CVPR 2018 中国论文分享会之 「GAN 与合成」

GAN and Synthesis
AI 科技评论按:2018 年 5 月 11 日,由微软亚洲研究院、清华大学媒体与网络技术教育部-微软重点实验室、商汤科技、中国计算机学会计算机视觉专委会、中国图象图形学会视觉大数据专委会合作举办了 CVPR 2018 中国论文宣讲研讨会,数十位 CVPR 2018 收录论文的作者在此论坛中分享其最新研究和技术观点。研讨会共包含了 6 个 session(共 22 个报告),1 个论坛,以及 20 多个 posters,AI 科技评论将为您详细报道。
AI科技评论注:全球计算机视觉顶级会议 IEEE CVPR 2018 将于 6 月 18 - 22 日在美国盐湖城召开。据 CVPR 官网显示,今年大会有超过 3300 篇论文投稿,其中录取 979 篇;相比去年 783 篇论文,今年增长了近 25%。
更多报道请参看:
Session 1:GAN and Synthesis
Session 2: Deep Learning
Session 3: Person Re-Identification and Tracking
Session 4: Vision and Language
Session 5: Segmentation, Detection
Session 6: Human, Face and 3D Shape
本文为 Session 1,报告论文主要以使用 GAN 方法和生成方法为主,共有四场论文报道。
在第一个报告中,北京大学刘家瑛副教授介绍他们团队使用 Attentive GAN 从单幅图像中去除雨滴的工作;第二个报告由来自中科院自动化所的胡一博博士介绍他们通过 CAPG-GAN 算法实现人脸旋转任意角度的工作;随后是由北京大学连宙辉副教授介绍了他们提出的交互式纹理变换的通用框架;最后由来自微软亚洲研究院的傅建龙研究员介绍了他们提出的基于instance-level的 DA-GAN(深度注意生成对抗网络),该网络在图像到图像翻译中能够实现更精细的生成结果。
1、如何从单张图片中去除雨滴?
论文:
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image
报告人:刘家瑛,北京大学
论文下载地址:
https://arxiv.org/abs/1711.10098
去除图片中的雨痕,一般有四种情景,如下图所示,分别为:落下的雨滴(Rain Drop 1),落在镜头上的雨滴(Rain Drop 2),雨线(Rain Streak),以及雨雾(Mist)。

刘家瑛团队在去年 CVPR 中曾发表过一篇关于去除雨痕的文章《Deep Joint Rain Detection and Removal From A Singal Image》,在这篇论文中他们主要研究如何去除图片中的雨线。但在无人驾驶或相关研究中,更具挑战性的一个任务是如何去除落在玻璃或者镜头上的雨滴。刘家瑛在本次分享会上介绍了她所指导的北大大二学生 Rui Qian 所做的该方面工作,也即去除单张图片上随机散布的雨滴(Rain Drop 2)。
在此之前仅有的一篇类似研究,是由 David Eigen 等人发表在 ICCV 2013 的一篇文章,在这篇文章中由于作者只使用了 3 层卷积网络,所以只能处理很少的 case,同时能够处理的图片上的雨滴也非常小,基本上可以视为灰尘。
在刘家瑛所分享的这篇文章中,其思路仍然延续去年文章的方法,即生成数据集,然后用生成的数据集来训练模型。
1、数据集生成
数据集的生成方式是,本文作者 Rui Qian 使用单反+一个 3 毫米厚的玻璃片(或者直接把水喷在镜头上)收集了 1000 多对(有雨和无雨)在不同户外环境、不同背景、不同尺寸和形状的雨滴图像,以模拟真实环境中雨滴的多样性。使用一个数学公式来表达带有雨滴图像的话,如图中公式所示:

2、模型框架
在该论文中作者选择使用 GAN 的方法,整个模型的框架如下图所示:
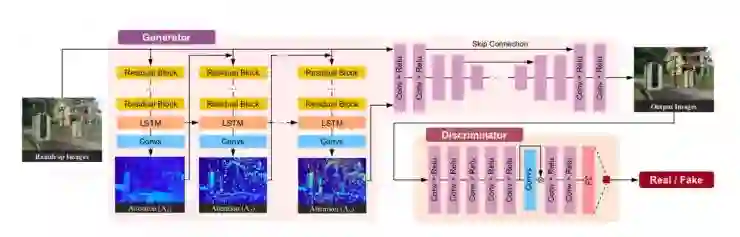
共包含三个部分,分别为:Generator(Attention-recurrent Network),Context Autoencoder 和 Dicriminator Network。
第一部分主要的工作是做检测(即检测雨滴在图片中的位置),然后生成 attention map。首先使用 Residual block 从雨滴图片中抽取 feature,渐进式地使用 Convs 来检测 attentive 的区域。训练数据集中图片都是成对的,所以可以很容易计算出相应的 mask(M),由此可以构建出 Loss 函数;由于不同的 attention 网络刻画 feature 的准确度不同,所以给每个 loss 一个指数的衰减。相应的 loss 函数如下:
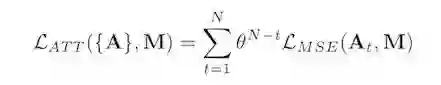
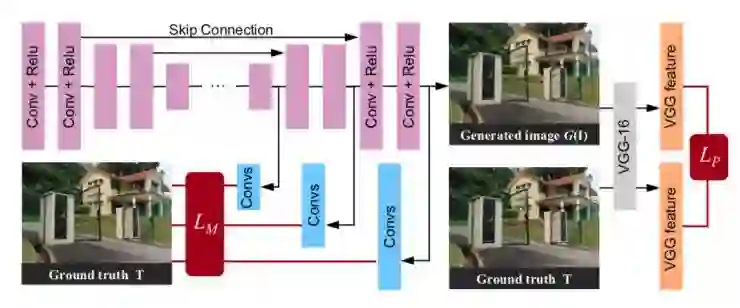
随后将 attention map 和雨滴图像一起送给 autoencoder,生成去雨滴图像。autoencoder 的结构用了 16 个 Conv 和 Relu。为了避免网络本身造成的 blur,作者使用了 skip connection,因为在低级层次这会带来很好的效果。在构建 loss 方面,除了多尺度的考虑,还加上了一个高精度的 loss,即:Multi-scale loss + perceptual loss。
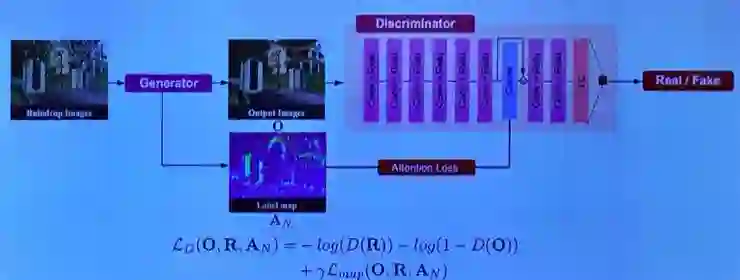
最后一个是 discriminator。这个步骤有两种方式,一种是只使用 autoencoder 生成的无雨滴图像,进行判断;另一种则是加入 attention map 作为指导。如图所示:
3、实验结果
作者使用两个数据集(PSNR 和 SSIM)进行了验证,其中 PSNR 是他们自己收集的数据集。作者选用 Eigen 等人 2013 年发表的工作以及 Pix2Pix 的方法作为对比。结果如下:
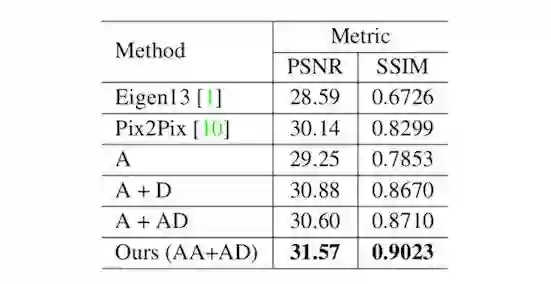
其中 A 表示只有 Autoencoder,A+D 表示 Autoencoder+Discriminator,A+AD 表示 Autoencoder + Attention Discriminator,AA + AD 表示 Attention Autoencoder + Attention Discriminator。
实际去雨效果如图所示:


2、如何旋转图像中的人脸?
论文:
Pose-Guided Photorealistic Face Rotation
报告人:胡一博,中科院自动化所
论文下载地址:暂无
对于如何将图像中的人脸旋转任意角度,例如从一张正脸图像生成侧脸图像,或反之从侧脸恢复其正脸图像,无论是学术界还是工业界都给予了很大的关注,因为这可以用于人脸编辑、姿态变换、数据增强、表示学习等当中。
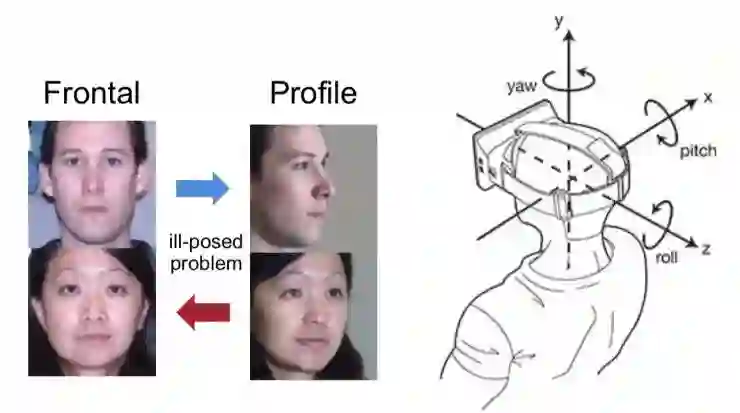
视角旋转有 x、y、z 三个方向,目前研究中主要考虑左右偏转。如果从单张图像进行旋转的话,这其实是一种「无中生有」、一对多的病态问题。因此目前人脸旋转存在真实性不高、分辨率较低、身份信息保持较差的问题。
胡一博在介绍他们的工作之前,简单介绍了人脸旋转研究的历程,如下图所示:

1、启发
从 2015 年的 CVPR 论文开始,人脸识别逐渐引起广泛的关注。目前人脸识别主要分成两个部分,一个是人脸正面化,一个是水平方向的任意角度旋转。之所以将人脸正面化作为一个单独的部分,是因为人脸正面化的过程中可以引入「对称性」的强约束,从而降低一对多问题的困难。
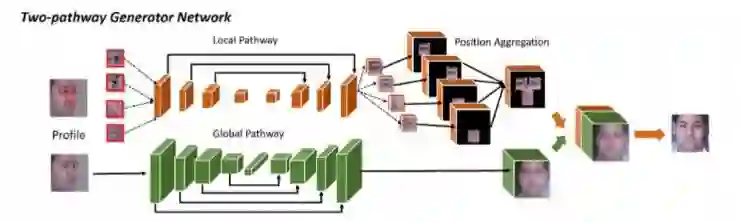
其中的 TP-GAN 是人脸正面化中一个里程碑式的工作,这种方法出现之后使得人脸转正能够达到以假乱真的效果。TP-GAN 之所以能够这么有效是因为,它通过一条全局通路和 4 个局部通路(分别对应人的五官),最终让局部和全局的通路进行融合。但是这种方法有两点不足:1)它受限于最慢通路的约束存在一定的性能瓶颈;2)只适用于人脸正面化的问题中,而不能应用于更广泛的人脸旋转中。针对这两个问题,胡一博认为我们需要提升其网咯性能以及实现任意姿态的人脸旋转。
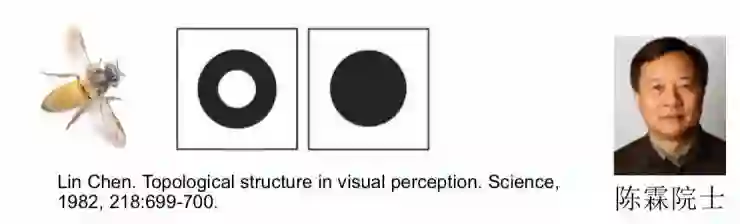
另一方面,全局优先拓扑感知理论指出生物视觉系统对全局拓扑结构非常敏感。人脸五官包含着很丰富的全局拓扑信息,因此以人脸全局拓扑信息作为一个条件指导整个人脸的过程。
2、模型
基于上面两方面的启发,胡一博等人提出了 CAPG-GAN 的方法,该方法能够进行二维空间中任意角度的人脸旋转。选择人脸全局拓扑信息作为条件有两个优势,首先它可以提供人脸的结构信息促使生成的图像更加的逼真,其次在判别器中它可以作为先验知识,可以提高判别器对于人脸结构的判别性,进而促使生成器生成分辨率较高的图像。CAPG-GAN 的结构图如下:
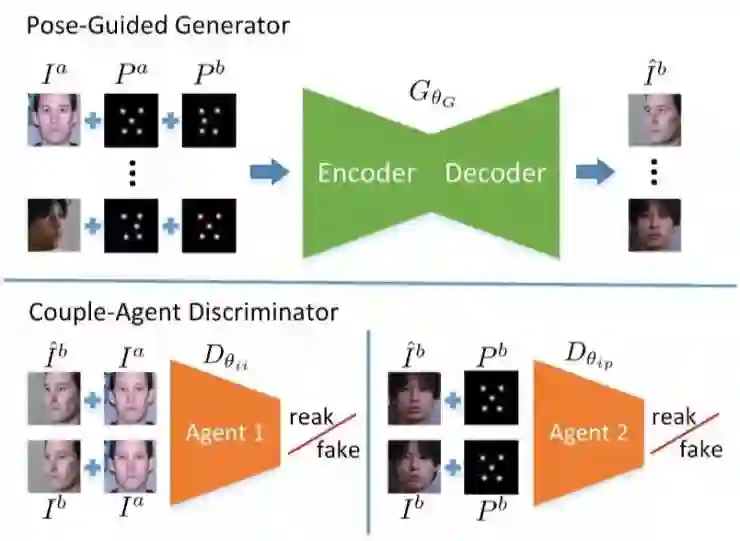
输入包括原始图像 I^a,原始图像的五个关键点 P^a,以及目标姿态的关键点 P^b,通过生成器 G 输出目标图像。判别器采用的是 couple-agent 的结构,本质上就是两个独立的判别器,agent 1 判别旋转角度的真实性,agent 2 判断的是拓扑结构的真实性。
针对两个 agent,对应的损失函数如下图所示:

3、实验对比
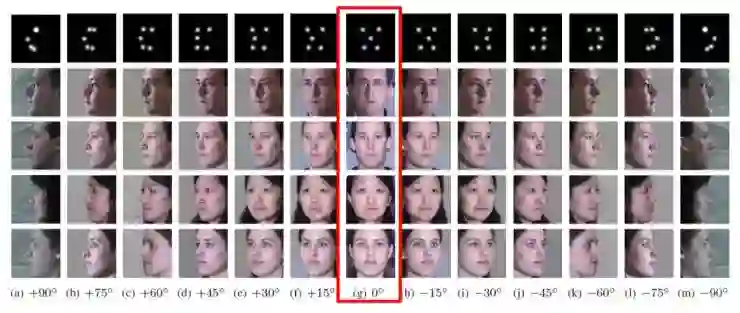
胡一博团队针对人脸正面化以及旋转任意角度的任务在多种数据集上进行实验验证,其结果表现优异。效果如下:
相关文章:
[1]中科院自动化所赫然:大规模人脸图像编辑理论、方法及应用
[2] 中科院自动化所智能感知与计算研究中心11篇论文被CVPR接收 | CVPR 2018
3、如何给字体添加多样风格?
论文:
A Common Framework for Interactive Texture Transfer
报告人:连宙辉,北京大学
论文下载地址:
http://www.icst.pku.edu.cn/F/zLian/papers/CVPR18-Men.pdf
研究来源于需求。连宙辉副教授来自北京大学计算机科学技术研究所(该研究所是由)的字形计算技术实验室。传统上,字形设计需要人工对每个字进行手写或者设计,然后输入系统才能够被利用。但是由于中文有大量的汉字,且很多汉字的结构非常复杂,所以这项工作艰难且费时。一种解决方法就是,设计一个特定风格的字,然后通过变换迁移到别的字上。

那么是否可以将任意纹理的图像风格通过变换迁移到一个目标汉字上呢?更广义一点,是否可以将任意纹理风格迁移到任意图像上呢?基于这些思考,连宙辉团队在其论文中提出一种交互式的纹理迁移通用框架。

如上图所示,该通用框架能够:(a)将涂鸦转换为艺术品,(b)编辑装饰模式,(c)生成特殊效果的文本,(d)控制文本中的效果分布图像,(e)交换纹理。
1、方法

纹理迁移的问题其实就是,如何输入原始纹理图像、原始图像的语义图以及目标图像的语义图后,从而输出目标纹理图像。
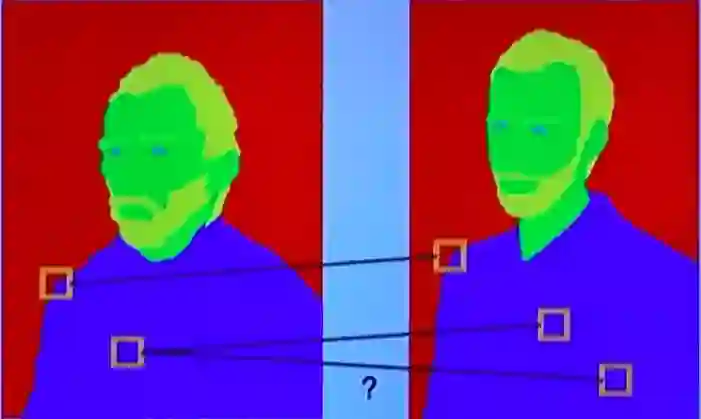
其中较为关键的问题是,如何将两张语义图进行匹配。例如上图中,对于边缘由于有丰富的语义信息指引,因此可以较为容易地进行匹配;但是对于内部大面积的区域(d、e),同一个点有很多地方可以去匹配,作者选择利用从边缘传过来的信息(纹理一致和结构引导)可以实现很好的匹配效果。
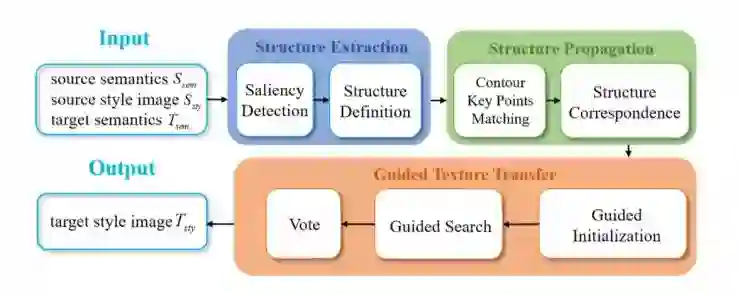
整个流程如上图所示,共分为三大部分 7 个步骤。需要说明的是,基于交互式结构的图像合成是由语义映射和结构信息来指导的,其中用户可以对语义通道进行注释来控制目标图像中风格化纹理的空间分布。在结构提取环节,通过内容感知显着性检测自动提取结构通道,并将其从源样式图像传递到目标。具体而言,传播步骤通过在源图像和目标图像之间的关键轮廓点的配准来获取内部结构对应关系。结合语义和结构信息进行动态指导,可以使转换过程产生具有内容意识和低级细节的高质量纹理。
2、实验结果

3、结论
本文提出了一个结构指导的交互式纹理传递的一般框架。该方法可以自动将样式从给定的源图像迁移到用户控制的目标图像,同时保持结构的完整性和视觉丰富性。更具体地说,作者引入了通过自动提取显著区域和传播结构信息获得的结构指导。通过将结构通道与语义和纹理一致性结合起来,可以实现指导纹理转移。实验结果表明,所提出的框架广泛适用于许多纹理转移挑战。尽管目前大多数模型都倾向于使用基于神经的方法进行样式转换,但本文的结果表明,简单的传统的纹理合成框架仍然可以表现出优异的性能。
4、如何进行更细致的图像到图像翻译?
论文:
DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Network
报告人:傅建龙,微软亚洲研究院
论文下载地址:
https://arxiv.org/abs/1802.06454
本文是另外一篇将 Attention 机制与 GAN 相结合,以生成更高质量目标的工作。
1、启发
傅建龙在报告中认为,CV 中的图像到图像的翻译任务(Image2Image Translation)是一个比较广泛的概念,即根据 source domain 中的图像生成 target domain 中的对偶图像,同时在翻译过程中约束生成的样本和 source 中的样本有尽量一致的分布。事实上有许多基本的 CV 问题都属于图像到图像的翻译问题,例如白天到黑夜的图像转换、黑白照到彩色照的转换、低像素到高像素的转换、去除水印、图像分割、2D 到 3D、梵高风格化、木炭风格、缺失部分复原等。

更高级的如下图这些:

在这所有的任务中,根据是否是一对一的学习对,将这些任务划分为 pair data 任务和 unpair data 任务。(如下图所示)
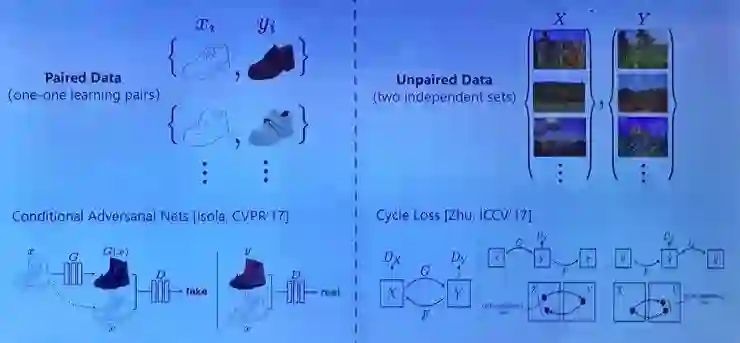
其中前者在训练数据集中具有一对一的数据对,x 作为输入,y 用来计算输出的 loss 函数,目前效果最好的网络是 Pix2Pix 网络;而后者则是两个独立的数据集之间的训练,模型应该能够从两个集合中自动地发现集合之间的关联,从而来学习出映射函数,其中目前效果最好的网络是 CycleGAN 模型。
但是以上这些都是基于图像级的特征学习,若想完成更高质量要求的生成任务(例如要求改变图像区域的风格)则较为困难。于是有人便提出了基于 instance-level 的图像到图像的翻译方法——PatchGAN:
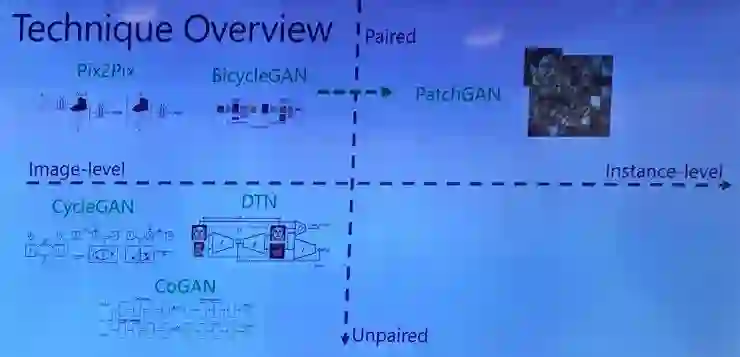
如傅建龙所说,做研究就是要找到前人所没有填补的空缺。通过画出上图,可以很明白地看出,对应的也应该有基于 unpaired instance-level 的图像到图像的翻译方法。这正是本文的工作,即能否自动地发现 source domain 和 target domain 的 instance 之间的关联,同时这是一种 unpair 的方法,不需要任何人类标注。
2、模型
既然是基于 instance-level 的方法,那么首先就要问:什么是 instance?

事实上,这是一个比较宽泛的概念,在不同的任务中可以有不同的定义。例如在生成鸟的任务中,鸟本身是一个 instance,鸟的嘴、腿、翅膀、尾巴等也都可以是 instance;如果想要建立更细致的生成模型,也可更加细致地去定义更多种 instance。
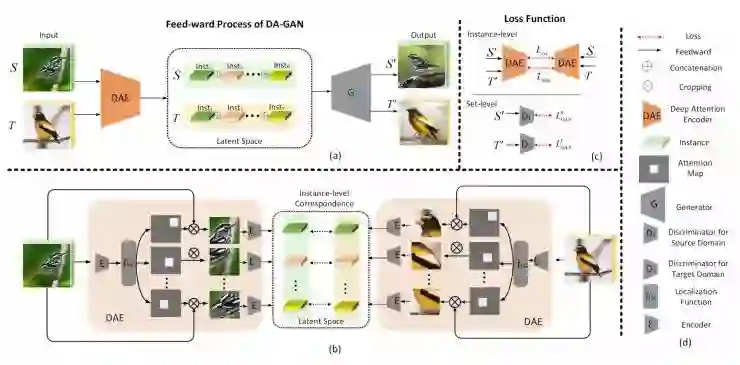
介绍了以上的思路后,模型本身的构建就很清晰了。如上图所示,首先通过一个深度 Attention 编码器(DAE)来自动地学习各个 instance,然后将不同的部分分别投射到一个「隐空间」,最后通过 GAN 网络进行生成。
3、实验结果
定量的比较可以看出,DA-GAN 相比于其他方法有较大的提升。
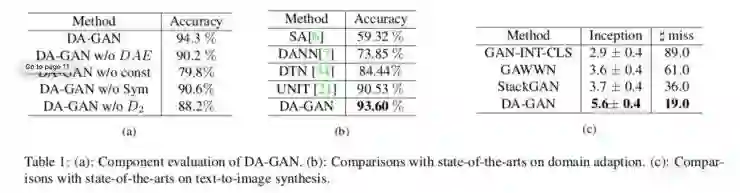
在定性比较方面,有下面三种:
Text to Image

object configuration

pose morphing

从左到右分别为 source bird、target bird 和 DA-GAN 生成的鸟。一个疑问是:鸟腿缺失是因为什么呢?
4、结论
本文提出了一种无监督的图像翻译的方法,即通过更细致化的 instance-level 的 GAN 生成来获得更高质量的翻译图像。通过实验结果可以很明显地看出 DA-GAN 相较于其他网络在性能上的提升。但是需要注意的是,在生成结果中仍然存在一些失败的地方(例如前面提到的「缺失的鸟腿」),这可能由于模型中的 instance 是通过弱监督 Attention 机制学到的,这与完全监督下的学习还是有一定的差距。如何弥补,或许要静等傅建龙团队接下来的工作了。
相关文章:
[1] DA-GAN技术:计算机帮你创造奇妙“新物种”
对了,我们招人了,了解一下?

BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业
扫码或点击阅读原文了解一下!

┏(^0^)┛欢迎分享,明天见!






