编程之性能优化知多少
(点击上方蓝字,可快速关注我们)
来源:『圣杰』
cnblogs.com/sheng-jie/p/7109385.html
一、引言
性能优化是一个老生常谈的问题了,典型的性能问题如页面响应慢、接口超时,服务器负载高、并发数低,数据库频繁死锁等。而造成性能问题又有很多种,比如磁盘I/O、内存、网络、算法、大数据量等等。
我们可以大致把性能问题分为四个层次:代码层次、数据库层次、算法层次、架构层次。
所以下面我会结合实际性能优化案例,和大家分享下性能调优的工具、方法和技巧。
二、先说心态
说到性能问题,你可能首先就想到的是麻烦或者头大,因为一般性能问题都比较紧急,轻则影响客户体验,重则宕机导致财务损失,而且性能问题比较隐蔽,不易发现。因此一时间无从下手,而这时我们就很容易从心底开始去排斥它,不愿接这烫手的山芋。
而恰巧,性能调优是体现程序员水平的一个重要指标。
因为处理bug、崩溃、调优、入侵等突发事件比编程本身更能体现平庸程序员与理想程序员的差距。当面对一个未知的问题时,如何定位复杂条件下的核心问题、如何抽丝剥茧地分析问题的潜在原因、如何排除干扰还原一个最小的可验证场景、如何抓住关键数据验证自己的猜测与实验,都是体现程序员思考力的最好场景。是的,在衡量理想程序员的标准上,思考力比经验更加重要。
所以,若你不甘平庸,请拥抱性能调优的每一个机会。当你拥有一个正确的心态,你所面对的性能问题就已经解决了一半。
三、再说技巧
拿到一个性能问题,不要忙着先上工具,先了解问题出现的背景,问题的严重程度。然后大致根据自己的经验积累作出预估。比如客户来了个性能问题说系统宕机了,已经造成资金损失了。
这种涉及到钱的问题,大家都比较敏感,根据自己的level,决定是否要接这个锅。这不是逃避,而是自知之明。
了解问题背景之后,下一步就来尝试问题重现。如果在测试环境能够重现,那这种问题就很好跟踪分析。
如果问题不能稳定重现或仅能在生产环境重现,那问题就相对比较棘手,这时要立刻收集现场证据,包括但不限于抓dump、收集应用程序以及系统日志、关注CPU内存情况、数据库备份等等,之后不妨再尝试重现,比如恢复客户数据库到测试环境重现。
不管问题能否重现,下一步,我们就要大致对问题进行分类,是代码层次的业务逻辑问题还是数据库层次的操作耗时问题,又或是系统架构的吞吐量问题。那如何确定呢?而我倾向于先从数据库动手。
我的习惯做法是,使用数据库监控工具,先跟踪下Sql耗时情况。如果监控到耗时较长的SQL语句,那基本上就是数据库层次的问题,否则就是代码层次。若为代码层次,再研究完代码后,再细化为算法或架构层次问题。
确定问题种类后,是时候上工具来精准定位问题点了:
Sql耗时问题,推荐使用免费的Plan Explorer(https://www.sentryone.com/plan-explorer)分析执行计划。
代码问题定位,优先推荐使用VS自带的Performance Analysis,其次是RedGate的性能分析套件.NET Developer Bundle(http://www.red-gate.com/products/dotnet-development/dotnet-developer-bundle/);然后还有Jet Brains的dotTrace -- .NET performance profiler,dotMemory-- .NET memory profiler;再然后就是反人类的Windbg;等等。
精准定位问题点后,就是着手优化了。相信到这一步,就是优化策略的选择了,这里就不展开了。
优化后,最后当然要进行测试了,毕竟优化了多少,我们也要做到心里有谱才行。
四、 案例分享
下面就分享下我针对代码层面、数据库层面和算法层面的优化案例。
4.1. SQL优化案例
案例1:客户反馈某结算报表统计十天内的数据耗时10mins左右。
由于前几天刚学会用RedGate的分析工具,拿到这个问题,本地尝试重现后,就直接想使用工具分析。然而,这工具在使用webdev模式起站点时,总是报错,而当时时一根筋,老是想解决这个工具的报错问题。结果,白白搞了半天也没搞定。
最后不得已放弃工具,转而选择使用sql server profiler去监控sql语句耗时。一跟踪不要紧,问题就直接暴露了,整个全屏的重复sql语句,如下图。
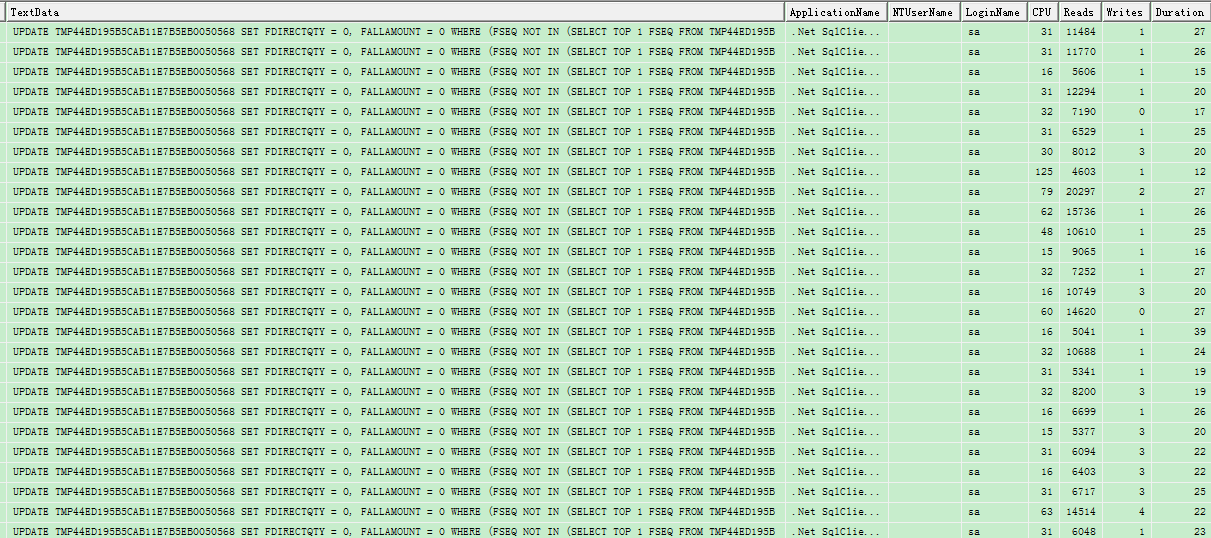
这下问题就很明显了,八成是代码在循环拼接sql执行语句。根据抓取到sql关键字往代码中去搜索,果然如此。
#region更新三张表数据结合的中间临时表数据,有上游单据的直接调拨单分多次下推时,只计算一次的调拨数量和价税合计
string sSql = string.Format(@
"SELECT FENTRYID FROM {0} GROUP BY FENTRYID HAVING COUNT(FENTRYID) > 1", sJoinDataTempTable);
using(IDataReader reader = DBUtils.ExecuteReader(this.Context, sSql)) {
while (reader.Read()) {
sbSql.AppendFormat(@"
UPDATE {0} SET FDIRECTQTY = 0,FALLAMOUNT = 0
WHERE FSEQ NOT IN (
SELECT TOP 1 FSEQ FROM {0} WHERE FENTRYID = {1}) AND FENTRYID = ({1});"
, sJoinDataTempTable, Convert.ToInt32(reader["FENTRYID"]));
listSqlObj.Add(new SqlObject(sbSql.ToString(), new List < SqlParam > ()));
sbSql.Clear();
}
}
#endregion
看到这段代码,咱先不评判这段代码的优劣,因为毕竟代码注释清晰,省了我们理清业务的功夫。这段sql主要是想做去重处理,很显然选用了错误的方案。改后代码如下:
string sqlMerge = string.Format(@"
merge into {0} t1
using(
select min(Fseq) fseq,Fentryid from {0} t2 group by fentryid
) t3 on (t1.fentryid = t3.fentryid and t1.fseq <> t3.fseq)
when matched then
update set t1.FDIRECTQTY = 0, t1.FALLAMOUNT = 0
", sJoinDataTempTable);
listSqlObj.Add(new SqlObject(sqlMerge, new List < SqlParam > ()));
sbSql.Clear();
改后测试相同数据量,耗时由10mins降到10s左右。
4.2. 代码优化案例
案例2:客户反馈销售订单100条分录行,保存进行可发量校验时,耗时7mins左右。
拿到这个问题后,本地重现后,监控sql耗时没有异常,那就着重分析代码了。因为可发量校验的业务逻辑极其复杂,又加上又直接再一个类文件实现该功能,3500+行的代码,加上零星注释,真是让人避之不及。逃避不是办法,还是上工具分析一把。
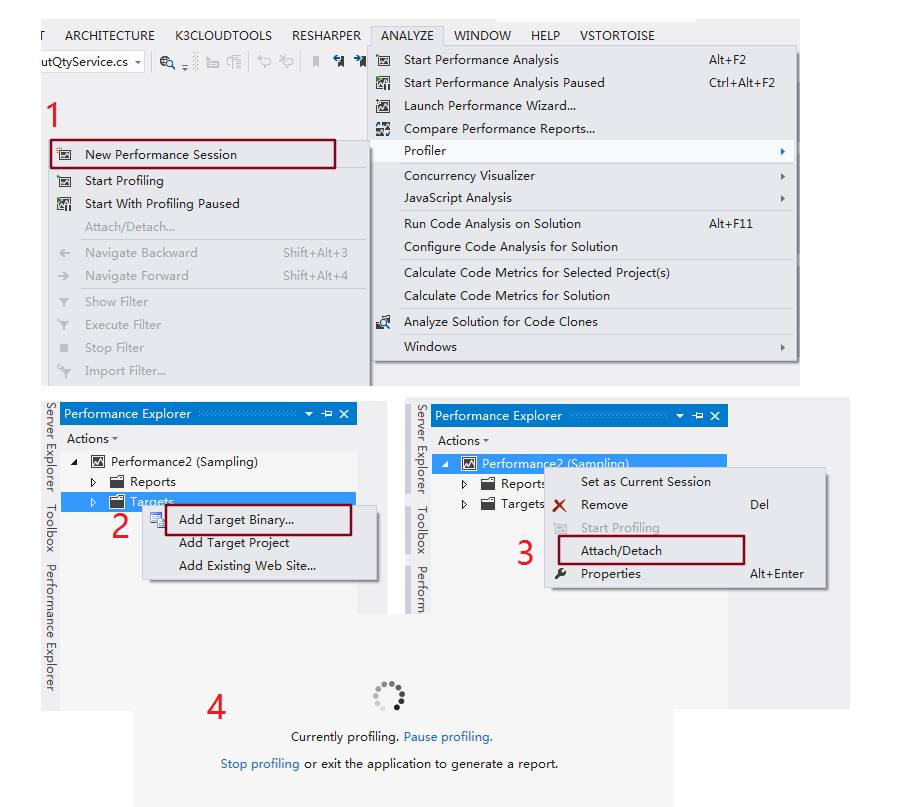
这次我选用的时VS自带的Performance Profiler,开发环境下极其强大的性能调优工具。针对我们当前案例,我们仅需要跟踪指定服务对应的dll即可,使用步骤如下:
Analyze-->Profiler-->New Performance Session
打开Performance Explorer
找到新添加的Performance Session,右键Targets,然后选择Add Target Binary,添加要跟踪的dll文件即可
将应用跑起来
选中Performance Session,右键Attach对应进程即可跟踪分析性能了
在跟踪过程中,可随时暂停跟踪和停止跟踪
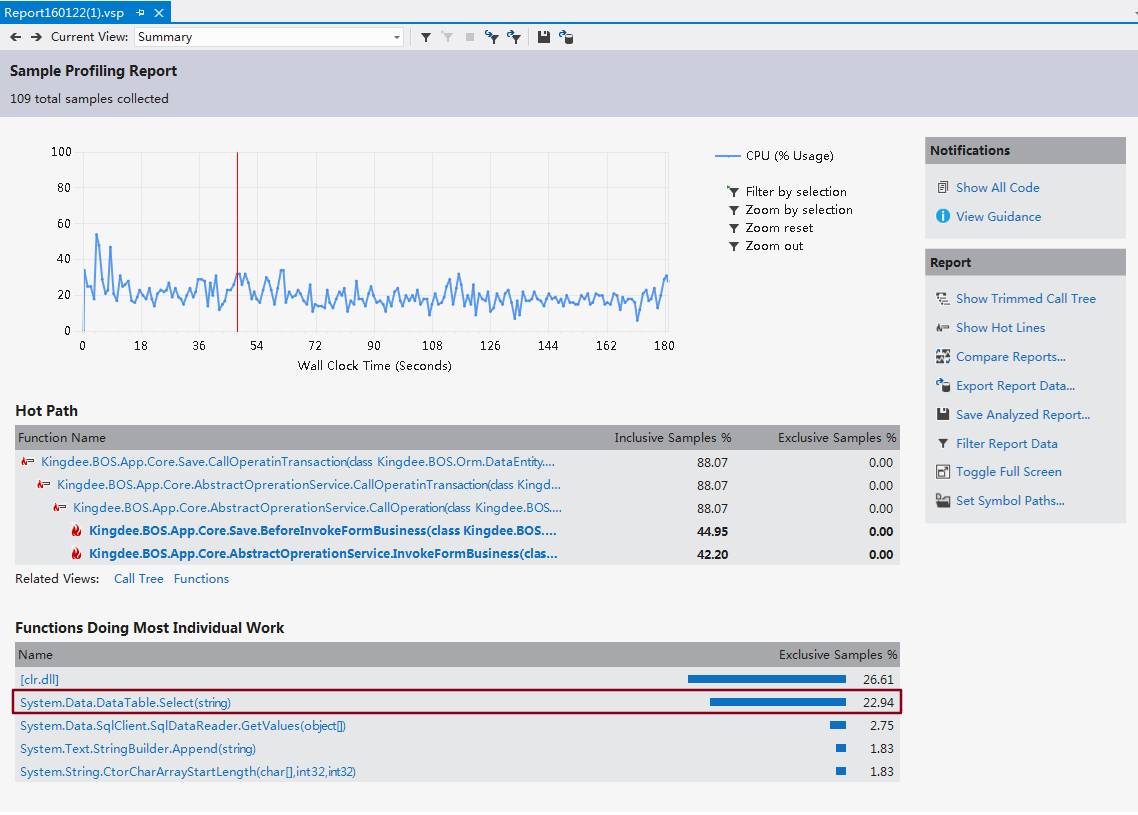
跟踪结束后本案例跟踪到的采样结果如下图:
同时Performance Profiler也给出了问题的建议,如下图:
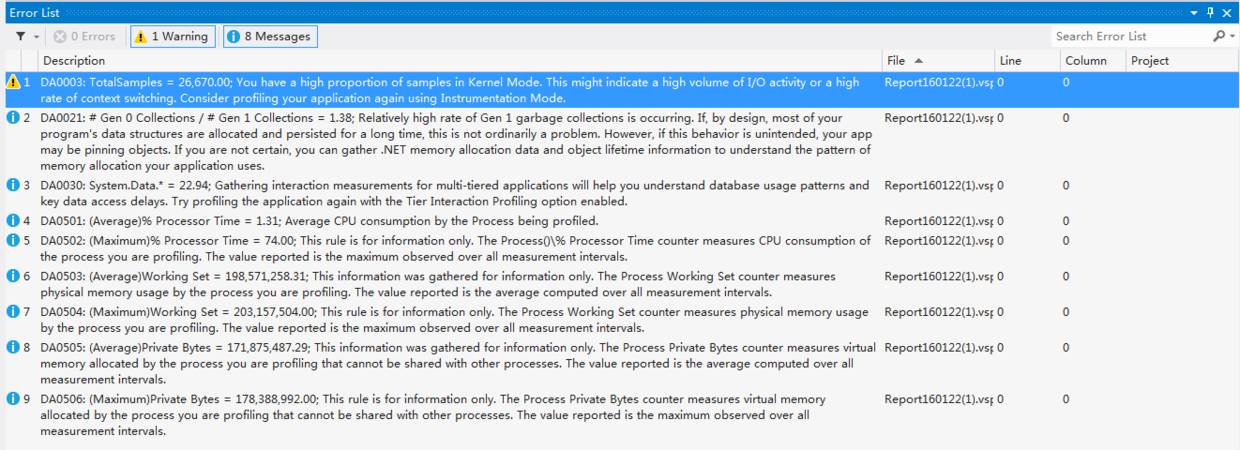
其中第1、4条大致说明程序I/O消耗大,第一代的GC上存在未及时释放的垃圾占比过高。而根据上图的采样结果,我们可以直接看出是由于再代码中频繁操作DataTable引起的性能瓶颈。走读代码发现的确如此,所有的数量统计都是在代码中循环遍历DataTable进行处理的。而最终的优化策略,就相当于一次大的重构,将所有代码中通过遍历DataTable的计算逻辑全部挪到SQL中去做。由于代码过多,就不再放出。
案例3:客户反馈批量引入1000张订单,耗时40mins左右,且容易中断。
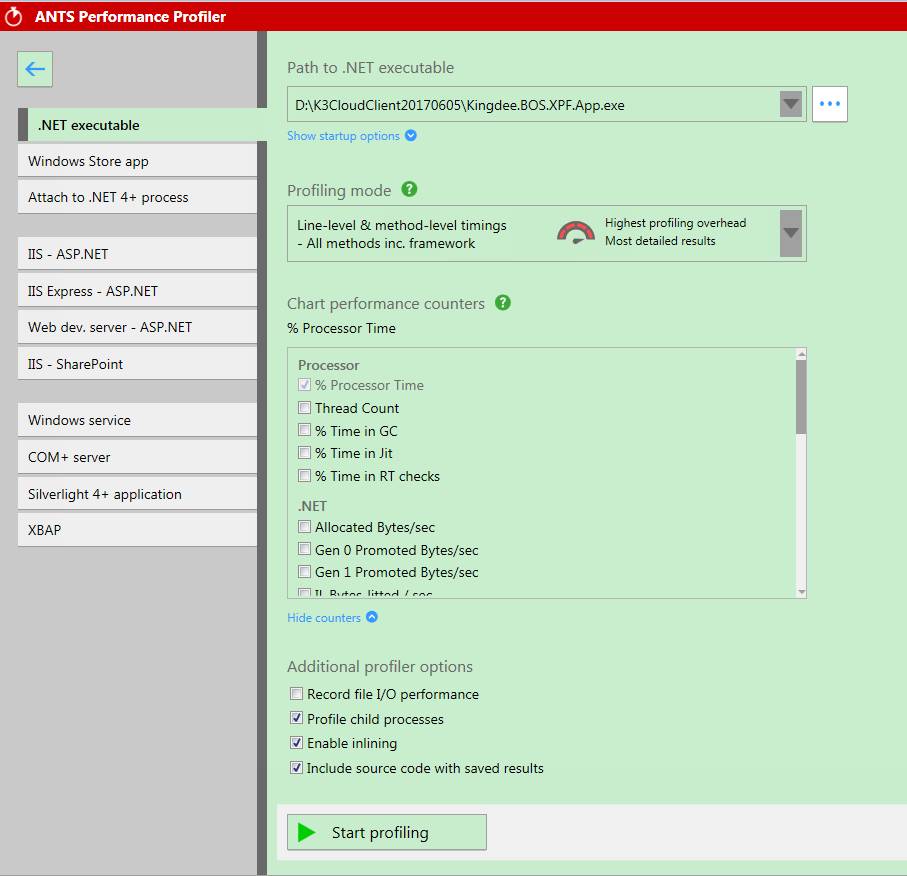
同样,我们还是先尝试本地重写。经测试批量引入101张单据,就耗时5mins左右。下一步打开Sql监控工具也未发现耗时语句。但考虑到是批量导入操作,虽然单个耗时不多,但乘以100这个基数,就明显了。下面我们就使用RedGate的Ants Performance Profiler跟踪一下。
该工具比较直观,可以同时监控代码和SQL执行情况。第一步,New Profiler Session,第二步进行设置,如下图。根据自己的应用程序类别,选择相应的跟踪方式。
针对这个问题,我们跟踪到的调用堆栈和SQL耗时结果如下图:
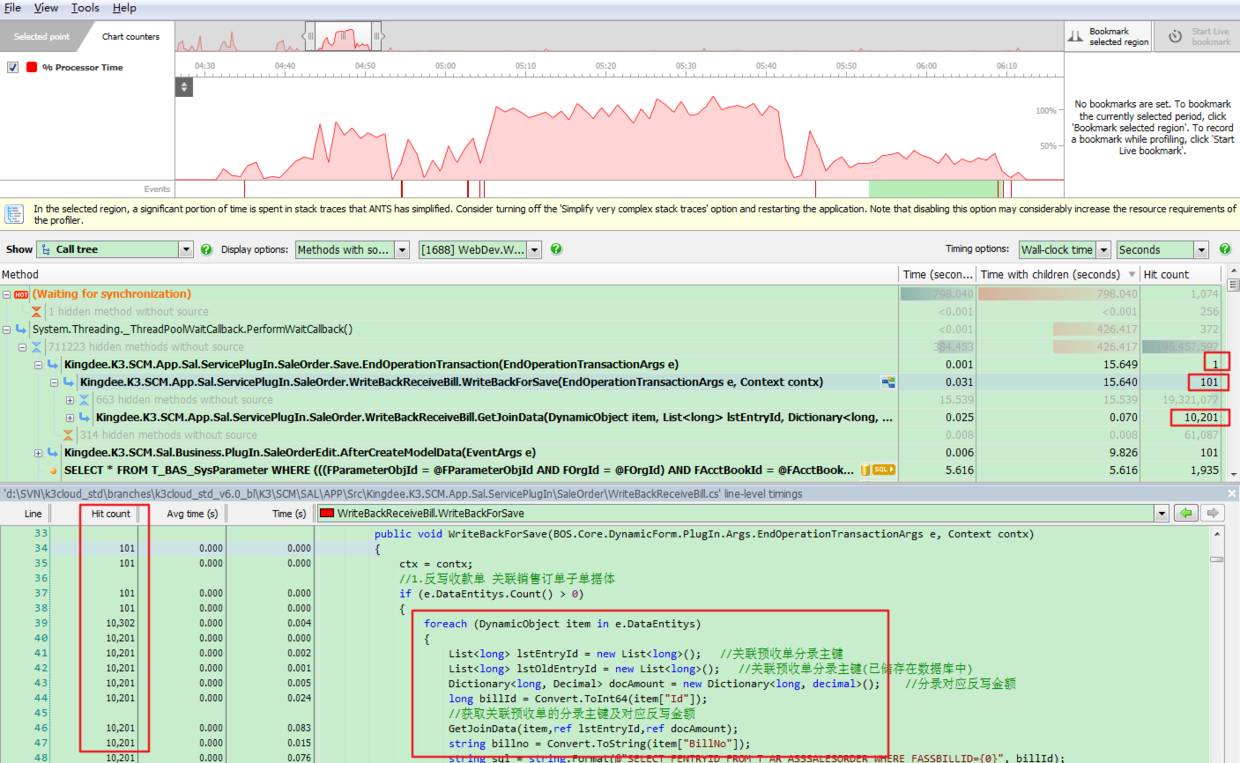

首先从调用堆栈中的Hit Count,我们可以首先看出它是一个批量过程,因为入口函数仅调用一次;第二个我们可以代码中是循环处理每一个单据,因为Hit Count与我们批量引入的单据数量相符;第三个,突然来了个10201,如果有一定的数字敏感性的话,这次性能问题的原因就被你找到了。这里就不卖关子了,101 x 101 = 10201。
是不是明白了什么,存在循环嵌套循环的情况。我们走读代码确定一下:
//Save.cs
public override void EndOperationTransaction(EndOperationTransactionArgs e) {
//省略其他代码
foreach(DynamicObject dyItem in e.DataEntitys) {
//反写收款单
WriteBackReceiveBill wb = new WriteBackReceiveBill();
wb.WriteBackForSave(e, this.Context);
}
}
//WriteBackReceiveBill .cs
public void WriteBackForSave(EndOperationTransactionArgs e, Context contx) {
//省略其他代码:
foreach(DynamicObject item in e.DataEntitys) {
//do something
}
}
好嘛,外层套了一个空循环却什么也没做。修改就很简单了,删除无效外层循环即可。
4.3. 算法优化案例
案例4:某全流程跟踪报表超时。
这个报表是用来跟踪所有单据从下单到出库的业务流程数据流转情况。而所有的流程数据都是按照树形结果存储在数据库表中的,类似这样:

图中的流程为:
销售合同-->销售订单-->发货通知单-->销售出库单
为了构造流程图,之前的处理方法是把流程数据取回来,通过代码构造流程图。这也就是性能差的原因。
而针对这种情况,就是考验我们平时经验积累了。对于树形结构的表,我们也是可以通过SQL来进行直接查询的,这就要用到了SQL Server的CTE语法来进行递归查询。关于递归查询,可参考我这篇文章:SQL递归查询知多少(http://www.jianshu.com/p/ab9d268aa54c)。
五、总结
性能调优是一个循序渐进的过程,不可能一蹴而就,重在平时的点滴积累。关于工具的选择和使用,本文并未展开,也希望读者也不要纠结与此。当你真正想解决一个问题的时候,相信工具的使用是难不住你的。
最后就大致总结下我的调优思路:
调整心态,积极应对
了解性能背景, 收集证据, 尝试重现
问题分类,先监控SQL耗时,大致确定是SQL或是代码层次原因
使用性能分析工具,确定问题点
调优测试
看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能