DeepMind推出分布式深度强化学习架构IMPALA,让一个Agent学会多种技能

维金 编译自 DeepMind Blog
量子位 出品 | 公众号 QbitAI
目前,深度增强学习(DeepRL)技术在多种任务中都大获成功,无论是机器人的持续控制问题,还是掌握围棋和雅达利的电子游戏。不过,这些方面的进展仅限于孤立任务。完成每一项任务都要单独调试、训练agent。
在最近的工作中,我们研究了如何训练单一agent去执行多种任务。
今天,我们发布了DMLab-30。这是一组新任务,包含了在统一视觉环境、通用动作空间(action space)中的多种类型挑战。训练agent去胜任多种任务意味着巨大的吞吐量,以及要高效地利用每个数据点。
为此,我们开发了全新的、扩展性强的agent架构,用于分布式训练。这就是IMPALA(重要性加权的操作者-学习者架构,Importances Weighted Actor-Learner Architectures),这种架构利用了新的离策略修正算法V-trace。
DMLab-30
DMLab-30用开源增强学习环境DeepMind Lab设计的新关卡的集合。这些环境让任何DeepRL研究者都能基于大量有趣的任务去测试不同系统,可能是单个任务也可能是多任务集合。
任务的设计则尽可能地多样化。这些任务有不同目标,从学习到记忆,再到探索。在视觉上这些任务也有所不同,从色彩鲜艳的现代风格材质,到黎明、正午和夜晚沙漠中表现出的棕色和绿色。这些任务也涉及多种物理环境,从开放的山地地形,到直角迷宫,再到开阔的圆形房间。
此外,有些环境中设置了“机器人”,这些机器人有属于自己的、以目标为导向的行为。同样重要的,不同关卡的目标和奖励有所不同,具体从跟踪语言命令、使用钥匙去开门、寻找蘑菇,到绘制和追踪复杂的不可逆路径。
然而在最基本的层面上,从动作空间和观察空间来看,环境都是相同。这使得单一agent可以通过训练,在不同环境中行动。
IMPALA:
重要性加权的操作者-学习者架构
DMLab-30的挑战性很强。为了利用这个工具,我们开发了全新的分布式agent,即IMPALA。这个agent能利用高效的分布式架构和TensorFlow,让数据吞吐量最大化。
IMPALA的灵感来自于热门的A3C架构,后者使用多个分布式actor来学习agent的参数。在类似这样的模型中,每个actor都使用策略参数的一个副本,在环境中操作。actor会周期性地暂停探索,将它们已经计算得出的梯度信息分享至中央参数服务器,而后者会对此进行更新。
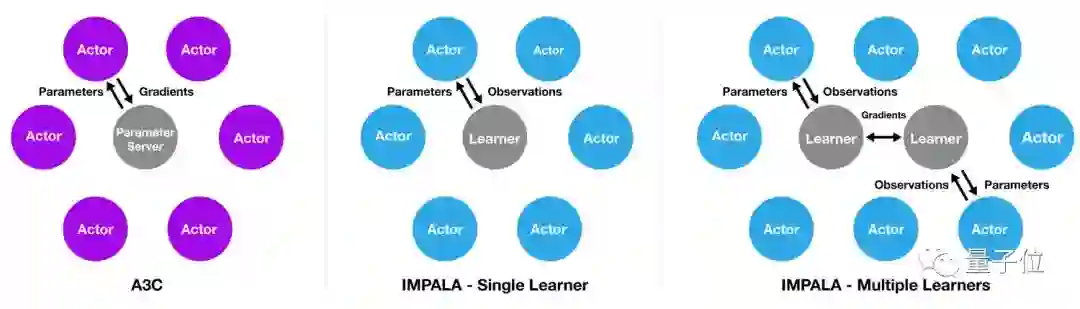
与此不同,IMPALA中的actor不会被用来计算梯度信息。它们只是收集经验,并将这些经验传递至位于中心的learner。learner会计算梯度。因此在这样的模型中,actor和learner是完全独立的。为了利用当代计算系统的规模优势,IMPALA在配置中可支持单个learner机器,也可支持多个相互之间同步的learner机器。以这种方式将学习和操作分开也有利于提升整个系统的吞吐量,因为与批量A2C这类架构不同,actor不再需要等待学习步骤。这帮助我们在有趣的环境中训练IMPALA,同时不必面临由于帧渲染时间或任务重启耗时造成的差异。
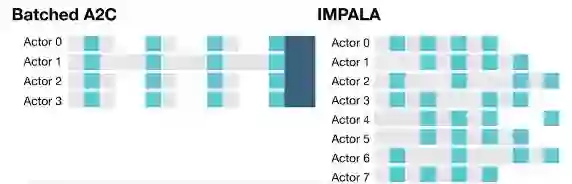
不过操作和学习的解耦也导致,actor的策略落后于learner。为了弥补这样的差距,我们引入了离策略优势actor-评价者公式V-trace。它弥补了离策略actor获得的轨迹。你可以从我们的论文中了解算法及其分析细节。
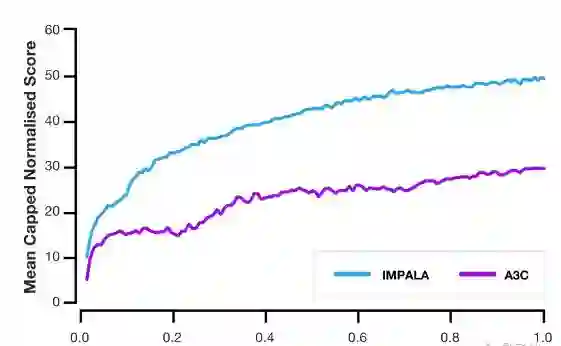
凭借优化的模型,与传统agent相比,IMPALA可以处理多出一到两个数量级的经验,使得在挑战性环境中的学习成为可能。我们将IMPALA与多种热门的actor-评价者方法进行了比较,发现前者有明显的速度提升。此外,IMPALA的吞吐量上升与actor、learner的数量增长呈线性关系。这表明,分布式agent模型和V-trace算法都可以胜任超大规模的实验,即使机器数量达到数千台。
在利用DMLab-30关卡进行测试时,与分布式A3C相比,IMPALA的数据效率达到10倍,而最终得分达到两倍。此外,与单任务环境中的训练相比,IMPALA在多任务环境的训练中表现出正向转换。
论文
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, Koray Kavukcuoglu
https://arxiv.org/abs/1802.01561
开源代码
https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30
博客原文
https://deepmind.com/blog/impala-scalable-distributed-deeprl-dmlab-30/
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


