12月的音乐可视化笔记:我从TOP2000歌曲中,分析了这几年流行音乐的变化趋势

大数据文摘作品
编译:HAPPEN、朝夕、林海、吴双
2017年的最后一个月挟裹着寒风悄悄地来临了,与我们不经意间撞了一个满怀。今天,我们收录了两篇特别可爱的“创作笔记”,是生活在阿姆斯特丹的Nadish和在旧金山生活的Shirley,因为要共同在12月份完成属于各自的一篇音乐可视化的小项目。他们各自用了4周完成创作,并写了下了两篇”创作笔记”。
从一开始确定各自的选题,到收集数据完成阶段性效果草图,再到最终实现代码完成验证,他们经历了一些趣事,我们从中既可以看到音乐可视化模型的新视角,也希望为大家在寒冬里带来一丝暖意。
“我从TOP2000歌曲中,分析了这几年流行音乐的变化趋势”
第一周 | 数据
关注大数据文摘,公众号后台回复“隔壁老王”,下载设计师老王从隔壁发来的高清大图
当你和荷兰人谈论“12月的音乐”,他们很有可能想到Top 2000,这是一个从圣诞节开始到12月31日午夜之间播放的年度音乐榜单。我其实在之前就接触过这份数据。那是我的第二个正式个人项目,当时对于d3(交互式数据可视化的Java库)我还是个新手。有时我会看到艺术家重温自己过去完成的作品,来审视自己风格的变化(这也是我很爱做的事),我认为这个项目很适合去尝试一下(在效果草图(sketch)的部分,你可以看到我其实已经思考这个想法长达几个月了)。所以,在我初次尝试了两年后,我开始再次关注Top2000并将一些见解进行可视化处理。
不用担心你不是荷兰人,Top2000榜单中90%都是英文歌。Queen常常排榜首,还有许多Beatles、U2、Michael Jackson的歌,所以这份列表对你来说可能很熟悉。
Top2000网站在今年12月19日公开分享了一份包含2000首歌的歌名、歌手、发行年份等特征的Excel文件。
但是我需要另一个重要的变量:歌曲在每周榜单中达到的最高排名。
这在荷兰比较少见,我最终选择使用每周Top40作为重点研究对象,一方面因为它从1965年开始持续到今日没有中断,另一方面是它的数据看起来很好抓取。因此我写了一个小爬虫程序,爬取了近50年的列表,保存了歌手名字、歌曲名称、歌曲界面地址以及排名位置。之后我将数据做了整合,使每一首歌都有唯一一行数据(歌曲的URL是唯一键),并保存了额外的信息,例如达到的最高排名以及在Top40上榜的周数。
接下来是麻烦的地方,将Top40的歌手和歌曲与Top2000相匹配。当然我首先尝试直接通过精准匹配歌手和歌曲名称来融合两张榜单,结果只有大概60%的歌曲被完全匹配。浏览了剩下的歌曲后,我发现两张榜单有时候用词的长度有差异,比如John Lennon-Plastic Ono Band 对应John Lennon。所以我开始在两张榜单中搜索部分匹配的歌曲,只要这首歌曲名和歌手名的所有单词都能被另一张榜单的某一项包含即可。这种方法帮助我又匹配了10%的歌曲。
随后是不好判断的部分。有时候有些单词的拼写存在微妙的区别,例如Don't stop 'til you get enough 对应Don't stop 'till you get enough。我使用了R语言的stringdist包,用其中的Full Damerau-Levenshtein距离来比对两个榜单的歌曲名与歌手名(它计算了将b转为a时相邻字符发生的删除、插入、替换、转置等必要变换的数量)。我在处理上比较严格,设定在标题和歌手名匹配时只能有两次变换(否则歌曲 U2的Bad 可能会被转换为任意一首三个词的歌和2-3个词的歌手)。令人沮丧的是,这种方法只提高了2.5%的匹配率。这侧面说明,我非常需要在每一步处理后快速检查一下所有已匹配的歌曲,以找出错误的匹配。
此时还有大约600首歌未被匹配。不过这并不是很糟糕的事,因为不是所有的歌都在Top40中,例如排名第三的歌,Led Zeppelin with Stairway to Heaven ,因为它只发行了唱片而没有发行单曲。但是如何判断未匹配的歌是确实理应匹配不上还是出现在Top40中但未被匹配呢?我采用的最后一个想法是使用每周音乐贴士(Tips of the week)。从1970年左右开始,音乐网站在评选Top40时,还提供了一个20-30条左右的扩充列表以列出一些不在Top40中,但被DJ认为将在或应该在榜单中的歌曲。因此我抓取了所有年份的列表,然后像Top40那样处理了一遍。这个方法匹配了8%左右我确定是在Top40中从未出现的歌曲(但是它们曾经在扩充列表中被提到过)。
对于剩余的430首歌,我浏览了列表中的较长或少见的歌手名或歌曲名,这些是我认为可能是匹配方法没有成效但的确出现在Top40中的歌曲,例如Top2000中的 Andrea Bocelli& Sarah Brightman对应Top40中的 Sarah Brightman& Andrea Bocelli 。我无法确定剩下的380首歌中有多少曾出现在Top40里,但是说实话,经过所有的数据处理以及我对数据的检查,我认为这种情况低于10%。
第二周 | 效果草图
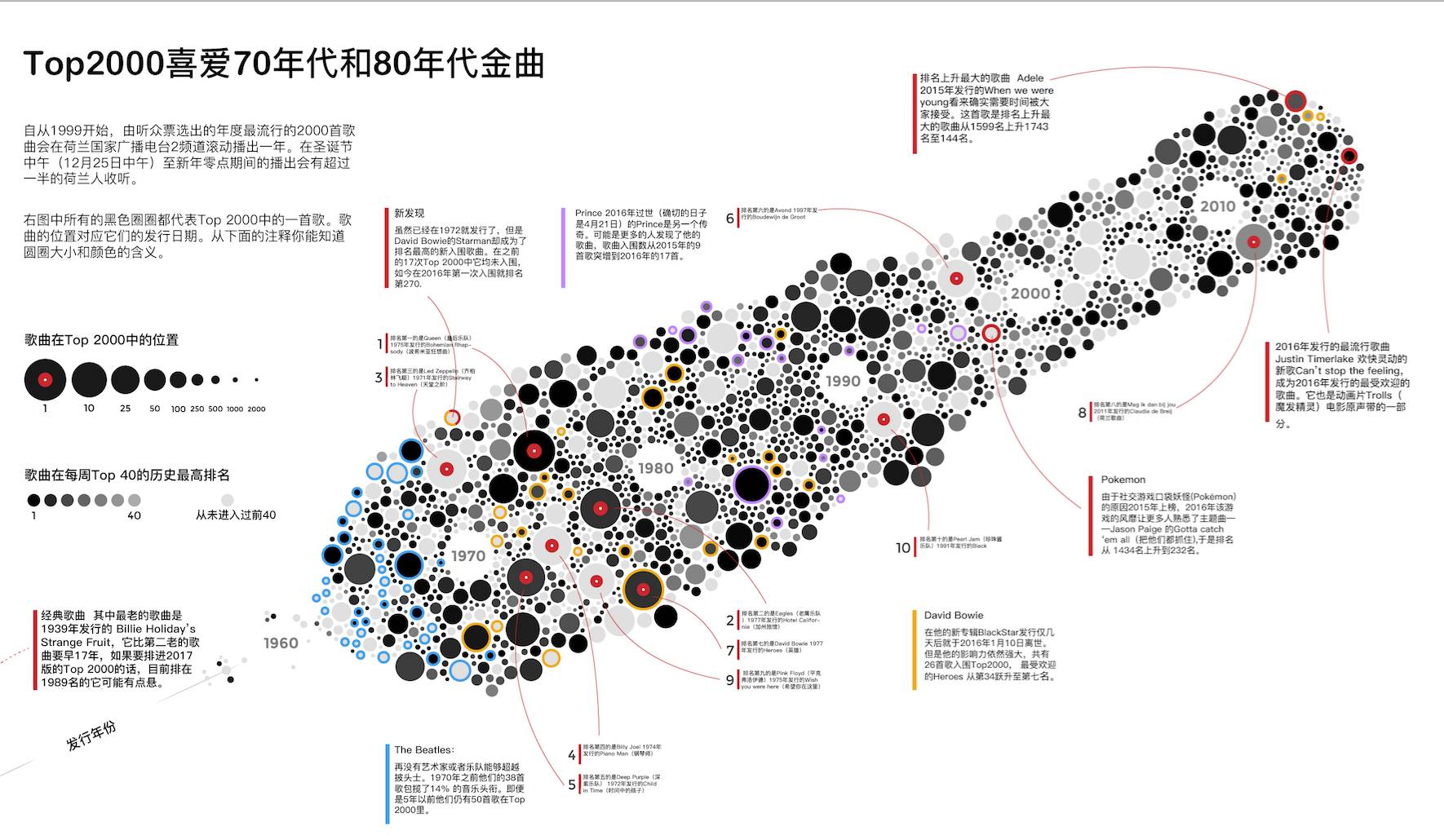
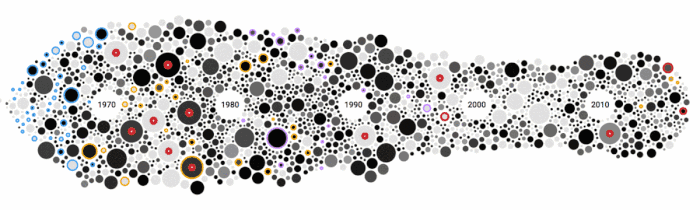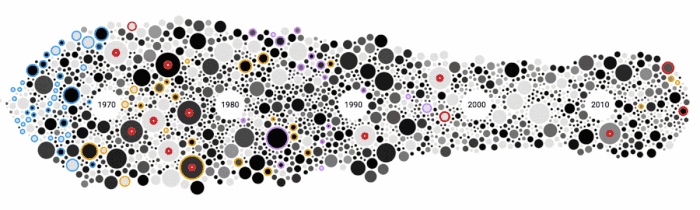
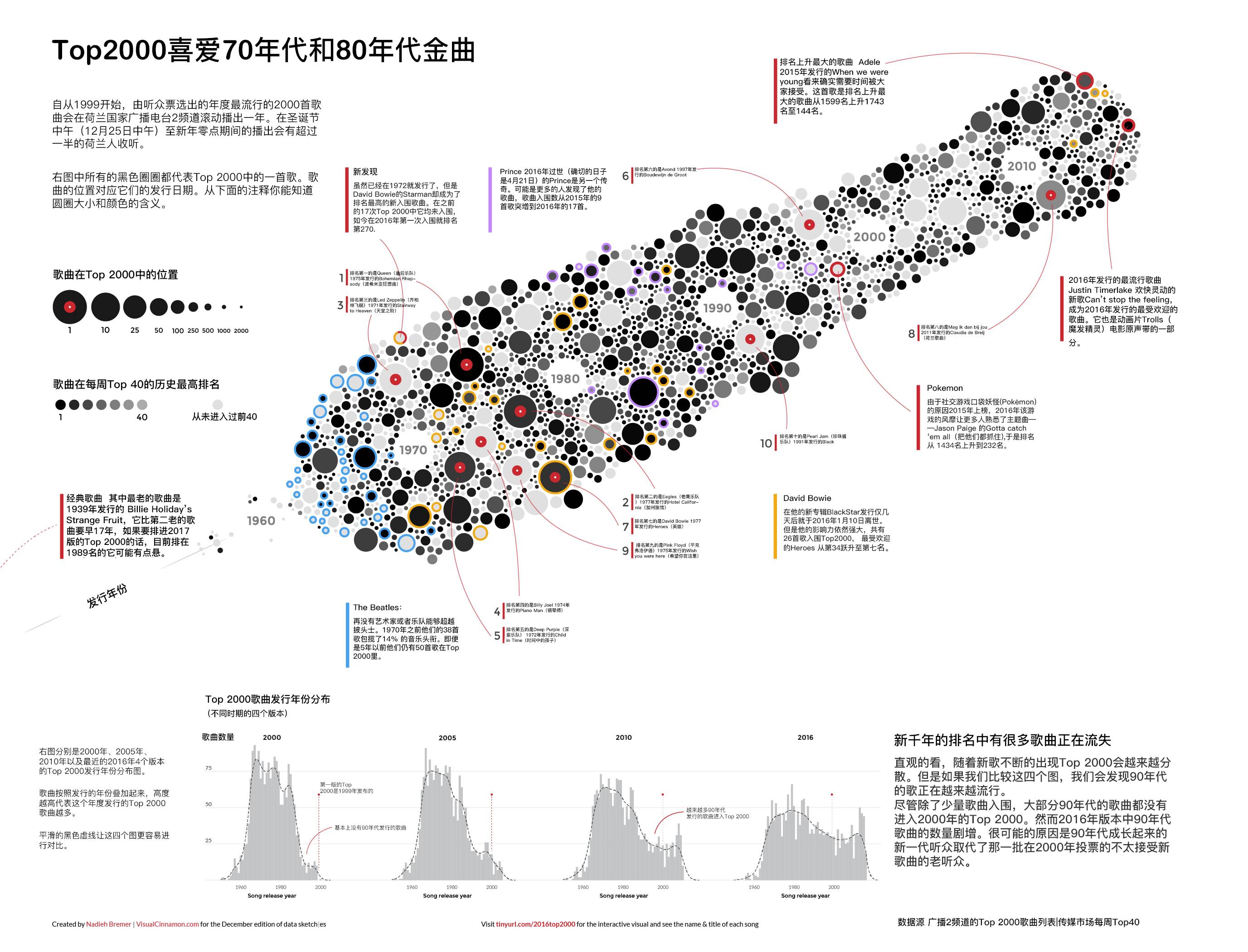
今年春天我参加了 Juan Velasco一家很棒的工作坊叫“ Information Graphics for Print and Online”。这家工作坊的一部分工作是绘制信息图。我的三人小团队对Top2000歌曲榜单都非常感兴趣,写下了大约40个可能的想法。但从我之前对这份数据进行可视化的尝试中,我已经知道在过去的时间里,最受人喜欢的年代(歌曲发行时间)发生了一个非常有趣的变化。因此,我们选择以它作为整体概念,围绕着它来设计信息图的每一个基础部分。
以最新的Top2000榜单为中心,将同一年发行的歌曲聚集在一起,通过蜜蜂群图来可视化。每一个圈(也就是一首歌)的大小由它们在Top40的最高排名来决定,颜色由它们在Top2000的排名决定。其中一些歌曲会添加注释,并高亮提示,例如排名最高的新歌。
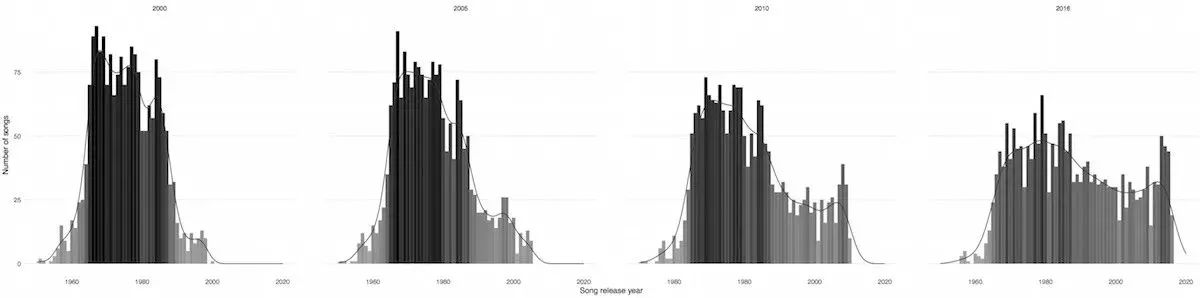
最后,底栏中是一些迷你图表,突出展示了1999、2008、2016年版本的Top2000榜单中被选歌曲的发行年份分布。这强调了一个事实即1999年,大部分歌曲都是在70年代发行的,但是它们慢慢地进入了下几个十年。
在工作坊的第二天,我们在之前的概念上设计了移动端手机版本的交互图。这一次我们引入了一张很长的可滑动的蜜蜂群图,理论上你可以点击播放每一首歌,并查看额外信息。
第三周和第四周|代码
这个月我终于开始集中精力做一个静态海报。无论如何我还是准备使用d3来创建核心部分-蜜蜂群图。然后我把它拖进Illustrator。底部的直方图我将直接用R生成导入Illustrator,所以说这是多种工具协作的结果。
使用d3v4(数据可视化软件D3.js V4版本)可以定义横跨x和/或y轴的力,使得创建蜜蜂群图变得十分简单。这里我使用水平轴向的力把歌曲按照发行年份进行汇聚。我花了好几个迭代来找出x轴和y轴方向的力平衡(为了避免圆圈的重叠,我加了偏移量)。最终这些歌曲在年代轴上分布地非常完美也没有出现有些歌曲偏离发行年代太远的情况。
起初,我用歌曲在TOP 40榜单的最高排名生成圈圈的大小,用他们在TOP 2000的排名来分配颜色。但是,却生成了大量几乎相同大小的浅灰色圆圈(请看下图),这看起来并不是很漂亮。

所以我交换了这两个规则(即大小使用Top 2000的排名决定,颜色深浅则由Top 40的排名决定),效果立竿见影。然后我对想要注释的圆圈(歌曲)进行标记。受到黑胶唱片那强烈黑色的灵感启发,我想用黑白来展现,只使用红色标记有些趣事的歌曲,蓝色标记列表里拥有最多歌曲的艺术家或者乐队(披头士乐队)。针对David Bowie and Prince这两个著名歌手今年(2016年)辞世的噩耗,我特意用黄色和紫色进行了标记。
由于排名前十的歌曲圆圈最大,我特意把它们做成了黑胶唱片的外形(其实也就类似一个红圈上面叠加一个小的白圈)

一个小提示:不要对SVG(可缩放矢量图)矢量图的外侧描边,因为当对一个元素描边的时候,笔画的宽度会覆盖在元素的轮廓上。而在这个项目中我需要让整个灰色圆圈都被看到而不是被描边挡住一部分(这种情况对于小圆圈非常明显),所以我在灰色圆圈后面画了稍微大几个像素的彩色圆圈模拟彩色的描边。下面的动图中这种“大一点”的圆圈就是使用了这种背景圆圈的画法,以此使得灰色圆圈可以保持真实半径。
完成这些简单的元素设计并确定我不会再做任何更改了之后,我使用SVG Crowbar工具保存蜜蜂群图并用Illustrator打开。然后我把图片旋转25度角使其看起来效果更好,并且放上了注释(使用网络线来对齐行和列)。通过数据和Top 2000的网站可以得到一些有趣的结论,比如Justin Timberlake在2016年拥有一首排名最高的歌曲。
完成蜜蜂群图(信息图的上部分)后,我认为需要有个小巧的交互版本,这样你可以将鼠标悬停于圆圈上去看看它是哪首歌。我花了2-3个小时把蜜蜂群图用提示插件和注释进行了优化。

我还想知道不同发行年代的歌曲分布在90年代和00年代发生的变化。这是一个额外的细节,是对数据更深入的理解。我想把这些发现放在主图的下面,但是犹豫使用哪种可视化的方式来表现这个信息。2年前我已经有了历史的Top 2000数据,所以我只需把2015和2016的数据添加进去然后做成可视化图。从一开始我就觉得应该像直方图那样呈现,但是是否应该做平滑处理?该展示哪些年份的数据?是以重叠还是分开的形式?
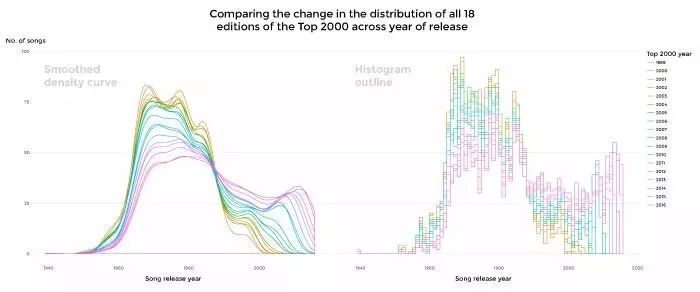
最后我选择了4个简单的直方图分开展示过去18年里四个时期的数据,为了让这4个图更容易比较,我添加了平滑密度曲线。下面的图就是我直接通过R调用ggplot2绘图包制作的图(柱状的高度使用了不同深浅的颜色区分。而为了不让这些直方图喧宾夺主吸引太多的眼球,我最终选择了灰色)。
下面就是最终的信息图。除了英文版的我还做了一个荷兰语版本,毕竟数据反映的是荷兰的流行音乐文化。
关注大数据文摘,公众号后台回复“隔壁老王”,下载设计师老王从隔壁偷来的高清大图
其实,我决定做一个信息图的另一个原因是这个月时间比较紧,12月7号了我才完成11月的数据草图,我当时计划去伦敦过一个短暂的假期(8个月了,我在那里再次遇见了Shirley)我们一起度过了12月的最后几天。而且我做静态视图一向很快,即使这些还部分基于我还不太熟悉的d3。
数据的爬取和清洗工作耗费了我大概20个小时,构思和草图大概3小时,写代码和作图大概20-30小时(我一直告诉自己要赶上进度,呵呵)。完成这些静态图之后,总是提醒我自己是多么喜欢制作“可打印的”东西啊!
“我拿到了大家最爱的DDR(劲舞革命)全部曲库,并搞透了他们的步法!”
第一周丨数据

最初,在我们同意12月份做音乐项目的时候,我感觉相当迷茫。除了也许做点和K-POP(韩国流行音乐)相关的之外,我不知道应当做什么。正当我和Kenneth Ormandy为找不到头绪而发愁时,我猛然间想起了DDR(跳舞机游戏:劲舞革命,Dance Dance Revolution)。
DDR曾经是我青少年生活的重要组成部分。2001年,我第一次在朋友家里见到它。而那时我家附近根本没有可以玩DDR游戏的游戏厅,为此,我乞求父母给我买一套。然而,说起来容易做起来难,因为当时我家还没有买过任何视频游戏,所以,只购买DDR游戏是不行的,还必须购买配套的PS2游戏机以及相应的游戏垫才可以。我用了两年的时间才说服父母,在那年夏天终于拿到手。之后我几乎天天都要玩几个小时。玩游戏时,我比较喜欢在同一首歌、同一难度反复地玩,直到我完全掌握为止(这里面的完全掌握指的是能够连续通关这首歌两次)。我经常玩DDR,直到5年后我上大学为止。
(老实说,我其实没有那么厉害,我最好的成绩是通关难度在8/10级,而玩得最顺手的则是6或者7/10级)
说做就做,当我第一次去搜索相关信息时,找到的数据之多令我非常兴奋,包括几百首(也可能是几千首)DDR歌曲,且至少有三种难度级别、多种BPMs(一分钟内歌曲的节拍数)和Groove Radar(合拍雷达,DDR的一个难度指标值,以图表形式度量步法与音乐合拍的难易度,包括五个方面:Stream, Voltage, Air, Chaos, and Freeze),这可是相当大的数据量!(顺便说一句,我可从来不知道也有人称呼pentagon为Groove Radar,我也是刚刚Google了一下才知道。)即便在我最大胆的梦里,也绝不会想到可以获得645首歌里面的所有步法。但是,我却找到了令人称奇的DDR Freak站点,以及他们的步法表,如下:

然后,我开始咨询懂计算机的朋友,探寻从这些图像中获取数据的方法。但是,Kenneth建议我先给DDR Freak发电子邮件,询问他们是否有原始数据。对此我有些犹豫,因为DDR Freak的网站已经至少5年没有任何变动了。但是,我还是找到了一个电子邮件地址(Jason Ko,DDR Freak创建者),就想说,为什么不写一封信呢?反正也没指望能够得到回复。
然而,Jason在18分钟后回复了我(注意:是18分钟),并附上了一个包括他手头上所有歌曲的压缩文件。他实在是太牛了!他的压缩文件包有几种不同的数据格式,包括:.dwi(舞蹈乐曲文件)和.stp(他们自己的专利模式文件)。
.dwi文件内容如下:
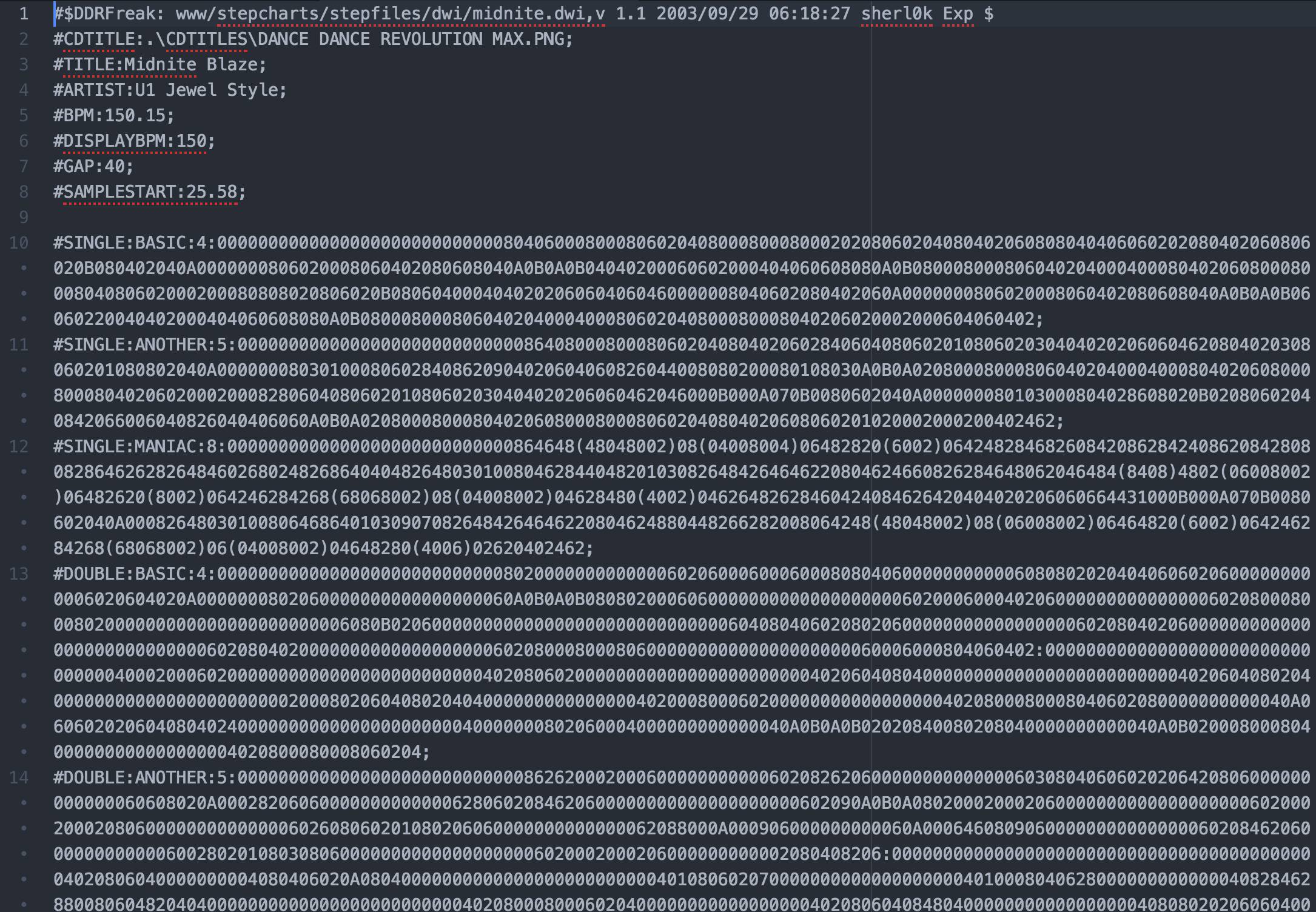
对于该文件格式,可以非常简略做如下解释:0表示没有箭头,2表示向下箭头,4向左,6向右,8向上。通常,缺省设定是每个字符为1/8拍,但是圆括号(...)里面字符为1/16拍,方括号 [...]里面字符为1/24拍,依此类推。
有了这些信息,我就能够很快对.stp文件进行反向还原工程(reverse-engineer),同时我也发现这些文件界面友好,很容易上手,我最后也确实采用了这些文件来建模。
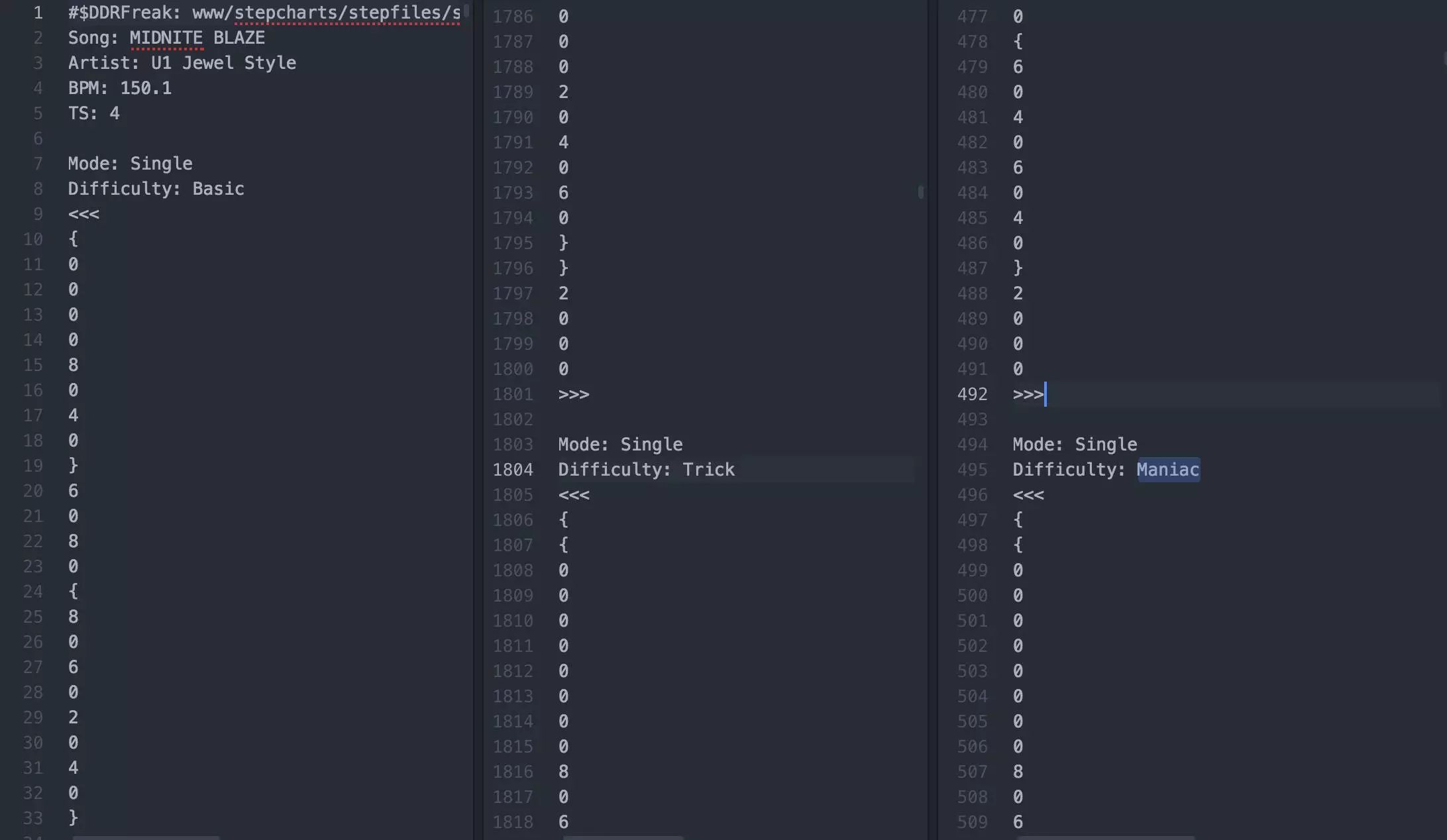
在这里,我发现唯一不一样的地方就是,它没有使用圆括号(...),而是使用大括号 {...} 来代表1/16拍,嵌套大括号{{...}}来表示1/24拍(尽管在我的编码中,我假定为1/32拍),等等。
如果你想利用该数据集,以下是我利用该数据编制的(超级直接)解析代码(parsing code),及其产生的.json文件。
第二周丨效果草图
因为我12月份中大部分时间都出行在外,所以,我想做得相对简单些。几周前,我曾经看到过teamLAB(日本科技艺术团体)的水晶宇宙(Crystal Universe),被其美景所震撼!

所以我也想在12月份也做出类似的效果图。图中每一步都是一个光点,我依据该步法在歌曲中的位置来点亮相应的光点。在起步阶段,我将光点按照每一首歌曲的2个模式(mode)(单人、双人)(Single and Double)和三个难度层级(level)(基础、熟练、流畅)(Basic, Trick, Maniac)投射到图中的各个步调(step)上。
为了能够将其与另一行音乐的不同模式和难度区别开来,我又一次想到11月份曾使用过的音乐表格/线段方法(你可能必须点击并放大图片,才能看到其中的线条,它们实在是太细小了):

但是,接下来我陷入了困境。是的,有了这些线段,我现在可以把一行的模式/难度层级与另一行区别开来。但是这并没有给我带来什么好处,这些步调太过分散,我无法在一个屏幕上看到整首歌曲,并判断其中是否存在什么令人感兴趣的规律。此外,我也无法推断,该界面的其他部分要如何接入,以便人们浏览、选择歌曲,从而了解该歌曲。
第三、四周|代码
就在我陷入困境时,带着仅有的两个针对界面设计的目标,我进入了梦乡:一是要让每一首歌曲都变得紧凑,二是要让视觉化模拟的歌曲能够连续播放。当我第二天醒来时,脑海中出现了螺旋线,而且我确信,这就是我的问题的答案。螺旋线就象一个个圆圈,非常紧凑,同时也是一个非常基本的连续线条,能够把各个步法投射上去,连续播放出来。
于是,我迅速地查找螺旋图案背后的数学原理,并非常开心地发现,阿基米德螺线(Archimedean spiral,螺旋线的一种,其中各个螺旋线之间的距离相等)的半径就是它的螺线角。

螺旋线
对于最简单的螺旋线--阿基米德螺线来说,螺旋线半径r(t)和螺旋角t成正比,因而等式可以表达为:
(3)极坐标表达式:R(t) = at (a是常数)
由此可以得到:
(2)参数形式:x(t) = at cos(t), y(t) = at sin(t),
(1)中心等式:x2 + y2 = a2 [arc tan(y/x)]2
直到我认识到……如果我使用这一公式,我可能会得到如下图的结果:

相反,我想让这些点(节拍)在沿着螺旋线行进,并保持相同间距,我认识到,问题并没有我想象那么简单:

如果阿基米德螺线的极坐标表达式给定如下:
ρ=θ
那么,其参数等式则为(θcosθ,θsinθ),且在0和θf之间的弧长为:
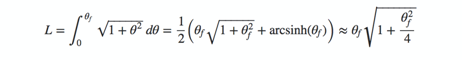
进而,在类似阿基米德螺线这样的螺旋线上等距离放置光点,其较好办法是取第N个点,使其满足:
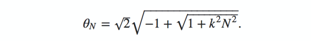
(问答网络平台Stack Exchange:该公式可以将光点放置在阿基米德螺线上,并保持其间距为相等的弧长)
认识到这一点后,我如遭雷击,因为我已经近十年没有接触积分了。我用了一个小时在我的笔记本上草草演算,试图解出公式中的各个步骤,以便能够弄明白如何推导出最后的公式。可惜我没那么幸运。
1.就在这时,两个奇迹出现了:我把当前面临的困境发布到Twitter上,结果Andrew Knauft 来帮助我,给出了他自己所作出的详细推导。
2.我在一个酒吧等人时,一个人坐在了我对面的空位上。于是我趁机问他数学水平如何,然后,在我们通过电子邮件沟通了几次之后,他(Issac Kelly)给出了使用暴力算法(brute-forced )的解答。
因为我这个月已经落后太多太多,完全没有任何时间,所以我直接拿Issac的暴力算法,用于DDR步调的编程:

(上图为改写过的螺旋线编码)
随后,我为每一首歌曲都加了图例和过滤器(filter)(最早我把图例放在最上方的图片顶部,并作为过滤器用于所有歌曲,但是,我发现这样做完全没有任何效果,因而转为分别为每一首歌曲配备过滤器):
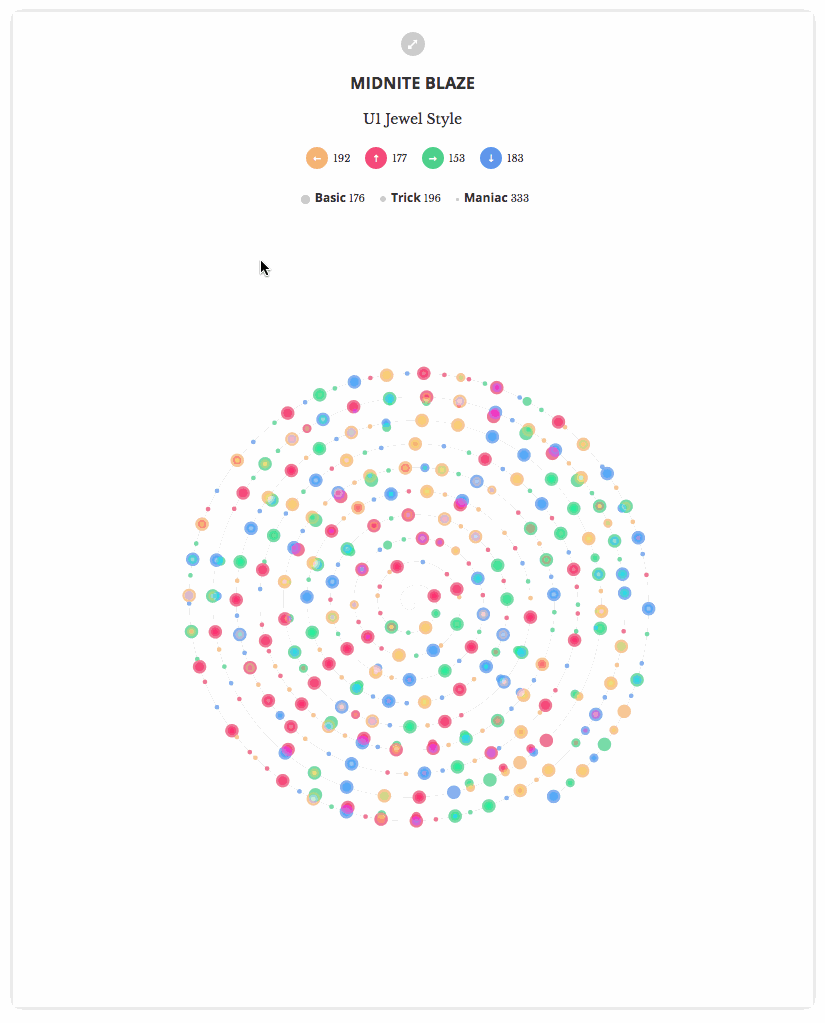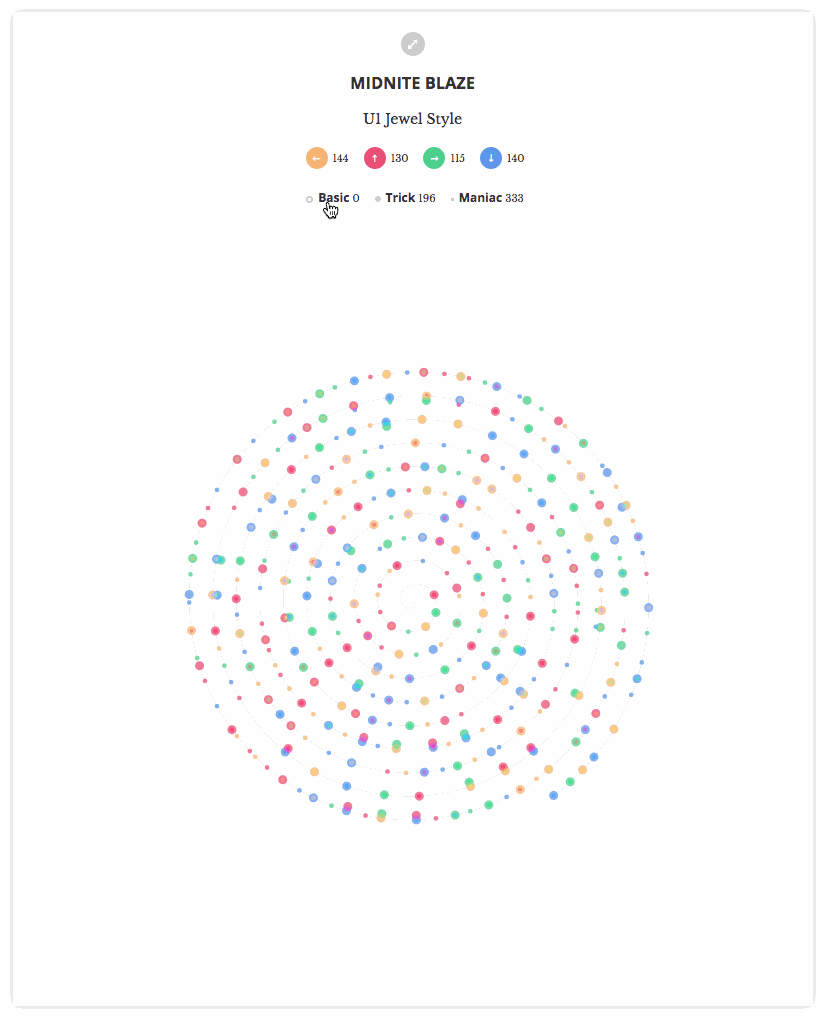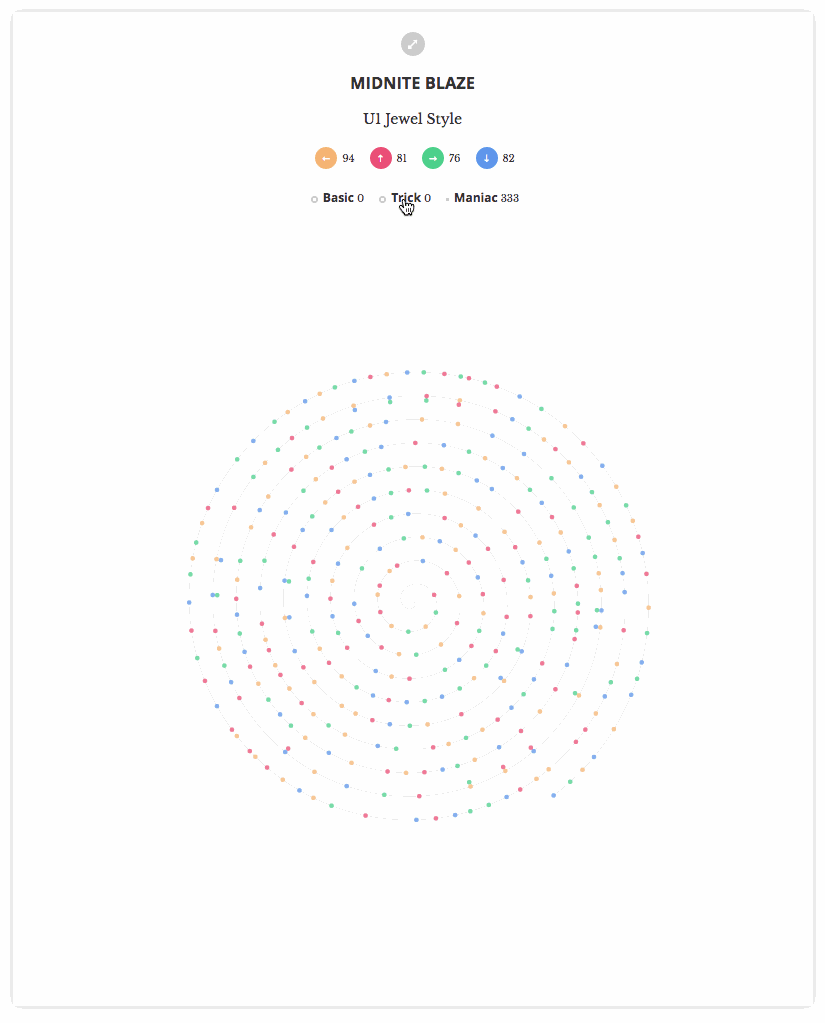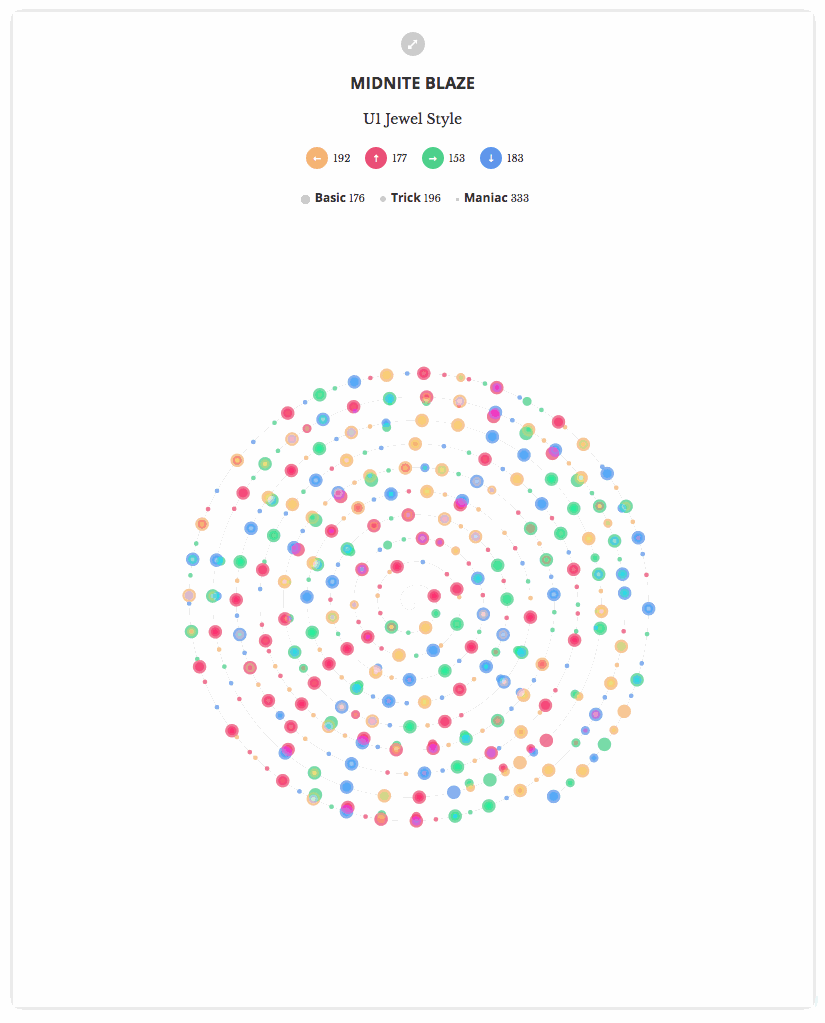
以下是最终结果:
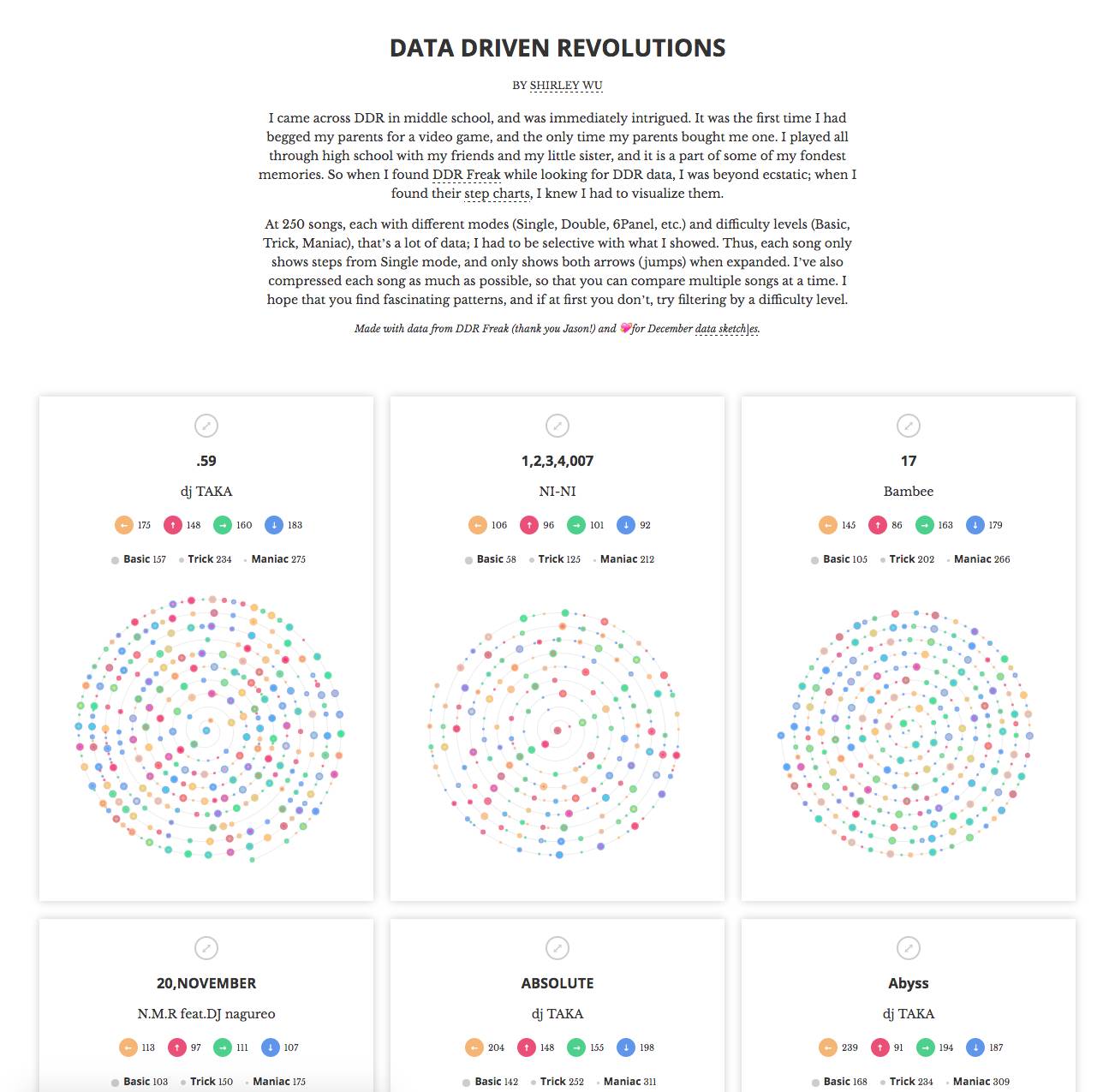
总的来说,考虑到起步较晚的情况,我对最终结果还是比较满意的。现在,利用螺旋线,我能够对多首歌曲进行对比,(经过可视化之后)大的螺旋线(较长的歌曲)和细微的螺旋线都变得显而易见。还能一眼看出,对有些我以前喜欢的歌曲来说,整首曲子确实有许多地方步调非常紧凑,仅仅有少数几处中断,难怪一听这些歌曲我就喘不上来气!
说了这么多,我还不是100%满意。由于我要做得紧凑一些,所以牺牲了对歌曲内部规律的关注。而DDR最有趣的地方之一是,一首歌里会有一些成套步法反复出现,但目前这个可视化模型是很难找到这样的步法的。即便给我足够多的时间,我也无法确定自己能否找到既可以展现歌曲间的规律又可以看到歌曲内部规律的可视化模型来。
无论是满足于现在的结果或者未来更进一步,在这个月里,我最开心的并非是这些处理流程以及最终的结果,而是热心的陌生人们对我(近乎)完美的帮助,这表明,确实有些人真的超赞啊!
作品地址:http://www.datasketch.es/december/code/nadieh/
关注大数据文摘,公众号后台回复“隔壁老王”,下载设计师老王从隔壁偷来的高清大图!
课程推荐
使用keras快速构造深度学习模型实战
微软&谷歌数据科学家,带你每周案例实战
史上最高性价比!
两位顶尖的微软/谷歌数据科学家,直播互动分享珍贵学习经验,并详细讲解前沿实战案例!GPU云实验平台提供便捷的操作环境。还有原著大作免费送!
七周时间,带你玩转Keras!
很多即将毕业和渴望转型的小伙伴都加入了我们,你不来吗?

志愿者介绍
回复“志愿者”加入我们




往期精彩文章
点击图片阅读








