学习》,介绍TPU最新进展以及谷歌在可扩展机器学习方面的工作。英伟达首席科学家Bill Dally、Facebook贾扬清等也发表演讲。

机器学习有可能解决世界规模的难题。在2008年美国工程院列出的“21世纪重大工程挑战”(Grand Engineering Challenges for 21st Century)中,有很多都是可以用机器学习解决的,包括完善城市基础设施、推进健康信息学、增强虚拟现实以及提升个性化学习。
但是,要支持重大工程问题,也就需要大规模可扩展的机器学习。现在,ML不断发展,以利用诸如GPU,TPU,CPU以及这些硬件构成的集群。大学和行业研究人员也一直在使用这些新的计算平台,从数据、模型等多个维度扩展机器学习。
正是在这样的背景下,Scaled Machine Learning(ScaledML)大会应运而生,将在各种计算平台上运行和扩展机器学习算法的研究人员聚集到一起,展示和交流彼此的角度和思维。
与新智元之前介绍过的系统机器学习大会(SystemML)一样,ScaledML近年来也愈发受关注,2018年的票,700多张,据说是放出来不到一小时就抢光。

ScaledML大会的组织/发起人之一是斯坦福大学兼职教授、深度学习和计算机视觉初创公司Matroid联合创始人Reza Zadeh。ScaledML 2018的嘉宾阵容大牛如云,除了组织人Reza Zadeh:
Andrej Karpathy,特斯拉AI总监
Jeff Dean,谷歌大脑负责人
Ion Stoica,伯克利RISE实验室负责人
Francois Chollet,Keras作者、谷歌研究科学家
Bill Dally,英伟达首席科学家、斯坦福教授
Jennifer Chayes,微软新英格兰研究院和微软纽约研究院院长
Simon Knowles,Graphcore联合创始人兼CTO
Anima Anandkumar,亚马逊深度学习首席科学家,加州理工教授
Ilya Sutskever,OpenAI研究总监
贾扬清,Facebook AI基础设施总监
英伟达首席科学家、斯坦福教授Bill Dally指出,深度学习正在助推人工智能革命,在教育、交通、医疗和图像等领域,越来越多的研究人员扩展深度学习——微软的图像识别从2012年到2015年模型增长了15倍(从8层神经网络、1.4 GFLOP,变为152层22.6 GFLOP),百度的语音识别DeepSpeech,从2014年到2015年一年之间就增长了10倍,由此也开启了硬件革命。如何在摩尔定律之后继续扩展?稀疏性、仅用4-6位来表示权重,支持稀疏权重和码本的高效推理引擎(EIE),以及新的训练方法。

Graphcore作为最近极受关注的AI芯片初创公司,其联合创始人兼CTO Simon Knowles介绍了他们的芯片IPU的特点。Knowles特别提到,小批量(批量大小在4~16之间)SGD得到的模型是最好的,机器处理非常小的、能并行的批量最有效。此外,我们还需要采用其他高效利用内存的算法,比如用计算换存储,以及可逆模型(reversible models)。
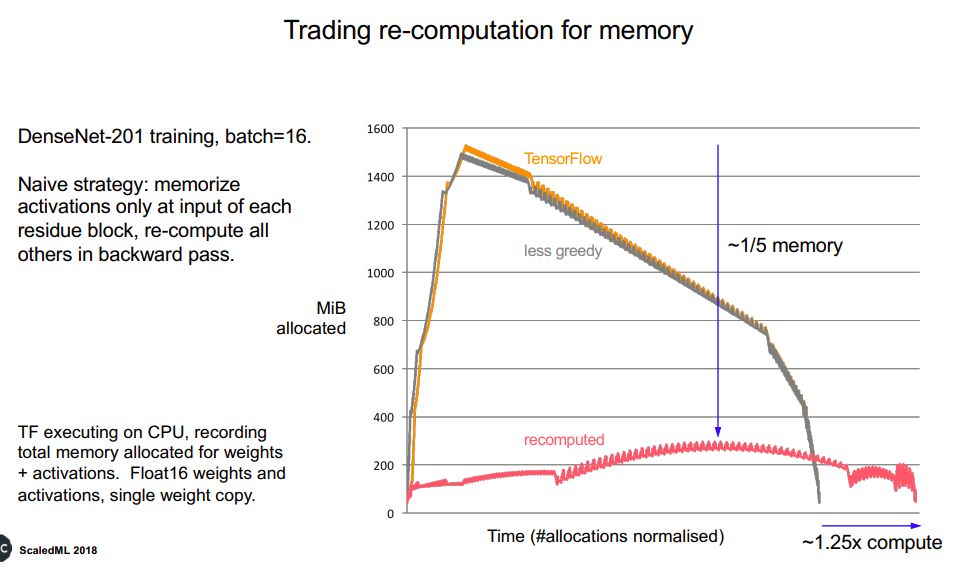
最后,作为Facebook AI基础设施总监的贾扬清,介绍了Facebook如何利用机器学习,包括Facebook用于机器学习的硬件和平台、框架。作为支撑20亿用户的超大平台,Facebook的机器学习流程如下:
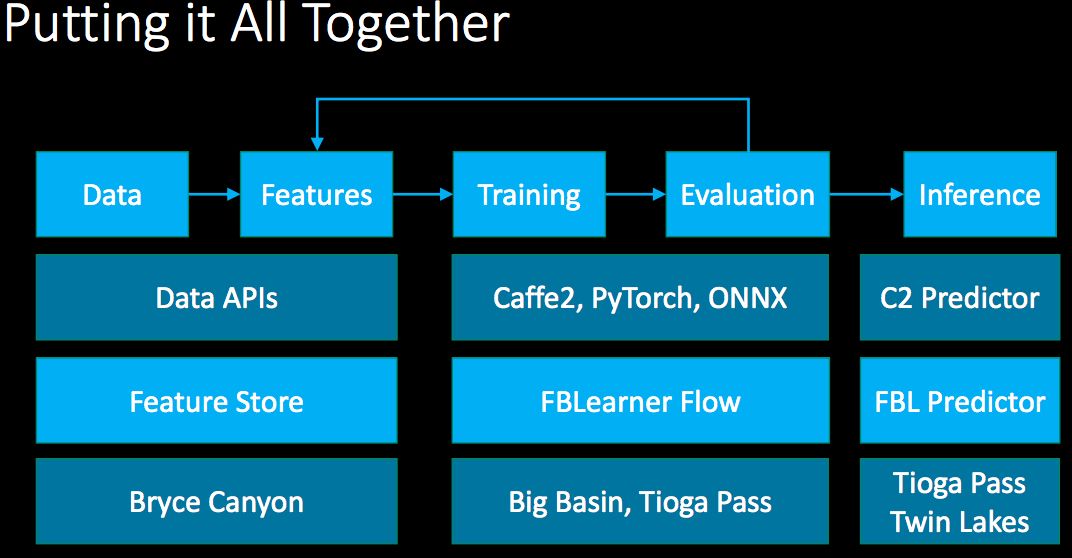
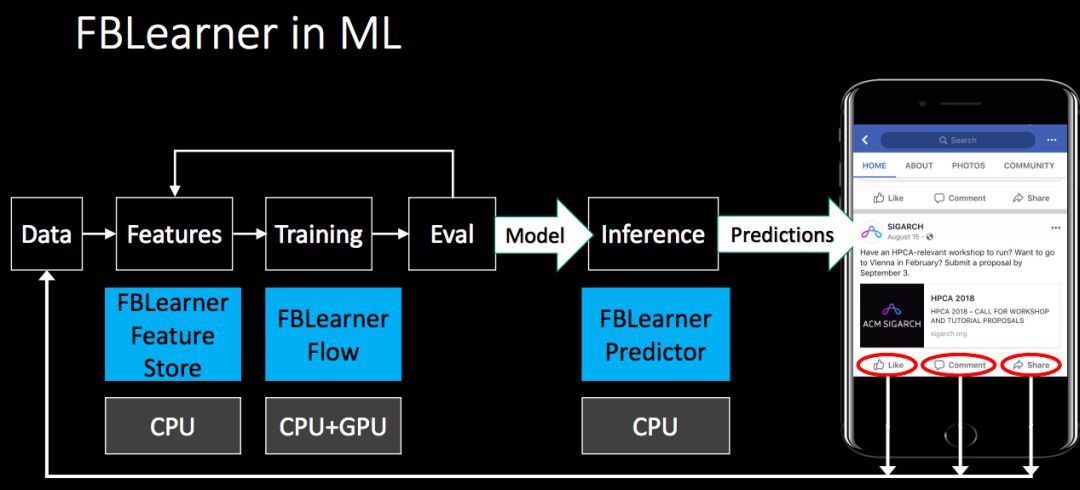
其中,Facebook机器学习平台FBLearner Flow的流程如下。这一平台要能方便地在不同的产品中重复使用多种算法,并可以延伸到成千上万种模拟的定制试验操中,轻松地对实验进行管理。FBLearner Flow提供了创新性的功能,比如从流水线定义和对Python编码进行自动化平行移用中自动生成用户界面(UI)试验。
下面,我们重点介绍Jeff Dean在ScaledML 2018的演讲《系统与机器学习》(Systems and Machine Learning)。演讲中,Jeff Dean主要介绍了两方面,一是谷歌如何利用机器学习解决一些重大的问题(比如天文、医疗),二是他们如何应对在规模上变得越来越大的机器学习难题。

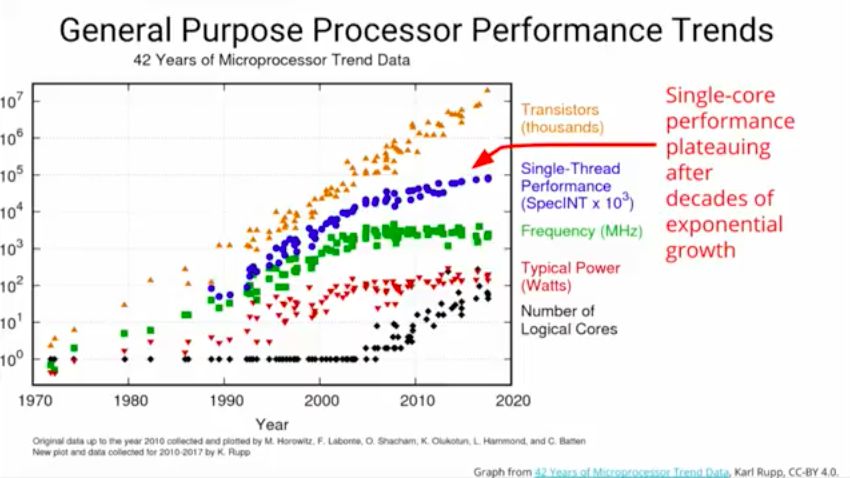
演讲从机器学习系统开始。他首先介绍了通用处理器性能趋势,指出经过数十年的指数式增长,单核性能保持稳定。

就在那时深度学习创造出了巨大的计算需求。在terabyte甚至petabyte大小的训练数据集上训练强大却昂贵的深度模型。再加上AutoML等技巧,可以将期望训练算力扩大5到1000倍。

在系统中使用昂贵深度模型的推理,有以下特点:每秒数十万的请求;延迟要求几十毫秒;数十亿用户。
机器学习系统能解决21世纪重大难题:城市基础设施、医疗、人脑逆向工程
在2008年美国工程院列出的“21世纪重大工程难题”中,14个问题里,至少有8项,也就是一半多,都能用到机器学习,甚至用机器学习去解决,包括环境问题、健康、医药、城市基础设施,以及人脑的逆向工程。

在城市基础设施问题中,Jeff Dean以谷歌Waymo自动驾驶为例:自动驾驶涉及到大量的数据、Waymo每周都会行驶2.5万英里,大部分是在复杂的城市道路上,在2016年,在模拟器上产生的数据量是10亿英里。因此,需要用到深度学习。

在健康问题上,谷歌用深度学习分析糖尿病视网膜图像,算法的准确率已经超越了人类医生。
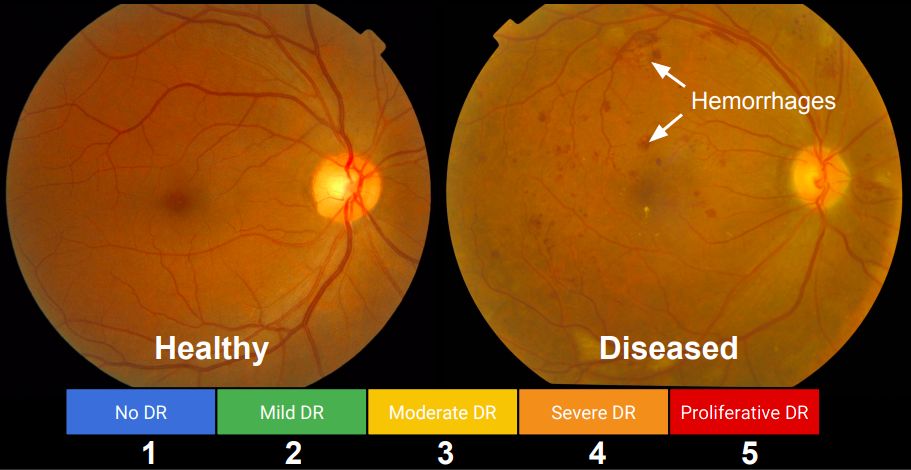
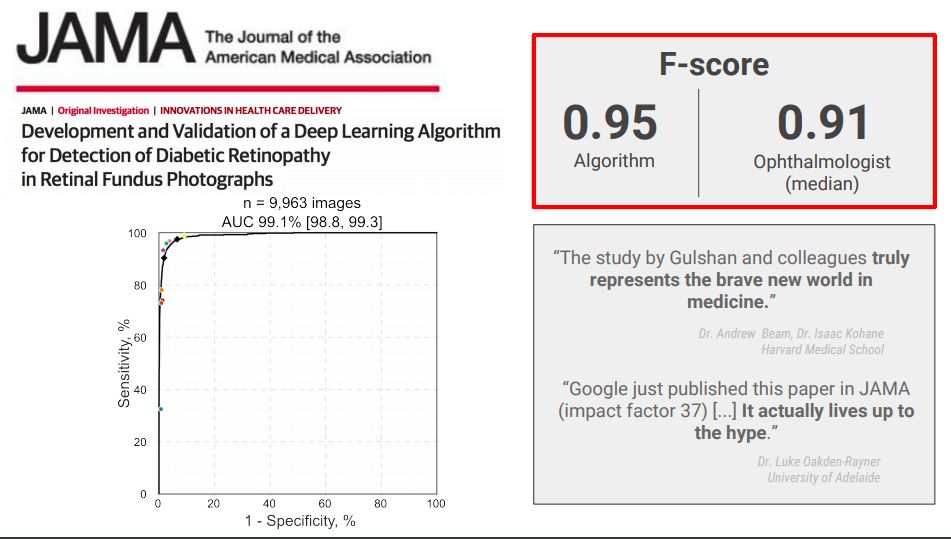
不仅如此,谷歌还使用深度学习视网膜图像分析来预测心血管疾病突发风险。使用深度学习来获得人体解剖学和疾病变化之间的联系,这是人类医生此前完全不知道的诊断和预测方法,不仅能帮助科学家生成更有针对性的假设,还可能代表了科学发现的新方向。
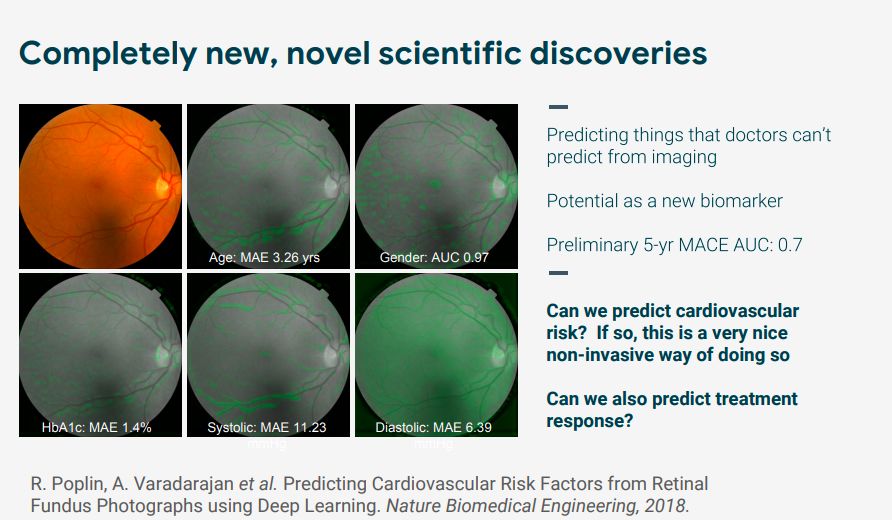
此外,在预防性医疗保健任务上,给定一个大量的去识别医疗记录的训练数据,我们是否可以预测不在训练集中的患者的有关情况,比如患者将在未来N天内再次入院吗?患者入住的可能住院时间是多少?现在对患者最有可能的诊断是什么? 医生应该考虑使用哪些药物?该对患者做哪些检测?下个月哪些患者出现什么症状的风险最高?
为此,谷歌联合几大顶级医院和医学研究机构,发表了他们迄今最大的电子病例深度学习研究。

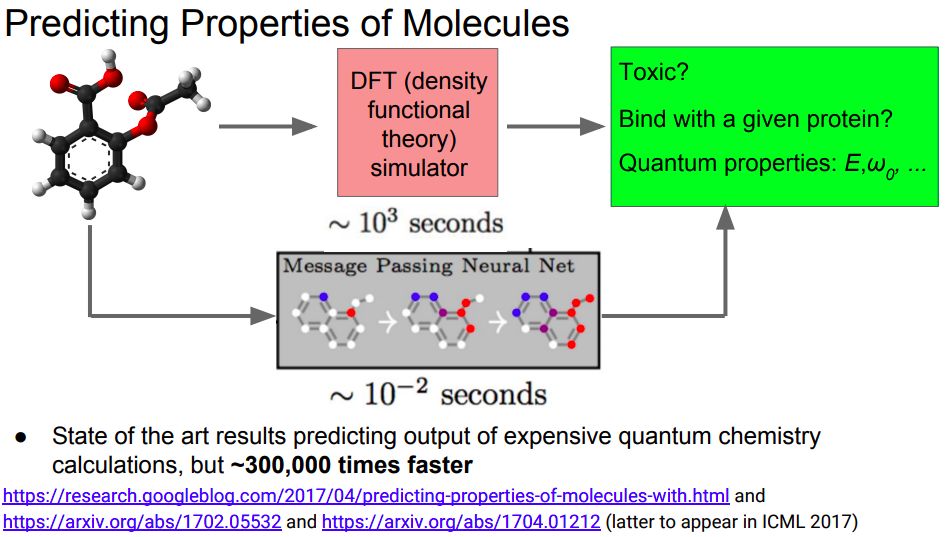
还有预测分子结构和性质:
在人脑逆向工程方面,谷歌和马克思普朗克研究所等机构合作,首先从理解人脑神经网络图像开始,重构生物神经网络,已经取得了一些进展。
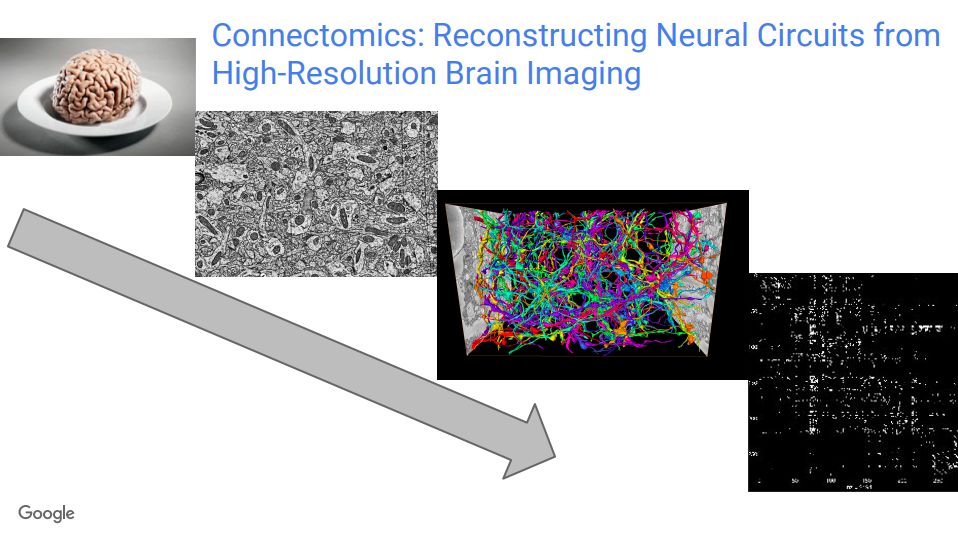
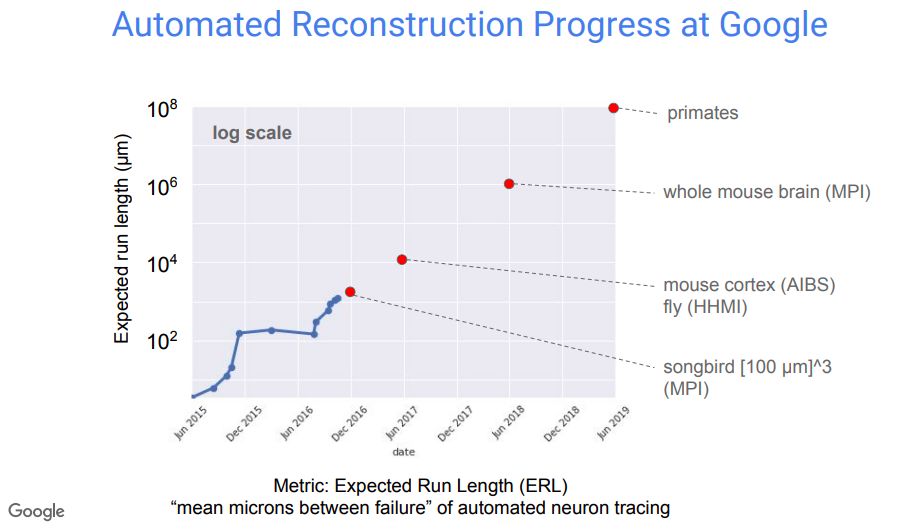
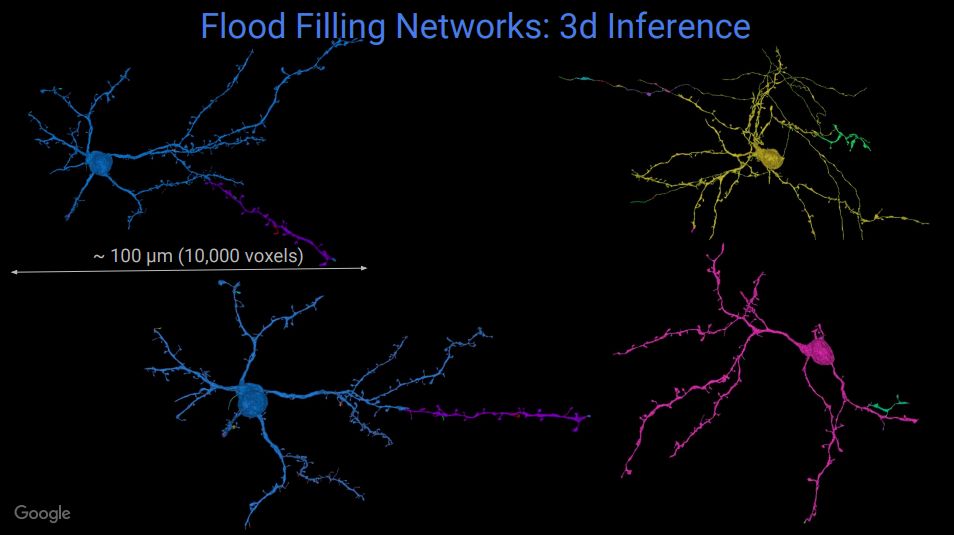
关于神经系统如何产生精确的、时序运动行为,并且进行强化学习,研究人员提出了一些假设,这个项目的目标,就是完整重建用于连接和测试这些特定假设的连接。目前,使用马克思普朗克研究所的数据,研究人员已经生成了大约6000亿个体素。
他们还提出了一种模拟生成神经网络的算法“Flood Filling Networks”,可以使用原始数据,利用此前的预测,自动跟踪神经传导。


机器学习系统能解决21世纪重大难题:设计科学工具
在设计科学工具方面,自然是TensorFlow。作为基础框架,TensorFlow能支持很多工具开发,这些工具能够用来寻找行星、设计新的传感器,用来监测非法森林采伐,以及安装在奶牛身上,让农场主了解每头牛的健康状况。这里就不多介绍了,大家想深入了解可以看视频/下载PPT(文末有链接)。
自动机器学习AutoML:超越机器学习专家,并且给人以启发

目前,机器学习的解决方案是由ML专家设计模型或网络,在大数据和超强计算力的支撑下得出。但是,众所周知,ML专家少,如何应对这一点。从去年开始,Jeff Dean就在他的演讲中频频提到“要用计算力替代ML专家/ML专业知识”,而事实证明,这一点确实可行。

如今,谷歌AutoML的概念已经深入人心。谷歌使用神经网络自动搜索和优化神经网络架构,不仅迭代速度更快,而且最终性能也更加优越。
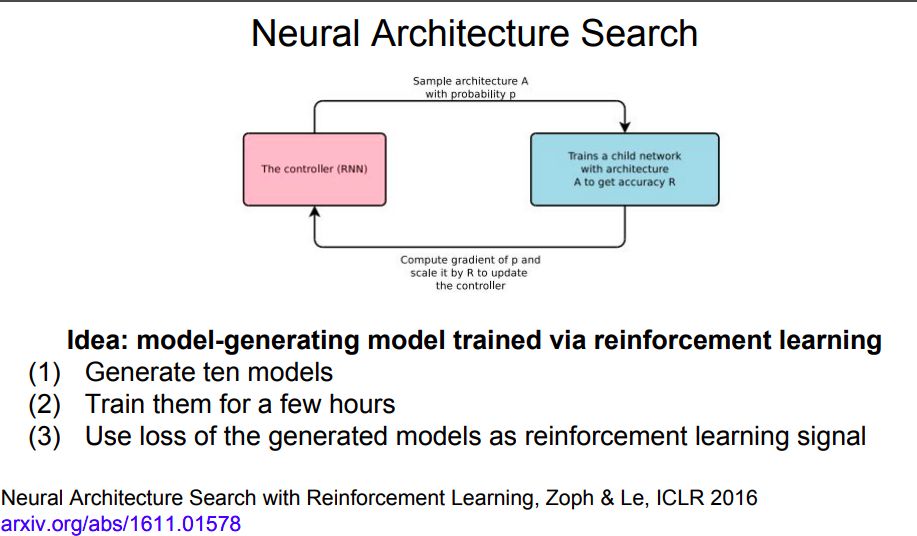

Jeff Dean特别指出,由顶级机器学习研究人员设计的模型,在利用硬件的效率和模型大小上,都被AI设计的模型所超越。AI设计的模型,与人设计的结构非常不同,很多都是人不会想到,也不会去走的路,比如没有池化层,有很多跳跃的连接。但是,从中还是能看出一些底层的共通点,也对今后人类设计和优化网络结构给予了启发。
软件需求改变硬件结构:谷歌TPU最新进展

因此我们需要更多的计算力,而深度学习正在改变我们设计计算机的方式。深度学习具有的两种特殊计算性能:可以降低精度,浮点计算;出现了很多专门的深度学习模型运算。

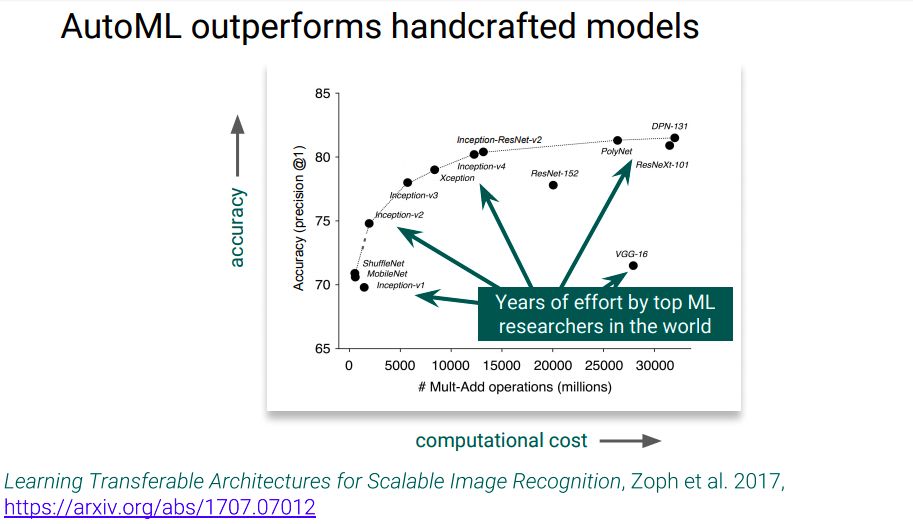
为此,谷歌研发了TPU,第一代TPU是用于神经网络推理的芯片:92 T ops/秒 of 8位 量化整数运算,用于搜索请求、神经机器翻译、言语和图像识别、AlphaGo比赛等。


第一代TPU对推理起到了巨大的帮助,但不能做训练。对于研究者的生产力和不断增多的问题来说,加快训练速度至关重要。于是,谷歌推出了第二代TPU,一个TPU由四个专用集成电路组成,配有64GB的“超高带宽”内存。这一组合单元可以提供高达180 teraflops的性能,内存为64 GB HBM, 2400 GB/秒mem BW。


Jeff Dean介绍了谷歌TPU的最新进展,能支持图像识别、机器翻译更多的模型,接下来还预计推出基于Transformer的语音识别和图像生成,以及DeepVariant基因检测等新模型支持。
从去年底到现在,再次将训练时间缩短。


今年下半年,谷歌计划增加一个集群选项,让云客户将多个TPU聚合成一个“Pod”,速度达到petaflop的范围。而当时内部使用的Pod包括64个TPU,总吞吐为11.5 petaflops。这一点,在昨天的TensorFlow开发者大会上也有介绍。

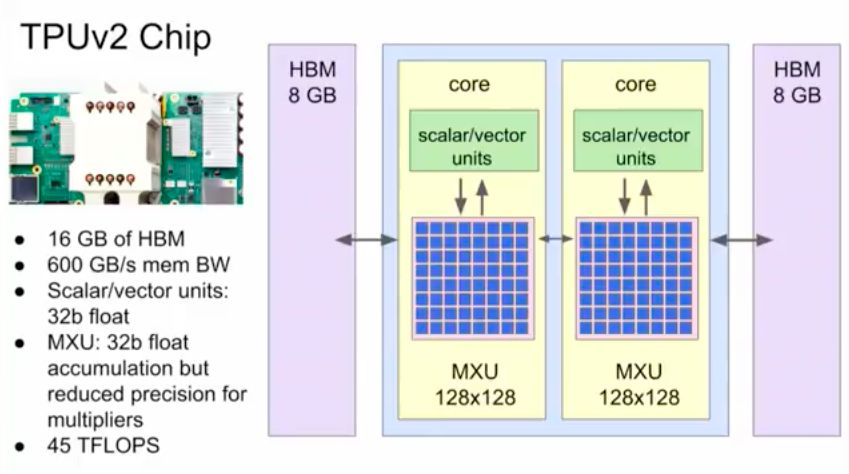
Cloud TPU是谷歌设计的硬件加速器,为加速、拓展特定tensorflow机器学习workload而优化。每个TPU里内置了四个定制ASIC,单块板卡的计算能力达每秒180 teraflops,高带宽内存有64GB。某些程序只会对CPU、GPU、TPU进行微小的修改,某些程序通过同步数据并行度进行缩放,而不能在TPU pod上进行修改。

当然,Jeff Dean重点推荐了谷歌刚刚发布不久的Cloud TPU。谷歌设计Cloud TPU是为了给TensorFlow的workload提供差异化性能,并让机器学习工程师和研究人员更快速地进行迭代。
如Resnet,MobileNet,DenseNet和SqueezeNet(物体分类),RetinaNet(对象检测)和Transformer(语言建模和机器翻译)等模型实现可以帮助用户快速入门:https://github.com/tensorflow/tpu/
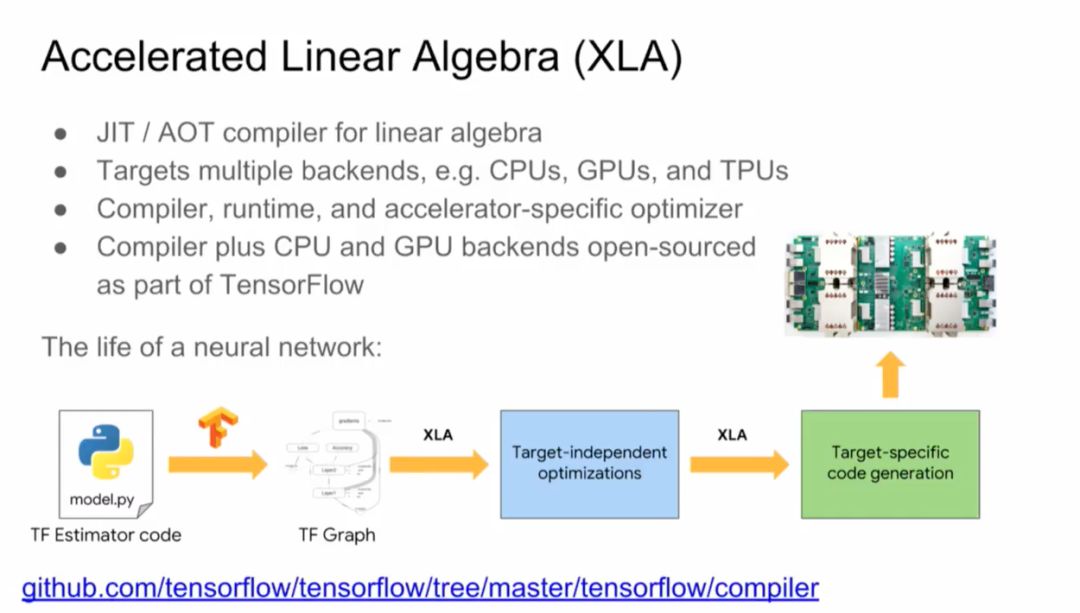
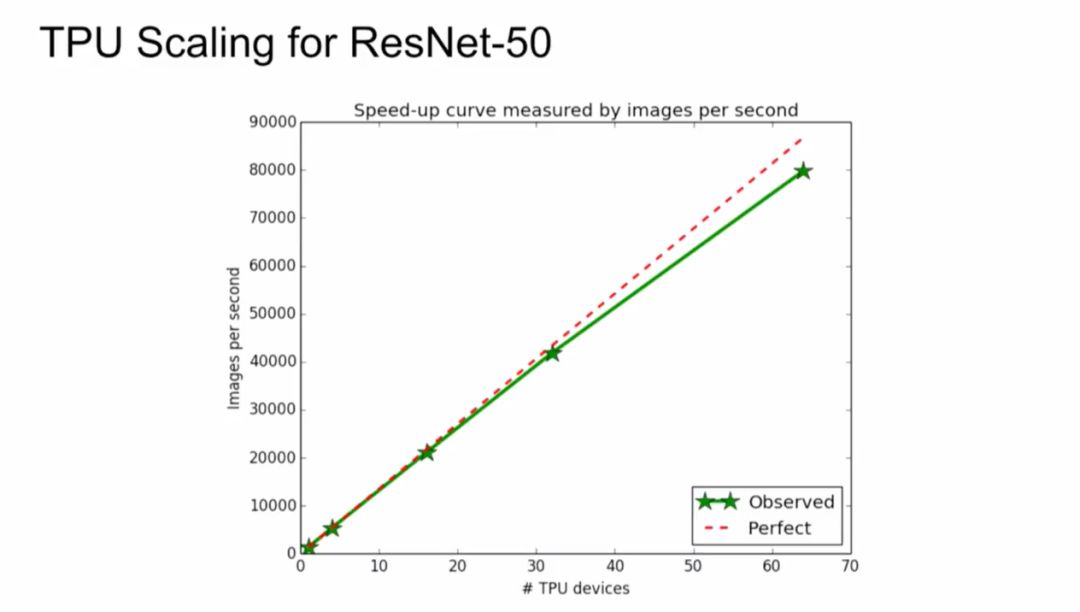
使用单个 Cloud TPU,训练 ResNet-50 使其在 ImageNet 基准挑战上达到期望的准确率。
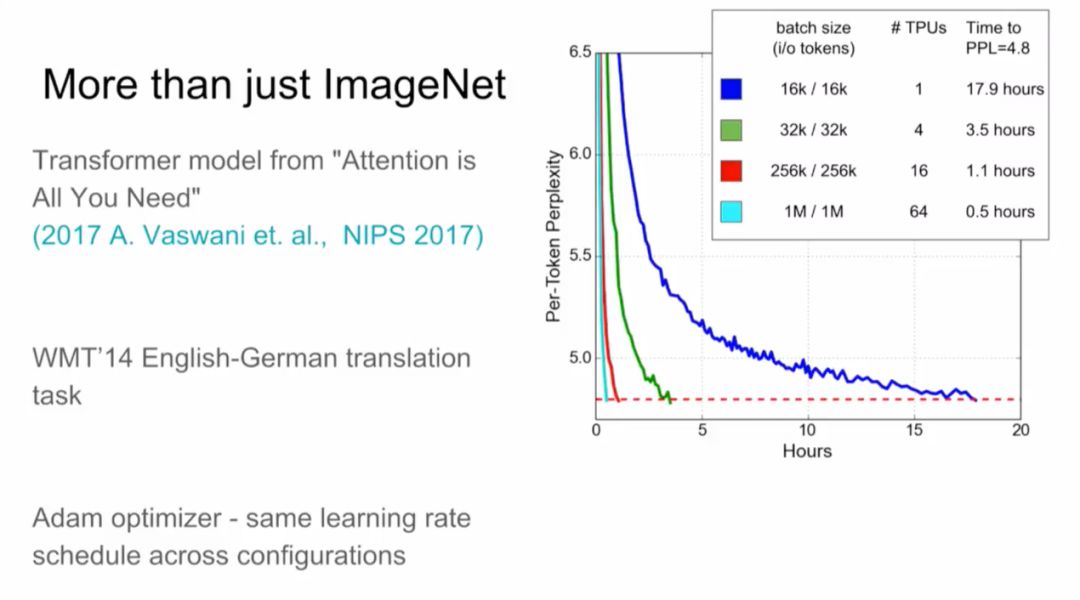
在未来,我们将如何建造深度学习加速器?

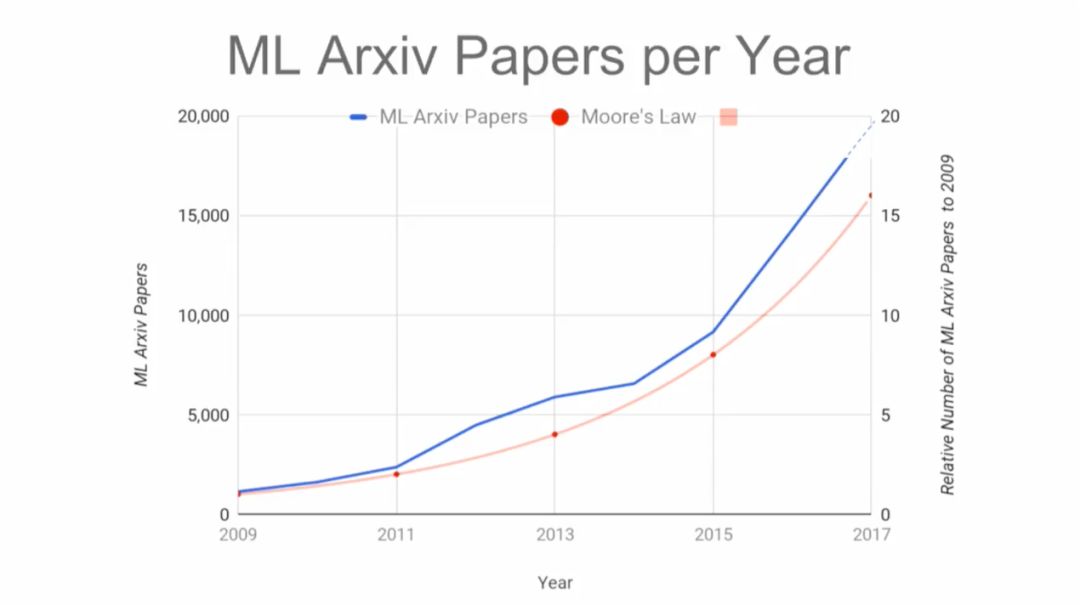
在Arxiv上的机器学习的论文逐年增长,速度已经超过摩尔定律。如果你现在开始做ASIC,大约两年后能够流片,而这款芯片需要能够持续使用3年。换句话说,必须看清楚未来5年的技术发展,但是,我们能够看清吗?怎样看清?


一些必须考虑的问题包括精度、稀疏性和嵌入等等。Jeff Dean说,因为不得不直接在ML模型中进行批处理(batching),他常常感到很头痛。
极低精度训练(1-4位权重,1-4位激活)能否适用于通用问题?我们应该如何处理疏密混合的专家路由?如何处理针对某些问题非常巨大的嵌入?我们是否应该专门为处理大的批量建立机器?至于训练算法,SGD一类的算法还会是主流训练范式吗?像K-FAC一类的大批量二阶方法会是更好的选择吗?


在System for ML这节,Jeff Dean谈了机器学习如何直接影响系统。现在,很多系统实际上都没有用到机器学习,但这一点应该得到转变。一个很好的例子就是高性能机器学习模型,这也是谷歌大脑最近在从事的一个研究重点。

对于大规模模型来说,并行计算很重要,模型的并行也很重要。让不同的机器计算不同的模型,或者模型的不同部分,就避免了单台机器内存不足的问题,将来让模型扩展到更多机器上也更加方便。
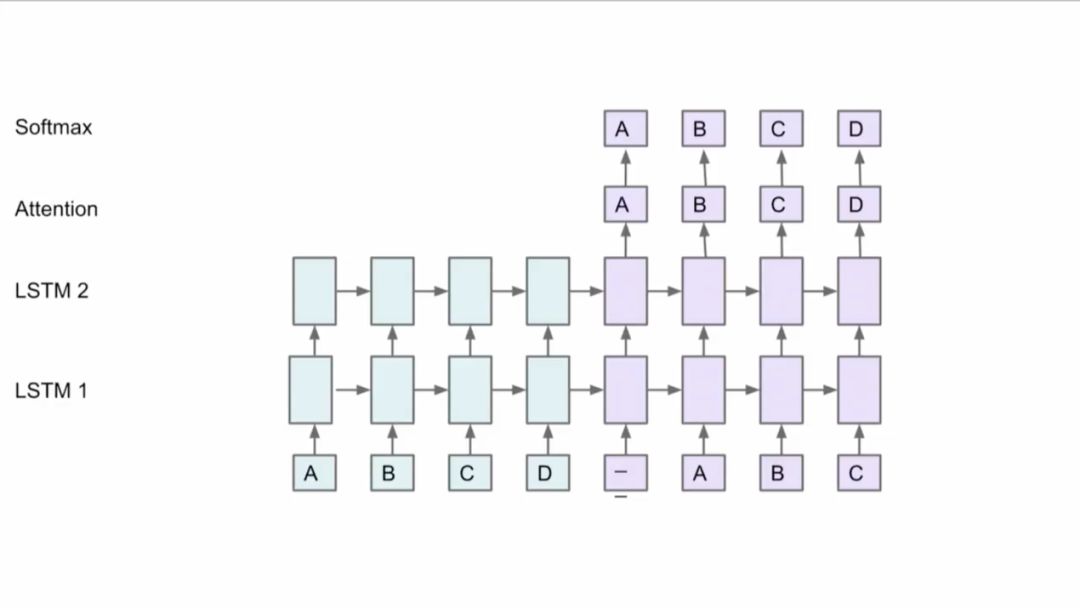
但是,如何将模型分布到不同机器上并且取得好的性能是很难的。Jeff Dean以下面这个网络为例,比如有两个LSTM,有Attention机制,在顶层有Softmax,你可以将方框中的部分放到不同的GPU卡上,因为这些部分都有同样的参数,这些层也不用移动。
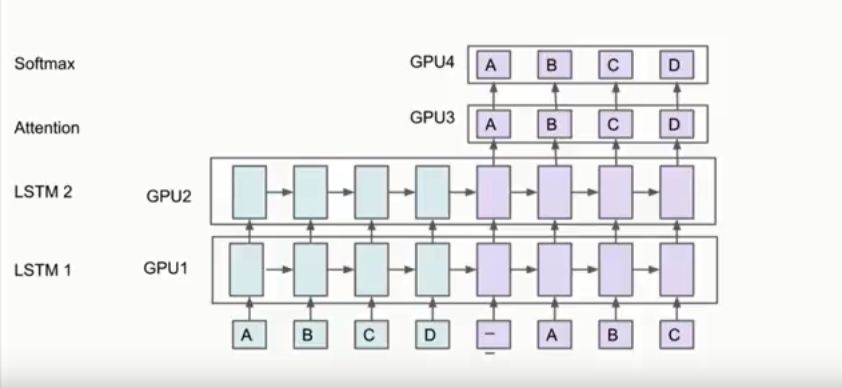
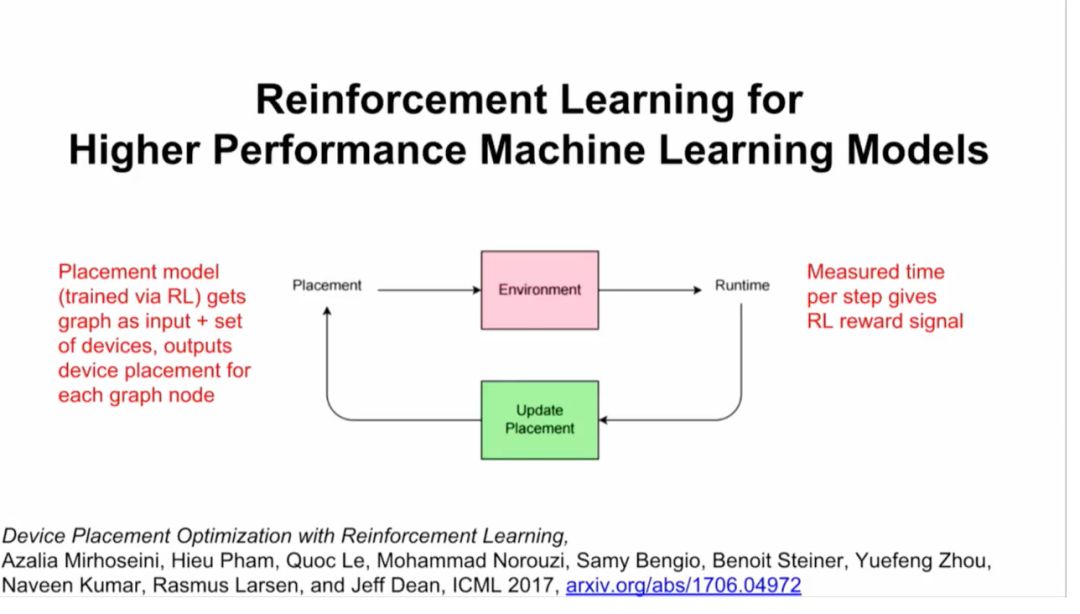
此外,谷歌大脑还在进行一项研究,用强化学习来替代一部分硬件上的计算。你将计算视为算子和dependencies组成的graph,然后给一组硬件,比如你想在4块GPU或者8块GPU上运行这个模型,结果整个过程成了很好的强化学习过程(见下图)。
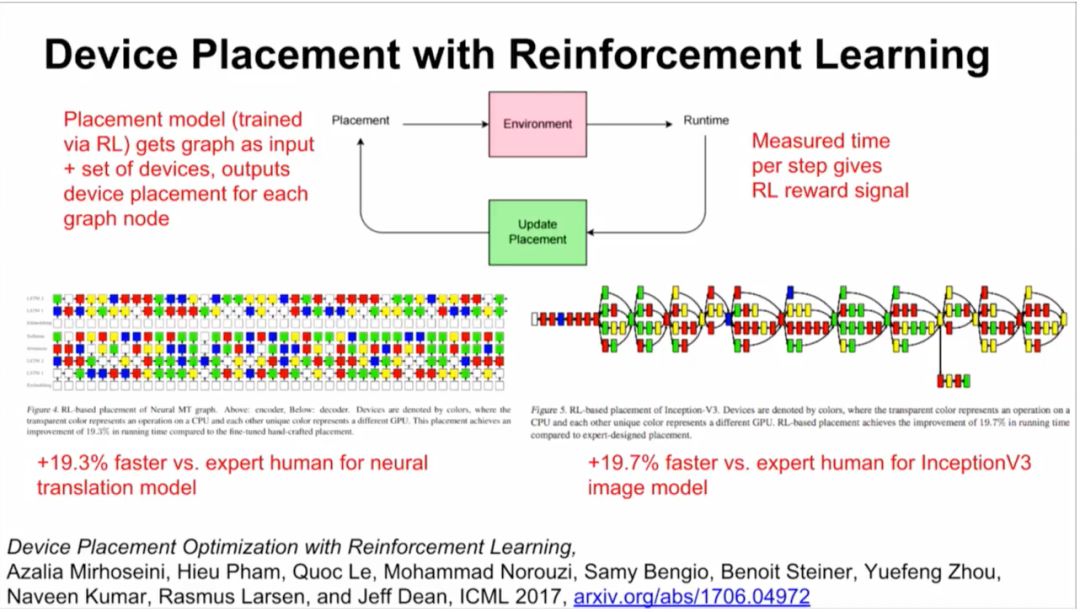
结果:比人类专家要快19.3%(神经转换模型)和19.7%(InceptionV3图像模型)。
之后,谷歌大脑将上述研究泛化,提出了一个层次模型(Hierarchical Model),将计算图有效地放置到硬件设备上,特别是在混合了CPU,GPU和其他计算设备的异构环境中。这项研究提出了一种方法,叫做“分层规划器”(Hierarchical Planner),能够将目标神经网络的runtime最小化,这里的runtime包括一次前向传播,一次BP,一次参数更新。
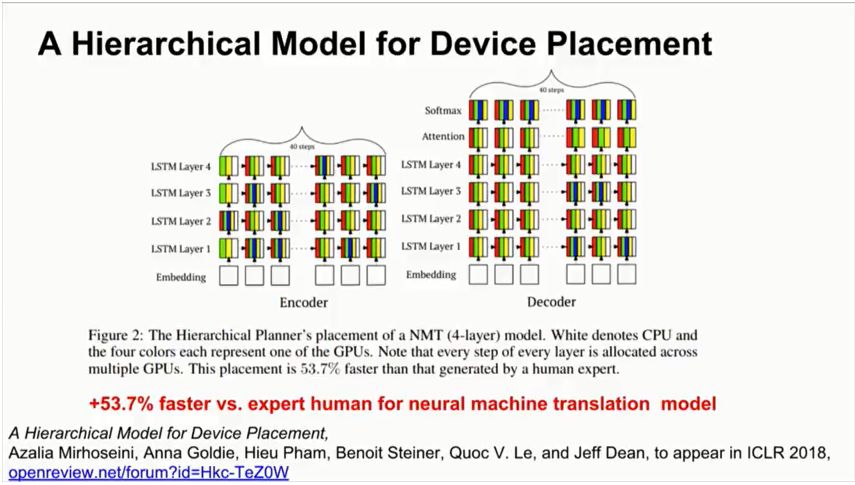
为了测量运行时间,预测全部在实际的硬件上运行。方法完全是端到端的,扩展到包含超过80,000个运算的计算图。最终,新方法在图中找到了高度细化的并行性,比以前的方法大幅提高速度。

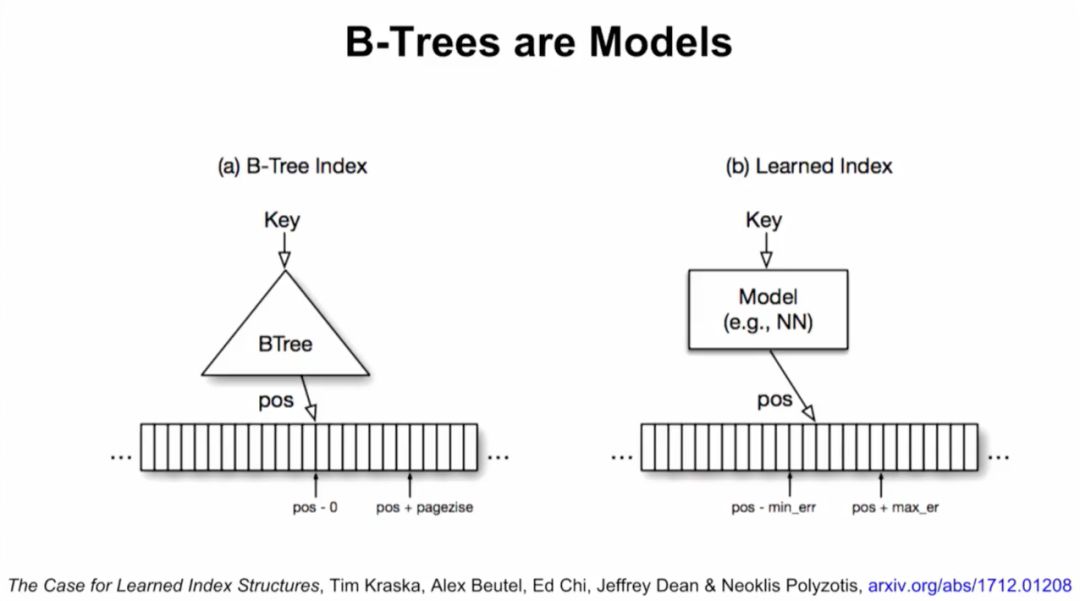
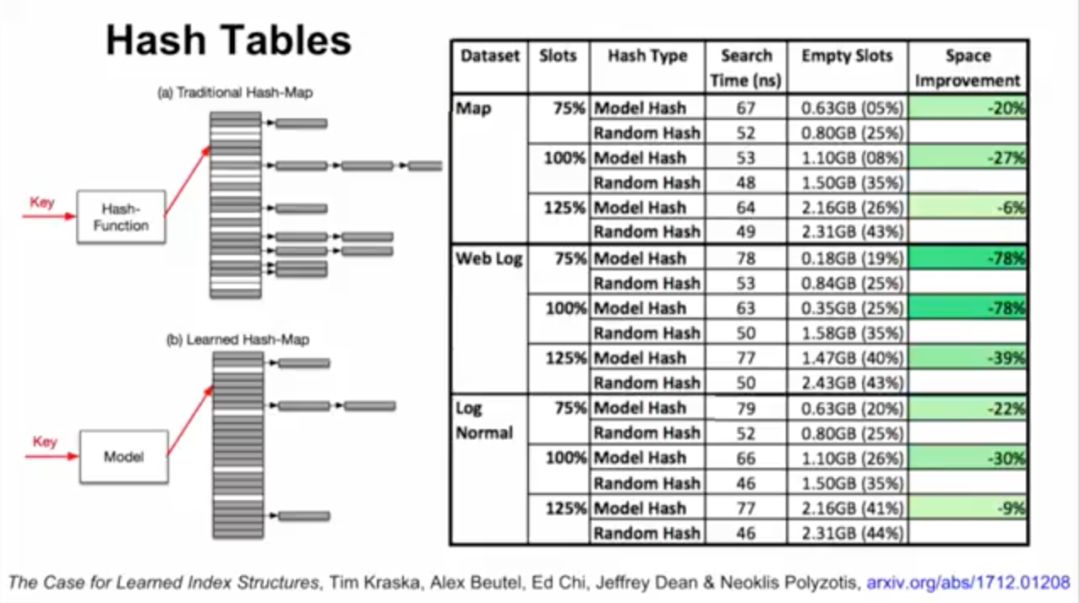
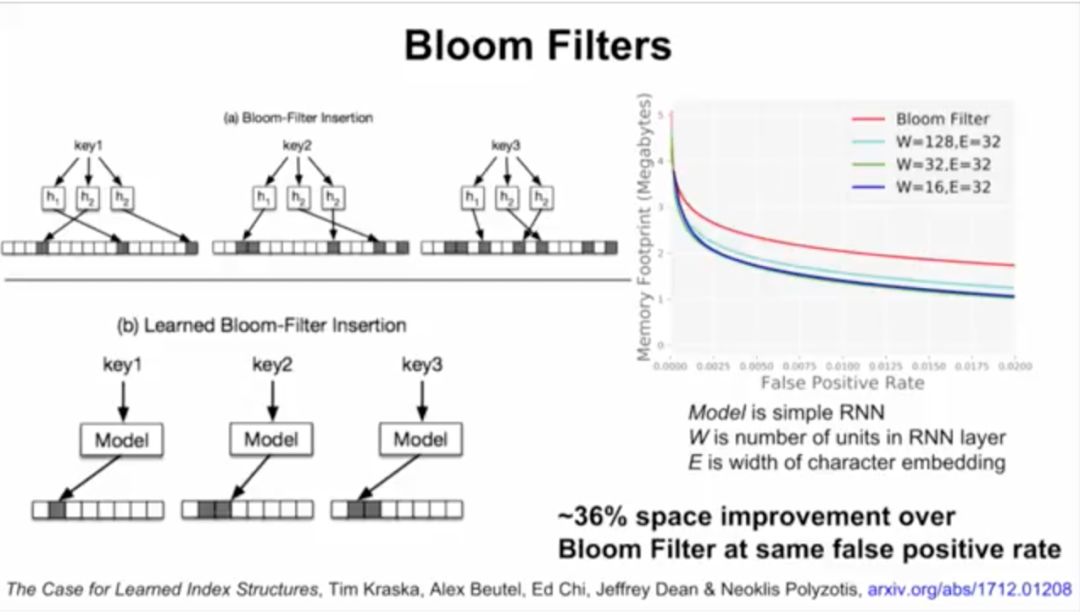
接下来,Jeff Dean介绍了谷歌大脑的研究,用ML模型替代数据库组件。他们将神经网络应用于三种索引类型:B树,用于处理范围查询;哈希映射(Hash-map),用于点查找查询;以及Bloom-filter,用于设置包含检查。
B-tree实际上可以看做模型。数据的累积分布函数(CDF)可以作为索引。举例来说,如果键的范围在0到500m之间,比起用哈希,直接把键当索引速度可能更快。如果知道了数据的累积分布函数(CDF),“CDF*键*记录大小”可能约等于要查找的记录的位置,这一点也适用于其他数据分布的情况。
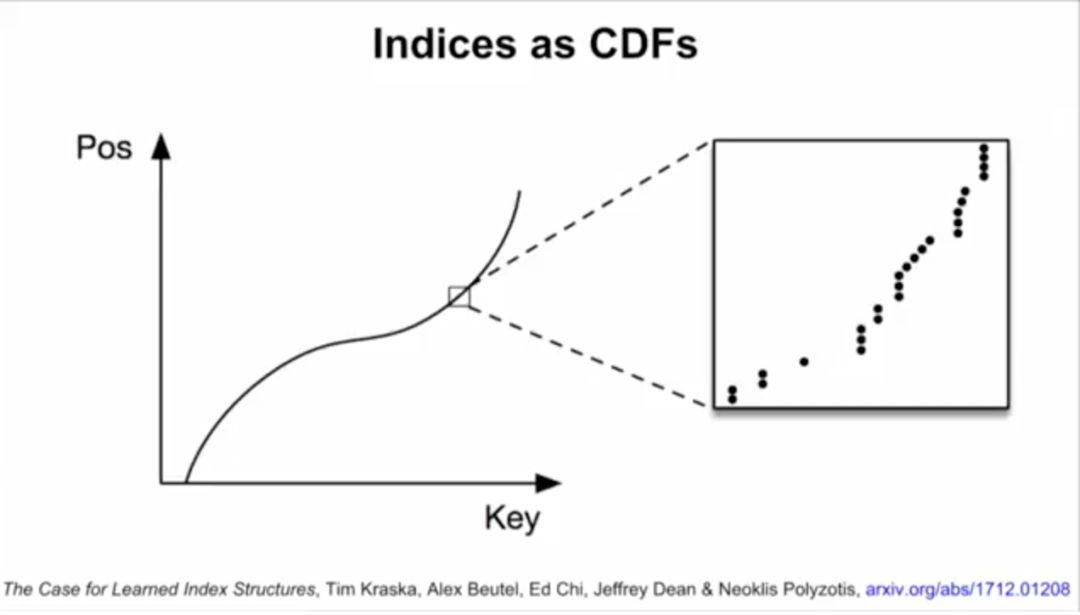

在测试时,研究人员将机器学习索引与B树进行比较,使用了3个真实世界数据集,其中网络日志数据集(Weblogs)对索引而言极具挑战性,包含了200多万个日志条目,是很多年的大学网站的请求,而且每个请求都有单一的时间戳,数据中含有非常复杂的时间模式,包括课程安排、周末、假期、午餐休息、部门活动、学期休息,这些都是非常难以学习的。
对于网络日志数据,机器学习索引带来的速度提升最高达到了53%,对应的体积也有76%的缩小,相比之下误差范围稍有加大。
精确了解数据分布,可以大幅优化当前数据库系统使用的几乎所有索引结构。
这里有一个关键点,那就是用计算换内存,计算越来越便宜,CPU-SIMD/GPU/TPU的功能越来越强大,在论文里,谷歌大脑的研究人员指出,“运行神经网络的高昂成本在未来可以忽略不计——谷歌TPU能够在一个周期内最高完成上万次神经网络运算。有人声称,到2025年CPU的性能将提高1000倍,基于摩尔定律的CPU在本质上将不复存在。利用神经网络取代分支重索引结构,数据库可以从这些硬件的发展趋势中受益。”
Jeff Dean说,这代表了一个非常有前景且十分有趣的方向,传统系统开发中,使用ML的视角,就能发现很多新的应用。

那么,除了数据库,ML还能使用在系统的哪些方面?一个很大的机会是启发式方法。计算机系统里大量应用启发式方法,因此,ML在用到启发式方法的地方,都有机会带来改变。

只要现在使用启发式方法的地方,都存在改善的机会

编译器:指令调度,寄存器分配,循环嵌套并行策略
网络:TCP窗口大小决定,退避重传,数据压缩
操作系统:进程调度,缓冲区缓存插入/替换,文件系统预取
作业调度系统:哪些任务/ VM要在同一台机器上定位,哪些任务要抢先……
ASIC设计:物理电路布局,测试用例选择
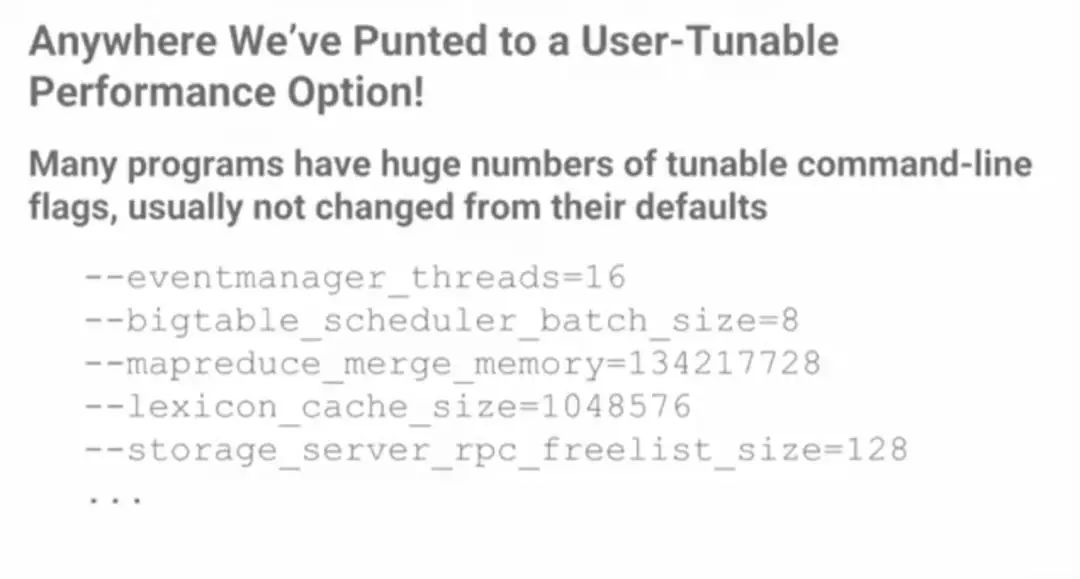
许多程序都有大量可调的命令行标记,通常不会从默认值中更改。
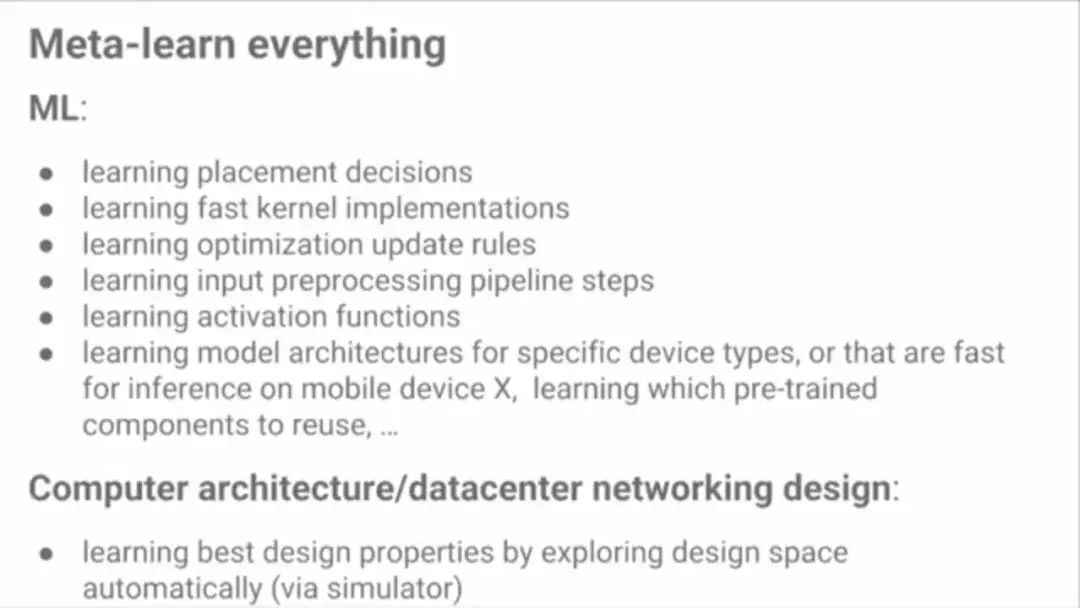
所有都可以元学习(meta-learn)
ML:
学习位置决定
学习快速内核实现
学习优化更新规则
学习输入预处理流程步骤
学习激活函数
学习针对特定设备类型的模型架构,或针对移动设备快速推理的模型架构,学习哪些预训练的组件可重用,......
计算机体系结构/数据中心网络设计
通过自动测试设计空间来学习最佳设计性能(通过模拟器)

在这些设置中取得成功的几个关键:
(1)有一个数字指标来衡量和优化
(2)具有清晰的接口,可以轻松地将学习整合到所有这些系统
目前的工作:探索API和实现
基本的想法:
在某些情况下做出一系列选择
最终获得关于这些选择的反馈
即使在分布式设置中,也可以以非常低的开销工作
支持核心接口的许多实现
总结:ML硬件尚处于起步阶段。更快的系统和更广泛的部署将导致更广泛的领域取得更多突破。我们的所有计算机系统核心的学习将使它们更好/更具适应性。

介绍完Jeff Dean这将近1小时的演讲,你会发现ScaledML绝对是一场干货爆棚的大会。
所有讲者的视频和Slides都在这里:
https://www.matroid.com/blog/post/slides-and-videos-from-scaledml-2018
英伟达首席科学家Bill Dally的PPT:https://www.matroid.com/scaledml/2018/bill.pdf
贾扬清大神的PPT:https://www.matroid.com/scaledml/2018/yangqing.pdf
Keras作者大规模深度学习PPT:https://www.matroid.com/scaledml/2018/francois.pdf
注定是一个忙碌的周末,学习吧!
精彩回顾
2018新智元产业跃迁AI技术峰会圆满结束,点击链接回顾大会盛况:
爱奇艺 http://www.iqiyi.com/l_19rr3aqz3z.html
腾讯新闻 http://v.qq.com/live/p/topic/49737/preview.html
新浪科技 http://video.sina.com.cn/l/p/1722511.html
云栖社区 https://yq.aliyun.com/webinar/play/419
斗鱼直播 https://www.douyu.com/432849
天池直播间 http://t.cn/RnQPhuY
IT大咖说 http://www.itdks.com/eventlist/detail/1992


