【NLP】信息抽取
来自:CS的陋室
这篇同样是课程的系列笔记(深蓝学院)。上一节讲的观点分析,即分析某个人对某件事情的评价,好坏,怎么好或者怎么坏,但是问题来了,我们如何识别这些人评价的具体是什么内容呢,举一个类似的问题,如何从海量新闻中识别最近股市大跌,如何识别最近的冬奥会,以快速应对这些大事件带来的影响呢,这就是所谓的信息抽取。
根据老师的讲解,信息抽取主要分为命名实体识别、关系抽取、实体消歧等。
信息抽取的定义
从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术,即Making information more machine-readable,换成更方便及其识别的形式,以进行后续的研究。
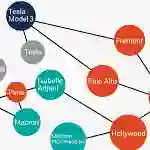
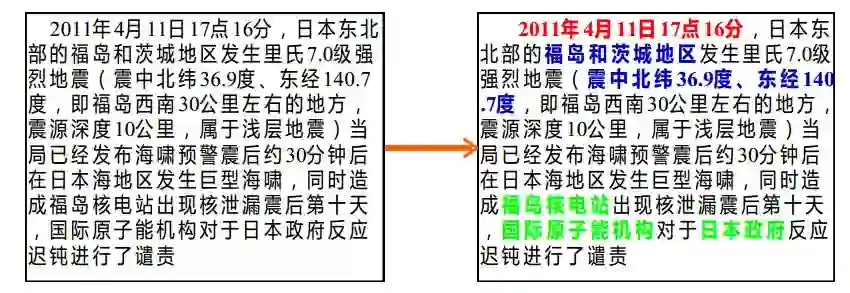
下面是一个例子,从2011年的7级地震,相信不少人还记忆犹新,尤其是他的福岛核电站,那些年我们还抢过紫菜来着对吧。将一条新闻中的重点信息进行抽取和结构化,形成下面的形式,就是信息抽取。

命名实体识别
按照老师的讲解,命名实体识别的任务主要由下面的两块内容来解释,核心是把“是什么”找出来。
识别出待处理文本中七类(人名、 机构名、 地名、 时间、 日期、 货币和百分比) 命名实体,
两个子任务:实体边界识别和确定实体类别
看起来比较简单,但是实际上并非如此,有很多“边缘”问题其实并不简单,有些识别的难度比较大,例如同义词,人名和别称,杜甫,杜子美,子美,杜工部,指的同一个人;有些词还有很丰富的含义,例如“苹果”,指的手机还是水果,就不好说。命名实体识别的主要方法其实比较统一,就是通过语境和语言与法特征进行抽取,同时一些比较常用的概率统计方法已经被大量使用,如MEMM,HMM,CRF等。
按照惯例放论文供参考,偏综述和对比,都是一些已经比较好的方法,虽然比较老。
[1] 吴友政. 问答系统关键技术研究. 中国科学院自动化研究所博士论文. 2006.
[2] Gina-Anne Levow. The Third International Chinese Language Processing Backoff: Word Segmentation and Name Entity Recognition [C]. Proceedings of the Fifth SigHAN Workshop on Chinese Language Processing, Sydney: Association for Computational Linguistics, 2006: 108-117.
关系抽取
关系抽取是命名实体识别的更进一步。Alexander Schutz等人认为关系抽取是自动识别由一对概念和联系这对概念的关系构成的相关三元组(A怎么了B)。
目前的主要方法主要是机器学习的方法,将关系实例转换成高维空间中的特征向量或直接用离散结构来表示,在标注语料库上训练生成分类模型,然后再识别实体间关系。基于特征向量的方法主要考虑如何获取各种有效的词法、语法、语义等特征,并把它们有效地集成起来,从而产生描述实体语义关系的各种局部特征和简单的全局特征,而核函数的方法主要考虑如何有效挖掘反映语义关系的结构化信息及如何有效计算结构化信息之间的相似度。其优缺点如下图所示。

按照惯例放论文供参考。
[1] GuoDong Zhou, Jian Su, Jie Zhang, and Min Zhang. 2005. Exploring various knowledge in relation extraction. In Proceedings of ACL.
实体消歧
这是目前这一块最难的部分。命名实体的歧义指的是一个实体指称项可对应到多个真实世界实体,例如苹果是指一种水果还是出IPhone的公司,还有很多同名的人,这是一个做非常头疼的问题。常见的方法有两种,一个是基于聚类方法的,另一个是基于实体链接的。

基于聚类的方法认为,统一指向应该有类似的上下文,“苹果”指公司的时候上下文应该是和这家公司有关,于是用聚类其实更加合适,结合词袋模型、语义特征、社交网络等就有比较好的结果。基于实体链接的方法则主要采用这种知识库作为支持的方案,将内容链接到知识库中,首先用前面的方法发现实体,然后将实体放在知识库中搜索,找到最为相似的特征进行匹配,得到最终结果。基于聚类的方法对基础工作(即知识库)的要求并不是很高,但是问题在于对知识库没有的内容会比较乏力,因此两者经常会一同使用,同时具有较好的结果。
按照惯例放论文供参考。
[1] Han, X. & Zhao, J. 2009. Named entity disambiguation by leveraging Wikipedia semantic knowledge. Proceeding of the 18th ACM conference on Information and knowledge management, pp. 215-224.
[2] Han, X. & Zhao, J. 2010. Structural Semantic Relatedness: A Knowledge-Based Method to Named Entity Disambiguation. Proceeding of ACL, pp. 50-59.
[3] XP.Han and L.Sun. A Generative Entity-Mention Model for Linking Entities with Knowledge Base. In Proceeding of ACL. 2011
问题与挑战
封闭走向开放
尽可能突破语料的领域性限制
互联网提供大量的语料,可以加以利用
信息抽取和识别相结合
鲁棒性要求更高
句法分析技术的支持
实体识别技术的进一步革新
大规模信息抽取
海量信息的获取,技术和理论方法
应对信息的低质量问题
深层语义信息
语言的丰富性导致很多内容的浅层理解会有很大误差
知识库的依赖
知识库确实能提升信息抽取的准确性,这要求知识库需要很高的可靠性
说到这里,这是根据课程内容总结的,对自己的理解有很大的补充,但是有一些细节之处不敢苟同,而且这篇文章也很泛泛,我会在未来慢慢展开,敬请期待,拖更这么久,别打我。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!