数据处理遇到麻烦不要慌,5个优雅的Numpy函数助你走出困境
参与:加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:机器之心@微信公众号 作者:Baijayanta Roy 参与:Luo Sainan、杜伟
【导读】在机器学习和数据科学工程的日常数据处理中,我们会遇到一些特殊的情况,需要用样板代码来解决这些问题。在此期间,根据社区的需求和使用,一些样板代码已经被转换成核心语言或包本身提供的基本功能。本文作者将分享 5 个优雅的 Python Numpy 函数,有助于高效、简洁的数据处理。

在 reshape 函数中使用参数-1
Numpy 允许我们根据给定的新形状重塑矩阵,新形状应该和原形状兼容。有意思的是,我们可以将新形状中的一个参数赋值为-1。这仅仅表明它是一个未知的维度,我们希望 Numpy 来算出这个未知的维度应该是多少:Numpy 将通过查看数组的长度和剩余维度来确保它满足上述标准。让我们来看以下例子:
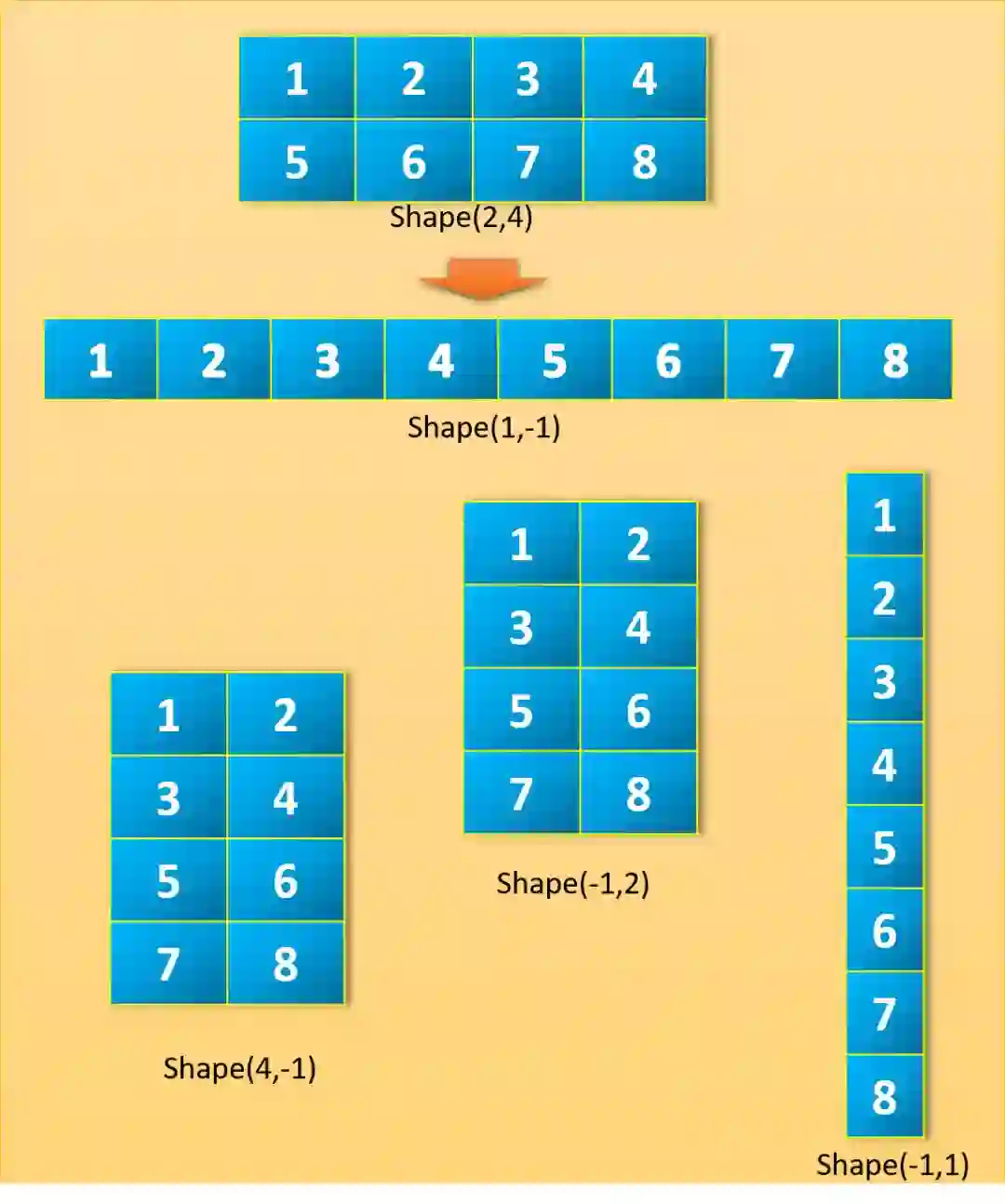
a = np.array([[1, 2, 3, 4],
[5, 6, 7, 8]])
a.shape
(2, 4)
a.reshape(1,-1)
array([[1, 2, 3, 4, 5, 6, 7, 8]])
a.reshape(-1,1)
array([[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8]])
a.reshape(-1,4)
array([[1, 2, 3, 4],
[5, 6, 7, 8]])a.reshape(-1,2)
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])a.reshape(2,-1)
array([[1, 2, 3, 4],
[5, 6, 7, 8]])a.reshape(4,-1)
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
a.reshape(2,2,-1)
array([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])a.reshape(2,-1,1)
array([[[1],
[2],
[3],
[4]],
[[5],
[6],
[7],
[8]]])
a.reshape(-1,-1)
ValueError: can only specify one unknown dimensiona.reshape(3,-1)
ValueError: cannot reshape array of size 8 into shape (3,newaxis)
Argpartition:在数组中找到最大的 N 个元素
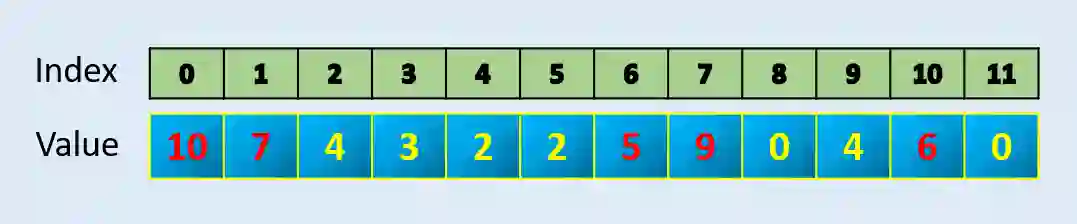
array = np.array([10, 7, 4, 3, 2, 2, 5, 9, 0, 4, 6, 0])index = np.argpartition*(array, -5)[-5:]
index
array([ 6, 1, 10, 7, 0], dtype=int64)np.sort(array[index])
array([ 5, 6, 7, 9, 10])
Clip:如何使数组中的值保持在一定区间内
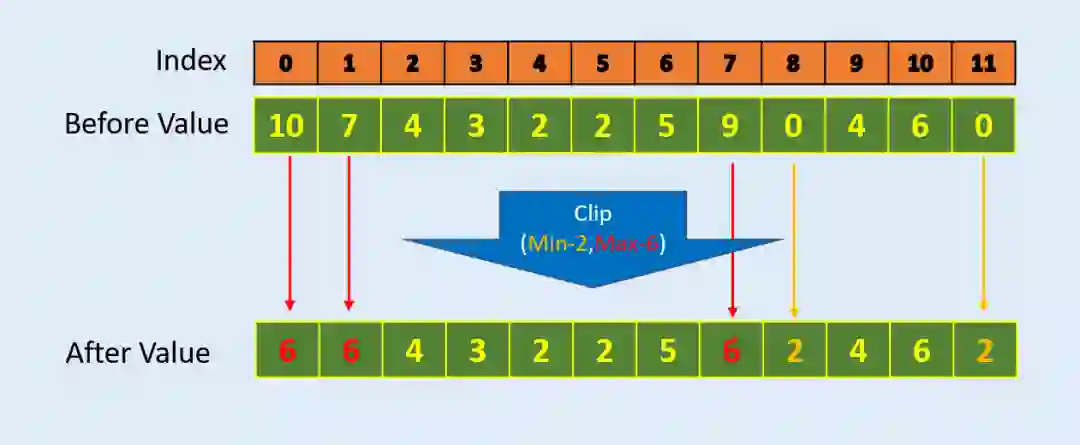
#Example-1
array = np.array([10, 7, 4, 3, 2, 2, 5, 9, 0, 4, 6, 0])
print (np.clip(array,2,6))[6 6 4 3 2 2 5 6 2 4 6 2]#Example-2
array = np.array([10, -1, 4, -3, 2, 2, 5, 9, 0, 4, 6, 0])
print (np.clip(array,2,5))[5 2 4 2 2 2 5 5 2 4 5 2]
Extract:从数组中提取符合条件的元素
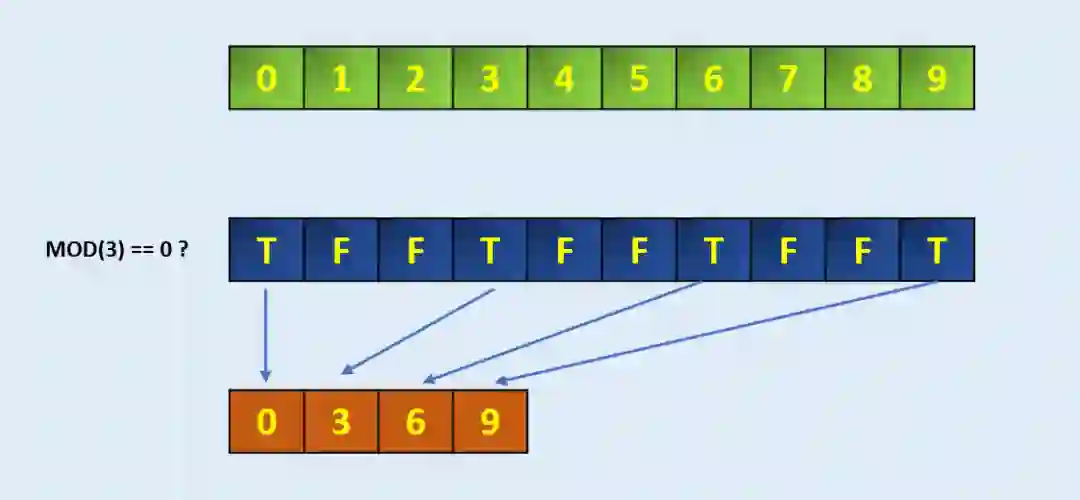
arr = np.arange(10)
arrarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])# Define the codition, here we take MOD 3 if zero
condition = np.mod(arr, 3)==0
conditionarray([ True, False, False, True, False, False, True, False, False,True])np.extract(condition, arr)
array([0, 3, 6, 9])
np.extract(((arr > 2) & (arr < 8)), arr)array([3, 4, 5, 6, 7])
setdiff1d:如何找到仅在 A 数组中有而 B 数组没有的元素
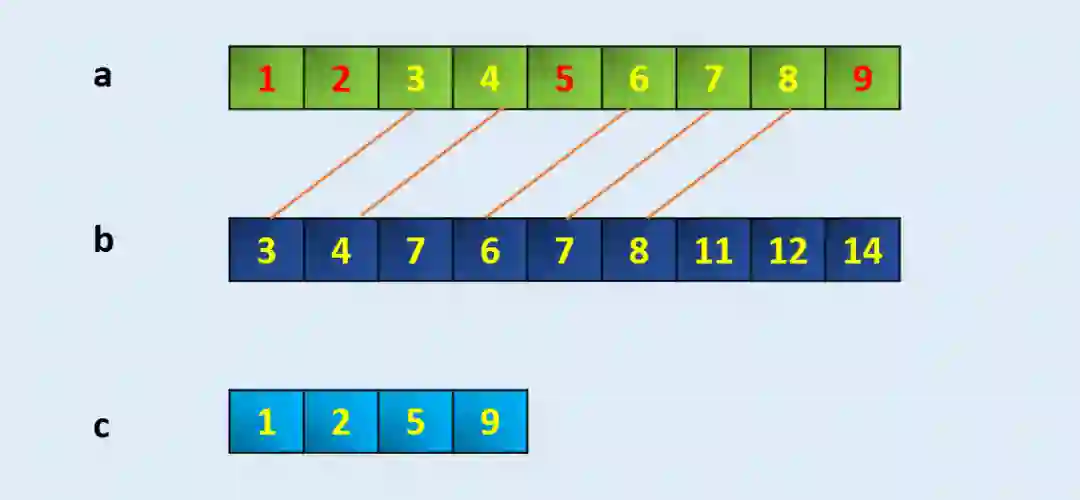
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
b = np.array([3,4,7,6,7,8,11,12,14])
c = np.setdiff1d(a,b)
carray([1, 2, 5, 9])
小结
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、OCR、姿态估计等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文