细读EETimes的AI芯片文章
最近EETimes上有一篇文章“AI Silicon Preps for 2018 Debuts”,非常全面的介绍了和AI芯片相关的各种问题,值得仔细阅读。由于已经有了翻译文章,我只挑一些个人认为比较有意思的内容和大家一起讨论一下。
•••
“The industry this year may see a microprocessor ship from startup Graphcore that uses no DRAM and one from rival Cerebras Systems that pioneers wafer-level integration. The hefty 2.5-D Nervana chip acquired by Intel is already sampling, and a dozen other processors are in the works. Meanwhile, chip companies from ARM to Western Digital are working on cores to accelerate the inference part of deep neural nets.”
这段文字信息量很大,其中Graphcore的无DRAM设计(Graphcore AI芯片:更多分析),Nervana的2.5D Chip(见下图)大家都比较熟悉了。Western Digital是用Esperanto Technologies(最近刚加到我的AI芯片列表)的RISC-V处理器做AI芯片。这里最值得关注的应该是Cerebras的“wafer-level integration”,据说非常“另类”。由于这家公司一直还是stealth mode,没有公开过技术信息,所以广大群众也只能先等待了。
“This is a renaissance of computer architecture and packaging. We will see much more interesting computers in the next year than we did in the past decade,” Patterson said.
计算机体系结构的大神说这句话当然是很权威了,重点是很多有趣的架构在短时间内集中出现(或者重生),确实很久没有这么过瘾了。

The rise of deep neural nets brought venture capital money back to semiconductors over the last few years. ...“We’re seeing an explosion of new startups with new architectures. I’m tracking 15 to 20 myself ... We haven’t had 15 silicon companies [emerge] in one segment for 10 to 15 years,” said serial entrepreneur Chris Rowen
不仅是架构百花齐放,对半导体创业公司的投资热情也是集中爆发。这一两年涌现的芯片初创公司,要比过去10到15年加起来还多。非常好奇Chris Rowen跟踪的15到20家是谁。
“Nvidia will be tough to compete with for training in high-end servers because of its strong software position, and you’d be crazy to go after the cellphone because you have to be good at so many things there, but there may be opportunities at the high and low ends” of the smartphone market, Rowen said.
放在美国,这么说我是非常赞同的。但结合中国国情,我认为可能有一些其它的机会(中国初创公司在AI芯片(IP)领域的机会)。
后面是对server端Training芯片的一些具体分析。以下是Intel Nervana的Chip框图。
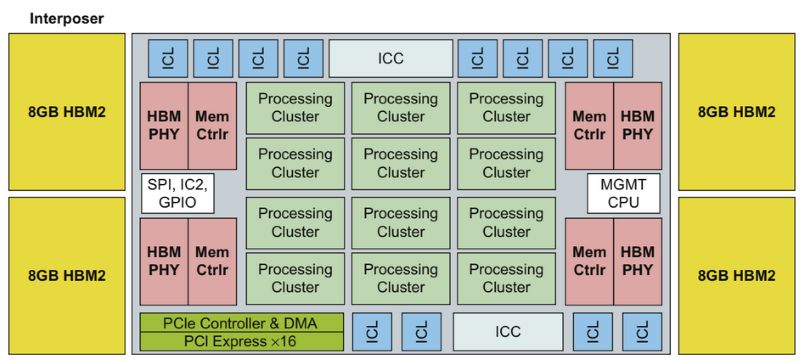
Intel’s Nervana is a large linear algebra accelerator on a silicon interposer next to four 8-Gbyte HBM2 memory stacks.Source: Hennessy and Patterson, “Computer Architecture: A Quantitative Approach”
Intel’s Nervana, called Lake Crest (above), is one of the most-watched custom designs. It executes 16-bit matrix operations with data sharing a single 5-bit exponent provided in the instruction set.
As in Nvidia’s Volta, the Lake Crest logic sits on a TSMC CoWoS (chip-on-wafer-on-substrate) interposer next to four HBM2 high-bandwidth memory stacks. The chips are designed to work as a mesh, delivering five to 10 times the performance of Volta.
Nervana的一个特色就是所谓flexpoint的数据精度。而对于Server端的training应用,HBM2(High Bandwidth Memory)和多芯片扩展已经是标配了,比如Nvidia Volta支持8颗芯片互连(下图),Google的TPU2也是4颗芯片组成一块板卡来工作。
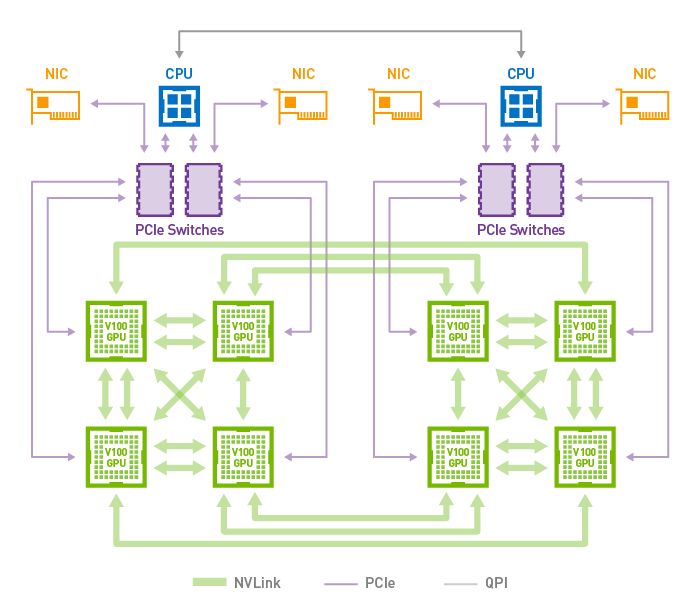
图片来自Nvidia网站
•••
文章第二部分的标题是“Accelerators lack common benchmarks”。其实我之前也写了一系列文章来讨论这个问题:给DNN处理器跑个分 - BenchIP,给DNN处理器跑个分 - 指标篇,给DNN处理器跑个分 - 设计篇。
确实,目前这个领域还没有权威的Benchmark。而出现(形成)一个权威的Benchmark不单纯是个技术问题。“It’s like the early days of RISC processors, recalled Patterson, when “each company would say, ‘You can’t trust the other guy’s benchmark but you can trust mine.’ That didn’t work well.””
当然,目前已经有很多组织开始制定Benchmark,比如文章所提的“Transaction Processing Performance Council (TPC)”,Baidu的DeepBench,Harvard 研究人员提出的“the Fathom suite”。另外,国内也有标准化组织在做这方面的事情。
后面的话题转到了另一个方向。我们知道,Benchmark一般是比较稳定的,而对于AI这个变化很快的领域,硬件设计如何能跟上节奏:
“Beyond the benchmarks, engineers need to track the still-evolving neural-network algorithms to make sure their designs don’t get left in the dust.” ““The marketplace determines which chips work best,” Patterson said. “It’s brutal, but that’s the excitement of designing computers.””
最终还是市场说了算,brutal并excitment吧。

这里还给了几个例子。第一个是高通,“So far, the mobile-chip vendor is running neural-net jobs in software on the DSP and GPU cores in its Snapdragon system-on-chip, but some observers expect it will tailor a new block for machine learning as part of a 7-nanometer Snapdragon SoC in 2019.”高通的异构架构我们之前也讨论过(高通的Hexagon DSP),做的还是非常高效的。目前的NN处理放在这个架构上已经能做不少事情了。当然,我们也期待看到他们的NN专用处理器。
另一个例子是算法对架构的影响。虽然我不是很赞同文章关于bach size问题的说法,算法对硬件设计的影响还是不言而喻的。
For example, Facebook recently demonstrated it could reduce training time from a day to an hour for some jobs by dramatically increasing the number of features packed into so-called batch sizes. That could be bad news for Graphcore, which tries to run all operations in local SRAM, eliminating the latency of external DRAM accesses but also limiting its memory footprint.
“They designed for a small batch size, but the software results from a couple of months ago suggest you want a large batch size. That indicates how quickly things are changing,” Patterson said.
最后一个例子是Rex Computing。这个公司在15年的时候也火过一阵,比如知乎就有这样的问题“如何看待 19 岁少年想做出在目前 Intel 同等计算性能下降低 80% 功耗的全新电路系统芯片?”。我之前也关注过他们,因为他们做的“创新”:VLIW, 不用cache,静态路由,不用虚拟内存,就是把我们在专用处理器上常用的方法放到了超算领域。这种设计当然对一些应用会有更高的效率,可是生态怎么办呢?从文中的说法“ The startup is targeting a June tapeout for a 16-nm SoC with 256 cores that it hopes will deliver 256 Gflops/watt.”似乎这两年他们进展不大。
•••
文章第三部分的题目是“Still early days for AI algorithms”。确实,算法的不确定性是芯片设计的大敌。但目前在这一点上,谁也很难做出一个准确的预测。大家只能把它作为一个必须承担的风险来接受了。
“There’s a high probability the algorithms will change in five years. We are gambling that the lowest-level primitives, like matrix multiplies, will be immutable,” said Advanced Micro Devices Fellow Allen Rush, speaking at a recent IEEE symposium on AI.
Overall, “the hard problems of AI are still hard,” he added. “The best researchers can get a robot to unlock a door, but picking up a cup may be harder than winning Alpha Go,” “source:one of the early triumphs of DNNs”.
•••
文章第四部分的题目是“Pioneers expand the application frontier”。相比“算法发生巨大变化”这片“悬在AI芯片上头顶的阴云”,应用领域的不断扩展应该是好消息。文章也举了很多例子。相信大家每天都能看到AI应用到某个新的领域的新闻。虽然很多消息有夸张的成分,但实实在在的应用也不少。所以,对于这个话题,过高的期待或者过于悲观的看法似乎都是没有必要的。“拿锤子找钉子”虽然听起来不靠谱,但大家都举起锤子各处敲打敲打不也是挺欢乐的场面吗。

Patterson, for his part, remains upbeat. While the broad AI field has failed to live up to some past promises, its current successes in areas such as machine translation are real, he said. “It’s possible all the low-hanging fruit is picked and there won’t be anything more exciting, but you read about advances almost every week … so I think we will find a lot more uses.”
•••
文章第五部分的题目是“First efforts toward software convergence”。对于AI芯片来说,和Benchmark问题类似,这也是一个重要话题(之前我在“Deep Learning的IR“之争””中也探讨过这个问题),而且现在也还没有结论。目前的AI软件(训练平台,编译器,库等等)还是处在一个比较混乱的状态。各种训练平台并存也给AI加速芯片的设计增加很多工作量。你不知道用户用什么样的平台训练模型,所以必须能够适配各种平台产生的数据。
现在也有一些工作在试图解决这个问题,比如文章里提到的ONNX:“One of the more promising is the Open Neural Network Exchange (ONNX), an open-source project started by Facebook and Microsoft and recently joined by Amazon. The group released version 1 of the ONNX format in December. It aims to translate neural-net models created with any of a dozen competing software frameworks into a graphical representation.”
以及NNEF:“A group of more than 30 mainly chip vendors released their preferred option, the Neural Network Exchange Format, on Dec. 20. NNEF aims to offer chip makers an alternative to creating their own, internal formats, as Intel did with Nervana Graph and Nvidia did with TensorRT.”
但问题也和Benchmark一样,这种数据结构(或者IR)的标准,往往涉及很多技术以为的因素,短期之内很难统一。所以,广大AI芯片的厂商也还是得“都支持”。
•••
文章最后一部分“A look toward the far horizon”,当然是看看未来的趋势。这里首先提到算法发展的趋势,从supervised到unsupervised。“The end goal is unsupervised learning — computers teaching themselves, without help from the engineers who built and programmed them.”这个趋势也许会对计算需求产生影响:
“Google says we need a lot of computation now, in this intermediate stage, but once things are automatically labeled you will only need to index new incremental content, [which is] more like how humans process data,” said Janet George, chief data scientist at Western Digital.
也许我们现在还是初级阶段,或者过渡阶段,未来的运算模式会发生很大变化。但这个未来什么时候会来,可能还没人能预测。
说到半导体技术的未来,这篇文章主要介绍的是电路和器件级的技术。首先的一个关键字是3D。
With Intel, Graphcore, and Nvidia “already making full-reticle chips, the next step is 3-D,” said Patterson. “When Moore’s Law was in full swing, people would chicken out before looking at exotic packaging for fear of reliability and cost problems. Now that Moore’s Law is ending, we will see a lot of experiments in packaging.”
除了3D封装,还有3D器件,比如:
The end game here is creating new kinds of transistors that can be stacked on-die in layers of logic and memory.
Suman Datta, an electrical engineering professor at Notre Dame, is bullish on negative-capacitance ferroelectric transistors as the basis of such chips. He laid out the landscape in the area at a recent conference dedicated to so-called monolithic 3-D structures. Such designs apply and advance the kinds of gains 3-D NAND flash has made with on-die chip stacks.
另外的关键字当然是存储。比如文章中介绍的ReRAM。由于AI芯片的特点就是数据主导和数据流驱动,存储是最重要的一个方向。介绍这个话题的文章很多,这里就不多说了。
其实,说到未来,谁能真的把Vathys的几个脑洞实现了就已经很牛了(Petascale AI芯片Vathys:靠谱项目?清奇脑洞?还是放卫星?)。
- END -
题图来自网络,版权归原作者所有
长按二维码关注




