Google发布“多巴胺”开源强化学习框架,三大特性全满足

编译整理 | Just
编辑 | 阿司匹林
出品 | AI科技大本营
强化学习是一种非常重要的 AI 技术,它能使用奖励(或惩罚)来驱动智能体(agents)朝着特定目标前进,比如它训练的 AI 系统 AlphaGo 击败了顶尖围棋选手,它也是 DeepMind 的深度 Q 网络(DQN)的核心部分,它可以在多个 workers 之间分步学习,例如,在 Atari 2600 游戏中实现“超人”性能。
麻烦的是,强化学习框架需要花费大量时间来掌握一个目标,而且框架往往是不灵活和不总是稳定的。
但不用担心,Google 近日发布了一个替代方案:基于 TensorFlow 的开源强化学习框架 Dopamine(多巴胺)。
Google 的博文中提到,这个基于 Tensorflow 的强化学习框架,旨在为 RL 的研究人员提供灵活性,稳定性和可重复性的研究。受到大脑中奖励动机行为的主要成分的启发,以及反映神经科学与强化学习研究之间强烈的历史联系,该平台旨在实现可推动激进发现的思辨研究(speculative research)。此版本还包括一组阐明如何使用整个框架的 colabs。
除了强化学习框架的发布,谷歌还推出了一个网站(https://google.github.io/dopamine/baselines/plots.html),允许开发人员快速可视化多个智能体的训练运行情况。他们希望,这一框架的灵活性和易用性将使研究人员能积极尝试新的想法,不管是渐进式还是激进式的想法。
以下为 Google 博客详细内容:

引入灵活和可重复的强化学习研究的新框架
强化学习(RL)研究在过去几年中取得了许多重大进展。这些进步使得智能体可以以超人类级别的能力玩游戏。比如 Atari 游戏中 DeepMind 的 DQN ,AlphaGo ,AlphaGo Zero 以及 Open AI Five。
具体而言,在 DQN 中引入 replay memories 可以利用以前的智能体经验,大规模的分布式训练可以在多个 workers 之间分配学习过程,分布式方法允许智能体模拟完整的分布过程,而不仅仅是模拟它们期望值,以学习更完整的图景。这种类型的进展很重要,因为出现这些进步的算法还适用于其他领域,例如机器人技术。
通常,这种进步都来自于快速迭代设计(通常没有明确的方向),以及颠覆既定方法的结构。然而,大多数现有的 RL 框架并没有结合灵活性和稳定性以及使研究人员能够有效地迭代 RL 方法,并因此探索可能没有直接明显益处的新研究方向。此外,从现有框架再现结果通常太耗时,这可能导致科学的再现性问题。
今天,我们推出了一个新的基于 Tensorflow 的框架,旨在为 RL 的研究人员提供灵活性、稳定性和可重复性。受到大脑中奖励动机行为的主要成分的启发,以及反映神经科学与强化学习研究之间强烈的历史联系,该平台旨在实现可推动激进发现的思辨研究(speculative research)。此版本还包括一组阐明如何使用整个框架的 colabs。

易用性
清晰和简洁是该框架设计中要考虑的两个关键因素。我们提供更精简的代码(大约 15 个Python 文件),并且有详细记录。这是通过专注于 Arcade 学习环境(一个成熟的,易于理解的基准)和四个基于 value 的智能体来实现的:DQN,C51,一个精心策划的 Rainbow 智能体的简化版本,以及隐式分位数网络(Implicit Quantile Network)智能体,这已在上个月的 ICML 大会上已经发表。我们希望这种简洁性使研究人员能够轻松了解智能体内部的运作状况,并积极尝试新的想法。

可重复性
我们对重复性在强化学习研究中的重要性特别敏感。为此,我们为代码提供完整的测试覆盖率,这些测试也可作为其他文档形式。此外,我们的实验框架遵循 Machado 等人给出的关于使用 Arcade 学习环境标准化经验评估的建议。

基准测试
对于新的研究人员来说,能够根据既定方法快速对其想法进行基准测试非常重要。因此,我们为 Arcade 学习环境支持的 60 个游戏提供四个智能体的完整培训数据,可用作 Python pickle 文件(用于使用我们框架训练的智能体)和 JSON 数据文件(用于与受过其他框架训练的智能体进行比较);我们还提供了一个网站,你可以在其中快速查看 60 个游戏中所有智能体的训练运行情况。
下面展示我们在 Seaquest 上的 4 个代理的训练情况,这是由 Arcade 学习环境支持的一种 Atari 2600 游戏。
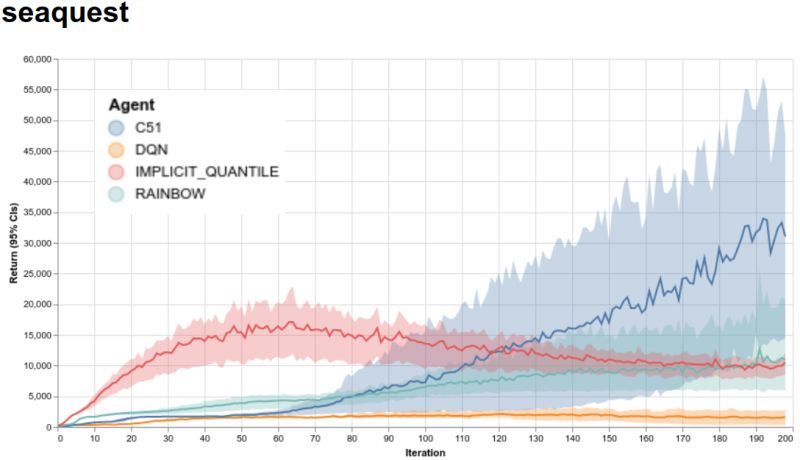
在 Seaquest 上的 4 名智能体参加了训练。x 轴表示迭代,其中每次迭代是 100 万个游戏帧(4.5 小时的实时游戏);y 轴是每场比赛获得的平均分数。阴影区域显示的是来自 5 次独立运行的置信区间。
我们还提供已经训练好的深度网络,原始统计日志以及用 Tensorboard 绘图的 Tensorflow 事件文件。这些都可以在网站的下载部分找到。
希望我们框架的灵活性和易用性将使研究人员敢于尝试新的想法,包括渐进式和激进式的想法。我们已经积极地将它用于我们的研究,并发现它能够灵活且快速迭代许多想法。我们很高兴可以为更大的社区做些贡献。
GitHub 链接:
https://github.com/google/dopamine/tree/master/docs#downloads
参考链接:
https://ai.googleblog.com/2018/08/introducing-new-framework-for-flexible.html
https://venturebeat.com/2018/08/27/google-releases-open-source-reinforcement-learning-framework-for-training-ai-models/