手把手教你用Python 和 Scikit-learn 实现垃圾邮件过滤

欢迎大家参与在留言区交流
本周内(截止至7月23日晚24点)
本公众号本周发布的所有文章,留言获赞最多者
AI研习社送西瓜书
AI 研习社按:本文原文来自一篇国外大神的博客,由雷锋网字幕组 彭艳蕾、林立宏 两位组员共同编译完成,转载请注明出处。
文本挖掘(Text Mining,从文字中获取信息)是一个比较宽泛的概念,这一技术在如今每天都有海量文本数据生成的时代越来越受到关注。目前,在机器学习模型的帮助下,包括情绪分析,文件分类,话题分类,文本总结,机器翻译等在内的诸多文本挖掘应用都已经实现了自动化。
在这些应用中,垃圾邮件过滤算是初学者实践文件分类的一个很不错的开始,例如 Gmail 账户里的“垃圾邮箱”就是一个垃圾邮件过滤的现实应用。下面我们将基于一份公开的邮件数据集 Ling-spam,编写一个垃圾邮件的过滤器。Ling-spam 数据集的下载地址如下:
http://t.cn/RKQBl9c
这里我们已经从 Ling-spam 中提取了相同数量的垃圾邮件和非垃圾邮件,具体下载地址如下:
http://t.cn/RKQBkRu
下面我们将通过以下几个步骤,编写一个现实可用的垃圾邮件过滤器。
1. 准备文本数据;
2. 创建词典(word dictionary);
3. 特征提取;
4. 训练分类器。
最后,我们会通过一个测试数据集对过滤器进行验证。
1. 准备文本数据
这里我们将数据集分成了训练集(702封邮件)和测试集(260封邮件)两部分,其中垃圾和非垃圾邮件各占 50%。这里因为每个垃圾邮件的数据集都以 spmsg 命名,因此很容易区分。
在大部分的文本挖掘问题中,文本清理都是第一步,即首先要清理掉那些与我们的目标信息无关的词句,本例中也一样。通常邮件里一般都会包含很多无用的字符,比如标点符号,停用词,数字等等,这些字符对检测垃圾邮件没什么帮助,因此我们需要将它们清理掉。这里 Ling-spam 数据集里的邮件已经经过了以下几个步骤的处理:
a) 清除停用词 --- 像 "and", "the", "of" 等这些停用词在英语语句中非常常见。然而,这些停用词对于判定邮件的真实身份并没有什么卵用,所以这些词已经从邮件中被移除。
b) 词形还原 --- 这是一种把同一个词的不同形式组合在一起,以便被当做一个单独项目来分析的过程。举个栗子,"include", "includes" 和 "included" 就可以全部用 "include" 来代表。与此同时,语句的上下文含义也会通过词形还原的方法保留下来,这一点不同于词干提取 (stemming) 的方法(注:词干提取是另一种文本挖掘的方法,此法不考虑语句的含义)。
此外,我们还需要移除一些非文字类的符号(non-words),比如标点符号或者特殊字符之类的。要实现这一步有很多方法,这里,我们将首先创建一个词典(creating a dictionary),之后再移除这些非文字类的符号。需要指出的是,这种做法其实非常方便,因为当你手上有了一个词典之后,对于每一种非文字类符号,只需要移除一次就 ok 了。
2. 创建词典(Creating word dictionary)
一个数据集里的样本邮件一般长这样:
Subject: posting
hi , ' m work phonetics project modern irish ' m hard source . anyone recommend book article english ? ' , specifically interest palatal ( slender ) consonant , work helpful too . thank ! laurel sutton ( sutton @ garnet . berkeley . edu
你会发现邮件的第一行是标题,从第三行开始才是正文。这里我们只在邮件正文内容的基础上做文本分析,来判定该邮件是否为垃圾邮件。第一步,我们需要创建一个文字的词典和文字出现的频率。为了创建这样一个“词典”,这里我们利用了训练集里的 700 封邮件。具体实现详见下面这个 Python 函数:
def make_Dictionary(train_dir):
emails = [os.path.join(train_dir,f) for f in os.listdir(train_dir)]
all_words = []
for mail in emails:
with open(mail) as m:
for i,line in enumerate(m):
if i == 2: #Body of email is only 3rd line of text file
words = line.split()
all_words += words
dictionary = Counter(all_words)
# Paste code for non-word removal here(code snippet is given below)
return dictionary
词典创建好之后,我们只要在上面函数的基础上再加几行代码,就可以移除之前提到的那些非文字类符号了。这里我还顺手删掉了一些与垃圾邮件的判定无关的单字符,具体参见如下的代码,注意这些代码要附在 def make_Dictionary(train_dir) 函数的末尾。
list_to_remove = dictionary.keys()
for item in list_to_remove:
if item.isalpha() == False:
del dictionary[item]
elif len(item) == 1:
del dictionary[item]
dictionary = dictionary.most_common(3000)
这里通过输入 print dictionary 指令就可以输出词典。需要注意的是,你在打印输出的词典里可能会看到许多无关紧要的词,这一点无需担心,因为我们在后续的步骤中总是有机会对其进行调整的。另外,如果你是严格按照上文提到的数据集操作的话,那么你的词典里应该会有以下这些高频词(本例中我们选取了频率最高的 3000 个词):
[('order', 1414), ('address', 1293), ('report', 1216), ('mail', 1127), ('send', 1079), ('language', 1072), ('email', 1051), ('program', 1001), ('our', 987), ('list', 935), ('one', 917), ('name', 878), ('receive', 826), ('money', 788), ('free', 762)
3. 特征提取
词典准备好之后,我们就可以对训练集里的每一封邮件提取维度是 3000 的词数向量 word count vector(这个向量就是我们的特征),每一个词数向量都包含之前选定的 3000 个高频词具体的出现频率。当然,你可能猜到了,大部分出现的频率应该会是 0。举个栗子:比如我们字典里有 500 个词,每个词数向量包含了训练集里这 500 个词的出现频率。假设训练集有一组文本:“Get the work done, work done”。那么,这句话对应的词数向量应该是这样的:[0,0,0,0,0,…….0,0,2,0,0,0,……,0,0,1,0,0,…0,0,1,0,0,……2,0,0,0,0,0]。在这里,句中的每个词出现的频率都能显示出来:这些词分别对应长度为 500 的词数向量中的第 296,359,415 和 495 的位置,其他位置显示为 0。
下面这个 python 函数会帮助我们生成一个特征向量矩阵,该矩阵有 700 行 3000 列。其中每一行代表训练集中 700 封邮件的的每一封邮件,每一列代表词典中的 3000 个关键词。在 “ij” 位置上的值代表了词典中第 j 个词在该邮件(第 i 封)中出现的次数。
def extract_features(mail_dir):
files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)]
features_matrix = np.zeros((len(files),3000))
docID = 0;
for fil in files:
with open(fil) as fi:
for i,line in enumerate(fi):
if i == 2:
words = line.split()
for word in words:
wordID = 0
for i,d in enumerate(dictionary):
if d[0] == word:
wordID = i
features_matrix[docID,wordID] = words.count(word)
docID = docID + 1
return features_matrix
4.训练分类器
在这里我们会使用 scikit-learn 机器学习库来训练分类器,scikit-learn 库的相关链接如下:
http://t.cn/SMzAoZ
这是一个绑定在第三方 python 发行版 Anaconda 的开源机器学习库,可以跟随 Anaconda 一同下载安装,或者也可以按照以下链接中的提示独立安装:
http://t.cn/8kkrVlQ
安装好了之后,我们只需要将其 import 到我们的程序中就可以使用了。
这里我们训练了两个模型,分别是朴素贝叶斯分类器和 SVM(支持向量机)。朴素贝叶斯分类器是一个传统的监督型概率分类器,在文本分类的场景中非常常用,它基于贝叶斯定理,假设每一对特征都是相互独立的。SVM 是监督型的二分类器,面对特征数量较多的场景时非常有效,其最终目标是从训练数据中分离出一组子集,称为支持向量(分离超平面的边界)。判定测试数据最终类别的 SVM 决策函数正是基于该支持向量和内核技巧(kernel trick)的。
分类器训练完成后,我们可以在测试集上测试模型的性能。这里我们为测试集中的每封邮件提取字数向量,然后用训练好的朴素贝叶斯分类器和 SVM 模型,预测它的类别(普通邮件或垃圾邮件)。下面是垃圾邮件分类器的完整 python 代码,另外还需要包含我们在步骤 2 和步骤 3 中定义的两个函数。
import os
import numpy as np
from collections import Counter
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.svm import SVC, NuSVC, LinearSVC
from sklearn.metrics import confusion_matrix
# Create a dictionary of words with its frequency
train_dir = 'train-mails'
dictionary = make_Dictionary(train_dir)
# Prepare feature vectors per training mail and its labels
train_labels = np.zeros(702)
train_labels[351:701] = 1
train_matrix = extract_features(train_dir)
# Training SVM and Naive bayes classifier
model1 = MultinomialNB()
model2 = LinearSVC()
model1.fit(train_matrix,train_labels)
model2.fit(train_matrix,train_labels)
# Test the unseen mails for Spam
test_dir = 'test-mails'
test_matrix = extract_features(test_dir)
test_labels = np.zeros(260)
test_labels[130:260] = 1
result1 = model1.predict(test_matrix)
result2 = model2.predict(test_matrix)
print confusion_matrix(test_labels,result1)
print confusion_matrix(test_labels,result2)
性能测试
这里我们的测试集中包含 130 封垃圾邮件和 130 封非垃圾邮件,如果你已经顺利完成了之前的所有步骤,那么你将会得到如下的结果。这里显示的是两个模型在测试数据中的混淆矩阵,对角元素代表了正确识别的邮件数,非对角元素代表的则是错误的分类。
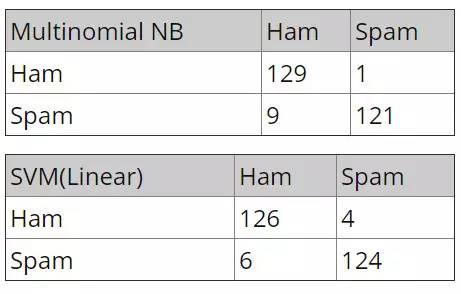
可以看到,两个模型在测试集上有着相近的性能,但 SVM 更倾向垃圾邮件的判定。需要注意的是,这里的测试数据集既没有用于创建字典,也没有用于模型训练。
拓展
感兴趣的朋友可以按照上文所述的步骤进行一些拓展,这里介绍拓展相关的数据库和结果。
拓展使用的是已经预处理好的 Euron-spam 数据库,其中包含了 6 个目录,33716 封邮件,每个目录中都包含非垃圾邮件和垃圾邮件子目录,非垃圾邮件和垃圾邮件的总数分别为 16545 封和 17171 封。Euron-spam 库的下载链接如下:
http://t.cn/RK84mv6
需要注意的是,由于 Euron-spam 数据库的组织形式有别于上文提到的 ling-spam 库,因此上文的一些函数也需要做少量的修改才能应用于 Euron-spam。
这里我们将 Euron-spam 数据库按照 3:2 的比例分为训练集和测试集,按照上文的步骤,我们在 13478 封测试邮件中得到了如下结果:
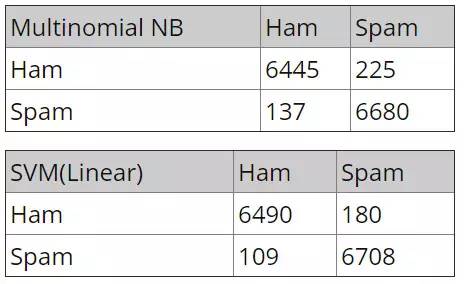
可以看到,SVM 的表现略胜于朴素贝叶斯。
总结
在本文中我们尽量保持简单易懂的叙述,省略了许多技术性强的讲解和名词。我们希望这是一篇简单易懂的教程,希望这篇教程可以对文本分析感兴趣的初学者们有所裨益。
有些朋友可能会对朴素贝叶斯模型和 SVM 模型背后的数学原理感到好奇,这里需要指出的是,SVM 在数学上属于比较复杂的模型,而朴素贝叶斯则相对更容易理解一些。我们当然鼓励对数学原理感兴趣的朋友们深入探索,关于这些数学模型网上有非常详细的教程和实例。除此之外,采用不同的方式实现同一个目标,也是一种很好的研究方法。例如可以调节如下一些参数,观察它们对垃圾邮件过滤的实际效果的影响:
a) 训练数据的大小
b) 词典的大小
c) 不同的机器学习模型,包括 GaussianNB,BernoulliNB,SVC
d) 不同的 SVM 模型参数
e) 删除无关紧要的词来改进词典 (例如手动删除)
f) 采用其他特征模型 (寻找 td-idf)
最后,博客中提到的完整 python 代码详见如下链接:
http://t.cn/R6ZeuiN
若有问题,欢迎在文末留言讨论。
福利
关注 AI 研习社(okweiwu)
回复「1」立即领取
【超过 1000G 神经网络/AI/大数据、教程、论文!】
推荐阅读
《手把手教你如何用 Python 做情感分析》
话题讨论
有没有要去CVPR的朋友?
在评论区留言我们一起面基啊!
欢迎在评论区分享
↓↓↓




