从400+节点Elasticsearch集群的运维中,我们总结了这些经验

Meltwater 每天要处理数百万量级的帖子数据,因此需要一种能处理该量级数据的存储和检索技术。
从 0.11.X 版本开始我们就已经是 Elasticsearch 的忠实用户了。在经历了一些波折之后,最终我们认为做出了正确的技术选型。
Elasticsearch 用于支持我们的主要媒体监控应用,客户通过该应用可以检索和分析媒体数据,比如新闻文章、(公开的)Facebook 帖子、Instagram 帖子、博客和微博。我们通过使用一个混合 API 来收集这些内容,并爬取和稍作加工,使得它们可被 Elasticsearch 检索到。
本文将分享我们所学到的经验、如何调优 Elasticsearch,以及要绕过的一些陷阱。
每天都有数量相当庞大的新闻和微博产生;在高峰期需要索引大约 300 多万社论文章,和近 1 亿条社交帖子数据。其中社论数据长期保存以供检索(可回溯到 2009 年),社交帖子数据保存近 15 个月的。当前的主分片数据使用了大约 200 TB 的磁盘空间,副本数据大约 600 TB。
我们的业务每分钟有 3 千次请求。所有的请求通过一个叫做“search-service”的服务,该服务会依次完成所有与 Elasticsearch 集群的交互。大部分检索规则比较复杂,包括在面板和新闻流中。比如,一个客户可能对 Tesla 和 Elon Musk 感兴趣,但希望排除所有关于 SpaceX 或 PayPal 的信息。用户可以使用一种与 Lucene 查询语法类似的灵活语法,如下:
Tesla AND "Elon Musk" NOT (SpaceX OR PayPal)我们最长的此类查询有 60 多页。重点是:除了每分钟 3 千次请求以外,没有一个查询是像在 Google 里查询“Barack Obama”这么简单的;这简直就是可怕的野兽,但 ES 节点必须努力找出一个匹配的文档集。

我们运行的是一个基于 Elasticsearch 1.7.6 的定制版本。该版本与 1.7.6 主干版本的唯一区别是,我们向后移植(backport)了 roaring bitsets/bitmaps 作为缓存。该功能是从 Lucene 5 移植到 Lucene 4 的,对应移植到了 ES 1.X 版本。Elasticsearch 1.X 中使用默认的 bitset 作为缓存,对于稀疏结果来说开销非常大,不过在 Elasticsearch 2.X 中已经做了优化。
为何不使用较新版本的 Elasticsearch 呢?主要原因是升级困难。在主版本间滚动升级只适用于从 ES 5 到 6(从 ES 2 到 5 应该也支持滚动升级,但没有试过)。因此,我们只能通过重启整个集群来升级。宕机对我们来说几乎不可接受,但或许可以应对一次重启所带来的大约 30-60 分钟宕机时间;而真正令人担心的,是一旦发生故障并没有真正的回滚过程。
截止目前我们选择了不升级集群。当然我们希望可以升级,但目前有更为紧迫的任务。实际上该如何实施升级尚未有定论,很可能选择创建另一个新的集群,而不是升级现有的。
我们自 2017 年 6 月开始在 AWS 上运行主集群,使用 i3.2xlarge 实例作为数据节点。之前我们在 COLO(Co-located Data Center)里运行集群,但后续迁移到了 AWS 云,以便在新机器宕机时能赢得时间,使得我们在扩容和缩容时更加弹性。
我们在不同的可用区运行 3 个候选 master 节点,并设置 discovery.zen.minimum_master_nodes 为 2。这是避免脑裂问题 split-brain problem 非常通用的策略。
我们的数据集在存储方面,要求 80% 容量和 3 个以上的副本,这使得我们运行了 430 个数据节点。起初打算使用不同层级的数据,在较慢的磁盘上存储较旧的数据,但是由于我们只有相关的较低量级旧于 15 个月的数据(只有编辑数据,因为我们丢弃了旧的社交数据),然而这并未奏效。每个月的硬件开销远大于运行在 COLO 中,但是云服务支持扩容集群到 2 倍,而几乎不用花费多少时间。
你可能会问,为何选择自己管理维护 ES 集群。其实我们考虑过托管方案,但最后还是选择自己安装,理由是: AWS Elasticsearch Service 暴露给用户的可控性太差了, Elastic Cloud 的成本比直接在 EC2 上运行集群要高 2-3 倍。
为了在某个可用区宕机时保护我们自身,节点分散于 eu-west-1 的所有 3 个可用区。我们使用 AWS plugin 来完成该项配置。它提供了一个叫做 aws_availability_zone 的节点属性,我们把 cluster.routing.allocation.awareness.attributes 设置为 aws_availability_zone。这保证了 ES 的副本尽可能地存储在不同的可用区,而查询尽可能被路由到相同可用区的节点。
这些实例运行的是 Amazon Linux,临时挂载为 ext4,有约 64GB 的内存。我们分配了 26GB 用于 ES 节点的堆内存,剩下的用于磁盘缓存。为何是 26GB?因为 JVM 是在一个黑魔法之上构建的。
我们同时使用 Terraform 自动扩容组来提供实例,并使用 Puppet 完成一切安装配置。
因为我们的数据和查询都是基于时间序列的,所以使用了 time-based indexing,类似于 ELK (elasticsearch, logstash, kibana) stack。同时也让不同类型的数据保存在不同的索引库中,以便诸如社论文档和社交文档类数据最终位于不同的每日索引库中。这样可以在需要的时候只丢弃社交索引,并增加一些查询优化。每个日索引运行在两个分片中的一个。
该项设置产生了大量的分片(接近 40k)。有了这么多的分片和节点,集群操作有时变得更特殊。比如,删除索引似乎成为集群 master 的能力瓶颈,它需要把集群状态信息推送给所有节点。我们的集群状态数据约 100 MB,但通过 TCP 压缩可减少到 3 MB(可以通过 curl localhost:9200/_cluster/state/_all 查看你自己集群的状态数据)。Master 节点仍然需要在每次变更时推送 1.3 GB 数据(430 节点 x 3 MB 状态大小)。除了这 1.3 GB 数据外,还有约 860 MB 必须在可用区(比如 最基本的通过公共互联网)之间传输。这会比较耗时,尤其是在删除数百个索引时。我们希望新版本的 Elasticsearch 能优化这一点,首先从 ES 2.0 支持仅发送集群状态的差分数据这一特性开始。
如前所述,我们的 ES 集群为了满足客户的检索需求,需要处理一些非常复杂的查询。
为应对查询负载,过去几年我们在性能方面做了大量的工作。我们必须尝试公平分享 ES 集群的性能测试,从下列引文就可以看出。
不幸的是,当集群宕机的时候,不到三分之一的查询能成功完成。我们相信测试本身导致了集群宕机。—— 摘录自使用真实查询在新 ES 集群平台上的第一次性能测试
为了控制查询执行过程,我们开发了一个插件,实现了一系列自定义查询类型。通过使用这些查询类型来提供 Elasticsearch 官方版本不支持的功能和性能优化。比如,我们实现了 phrases 中的 wildcard 查询,支持在 SpanNear 查询中执行;另一个优化是支持“*”代替 match-all-query;还有其他一系列特性。
Elasticsearch 和 Lucene 的性能高度依赖于具体的查询和数据,没有银弹。即便如此,仍可给出一些从基础到进阶的参考:
限制你的检索范围,仅涉及相关数据。比如,对于每日索引库,只按相关日期范围检索。对于检索范围中间的索引,避免使用范围查询 / 过滤器。
使用 wildcards 时忽略前缀 wildcards- 除非你能对 term 建立倒排索引。双端 wildcards 难以优化。
关注资源消耗的相关迹象 数据节点的 CPU 占用持续飙高吗?IQ 等待走高吗?看看 GC 统计。这些可以从 profilers 工具或者通过 JMX 代理获得。如果 ParNewGC 消耗了超过 15% 的时间,去检查下内存日志。如果有任何的 SerialGC 停顿,你可能真的遇到问题了。
如果遇到垃圾回收问题,请不要尝试调整 GC 设置。 这一点经常发生,因为默认设置已经很合理了。相反,应该聚焦在减少内存分配上。具体怎么做?参考下文。
如果遇到内存问题,但没有时间解决,可考虑下 Azul Zing。这是一个很贵的产品,但仅仅使用它们的 JVM 就可以提升 2 倍的吞吐量。不过最终我们并没有使用它,因为我们无法证明物有所值。
考虑使用缓存,包括 Elasticsearch 外缓存和 Lucene 级别的缓存。在 Elasticsearch 1.X 中可以通过使用 filter 来控制缓存。之后的版本中看起来更难一些,但貌似可以实现自己用于缓存的查询类型。我们在未来升级到 2.X 的时候可能会做类似的工作。
查看是否有热点数据(比如某个节点承担了所有的负载)。可以尝试均衡负载,使用分片分配过滤策略 shard allocation filtering,或者尝试通过集群重新路由 cluster rerouting 来自行迁移分片。我们已经使用线性优化自动重新路由,但使用简单的自动化策略也大有帮助。
搭建测试环境(我更喜欢笔记本)可从线上环境加载一部分代表性的数据(建议至少有一个分片)。使用线上的查询回放加压(较难)。使用本地设置来测试请求的资源消耗。
综合以上各点,在 Elasticsearch 进程上启用一个 profiler。这是本列表中最重要的一条。我们同时通过 Java Mission Control 和 VisualVM 使用飞行记录器。在性能问题上尝试投机(包括付费顾问 / 技术支持)的人是在浪费他们(以及你自己)的时间。排查下 JVM 哪部分消耗了时间和内存,然后探索下 Elasticsearch/Lucene 源代码,检查是哪部分代码在执行或者分配内存。
一旦搞清楚是请求的哪一部分导致了响应变慢,你就可以通过尝试修改请求来优化(比如,修改 term 聚合的执行提示,或者切换查询类型)。修改查询类型或者查询顺序,可以有较大影响。如果不奏效,还可以尝试优化 ES/Lucene 代码。这看起来太夸张,却可以为我们降低 3 到 4 倍的 CPU 消耗和 4 到 8 倍的内存使用。某些修改很细微(比如 indices query),但其他人可能要求我们完全重写查询执行。最终的代码严重依赖于我们的查询模式,所以可能适合也可能不适合他人使用。 - 除非你能对 term 建立倒排索引。双端 wildcards 难以优化。
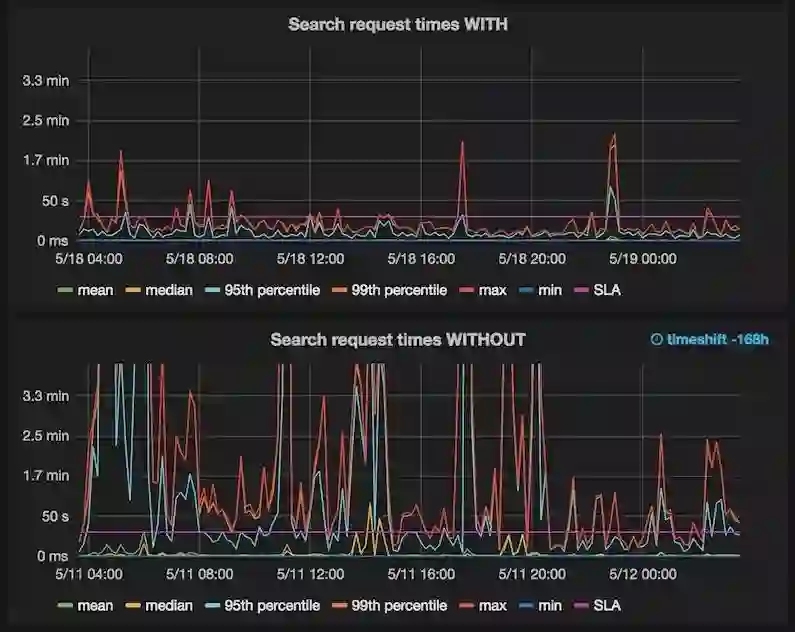
图表说明:响应时间。有 / 没有 重写 Lucene 查询执行。同时也表明不再有节点每天发生多次内存不足的情况。
顺便说明下,因为我知道会面临一个问题:从上一次性能测试我们知道通过升级到 ES 2.X 能小幅提升性能,但是并不能改变什么。话虽如此,但如果你已经从 ES 1.X 集群迁移到了 ES 2.X,我们很乐意听取关于你如何完成迁移的实践经验。
如果读到了这里,说明你对 Elasticsearch 是真爱啊(或者至少你是真的需要它)。
英文原文链接:http://underthehood.meltwater.com/blog/2018/02/06/running-a-400+-node-es-cluster/
活动推荐
在新技术落地的过程中,如何进一步降低运维的成本,让部署更加便捷?解决方案千万种,如何找到最适合自己业务的方案极其重要。2019 年 5 月 6-8 日,QCon 与您相约北京国际会议中心,关注运维领域最佳落地实践。点击 「 阅读原文 」或识别二维码了解 QCon 十周年精心策划,现在购票即享 8 折限时折扣,立减 1760 元,团购还有更多优惠!有任何问题欢迎联系票务小姐姐 Ring:电话 010-53935761,微信 qcon-0410






