7K字面经 | 百度金融、蚂蚁金服、易贷网、金蛋科技等互联网金融公司面试经验

文末有彩蛋 错过后悔一年
“金九银十”似乎成为了一年一度的通用语。每年的九十月份,也是用人单位大量吸纳人才的关键时期,此时,正是刚步入社会的毕业生和想要跳槽换一份更加理想的工作的人们的最佳求职期。
招聘季刚刚过去,小伙伴们都找到了心仪的工作吗?
最近看到一篇很火的面经,和大家分享一哈,在网上搜罗到,果断get起来,绝对是满满的干货。面经作者:于同学,一篇关于易贷网、金蛋科技、百度金融、蚂蚁金服等互联网金融公司的面试经验。
内容非常不错,写的超详细,值得大家一看,特别是对找金融方面的,很有帮助的喔
话不多说,面经开始~
首先,简历是你能被邀请去一个公司进行面试的敲门砖,一般技术岗的简历要突出特色与重点,忌讳繁杂与花哨,一般可以将简历分为基本信息、个人技能、工作经历、项目经验四个大的方面,这四项也是面试官最感兴趣的。
然后再对大项进行详细的划分,例如:个人技能和项目经验这两个肯定就能再分出来很多小项,小项在写的时候也要有完整的结构和严密的逻辑。一方面是让面试官在你的技能与经验迅速找到兴趣点,另一方面是让自己对自己有一个清晰的认识,这样面试的时候讲起来才能更有条理。
其次,就说一说我面试的部分公司和面试中经常遇到的问题。问到的问题我会清晰的列出来,问题的回答方式和我的答案也会写在下面,括号内的可能只说出相关知识点,部分详细的答案还需要各位看官自行去百度。
1
公司:金蛋科技,岗位:数据挖掘工程师
行业方向:互联网金融
一面技术:
(1) 介绍一下自己的逾期还款率项目
主要讲这个项目在什么场景下(P2P借贷平台)应用什么技术手段(数据处理,特征工程,LR、RF、GBDT训练,做Ensemble,调参)解决什么问题(对客户是否会逾期还款的预测,最后AUC达到了一个点:一般说70%-80%,太低没多大用,太高有点假或者有过拟合的可能性,有明显的好坏用户的分辨能力)
(2) 主要做了什么工作
这块肯定要挑自己擅长的说,因为接下来面试官会根据你说的擅长的部分进一步进行提问与了解,因为面试的是数据挖掘的岗位,所以我主要讲的是特征工程(数据处理,特征选择:Filter、Wrapper、Enbedded、特征衍生),捎带着说了一点模型训练的事情
(3) 常用数据从哪里来,大数据处理的方法和技术用过哪些
其实对于一个互金公司的数据来源无非是两个方面,一个是自己业务中积累下来的,还有就是从外界买来的,但是这个问题如果只回答是自己公司的,有些面试官又会觉得不可思议,因为自己公司的数据不可能是全面的,而互金行业对数据量要求又大,所以不要入了面试官的坑。大数据处理方法就回答spark和map-reduce,着重还是说map-reduce。
(4) 有一个1T大小的每行只有一个词汇的文本,怎么统计词的个数
这个问题其实就是考察大数据处理中map-reduce的原理了,原理很简单就是‘分——合’的思想,就是对HDFS上的资源进行分片,map阶段将数据分成key-value对,然后在reduce阶段再对key对应的value进行计数。这样就统计出了词的个数。
结果:技术面顺利通过,二面CRO,问我对互金的看法和风险化解等等业务上的问题,由于是第一场面试,对互金方面不算太了解,所以直接折在了二面。
2
公司:灵犀联云,岗位:算法工程师
行业方向:数据服务
一面算法:
(1) 编写二分查找算法
思想就是从中间查找,比较大小后再找左或右半边,这个百度一下,各个语言版本都有,这个问题需要能够手写出来的,回去背吧
(2) 二分查找的时间复杂度(O(logn),最坏O(n)),时间复杂度,空间复杂度怎么计算的
其实这个就是看你代码执行的时间和占用空间,简单方法就是把常见的算法的时间复杂度和空间复杂度记下来,如果实在记不住就百度一下计算的过程
(3) 简单问了一下工作经历和所作的工作
(这跟第一个面试问的一样,然后就从头到尾的介绍一遍)
(4) 在工作中用到了哪些算法,简单介绍
这个肯定挑自己掌握度高的和简历中写的介绍,例如LR,RF,SVM,然后说原理和推导过程。
二面技术:
(1) 分类和聚类的区别
从样本数据、模型、方法:分类(LR,DT…),聚类(K-Means,K-Means++),、产生的结果等方面阐述区别
(2) 特征是怎么进行选择的或者说怎么知道选出来的就是最好的
这个问题上面已经提过三种方法:Filter、Wrapper、Enbedded,主要从划分的属性上会像决策树生成过程中计算信息增益、增益率、Gini一样评价一个属性的评分
(3) L1正则化和L2正则化的区别
这个问题主要从公式,正则化形成过程,功能等方面进行回答,附一个我觉得讲的比较好的正则化的博客
https://blog.csdn.net/yuyang_1992/article/details/83685483
(4) 手推SVM
常用的机器学习算法大家最好还是可以手推出来的,因为有的面试官真的让你手推啊,手推之后回答了一下软间隔与硬间隔,核函数有哪些,区别,拉格朗日乘子法(西瓜书SVM那一章安排的明明白白)
三面人事:
这个人事就很牛的样子,完全不是公平性谈判,打压你的信心,说什么他们那都是清华北大的毕业的,我不是名校出身,处于技术初级算法工程师阶段,希不希望有一个好的平台什么的,反正就是各种忽悠,然后压榨工资。这种情况也慢慢跟他聊,拿到offer是关键,只不过把它当备胎。
结果:最后谈到了16k/月*14个月,第二天发offer。
3
公司:易贷网,岗位:算法工程师
行业方向:互联网金融
一面技术:
(1)介绍自己的项目和主要工作
基本上是面试时的第一项,后面这一项就不写了
(2)bagging和boosting的区别
这个具体化其实就是RF和GBDT的区别:
a.样本选择方式;
b.样例权重;
c.预测函数;
d.并行计算
(3)语料库怎么构建词向量
这个问题就是骗自然语言处理方向的问题了,因为这是我在第一次写简历的一个败笔,写了一个自然语言处理的项目。但是也是硬着头皮说用到了word2vect进行构建词向量的…
(4)TF-IDF的计算方法,含义,应用场景
含义:词频-逆向文件频率,是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
计算方式:TF 词在文件中出现频率;IDF:总文件数目除以包含该词语之文件的数目
应用场景:其实就是自然语言处理中看一个词的重要性,然后对于文本分类这样的项目能够起到作用。
(5)word2vect的原理,两种模型形式,霍夫曼树?
word2vect其实就是一个输入层,隐藏层和输出层这样的三层神经网络结构,一般分为CBOW和Skip-Gram两种形式,霍夫曼树是在训练CBOW和Skip-Gram优化的数据结构。
上面这三个问题具体还包含很多小点,由于我不是主要面深度学习的,所以就不加以赘述了,大家可以上网查一下,附一个博客链接,一目了然:
https://blog.csdn.net/yuyang_1992/article/details/83685421
二面直接上老大:
问我有没有自然语言处理的实际落地项目,他们现在急招的是自然语言处理的岗位,算法工程师不急。听到这很忧伤,自然语言处理我没做重点复习啊,只能硬着说做过一个短文本分类小项目,然后做下介绍,闲扯了10分钟,感觉已经没戏了,所以有想面自然语言处理方向的同学一定要好好复习。
4
公司:永辉云创,岗位:机器学习算法工程师
行业方向:机器学习
一面技术:
(1)写一个快排,说一下快排主要快在哪?
这个可以百度一下,原理,计算方法,代码应用尽有,主要快在它的思想是分而治之的思想,其实东西都是这个思想,例如分布式、hadoop等
推荐一个关于快排的博客:
https://blog.csdn.net/pythondafahao/article/details/80084385
(2)手推SVM,什么是核函数,为什么要用核函数,SVM核函数怎么选择?
手推公式我这里就不写了,认准切入点是我们要找到一条直线正好把正负样本分割在两端,而且让它们离直线越远越好,之后进行了一系列的计算。
核函数是为了解决样本不是线性可分的问题提出来的,主要的核函数有线性核,高斯核,Sigmoid核,核函数选择主要从训练集样本量,特征量上进行考虑。总之SVM的东西还是很多的,推导过程中还有拉格朗日乘子法、SMO算法、软间隔、硬间隔等问题。
(3) SVM和LR的异同点?
这个我整理了一篇博客,直接上链接:
https://blog.csdn.net/yuyang_1992/article/details/83686204
(4)连续值特征做离散化有什么好处?
同样这个问题博客见:
https://blog.csdn.net/yuyang_1992/article/details/83686284
(5)特征工程中对时序型特征怎么处理
时序特征其实是在预测上常用的一个特征,简单的来说我们可以根据特征中的时间特性来划分不同的时间区段(比如,现在马上到双十一了,在时间特征上我们可以剥离出双11,双12,周末,工作日等),这样会让特征有时序型(其实就是特征工程中对时间类别特征的处理),另外还有成熟的时序特诊处理方法(这个需要自行去搜一下paper),paper较长,这里就不赘述了。
(6)推荐系统的算法了解多少?简单介绍一下协同过滤,怎么计算商品之间的相似度?
其实我了解的真不多,所以我就简单说知道协同过滤(基于物品和基于用户),其实就是一个人以类聚,物以群分的过程,然后说一下距离计算的方法:欧氏距离、Jaccard相似度、Pearson相似度、余弦相似度,最终形成一个打分的矩阵,然后根据得分进行推荐。
(7)讲一下隐语义模型
思想是通过隐含特联系用户兴趣和物品,找出潜在的主题和分类,基于用户的行为对item进行自动聚类划分到不同类别/主题。知道这不是自己的强项,就跟面试官说只是了解,没有实际用过,但是我会回去好好研究研究,衣服信誓旦旦的样子。
(8)说说hadoop的原理
这又是大数据了,上面已经提到过了,大数据这块的东西大家还是好好看一下,因为现在搞算法,搞机器学习、深度学习都是在大数据的背景下的,所以这以后是一个基本的技能,面试官问的也比较多。
(9)简历中的销售量预测的项目的评价指标召回率和ACC怎么协调
这个问题就看实际业务场景是更偏重于哪一方面了,我的回答(不一定对)是我们是先以准确率为准进行模型调优,达到我们可接受的数值时,然后往上调召回率,最终使两个指标都稳定。
二面人事:人事没问什么特殊的问题,基本都是一个讨论,然后问一下工资,告知准备入职手续和材料。
结果:永辉云创是永辉超市注资成立的,初创阶段,业务方向也是依托于用户超市数据搞大数据处理和探索人工智能其它方面。顺利拿到offer,20K/月
5
公司:百度金融,岗位:算法工程师
行业方向:互联网金融
(1)简单介绍自己,主要负责哪部分工作?
这个就不说了,大家对这自己的简历都练几遍。尽量多说一点,这样面试官就少问一点。
(2)项目中用到的数据的量有多少?特征有多少维,都用作训练吗?
这个问题是很多面试官都喜欢问的,要根据自己写的项目实际情况进行阐述,数据量较大的情况一般是不能全部用作训练的,要不然那模型得跑多长时间啊,还有就是特征维度,一般几十到几千维都有,用作训练的其实也就几十维到百维这样,特征工程那块肯定要看一下哪些特征是有用的,进行特征选择,如果全用会给训练带来大量的工作反而起到副作用。
(3)对大数据了解多少?hadoop的原理?
大数据处理其实上面已经提到过,用到的工具有spark、hadoop,然后hadoop的原理就是分而治之,map-reduce都干什么,建议写两个这样的程序你就能明白它是怎么工作的,这个很主要,因为工作中就是这么用的。
(4)特征怎么进行组合的,对模型训练有什么指导意义?
特征组合一般都是拿差异性、关联性较大的特征进行组合,这样不会损失特征的作用,还可以拓展出未知的特征,例如将 longitude 与 latitude 组合,产生的组合特征则代表一个明确的城市街区。这样能产生比单独考虑单个特征更强烈的位置信息的信号,所以特征组合就是在衍生我们不能直接接触的特征,然后对模型训练有积极影响。
(5)在模型训练过程中都用了什么算法?
LR,RF,GBDT...,然后一一解释每个算法的特色、原理、中间再加点比较(因为都是分类算法)
(6)混淆矩阵,ROC、AUC、召回率、KS、Gini、IV
混淆矩阵:
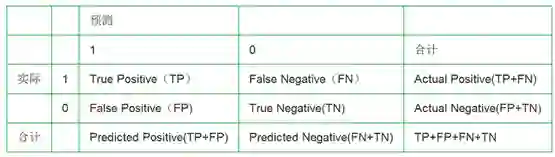
这个是后面计算ROC,AUC,召回率,准确率的基础,所以还是要把这个表格记住:
TP:正确肯定——实际是正例,识别为正例
FN:错误否定(漏报)——实际是正例,却识别成了负例
FP:错误肯定(误报)——实际是负例,却识别成了正例
TN:正确否定——实际是负例,识别为负例
• AccuracyRate(准确率): (TP+TN)/(TP+TN+FN+FP)
• ErrorRate(误分率): (FN+FP)/(TP+TN+FN+FP)
• Recall(召回率,查全率,击中概率): TP/(TP+FN), 在所有GroundTruth为正样本中有多少被识别为正样本了;
• Precision(查准率):TP/(TP+FP),在所有识别成正样本中有多少是真正的正样本;
• TPR(TruePositive Rate): TP/(TP+FN),实际就是Recall
• FAR(FalseAcceptance Rate)或FPR(False Positive Rate):FP/(FP+TN), 错误接收率,误报率,在所有负样本中有多少被识别为正样本了;
• FRR(FalseRejection Rate): FN/(TP+FN),错误拒绝率,拒真率,在所有GroundTruth为正样本中有多少被识别为负样本了,它等于1-Recall
ROC曲线就是以假阳性概率(False positive rate)为横轴,真阳性(True positive rate)为纵轴所组成的坐标图
上面大家可能学习过程中都能接触到,但是KS、Gini、IV是互金行业风控模型中常用的指标,一被问到我就懵逼了,完全不知道是啥啊,只能支支吾吾说没用过这些指标。
这几个指标内容也比较多,在这附一个讲的比较好的博客地址:
https://blog.csdn.net/htbeker/article/details/79697557
结果:可能大公司要求就是严格,亦或是一个问题就能看出来你在这个行业待了多长时间,所以:一面,卒。
6
公司:某金融集团,岗位:算法工程师
行业方向:互联网金融
一面技术:
(1)简单介绍一下自己
千篇一律,当练口才了。
(2)手写快速排序算法,讲原理,最好、最坏时间复杂度,空间复杂度
这个上面也提到了,主要看对算法的理解程度,所以面试中可以不去看那些数据结构,但是常用的算法一定要能默写出来,而且知道为什么快。
(3)简历中写的申请评分卡是怎么做的?
基于Logistic回归的申请评分卡模型开发(主要讲了流程):
①数据准备:收集并整合在库客户的数据,定义目标变量,排除特定样本。
②探索性数据分析:评估每个变量的值分布情况,处理异常值和缺失值。
③数据预处理:变量筛选,变量分箱,WOE转换、样本抽样。
④模型开发:逻辑回归拟合模型。
⑤模型评估:常见几种评估方法,ROC、KS等。
⑥生成评分卡
(4)做一个风控模型一般流程是什么样的
其实这个问题就是把上面的问题又说了一遍,但是我回来在网上查了一下大概是这个样子的:业务定义(确定义务才能确定其他的)->风险定义(其实就是定义好用户和坏用户,或者说是正负样本)->风险化解(这块就是用算法训练各种评分卡)->风险策略(针对作弊行为或坏账进行的后期行为)
(5)手推LR,并对每一步进行解释:引入sigmoid,逻辑回归的公式,极大似然,求解参数时的梯度下降算法
这个没什么可讲的,就是去手推吧,推几遍这些都记住了,包括哪一步该干什么。
(6)LR和SVM有什么异同点,怎么理解SVM的核函数
异同点和核函数都在上面说过了,这块回顾一下吧(其实整个这个面经看下来可以看出来,面试官们常问的问题也就这些,只是会从它们的业务中带出问题来)。
(7)项目中样本量是多少?正负样本比例如何?怎么解决正负样本不均衡的问题?
样本量自己说了几十万,正负样本10:1(肯定有人问,为什么说10:1,因为在互金行业的正负样本比是十分不平衡的,每有一个负样本就说明至少出现一笔坏账,在几百万数据的情况下,有1W坏账这个公司就别活了,当然我说这个比例也不是很准确的,但是我解释取样本的时候做了采样)。样本不均衡解决方法:负例采样,smote算法。然后讲了smote算法怎么做。
(8)特征工程做了哪些工作?为什么?
这个当时就把自己实际用的特征工程方法说了:对null值、异常值文本型、时间型、类别型,组合,统计缺失率等通通说了一遍,然后进行特征选择。这么做当然是为了模型能快速训练出效果,使数据收敛,提升评估指标等等啊,这么做肯定说产生好的影响。
(9) 项目中使用模型训练的评估指标是什么?AUC多少?KS值多少,KS值是怎么计算的
吃了百度金融的亏,这回我可答上来了,上面那个连接里面的每个概念、计算方法我都扣了好几遍。AUC:0.73(不能太高也不能太低,有零有整,很真实),KS:0.28(一般>0.2便说明模型有很好的区分能力)
这个问题其实也是一个不小的坑,因为你说的太假一下子就能看出来,面试官都是在实际工作中摸爬滚打出来的,你说AUC0.9那他得仰视你。
二面技术+业务:
(1)在工作中都会用哪些特征来进行模型的训练,哪些数据比较有效
这个主要是跟用户个人和信用方面息息相关的:例如个人基本信息(年龄、地址、学历、工作...)、设备属性(手机品牌啊,运营商...)、业务行为(借贷行为,还款,消费,旅游....),有效的肯定是跟业务关联多的。因为从这些特征中可以直观的判断这个人的借款需求和还款能力。
(2)对风控模型的理解,完成一个风控系统都需要做哪些工作
①尽可能全面搜集客户信息
②根据业务进行模型训练,然后对用户进行评分,完成授信
③后期监控,防止产生坏账和作弊行为
(3)给一个场景:有50W贷中数据和50W贷后数据,特征维度有300维,其中还包含了空值,怎么用这些数据做一个申请评分卡?
讲思想:用贷后数据进行数据分析,做数据处理(空值、异常值)、特征工程,然后计算特征的IV值和特征选择方法筛选特征,再把处理完的特征放到LR中进行训练(训练集,验证集按照7:3划分),对模型调优,达到一定指标。贷中数据也别闲着,放到模型里进行预测,放到库中,待时间线临近来验证模型实际应用中的效果。吧啦吧啦,说的口干舌燥,
(4)之前做的项目风险是怎么定义的?
这个不同公司有不同的定义,银行可能定义M1期以后是坏用户,而P2P比较脆弱,承担风险能力弱,所以M0期可能就定义为坏用户。
(5)有哪些手段防止用户的反欺诈行为?
这个问题回答的时候尽量从业务的场景去分析,第一,尽可能全面的收集用户的资料,用户资料越全后期用户的行为越可控;第二,授信前要有严格的授信策略(例如申请评分、贷中行为评分、贷后行为评分);第三,后对贷后用户进行监控和跟踪,采取电话回访或者其他方式确定用户真实存在。第四,就是不断完善自己的风控系统。
(6)给我找了一批数据,然后发给我,让我回去用这些数据训练一个预测好坏用户的模型。
这个就是实际动手操作了,并不难,回来对数据进行简单的处理,做点特征工程,然后用LR和RF分别训练了一个模型,然后做一下比较,用AUC和ACC评估指标说一下效果等等。
三面人事:
人事这关就是问你为什么辞职啊,上家公司待遇啊,对自己的定位啊,对整个行业的了解啊什么的,跟人事聊天就是让她感觉你很积极向上,离职原因不要贬低自己原来的公司,可以说自己想拓展一些技能啊,进行更多的挑战啊什么的。
人事问还有什么问题的时候也尽量问一些关于公司的文化啊,人才培养啊,进阶过程什么的,不要上来就问工资,这个问题等人事主动问你比较好。
结果:拿到offer,顺利入职
总结:BB这么多,都是我一家公司一家公司面过来的,还有几家公司跟我想从事的方向不一致,问题也都跟这些差不多就没多赘述,问题都是真实记录的,所以有要找互联网金融方面工作的朋友可以参考参考,有些问题我说的不对的也希望指正(改不改看我心情),我也学习学习。
以上的几家公司面经,是我在报名参加了七月在线的机器学习集训营完成了3个多月的课程之后,便向这个神秘而又充满诱惑力的职业发起挑战的,现在年薪40万~
七月在线是国内领先的人工智能教育平台,现推出了【深度学习集训营第二期】,只需努力5周,挑战年薪40万,甚至更高薪资~


课程大纲
预习阶段 从DL基础起步,掌握三大核心模型
在线视频:DNN与CNN,及NN框架
1-DNN与混合网络:google Wide&Deep
2-实战项目:数据非线性切分+google wide&deep 模型实现分类
3-CNN:从AlexNet到ResNet
4-实战项目:搭建CNN完成图像分类示例
5-NN框架:caffe, tensorflow与pytorch
6-实战项目:用几大框架完成DNN与CNN网络搭建与分类
在线视频 :RNN、LSTM、与条件生成、attention
1-RNN/LSTM/Grid LSTM
2-实战项目:RNN文本分类
3-RNN条件生成与attention
4-实战项目:google神经网络翻译系统
第一阶段 从数据科学比赛里看深度学习应用
在线直播:业务场景下机器学习/深度学习数据处理与特征工程
1-业务场景下的特征处理与挖掘套路
2-如何用tensorflow进行常见的数据特征工程
3-tensorflow搭建baseline模型解决分类问题
在线直播:tensorflow搭建混合网络
1-wide network搭建与优缺点
2-deep neural Network搭建与优缺点
3-混合网络搭建套路
4-用混合网络解决分类问题
线下实战:从DNN/Wide/Wide&Deep解决房价预测问题
1-机器学习vs深度学习,工业界的利弊权衡
2-神经网络基本原理和训练要点
3-如何针对不同的应用场景选择模型结构
4-从wide&deep到混合网络的搭建与应用
5-以kaggle比赛为例讲解神经网络解决方案
第二阶段 深度学习在计算机视觉中的应用
在线直播:深度卷积神经网络原理与实践
1-卷积操作的数学定义和物理意义
2-卷积神经网络结构的两大原理—局部连接和权值共享
3-卷积神经网络的主体结构和变种
4-3小时内用百行代码登顶Kaggle图像分类比赛的Top-5%
在线直播:海量图像与tensorflow处理
1-Tensorflow输入数据——TFRecord与Dataset
2-Tensorflow图像预处理
3-Parameter Server原理
4-Tensorflow的分布式训练的实现
线下实战:图像分类与图像检索实战
1-灵活选取卷积神经网络结构作为图像分类的Backbone
2-迁移学习在深度学习中的应用——“微调”(Fine-tune)技术
3-图像搜索的前世(Bag-of-Visual-Words)和今生(Deep Learning)
第三阶段 深度学习在自然语言处理中的应用
在线直播:文本预处理,词袋模型,word2vec,语言模型
1-NLP基本知识:词袋、tf-idf、朴素贝叶斯
2-DL中的NLP基础:word2vec、doc2vec、embedding、N-gram LM
3-用深度学习一步步完成情感分析任务
在线直播:CNN/LSTM 文本分类
1-文本分类问题处理流程
2-传统模型在文本分类上的表现
3-从RNN到LSTM
4-CNN/LSTM 在文本分类上的应用
线下实战:文本语义相似度匹配模型以及Seq2Seq模型构建
1-深度学习在自然语言处理中的基础工具:word2vec、Embedding
2-文本检索与匹配通用模型方法:DSSM,CDSSM,DRMM,ARC-I
3-Seq2Seq模型搭建详解与应用案例
4-(短)文本语义相似度匹配模型构建及其实践应用
线下实战:图像生成文本(Image2text)
1-Image2text基本模型
2-基于Attention的Image2Text
3-反问题:Text2Image
第四阶段 高级深度学习应用场景
上午线下:基于深度学习的聊天机器人,看图说话与VQA
1-基于深度学习匹配的聊天机器人
2-基于序列到序列模型的聊天机器人
3-结合CNN与RNN的看图说话与VQA看图问答机器人
下午线下:大规模车辆图片搜索(Re-ID)算法原理及实践
1-多任务(Multi-task)深度学习模型搭建与训练
2-深度排序(Deep Ranking, Triplet Loss)原理与训练技巧
3-使用多任务和深度排序模型,构建一个工业界和学术界最前沿的大规模车辆图片搜索算法(可用于智慧城市、视频监控等安防场景),在业界最大的车辆搜索开源数据集上取得State-of-the-Art效果
第五阶段 深度学习模型优化及实践技巧
上午线下:NLP与CV数据科学比赛案例详解与实践
1-NLP AI比赛:文本主题与标签预测(通用模型结构、textCNN与textRNN、texRCNN与其他网络)
2-图像比赛基本套路
3-图像分类与图像分割比赛解决方案介绍
下午线下:深度学习模型优化前瞻技术 以及实践技巧
1-深度卷积神经网络的历史变革和设计理念——从AlexNet到DenseNet
2-解析各类轻量级深度网络的设计理念——深度可分离网络
3-深度学习模型训练时应注意的问题即实践技巧
另外购买本集训营课程另赠送三门辅助课程
1、报名免费赠送售价339元的《机器学习工程师 第八期》,8大讲师天团带你从机器学习中的数学基础、到基本模型、特征工程、工业实战、高阶知识、深度学习,六大阶段,层层深入、逐层递进,直通机器学习本质与其应用。
2、报名免费赠送售价339元的《深度学习 第三期》,三大顶级讲师带你入门和掌握DL的王牌课程,精讲CNN、RNN、LSTM和GAN,直播课提供国内首创的GPU云实验平台,更新增常见DL面试考点精讲
3、报名免费赠送售价119元的《TensorFlow框架案例实战》,四大顶级讲师带你从TF数据预处理到建模训练,从图像到文本,一覆盖;精讲GAN图像生成等最新案例,首个覆盖Tensorflow和Tensorflow.上层库(比如Keras)的课程
以上三门课程,将更好助力你学习深度学习集训营课程中需要的知识~

11.10-11.12 三天大回馈
火爆进行中
大奖直抽iPad、机械键盘
海量课程5折购
精品课程1元秒
爆款课程免费送
等等炒鸡福利等你来
(点击文末“阅读原文”,进入主会场)
同时,由于和本公众号合作推广,特地给该号的粉丝们送一份专属福利——当下火爆的【生成对抗网络班】,原价99元现在 0元免费送
除此之外,我们还为大家精心制作了一份价值399元的【深度学习大礼包】,内含:10G深度学习训练数据集、20+深度学习论文集合和kaggle挑战赛完整源码。
扫描下方海报二维码,关注公众号,回复数字:1111,即可免费

长按识别二维码
点击 “ 阅读原文 ”,进入主会场