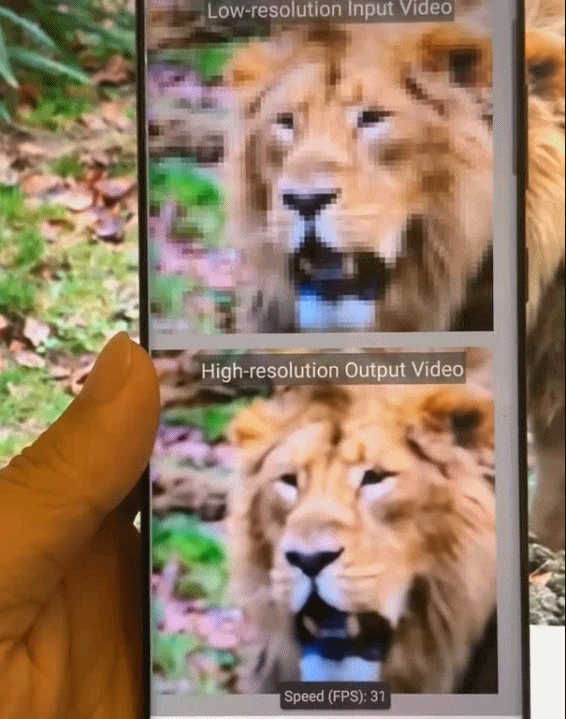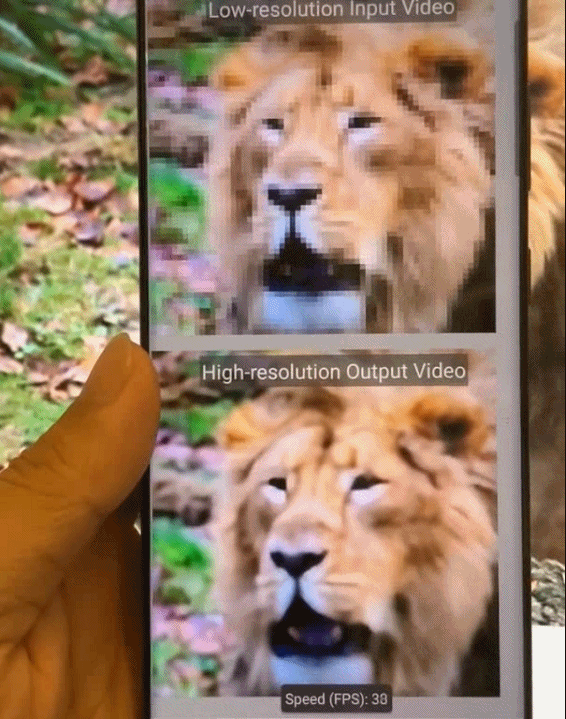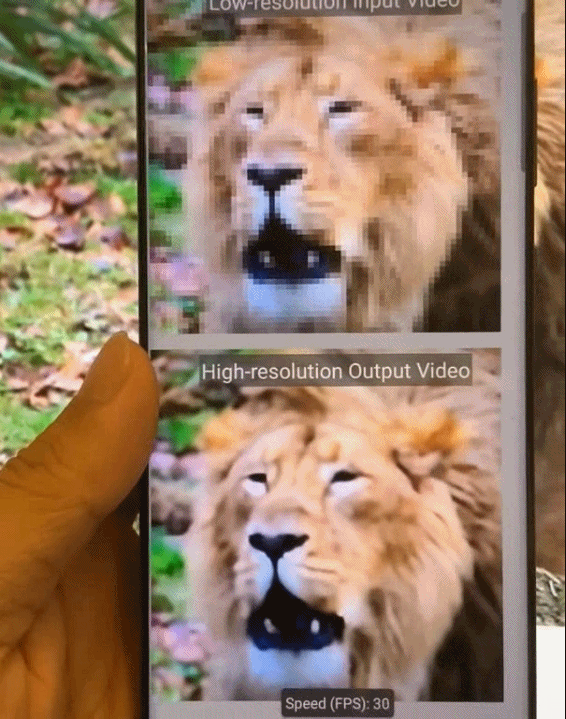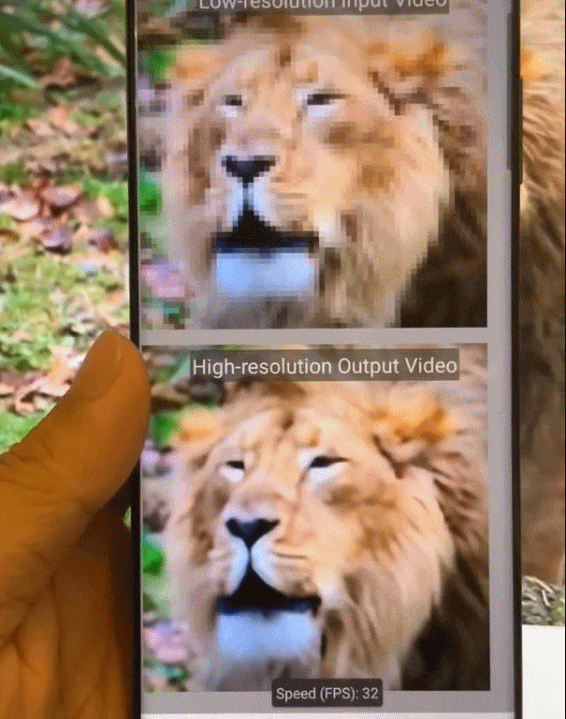
如何助力深度神经网络在移动端「看得」更清,「跑得」更快?来自美国东北大学等机构的研究者提出一种新型全自动模式化稀疏度感知训练框架。
基于模式化稀疏度的剪枝方法能够使深度神经网络在图像识别任务中「看得」更清楚,同时减小了模型尺寸,使模型在移动端「跑得」更快,实现实时推理。
由美国东北大学王言治教授研究团队与美国威廉玛丽学院任彬教授研究团队共同提出,IBM、清华等共同研究的模式化稀疏度感知训练框架,不仅能够同时实现卷积核稀疏模式的全自动提取、模式化稀疏度的自动选择与模型训练,还证明了所提取的模式化稀疏度与理论最佳模式化稀疏度相匹配,并进一步设计了能够利用模型特点实现编译器优化的移动端推理框架,实现了大规模深度神经网络在手机移动端上的实时推理。目前,这篇文章已被 ECCV 2020 会议收录,该文章同时入选 ECCV 2020 demonstration track。
目前,这项技术已经广泛应用在多种类型的人工智能(AI)任务中,包括但不限于:Yolo-v4 目标检测、实时相机风格迁移、AI 实时换脸、相机超分辨率拍摄、视频实时上色等,并且成功落地。以上任务全部在手机端上实现。
![]()
![]()
读者可点击以下链接,观看手机端实现的更多 AI 任务展示:
![]()
论文链接:https://arxiv.org/abs/2001.07710
通过开发功能强大的算法和设计工具,深度神经网络(DNN)成为各个领域的最新技术,包括图像分类、计算机视觉、语音识别和目标检测。随着海量数据不断增加,应用程序日趋复杂,模型的大小也急剧增加,对算力与内存的需求与日俱增,使得深度神经网络在资源有限的移动平台上实现实时推理受到很大的挑战。
近年来,移动与边缘计算平台正在迅速取代台式机和笔记本电脑,成为深度神经网络应用程序的主要计算设备。这些移动与边缘计算设备的物理尺寸受到严格限制,并结合了此类设备需要长时间运行的要求。然而,在大规模深度神经网络实际部署时,借助现有的移动端深度神经网络推理框架依然很难实现实时推理。即便这些平台能够运行大规模深度神经网络,巨大的计算代价对计算平台的运行时长也提出了挑战。因此,研发微型化的网络模型与可通用的加速方法势在必行。
为了弥合深度学习任务的性能(推理速度)要求与目标计算平台上资源可用性之间的差距,在算法层面,深度神经网络模型剪枝技术已被证明可有效消除原始模型中的冗余,从而得到小尺寸的网络模型。当前的两种主流剪枝方案——非结构化权重剪枝和结构化权重剪枝,代表了剪枝方式的两个极端,无法在保证模型精度和泛化能力的前提下,解决硬件执行效率低下的问题。研究者认为,必须寻求一种可以提供甚至超越两种稀疏性的最佳剪枝方案。
如图 1 所示,研究人员可视化了 VGG-16 在 ImageNet 上的预训练模型的部分权重,并且发现(i)卷积核的有效面积(即具有较高绝对值的权重)形成一些特定形状并在模型中反复出现,(ii)某些卷积核的权重值非常小,因此并不能对输出产生有效的激活,研究人员认为这种卷积核是无效卷积核。
![]()
图 1. ImageNet 数据集上 VGG-16 第三卷积层中随机选择的卷积核的热力图。每个内核中的权重值都经过归一化处理,深色表示该处为较高的绝对值。
基于上述两个发现,该研究提出了一个新的稀疏性维度——模式化稀疏度,并且提出了基于模式化稀疏度的深度神经网络权重模式化剪枝的概念。
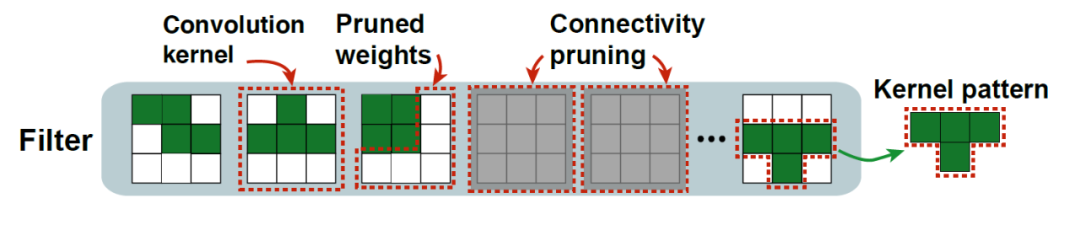
如图 2 所示,模式化剪枝中包含了两种卷积核层面的模型稀疏化方法,即卷积核(convolution kernel)模式化剪枝(pattern pruning)与连通性剪枝(connectivity pruning)。
![]()
为了实现卷积核模式化剪枝,该研究在每个卷积内核中删除固定数量的权重,其余权重形成具有特定形状的「模式化内核」。通过进一步挖掘,研究人员发现一些精心设计的卷积核模式(kernel pattern)具有特殊的视觉特性,可以潜在地提高图像质量,从而增强深度神经网络的特征提取能力。但是,什么样的卷积核模式能够更好地提升模型性能,同时保证硬件执行效率呢?这依然是个重要的问题。
同时,即使存在理论最优的卷积核模式,它能否在实际情况中得到深度神经网络的「青睐」?这又给该稀疏化方法的应用增加了不确定性。本文将从理论层面、算法实现层面、移动端硬件与编译器优化层面详细论述以上问题,并用实验数据展示模式化剪枝在高精度、实时性推理方面的强大作用。
在理论层面,该研究从一个全新且独特的角度审视了剪枝的概念。不同于将剪枝定义为模型参数的移除,这篇论文将剪枝转化成对神经网络模型权重加入一层二进制掩膜。研究人员将不同形状的二进制掩膜的集合称为「模式集」(pattern library),并将加入掩膜看作一种对神经网络的插值操作。通过不同模式的掩膜插值,得到一些功能性图像滤波器特征,能够实现图像的锐化与降噪,提高图像质量。值得一提的是,插值操作的过程仅需要少量种类的卷积核模式(或者说一个小尺寸的模式集)。
这样做所带来的好处是:(i)在算法层面,相对较少的卷积核模式可确保合适的搜索空间,以实现在深度神经网络上得到较好的训练效果;(ii)从编译器角度来看,更少的模式意味着更少的计算范式,从而能够潜在地降低线程分支。
图 3 展示了该研究设计的八种卷积核模式,通过 n 次插值,图 3(上)能够得到高斯滤波器,图 3(下)能够得到增强型拉普拉斯高斯滤波器。其中 n 代表神经根网络层数,系数 p 为任意位置 1 出现的概率,在正则化运算后没有实际意义。
![]()
![]()
图3.卷积核模式设计。
通过上述理论推导,我们得到了八种卷积核模式作为模式集。但是,一些至关重要的问题仍未得到解决。例如,这些从理论层面得出的最优模式集在算法实现层面上也是最理想的吗?即便以上问题的答案是肯定的,那么如何为每个卷积核选择合适的卷积核模式并训练非零权重?
为了回答上述问题,研究者在算法实现层面,设计了模式化稀疏度感知训练框架(pattern-aware network pruning framework),能够同时实现卷积核模式集的自动提取,模式化稀疏度的自动选择与模型训练。
在卷积核模式集的自动提取中,研究人员首先构建一个模式集全集,包含了所有可能种类的卷积核模式。在训练过程中,他们将这个模式集作为稀疏化目标,通过 ADMM(alternating direction method of multipliers)将原始剪枝问题解耦为 Primal-Proximal 问题,迭代式地通过传统梯度下降法求解 Primal 问题,并引入一个二次项迭代求解 Proximal 问题。通过每次 Primal-Proximal 迭代更新,使卷积核动态地从模式集中选择当前最优的卷积核模式,并同时通过梯度下降法训练该模式非零位置的权重。当卷积核对稀疏模式的选择趋于稳定的时候(一般仅需要迭代 3-5 次),就可以删除掉那些被选择次数非常少的卷积核模式,从而将模式集的大小降低,并用更新后的模式集进行下一轮迭代,最终实现模式集的自动提取。
尽管上述过程为迭代过程,但需要的总训练时长却是非常低的,原因在于该操作的目的是提取模式集而非完成整个训练过程。完成每一次模式集提取的迭代过程仅仅需要常规训练时长的 10%-20%。当训练集的大小足够小的时候,我们便可以用比常规训练时长减少 20% 左右的训练时间完成训练。从实验结果来看,完成模式集提取、模式化稀疏度选择与模型训练的总时长甚至可以少于大部分其他模型剪枝工作。
通过上述模式化稀疏度感知训练框架,我们得到了模式化剪枝后的稀疏模型。如何利用模型的权重空间分布特点实现编译器优化成为移动端硬件与编译器优化层面的研究重点。
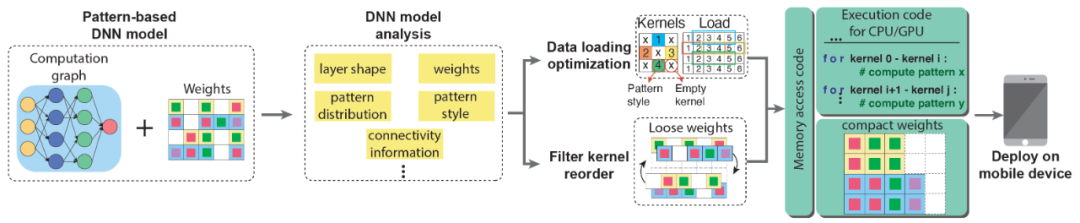
研究人员设计了适合模式化剪枝的移动端推理框架,能够部署并高效执行模式化剪枝后的深度神经网络模型,如图 4 所示。
![]()
图 4. 深度神经网络基于编译器优化的移动端推理框架概述。
这种编译器构架基于代码生成原理,将深度神经网络模型转化为底层静态执行代码,并配合适合模型特点的编译优化。研究人员利用已知的卷积核模式与连通性信息,相应地将每个卷积核的计算范式进行归类。通过将相同的卷积核模式(相同的计算范式)排列在一起,并将相似的重排结果在相同的线程中进行并行计算,消除所有静态代码分支,保证了高指令级与线程级平行性。
我们同时可以观察到,卷积核与输出通道重排后的模型权重分布非常规则与紧凑,因此,在缓存与寄存器访问频率上的优化效果变得非常明显。规则与紧凑的数据意味着更低的数据访问频率,而数据访问频率降低意味着更低的内存开销。这一设计方法是可通用的,因此该研究提出的移动端推理框架可以大规模地部署在现有各种量产手机端,实现端上 AI 实时推理,满足用户需求。
该研究的实验结果从三个方面展示了模式化稀疏度感知训练框架与基于编译器的移动端推理框架的性能,分别是卷积核模式集提取结果、模式化剪枝精度提升效果与移动端推理速度。
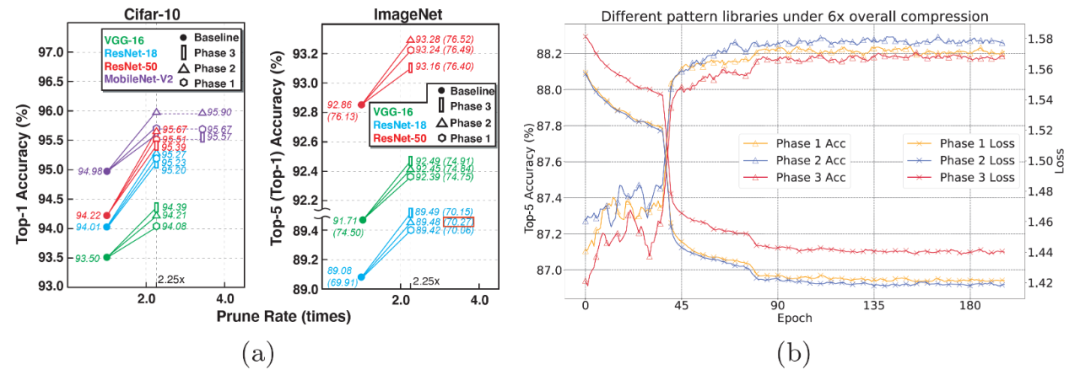
首先,图 5 展示了卷积核模式集提取结果。研究人员首先确定了每一个卷积核中应保留 4 个非零值,这样做的好处是控制模式集总集的大小,同时也利于移动端 CPU/GPU 的 SIMD 结构。当经过两次模式集提取后,模式集总集大小从 126 减小到 32 个,这时的模式集中卷积核模式分布图如图 5(b)所示。研究人员进一步训练并删除出现次数最少的卷积核模式后,得到了 Phase 1、2、3 模式集,其中的卷积核模式数量分别为 12、8、4,如图 5(a)所示。可以发现,Phase 2 模式集所含的卷积核模式与理论推导与八种卷积核模式完全匹配。因此研究人员得出结论,基于理论得出的卷积核模式也是算法实现层面上对于深度神经网络最优的卷积核模式。
![]()
图 5. 模式化稀疏度感知训练框架的模式集提取结果。
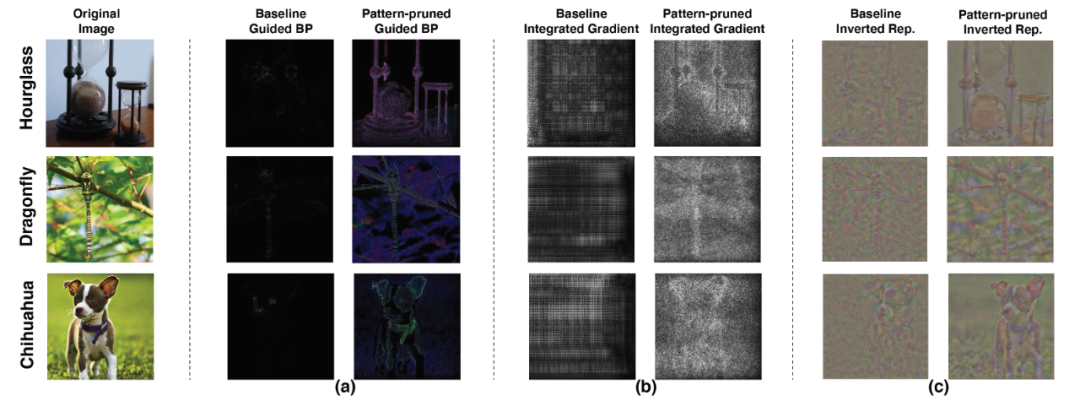
其次,研究人员展示了模式化剪枝对深度神经网络精度的提升。通过剪枝,深度神经网络将图像的细节「看得」更清了。如图 6 所示,通过不同的可视化方法,经过模式化剪枝的深度神经网络模型对于图像有明显的增强作用,模式化剪枝后的模型能够提取图像中更多的关键特征,并降低图像中的噪声。
![]()
图 6. 基于 VGG-16 在 ImageNet 上剪枝后的模型可视化效果图。此处采用了三种不同的可视化方法:(a)guided-backpropagation (BP) ,(b) integrated gradients,(c)inverted representation。
再次,研究人员展示了在不同种类的模式集(Phase 1、2、3)下,多种深度神经网络在 CIFAR-10 与 ImageNet 训练集上不同程度的精度提升效果,如图 7(a)所示。我们发现,在绝大多数情况下,当模型加载 Phase 2(同时也是理论推导得出的模式集)时,深度神经网络的精度提升幅度更大。这一现象使研究人员更加确信,基于理论得出的卷积核模式同时也是算法实现层面上对于深度神经网络最佳的卷积核模式。
图 7(b)从另一个角度佐证了这一观点:当拥有不同种类模式集的深度神经网络模型叠加相同剪枝率的连通性剪枝时,拥有 Phase 2 的模型能够保持更高水平的模型精度。研究人员在不同的网络结构模型中观察到了同样的现象。因此可以证明,Phase 2 模式集拥有更加稳定的精度表现。
![]()
图 7. (a)基于 CIFAR-10 与 ImageNet 的不同深度神经网络在模式化剪枝下的精度升高实验结果,(b)卷积核模式化剪枝叠加连通性剪枝后的 ResNet-18 训练曲线图。
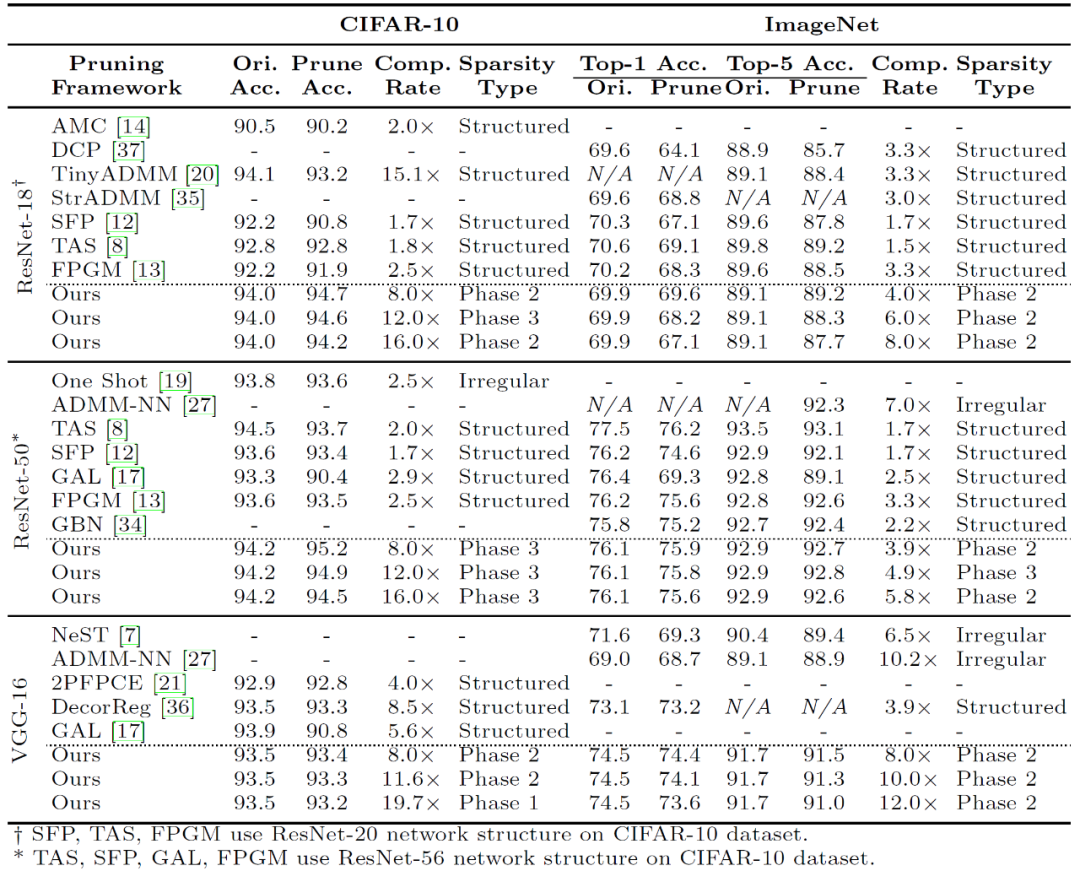
表 1 进一步展示了模式化剪枝的总体结果,研究人员将最好的剪枝精度与其模式集类型记录在表格中,并与其他研究工作进行系统性对比,结果表明大部分拥有最高精度的剪枝模型是基于 Phase 2 模式集的,这一现象同时体现在不同的数据集与深度神经网络中。
![]()
表 1. 基于模式化的剪枝在 CIFAR-10 与 ImageNet 数据集上的剪枝结果对比。
最后,该研究测试了基于编译器的移动端推理框架对模式化剪枝模型的加速效果。实验结果表明,模式化剪枝与编译器的协同优化极大地提高了移动端的推理速度。在移动端,研究人员使用了 Samsung Galaxy S10 智能手机来测试推理速度。
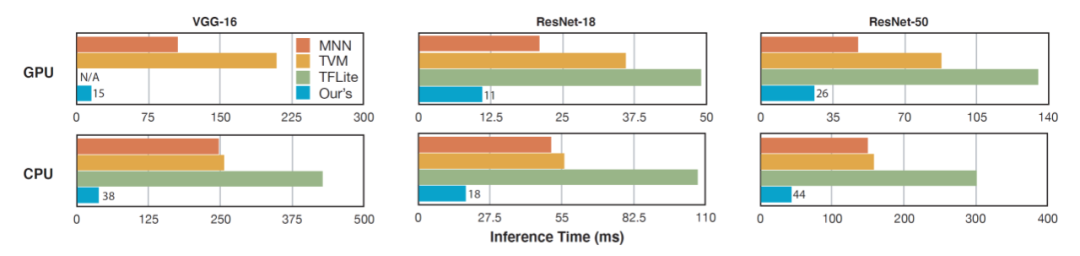
如图 8 所示,研究者测试了基于 Phase 2 模式集的稀疏化深度神经网络模型在 ImageNet 图像上的推理速度与在现有的深度神经网络加速器(TVM、MNN、TensorFlow-Lite)上的速度对比。
![]()
图8.基于Phase 2模式集的稀疏化深度神经网络模型在移动端的加速效果展示图。
结果表明,该研究提出的模式化剪枝与通用型移动端推理框架在推理速度上远远超过现有的加速器。事实上,在每一种网络结构下,该研究提出的方法在移动端都能在没有精度损失的情况下实现实时计算的要求(30 frames/second,即 33ms/second)。例如,在大型神经网络 VGG-16 上,该方法的推理时间仅为 15ms。这一对于最优的模式化剪枝方法与通用型的移动推理框架的研究使得在移动端对任意神经网络进行实时运算变为可能。
![]()
图9.基于模式化剪枝与通用型移动端推理框架在手机端不同AI应用场景的执行效果示意。从左到右依次为:相机超分辨率拍摄、实时相机风格迁移、视频实时上色、AI换脸。
![]()
图10.基于模式化剪枝与通用型移动端推理框架在手机端的执行效果图。从左到右依次为,实时相机风格迁移、视频实时上色、相机超分辨率拍摄。
马晓龙,美国东北大学 ECE 系 PhD 四年级学生,主要研究领域为机器学习算法,研究内容在 AAAI、ECCV、TNNLS、ASPLOS、DAC、ICS、PACT 等多个机器学习和计算机系统会议上发表。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com