万级规模 K8s 如何管理?蚂蚁双11核心技术公开


系统概览
设计模式
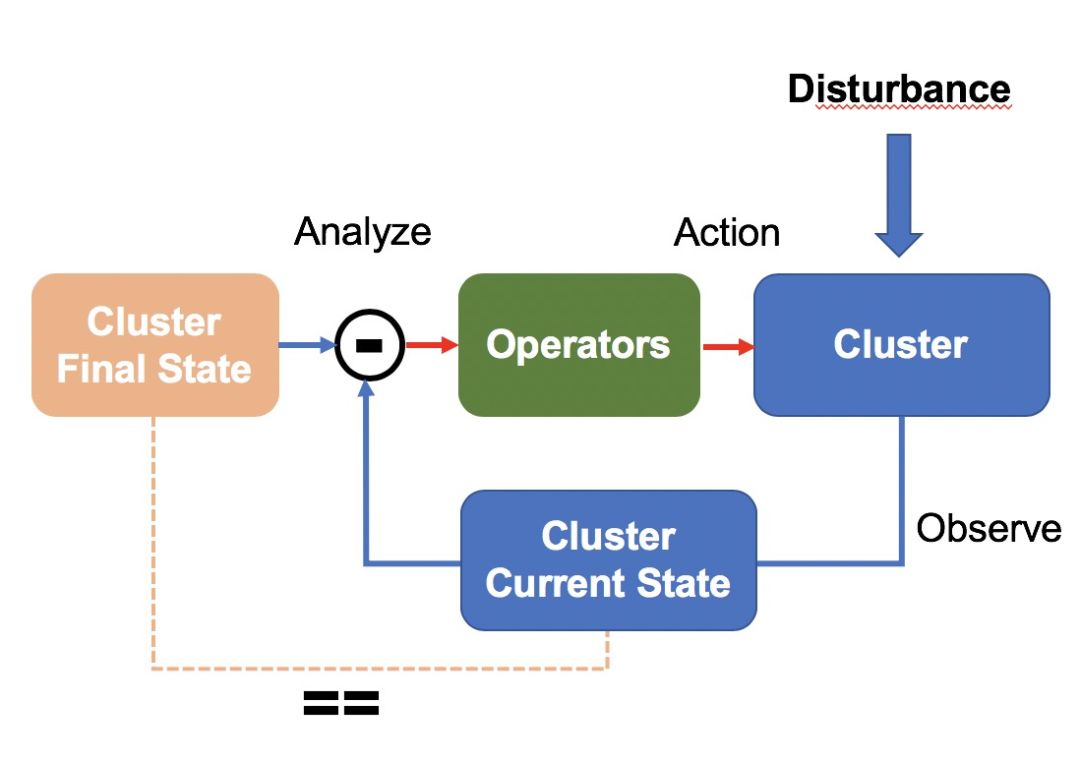
架构设计
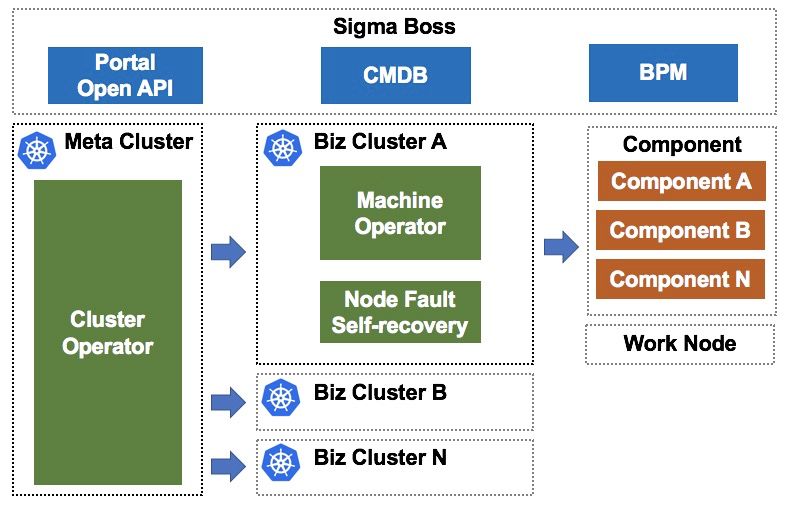
集群终态保持器
节点终态保持器
-
节点系统配置、内核补丁管理; -
docker / kubelet 等组件安装、升级、卸载; -
节点终态和可调度状态管理(如关键 DaemonSet 部署完成后才允许开启调度); -
节点故障自愈。
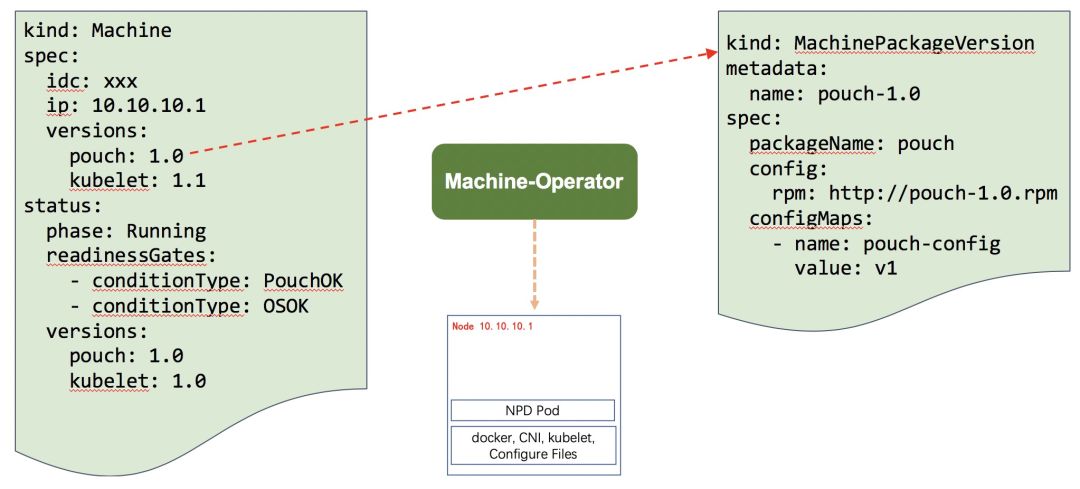
节点终态管理
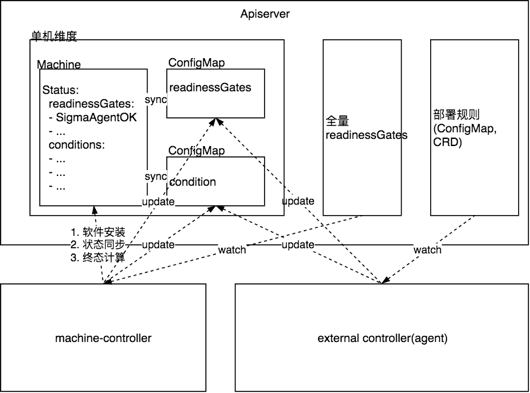
-
全量 ReadinessGates: 记录节点可调度需要检查的 Condition 列表; -
Condition ConfigMap: 各节点运维 Operators 终态状态上报 ConfigMap;
-
外部节点运维 Operators 检测并上报与自己相关的子终态数据至对应的 Condition ConfigMap; -
Machine-Operator 根据标签获取节点相关的所有子终态 Condition ConfigMap,并同步至 Machine status 的 conditions 中; -
Machine-Operator 根据全量 ReadinessGates 中记录的 Condition 列表,检查节点是否达到终态,未达到终态的节点不开启调度。
节点故障自愈
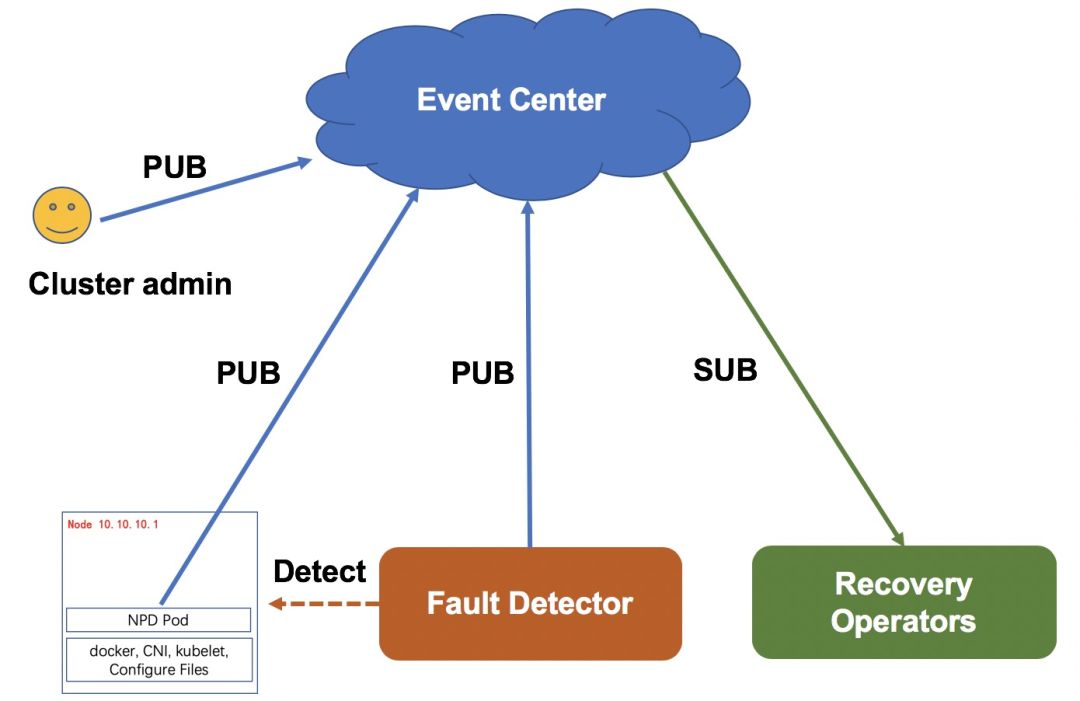
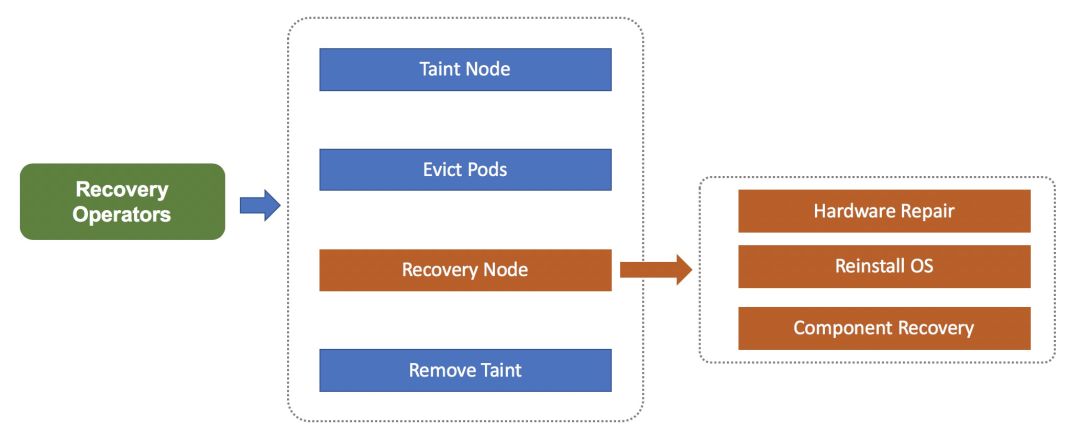
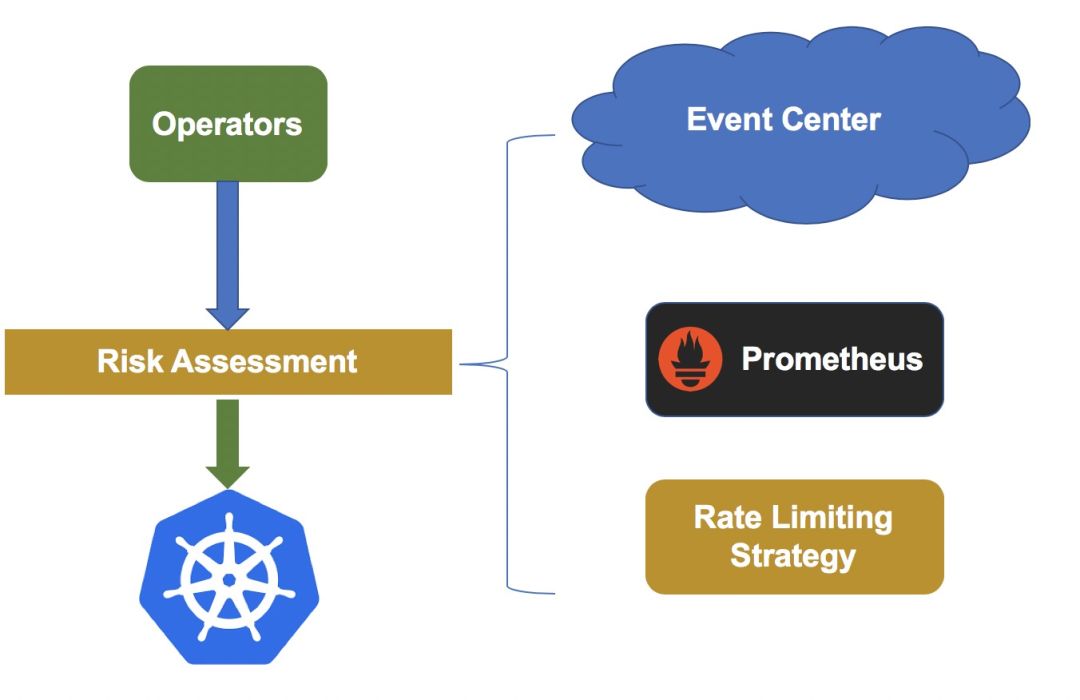
风险防范




2684亿!
阿里CTO张建锋:不是任何一朵云都撑得住双11

每秒订单峰值54.4万笔,我们扛住了!


登录查看更多
相关内容

Arxiv
5+阅读 · 2017年12月7日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2017年12月7日