深度学习及AR在移动端打车场景下的应用
点击蓝字订阅,不错过下一篇好文章
作为美团点评技术团队的传统节目,每年两次的Hackathon已经举办多年,产出很多富于创意的产品和专利,成为工程师文化的重要组成部分。本文就是2017年冬季Hackathon 4.0一个获奖项目的实践总结。
前言
前言
2017年在移动端直接应用AI算法成为一种主流方向。Apple也在WWDC 2017上重磅推出Core ML框架。准备Hackathon的过程中,我们就想能否基于Core ML的深度学习能力,结合AR,做酷一点的产品。我们观察到在晚上下班时间,是公司的打车高峰时段,这时候经常会有一堆车在黑暗中打着双闪,你很难通过辨认车牌去找到你叫的专车,所以我们把产品定向为一个打车时帮助用户找到车的App。
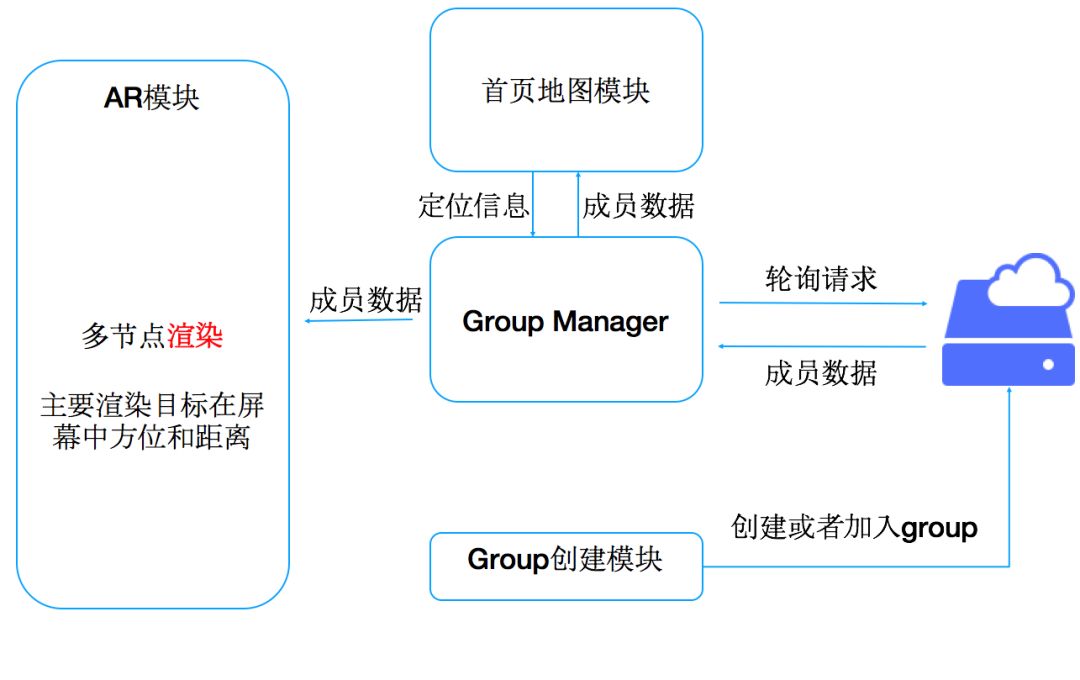
很快我们就把上面的想法落地实现了,开发了一个叫做WhereAreYou的简单App应用,相当于AR版本的微信共享位置,只要打开摄像头就可以看到小伙伴们的方位和远近。当然了,应用于打车场景下,就是让用户知道目标车辆从何驶来、距离多远。程序大概结构如图一所示:
远距离下使用AR帮助用户找到目标方位
远距离下使用AR帮助用户找到目标方位
我们用Node.js写了一个简单的服务,用户可以创建一个共享位置的group,其他用户拿到groupID后可以加入这个组,接着程序会通过服务来共享他们各自的GPS信息,同一个group内的成员可以在地图上看到其他成员的位置。值得一提的是,我们添加了一个AR模式,成员点击AR按钮后可以进入,此时摄像头会被打开,如果同一个组的其他小伙伴方位距离此用户很近,屏幕上就会出现一个3D模型,告诉用户附近有某某小伙伴,距离此地的远近等信息。主要过程和效果如图二所示:
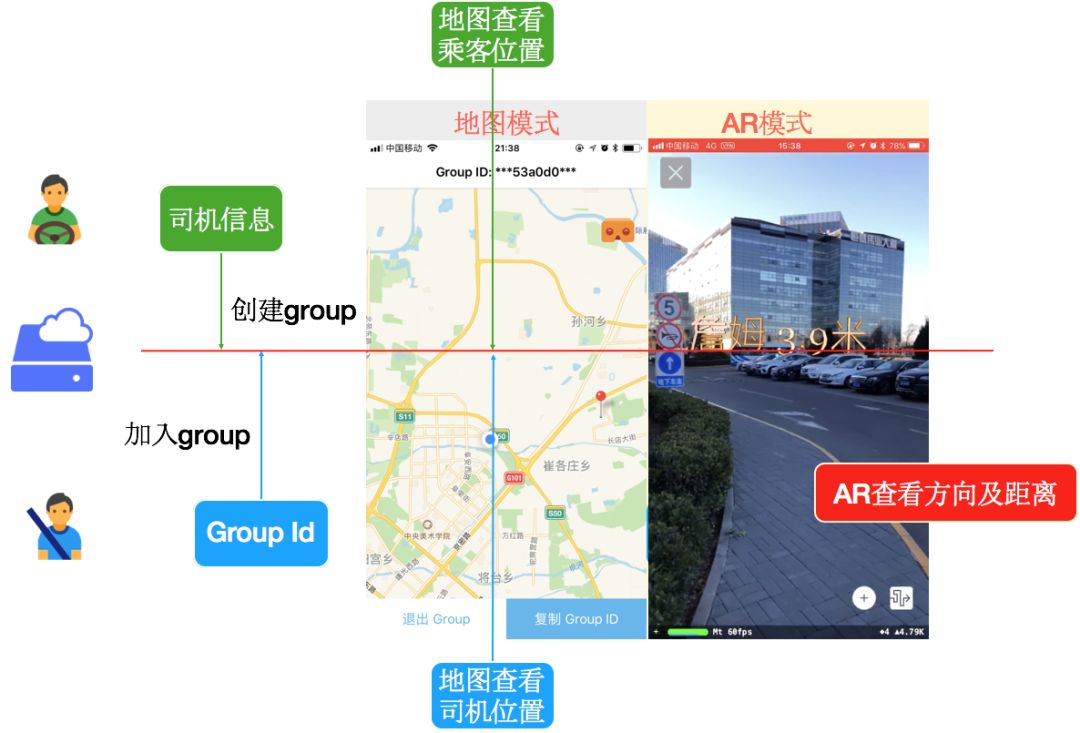
项目做到这里都很顺利,接下来就遇到了一些难点,主要是利用ARKit渲染模型的部分。其中有一个问题是如何把两个GPS空间上的方位反映到用户屏幕上,经过一些努力,我们终于攻克这个难关,这里可以分享一点干货:
首先考虑空间上的两个点P0、 P1,以P0为原点,横轴代表纬度,纵轴代表经度,这样我们可以求得两点位于正北的偏角θ;
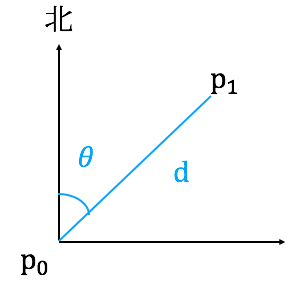
图三
2. 然后通过陀螺仪可以得到当前手机正方向的朝向α;
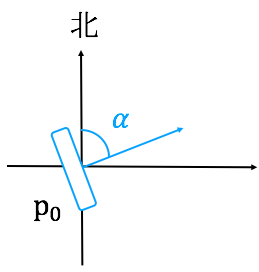
图四
3. 之后只要将3D模型渲染在屏幕正中央俯视偏角
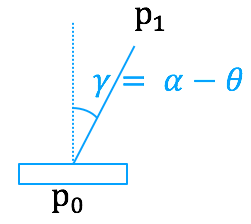
图五
那么问题来了,如何将一个3D模型显示在屏幕正中央γ处呢?这里就用到了ARKit的ARSCNView中的模型渲染API,跟OpenGL类似,ARSCNView从创建之初会设置一个3D世界原点并启动摄像头,随着手机的移动,摄像头相当于3D世界中的一个眼睛,可以用一个观察矩阵[camera]表示。
这样在屏幕正中央俯视偏角γ处渲染一个3D节点的问题,其实就是如何才能把观测坐标转换为世界坐标的问题。我们首先将物体放在手机前3米处,然后直接根据下图所示公式就可求得最终坐标:
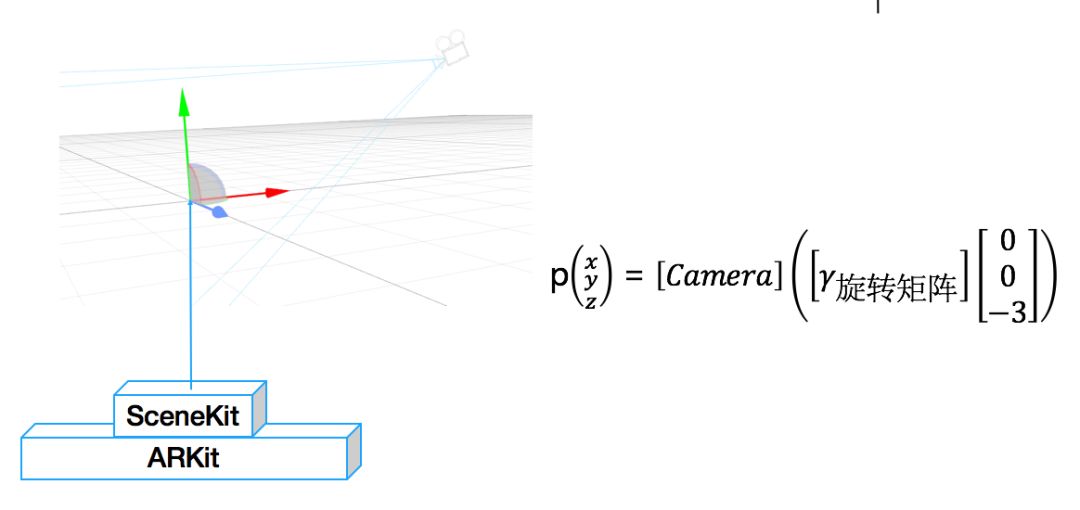
下面是在ARSCNView每次重新渲染回调中设置模型位置的逻辑:
func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) { guard let renderLocations = self.netGroupInfo?.locations?.filter({ (userLocation) -> Bool in
return userLocation.userId != GroupMenberManager.sharedInstance.getCurrentUserID()
}) else { return
} DispatchQueue.main.async { guard let camera = self.sceneView.pointOfView else { return } //当前用户定位
let currentLocation = UserLocation()
currentLocation.latitude = GroupMenberManager.sharedInstance.userLatitude
currentLocation.longitude = GroupMenberManager.sharedInstance.userLongitute // 循环处理当前组内其他成员
for renderLocation in renderLocations { // 两点间距离公式求得距离用来控制3D模型字体大小,直观的反应距离的远近
let distance = currentLocation.distanceFrom(renderLocation) // 求得两个用户间的坐标关系
let angle = currentLocation.angleFrom(renderLocation) // 根据上述公式求得3D模型要渲染的最终位置 compassAngle为实时获取的陀螺仪指南针方向
var position = SCNVector3(x: 0, y: 0, z: -3).roateInHorizontalPlaneBy(angle: self.compassAngle - angle)
position = camera.convertPosition(position, to: nil) //稳定在水平上
position.y = 0; //更新位置
self.virtualObjectManager.findVirtualObject(renderLocation.userId ?? "")?.scnNode.position = position //根据距离更新模型文字和大小
self.virtualObjectManager.findVirtualObject(renderLocation.userId ?? "")?.changeNodeTextAnSize(text: renderLocation.userTitle, distance: distance)
}
}
}写了一个周末差不多把上面功能完成,这个时候对于参赛获奖是没有任何底气的。因为其实这个点子并不十分新颖,技术难点也不够。最主要的痛点是,我们真机联调测试的时候发现,在10m范围内GPS定位的精度完全不可靠,屏幕中渲染的点位置经常错乱。我们之前知道近距离GPS定位会不准,却没想到3D模型在屏幕上对误差的反应这么敏感,这样的话比赛时现场演示是绝对不行的。
既然GPS近距离定位不准无法解决,我们决定在近距离时放弃GPS用另一种方式提醒用户目标在哪里。
近距离下使用AI算法找到目标
近距离下使用AI算法找到目标
我们做了一个设想,就是让程序在10米范围能够智能地去主动寻找到目标,然后在手机屏幕上标注出来。
之后我们对视觉算法在移动端实现的现状进行调研,发现随着近几年计算机视觉飞跃式发展,网上各种开源图片分类识别算法有很多,加上2017 年年初Apple推出了非常靠谱的Core ML,所以在短时间内实现一个移动端的“目标发现”算法是可行的。
在确定WhereAreYou需要添加的功能后,我们立足于打车找车这个问题进行调研开发,最后终于实现了一个稳定、高效、实时的基于多种CNN模型混合的车辆发现跟踪算法,下面GIF可以看到效果。

在使用完Core ML之后,真心觉得它确实如Apple在WWDC 2017上所言,性能十分优越。由此可以预见之后几年,在移动端直接应用AI算法的优秀App会层出不穷。
扯远了,上点干货吧!
在说我们的《基于多种CNN模型混合的车辆发现跟踪算法及其移动端实现》之前,先说一下Apple的Core ML能帮我们做到哪一步。
Core ML 是一个可以让开发者很容易就能在应用中集成机器学习模型(Machine Learning Models)的应用框架,在 iOS、watchOS、macOS和tvOS上都可以使用它。Core ML使用一种新的文件格式(.mlmodel),可以支持多种类型的机器学习模型数据,比如一些深度神经网络算法(CNN、RNN),决策树算法(boosted trees、random forest、decision trees),还有一些广义的线性模型(SVM、Kmeans)。Core ML models以.mlmodel文件的形式直接集成到开发应用中,文件导入后自动生成对应的工具类可直接用于分类识别等AI功能。
我们知道通过Keras、Caffe、libsvm 等开源学习框架可以生成相应的模型文件,但这些模型文件的格式并不是.mlmodel。Core ML Tools可以对这些文件进行转换,生成.mlmodel文件,将目前比较流行的开源学习框架训练出的模型直接应用在Core ML上,如图八所示:
coremltools本身是一个Python工具包,它可以帮我们完成下面几件事情:
第一点就是刚刚提到的将一些比较出名的开源机器学习工具(如Keras、Caffe、scikit-learn、libsvm、XGBoost)训练出来的模型文件转换为.mlmodel。
第二点是提供可以自定义转换的API。打个比方,假设Caffe更新到了Caffe 3.0,本身模型的文件格式变了,但coremltools还没来及更新,这时就可以利用这些API自己写一个转换器。
coremltools工具本身可以使用上述所说的各种开源机器学习工具训练好的模型进行决策。
看到这里是不是内心很澎湃?是的,有了这个工具我们可以很方便地把训练好的模型应用到Apple设备上,所以赶紧安装吧!步骤很简单,机器上有Python(必须是Python 2.X)环境后执行pip install -U coremltools就好了。
那如何进行转换呢?举一个栗子:
我们可以到Caffe Model Zoo上下载一个公开的训练模型。比如我们下载web_car,这个模型可以用于车型识别,能够区分奔驰、宝马等诸多品牌的各系车型约400余种。下载好web_car.caffemodel、deploy.prototxt、class_labels.txt这三个文件,写一个简单的Python脚本就可以进行转换了。
import coremltools# 调用caffe转换器的convert方法执行转换coreml_model = coremltools.converters.caffe.convert(('web_car.caffemodel', 'deploy.prototxt'), image_input_names = 'data', class_labels = 'class_labels.txt')# 保存转换生成的分类器模型文件coreml_model.save('CarRecognition.mlmodel')coremltools同时还提供了设置元数据描述的方法,比如设置作者信息、模型输入数据格式描述、预测输出张量描述,较为完整的转换脚本如下:
import coremltools# 调用caffe转换器的convert方法执行转换coreml_model = coremltools.converters.caffe.convert(('googlenet_finetune_web_car.caffemodel', 'deploy.prototxt'), image_input_names = 'data', class_labels = 'cars.txt')# 设置元数据coreml_model.author = 'Audebert, Nicolas and Le Saux, Bertrand and Lefevre Sebastien'coreml_model.license = 'MIT'coreml_model.short_description = 'Predict the brand & model of a car.'coreml_model.input_description['data'] = 'An image of a car.'coreml_model.output_description['prob'] = 'The probabilities that the input image is a car.'coreml_model.output_description['classLabel'] = 'The most likely type of car, for the given input.'# 保存转换生成的分类器模型文件coreml_model.save('CarRecognition.mlmodel')上面所说的“可以让开发者很容易地在应用中集成机器学习模型”是什么意思呢?是指如果你有一个CarRecognition.mlmodel 文件,你可以把它拖入到Xcode中:
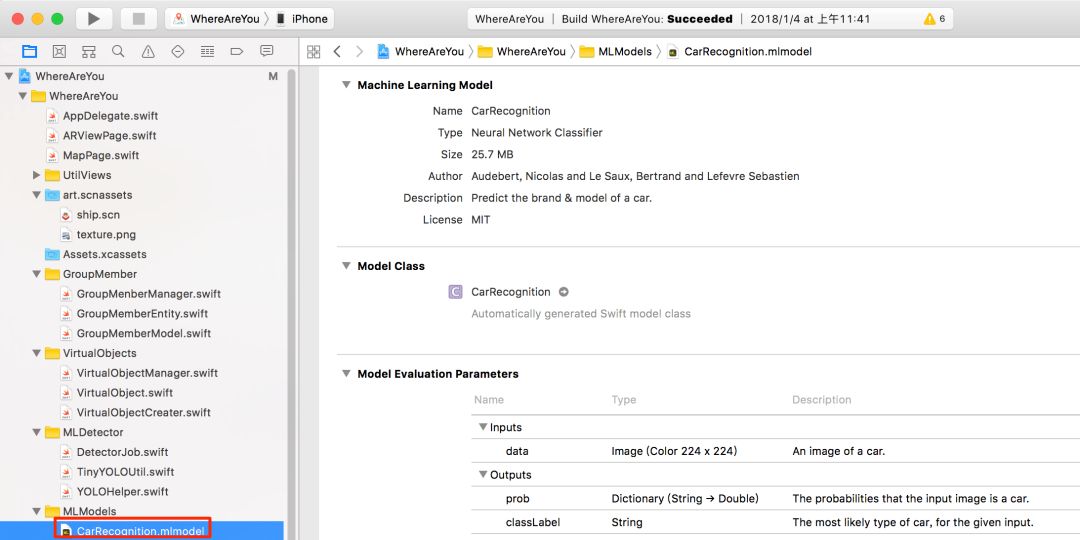
Xcode会自动生成一个叫做CarRecognition的类,直接使用其预测方法就好了。比如对一个汽车图片做识别,像这样:
let carModel = CarRecognition()let output = try carModel.prediction(image: ref)基于上述Core ML提供的功能结合一些开源模型算法我们完成了《基于多种CNN模型混合的车辆发现跟踪算法及其移动端实现》。
首先说一下大概的算法流程,还记得本文一开始在图一中提到的WhereAreYou程序结构图吗?现在我们在AR模块中添加主动寻找目标的功能。当目标GPS距离小于50米时,算法被开启。整个识别算法分为目标检测、目标识别以及目标追踪。当摄像头获取一帧图片后会首先送入目标检测模块,这个模块使用一个CNN模型进行类似SSD算法的操作,对输入图片进行物体检测,可以区分出场景中的行人、车辆、轮船、狗等物体并输出各个检测物体在图片中的区域信息。
我们筛选所有汽车目标,将对应物体的图片截取后送入目标识别模块,对车型进行识别。之后拿到识别出的车型跟车主上传的车型进行对比,如果车主的车型跟识别出的结果一致,就将当前帧和目标区域送入目标跟踪模块,并对当前车辆进行持续跟踪。当然如果跟踪失败就从头进行整个过程。具体如图十所示:
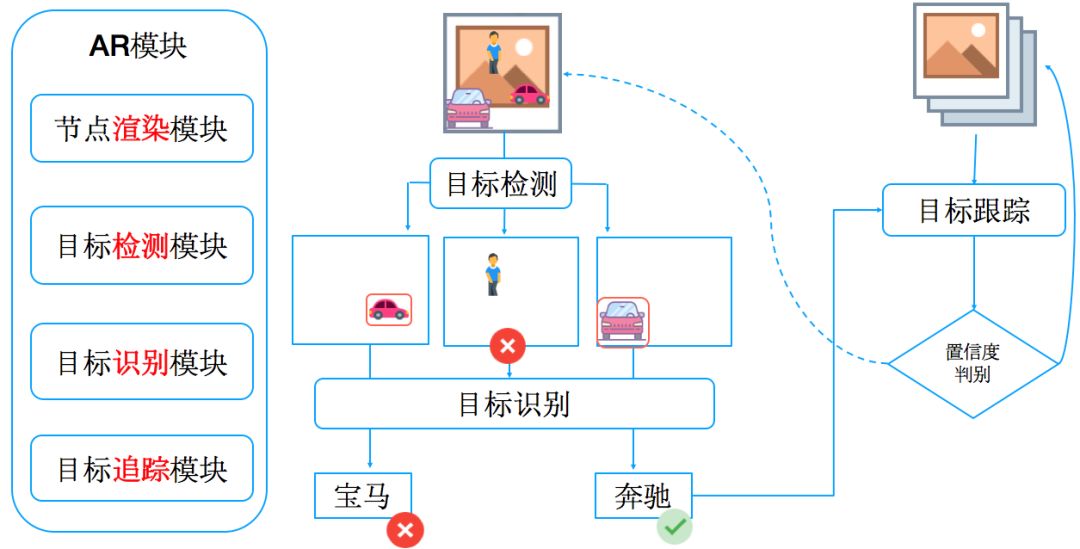
下面说一下为什么要结合这三种算法进行“寻找车主汽车”这个任务:
大家应该还记得刚刚介绍coremltools的时候举的一个例子,在例子中我们在Caffe Model Zoo下载了一个车型识别的算法模型。没错,我们这个结合算法其目标识别模块中用的车型识别正是这个模型。最初调研时,在caffe上找到这个开源模型很开心,觉得把这个模型下载好后转换一下应用到工程中就完事了。
结果发现,实际上将拍摄到的整幅图片送入这个模型得到的识别正确率几乎为零。分析原因是因为这个模型的训练数据是汽车的完整轮廓,而且训练图片并无其它多余背景部分。而现实中用户不可能只拍汽车,场景中汽车只是很小的一个区域,大部分还是天空、马路、绿化带等部分,整幅图片不做截取直接进行处理识别率当然不行。所以只有先找到场景中的车在哪,然后再识别这个是什么车。
在一副图片中标定场景中出现的所有车辆的位置,其实就是SSD问题(Single Shot MultiBox Detector),进一步调研可以了解到近几年基于CNN的SSD算法层出不穷,各种论文资料也很多。其中要数康奈尔大学的YOLO算法尤为出名。更重要的是原作者提供了一个他训练好的模型,这个模型在GitHub上就可以下载,没错我们结合算法其目标检测中的模型算法就是使用的这个→_→ 。
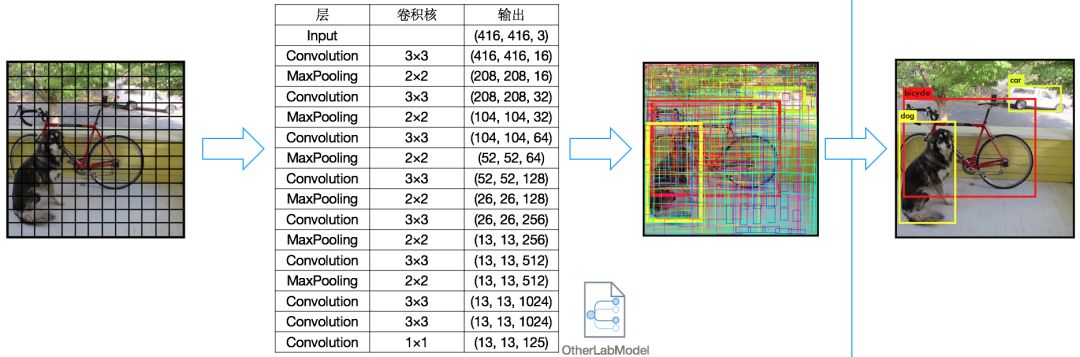
YOLO算法的一个特性就是其检测识别速度十分快,这是由其网络结构和输入结构决定的。YOLO模型输出张量结构决定了在屏幕上如何截取对应图片区域,这里简单介绍一下,概念不严谨之处还请各位不吝赐教。如图十一所示,YOLO算法将输入图片分为13 × 13个小块,每张图片的各个小块对应到其所属物体的名称和这个物体的范围。打个比方图十一中狗尾巴处的一个小块对应的是狗和这个狗在图片中的位置(dog、x、y、width、height),算法支持20种物体的区分。通过网络预测得到的张量为13 × 13 × 125。
其具体意义是一张图片中所有小块(共13 × 13个)每次预测得到5组结果,每组结果对应一个矩形区域信息(x、y、width、height)代表本小块所属的目标区域,同时给出这个区域确信是一个目标的概率(confidence,这里的“确信是一个目标”是指20种物体任意一个即可),还有 20种物体各自的确信概率。即125 = 5 × 25(x、y、width、height、confidence、Class1Confidence、Class2Cconfidence……)。了解这点后我们就不难截取最终识别结果所对应的图片区域了(当然只选取置信率比较高的前几个)。
图十二展示了YOLO高效地执行结果,图十三展示了YOLO目标检测与车辆识别结合后的执行效果。
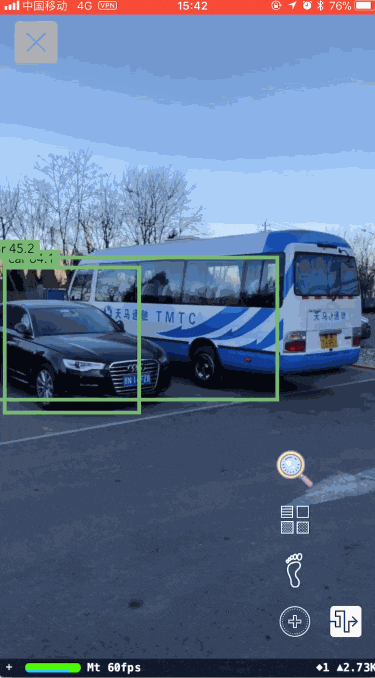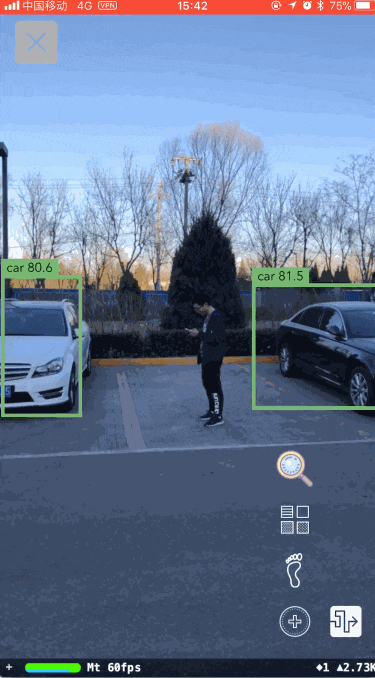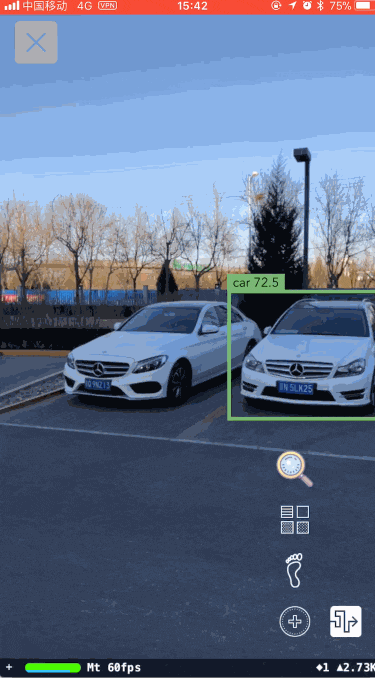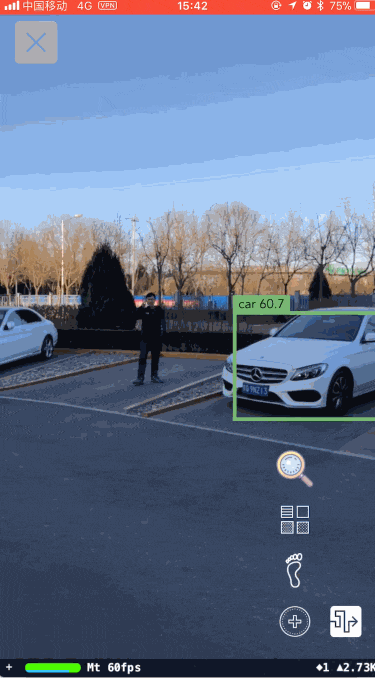

算法到此时可以算是差不多了,但从图十三中还是可以看到一些问题:
识别的结果并不是每帧图片都是对的,而且也并不是每帧图片都能检测出场景中的每一个车辆。这样就会导致在屏幕上标注车辆位置提示用户时会出现断断续续。经过调研后我们又加入了目标跟踪的模块。
目标跟踪的任务比较好理解,输入一帧图片和这张图片中的一个区域信息,要求得出下一帧中这个区域对应图像所在位置,然后迭代此过程。目标跟踪算法在深度学习火起来之前就比较成熟了,文献和开源实现都比较多,我们选用 CoreML官方提供的跟踪模块进行处理,实验效果发现还不错,最终结果如上(图七)所示。
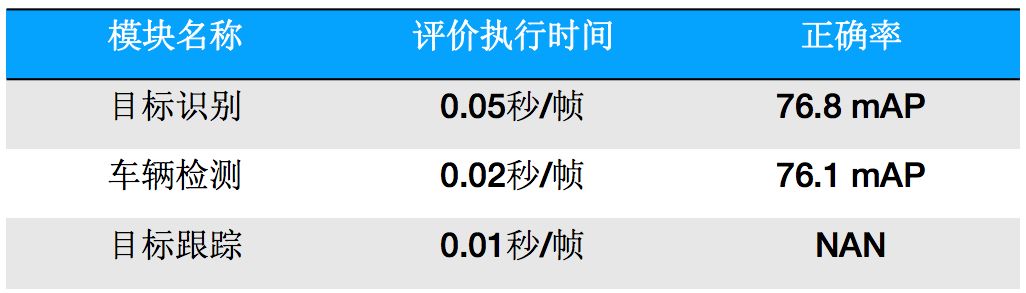
各个模块执行时间统计如下:
总结
总结
《基于多种CNN模型混合的车辆发现跟踪算法及其移动端实现》这个项目由于时间原因还有很多缺陷,诚如当时评委意见所说的那样“核心算法都是使用网上现有模型,没有自己进行训练”,此算法可以提高优化的地方有很多。比如添加车辆颜色、车牌等检测提高确认精度,优化算法在夜间、雨天等噪声环境下的表现等。
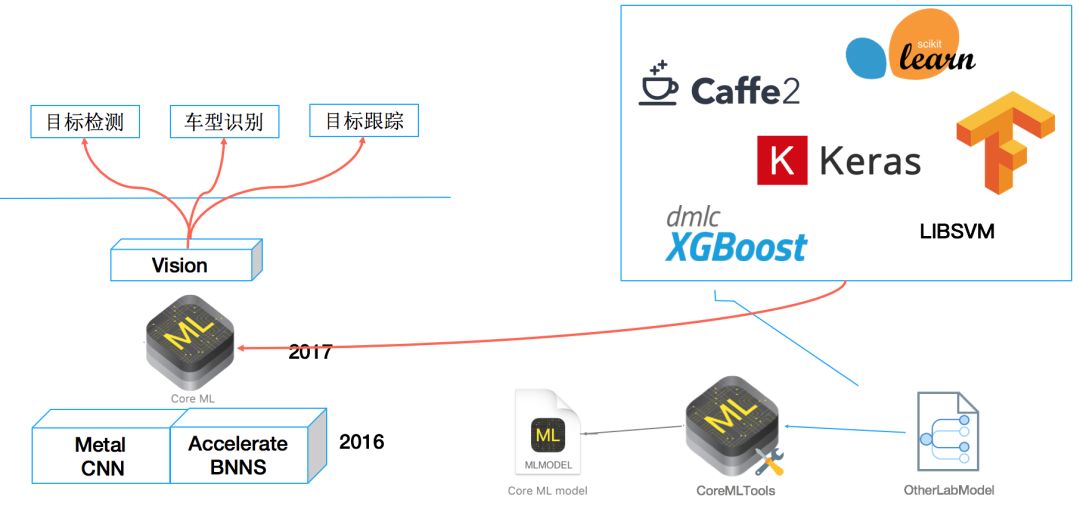
最后,通过这个项目的开发实现让我们知道在移动端应用 CNN 这样的学习算法已经十分方便,如图十五这样构建的移动端AI程序的执行速度和效果都很不错。希望我们的WhereAreYou项目就像能够帮助用户更快找到车一样,给前端工程师提供多一些灵感。相信未来前端工程师能做的可以做的需求会越来越有趣! ^ _ ^
参考文献
参考文献
[1] Yang L, Luo P, Change Loy C, et al. A large-scale car dataset for fine-grained categorization and verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3973-3981.
[2] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[J]. arXiv preprint arXiv:1612.08242, 2016.
作者简介
作者简介
大卫,美团点评前端iOS开发工程师,2016年毕业于安徽大学,同年加入美团点评到店餐饮事业群,从事商家移动端应用开发工作。
深度学习
深度学习在美团点评推荐平台排序中的运用
深度学习在美团点评的应用
美团点评联盟广告场景化定向排序机制

长按二维码关注我们
更多技术博客:美团点评技术博客。
PS:
正文中标绿的名词均为参考链接,可点击查询。
查看文中代码请关注tech.meituan.com的更新。




