容器混合云,多快好省做基因测序
James Watson 和 Francis Crick 于 1953 年发现了 DNA 的双螺旋结构,从此揭开了物种进化和遗传的神秘面纱,开启了人类对数字化遗传的认知,但是人类基因奥秘却是一点点被读懂的。
1956 年,一则癌症和染色体相关性的发现令整个癌症研究界震动:慢性骨髓性白血病(CML)患者的第 22 号染色体,比一般然明显短很多。二十余年后,学者们发现,9 号染色体的 Abl 基因,与 22 号染色体的 BCR 基因连到了一块,交错易位产生了一条 BCR-Abl 融合基因。BCR-Abl 蛋白一直处于活跃状态且不受控制,引发不受控的细胞分裂,从而导致癌症。
也就是说,只要细胞表达 BCR-Abl 蛋白,就有血癌风险。美国着手深入研究,并成功推出了治疗慢性骨髓性白血病的新药。这,就是格列卫,也是去年《我不是药神》中被我们熟知的‘高价药’。
在格列卫诞生前,只有 30% 的慢性骨髓性白血病患者能在确诊后活过 5 年。格列卫将这一数字从 30% 提高到了 89%,且在 5 年后,依旧有 98% 的患者取得了血液学上的完全缓解。为此,它也被列入了世界卫生组织的基本药物标准清单,被认为是医疗系统中“最为有效、最为安全,满足最重大需求”的基本药物之一。
基因测序在血液肿瘤领域应用的越来越广泛。根据病人的诊断结果, 血液肿瘤专科医生会选择相应的检查,比如 PCR 结合实时荧光探针技术, 来检测测 BCR-Abl 融合基因, 以诊断慢性骨髓性白血病, 也可以通过二代测序方式,SEGF(Single-end Gene Fusion)能够通过单端NGS 测序数据检测复杂的基因融合类型。
在另一面,无创产检唐氏/爱德华式筛查,近年来以高准确率和对胎儿的低风险,越来越受到国内年轻产妇的欢迎。基因公司每年都完成几十万例的 NIPT 检查,每一例的 NIPT 涉及到数百 MB+ 的数据处理,存储和报告生成。一家大型基因测序功能公司每日会产生 10TB 到100TB 的下机数据,大数据生信分析平台需要达到 PB 级别的数据处理能力。这背后是生物科技和计算机科技的双向支撑:测序应用从科研逐步走向临床应用,计算模式从离线向在线演进,交付效率越来越重要。
1. 数据存储:数据增长快,存储费用高,管理困难;长期保存数据可靠性难以保障;需要寻求低成本大数据量的数据压缩方式;元数据管理混乱,数据清理困难。
2. 分发共享:海量数据需要快速、安全的分发到国内多地及海外;传统硬盘寄送方式周期长,可靠性低;多地中心数据需要共享访问。
3. 计算分析:批量样本处理时间长,资源需求峰谷明显,难以规划;大规模样本的数据挖掘需要海量计算资源,本地集群难以满足;计算工作流流程迁移困难、线上线下调度困难、跨地域管理困难;线下弹性能力差,按需计算需求。
4. 安全合规:基因数据安全隐私要求极高;自建数据中心安全防护能力不足;数据合约(区块链);RAM 子账号支持。
而这样看来一套完备架构方案则是必不可少的。与传统高性能计算相比,按需切分任务的需求,自动从云中申请资源,自动伸缩能力达到最小化资源持有成本,90% 以上的资源使用率,用完后自动返还计算资源。最大化资源的使用效率,最低单样本的处理成本,最快速的完成大批量样本的处理。随着基因测序业务增长,自动完成线下资源使用,和线上资源扩容。高速内网带宽,和高吞吐的存储,和几乎无限的存储空间。
基因计算不同于常规的计算,对海量数据计算和存储能力都提出了很高的要求。主要通过容器计算的自动伸缩特性和阿里云 ECS 的自动伸缩能力的打通,可以大规模弹性调度云上的计算资源。通过对基因数据的合理切分,实现大规模的并行计算同时处理 TB 级别的样本数据。通过按需获取的计算能力,以及高吞吐的对象存储的使用,大幅降低了计算资源持有的成本和单个样本的处理成本。
整体技术架构是云原生容器混合云,云上云下资源一体,跨地域集群统一管理。作为主要Player,容器技术在数据分拆,数据质量控制,Call 变异提供了标准化流程化、加速、弹性、鉴权、观测、度量等能力,在另外一方面,高价值挖掘需要借助容器化的机器学习平台和并行框架对基因、蛋白质、医疗数据完成大规模线性代数计算来建立模型,从而使精准医疗能力成为现实。
数据迁移、数据拆分阶段百万小文件的读取对底层的文件系统压力,通过避免不必要小文件的读写提高样本的处理效率。 通过数据中心与阿里云的专线连接,实现高吞吐低延迟的数据上云以及与工作流结合的上云、校验、检测方式。而最终需要达成的目标是:在短时间内完成数十 TB 级数据的加密搬迁,确保数据传输客户端的高性能与安全性,实现并发传输、断点续传,且保有完善的访问授权控制。
基因计算的典型特征就是数据分批计算,需要按照特定步骤先后依次完成。将该问题抽象后,即需要申明式工作流定义 AGS(AlibabaCloud Genomics Service) workflow。
其工作流的特点是:多层次,有向无环图。科研大工作流 1000-5000+ 深度的 DAG,需要准确的流程状态监控和高度的流程稳定性。简单流程从任意步骤重现启动 ,失败步骤可以自动完成重试和继续,定时任务,通知,日志,审计,查询,统一操作入口 CLI/UI 。
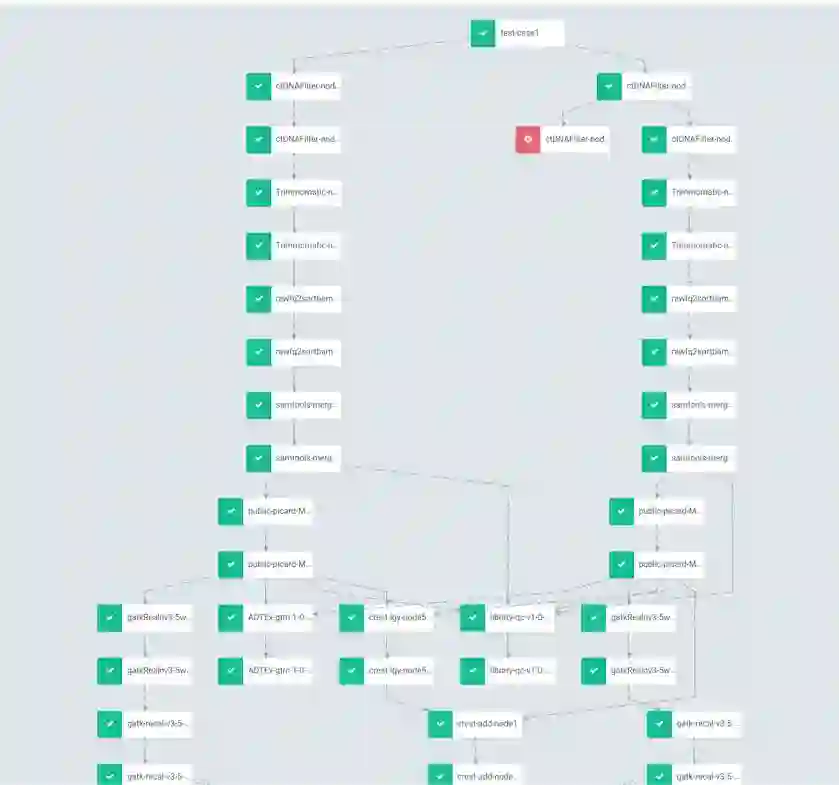
我们采用的方案是:
1. 简单 yaml 申明式定义,多层次,有向无环图, 复杂依赖支持, 任务自动分拆,自动并行化;
2. 云原生,与社区 argo 完全兼容的增强性 workflow 定义;
3. 失败步骤自动 Retry 增强,简单流程从任意步骤 retry。
4. 实时资源统计,监控集成云监控,云日志 SLS 集成, 审计集成, 定时任务;
5. 统一操作入口 ags-cli 与 Kubectl 集成;
6. 阿里云存储卷申明式支持,NAS,OSS,CloudDisk, 缓存加速支持。
通过跨越 IDC 和云上可用区的混合云 ACK 集群实现计算资源的统一调度和数据的云端汇聚。自动化,流程化上云数据,和后续的数据处理流程,形成 24 小时内完成批次下机数据的本地, 上云,云端处理和报告生成。按需弹性提供计算节点或者无服务化计算资源,形成按需计算能力,处理突发分析任务。我所带领的阿里云基因数据服务团队努力构建更具弹性的容器化集群,分钟级数百节点自动伸缩能力和分钟级数千轻量容器拉起的 Serverless 能力, 通过提高并行度来提高内网带宽的利用率,最终提高整体数据吞吐率,通过 NAS 客户端和服务端的 TCP 优化来提高 IO 读写速度,通过为 OSS 增加缓存层和分布式的缓存来实现对象存储读取加速等等。
还有很多问题,篇幅原因在此不一一展开:如何进行基因数据管理、最优化单位数据处理成本、采用批量计算的方式进行对样本分析、怎样使得基因数据处理安全及跨组织安全分享等等。
NovaSeq 测序仪带来了低成本(100$/WGS)高产出(6TB 通量)的二代测序方案,大量NovaSeq 的使用为基因测序公司每天产出的几十 TB 数据,这就要求大量的算力来分拆和发现变异,以及需要大量的存储来保存原始数据和变异数据。阿里云基因数据服务不断提升极致弹性的计算能力,和大规模并行处理能力,以及海量高速存储来帮助基因公司快速自动化处理每天几十上百 TB 的下机数据,并产通过 GATK 标准产出高质量的变异数据。
以 PacBio 和 Nanopore 为代表的三代测序的出现,超过 30K 到数百 K 的长读,和 20Gb 到15Tb 的大通量产出,长读和数据量对数据比对,分拆,发现变异带来了更大的算力需要和高IO 吞吐的需求,对基因计算过程中优化基因分析流程,拆分数据,按需调度大量计算资源,提供超高的 IO 吞吐带来了更大的挑战。
解码未知,丈量生命。科技的每一小步,都会成为人类前行的一大步。更多关于《基因测序的容器混合云实践》的内容 ,请点击阅读原文,关注 QCon 北京站获悉。
本文作者
李鹏,阿里云容器服务资深架构师,金融/生物计算行业解决方案专家,专注于基于Kubernetes 的容器产品开发和生产落地,负责过多个大规模容器平台的实施落地。16 年 +行业经验,在加入阿里云之前,曾在 IBM 担任 Watson 数据服务容器平台首席架构师,机器学习平台架构师,带领多个大型开发项目,涵盖云计算,数据库性能工具、分布式架构、生物计算,大数据和机器学习。

目前大会 9 折 报名中,立减 880 元。点击 「阅读原文」或识别二维码了解 QCon 十周年的精心策划。有任何问题欢迎联系票务小姐姐 Ring:电话 010-53935761,微信 qcon-0410。



