Bounter:一个针对大数据集的计数器

Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
Bounter 是一个C语言编写的Python库。它仅以较小的固定大小的内存便能在巨大的数据集里进行十分高效的项目概率统计。
为什么选择Bounter?
Bounter让你能够计算一项东西出现的次数,这类似于Python内建的dict或Counter:
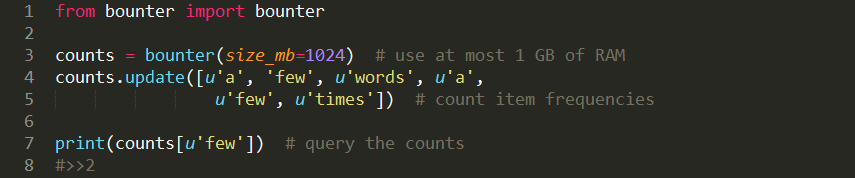
然而,和dict或Counter不同的是,Bounter能够处理巨大的集合,这些集合项甚至都与RAM大小不相符。这通常应用于机器学习和自然语言处理,如字典构建或匹配检测,这需要估算数十亿计的项目来得到它们的统计得分以及后续的过滤。
Bounter通过优化了的低级的C语言框架实现了近似算法,来避免Python对象的开销。它允许你指定想要使用的最大内存。在下面Wikipedia的例子中,Bounter使用了比Counter少31倍的内存。
Bounter有些情况下比内建的dict和Counter还要快,因此只要你把你处理的项当作字符串(字节字符和Unicode,Bounter在Python2和Python3里都支持),就没有理由不使用Bounter。
安装步骤
Bounter只需要Python2.7及以上版本或者Pyhon3.3及以上版本,并且有一个C编译器:

或者如果你愿意,也可以使用source tar.gz:进行安装:

它是如何工作的呢?
它并没有什么魔力,只是巧妙的使用了近似算法和扎实的技术。
特别是,Bounter底层实现了三种不同的算法,根据“计数”类型你需要:
1. 基数估算:有多少唯一项?

这是应用了HyperLogLog算法(构建于Joshua Andersen的 HLL代码之上)并使用最小内存的一个最简单的应用场景。
2. 项目频次:这一项出现了多少次?
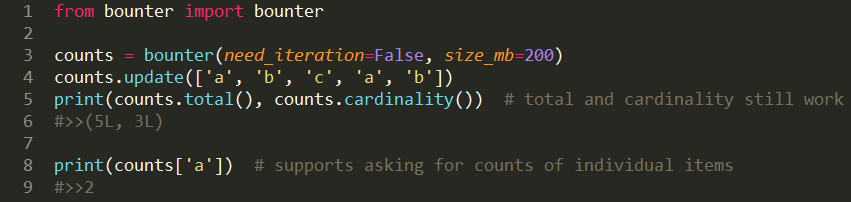
这个例子使用了最小略图算法以固定大小的内存高效的估算出了项目的数量。具体详情和参数请参考API文档。
为做进一步的优化,最小略图选择性地支持了一种对数概率计数器:
bounter(need_iteration=False):默认选项。精确计数,非概率计算。每批次占用4个字节(最大2^32)。
bounter(need_iteration=False, log_counting=1024):一个占用2字节的整数计数器。2048以内的数值会是精确的,更大的会有+/-2%的误差。最大可表示的值大概是2^71。
bounter(need_iteration=False, log_counting=8):一个更加令人称奇的概率计数器,它仅使用1个字节。8以内的值是精确的,更大的话会有+/-30%的误差。最大可表示的值大概是2^33
这些在内存与准确性上的折衷有些时候正好迎合了自然语言处理。在这种场景下能够处理巨大数据集比判断一个事件发生的准确度高55482倍或是55519倍更加重要。
3. 全项迭代:“有些什么项目以及它们出现的频次是多少?”
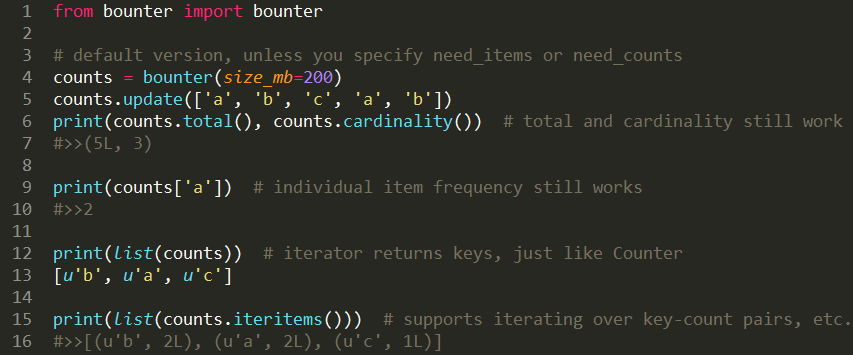
除了键值(字符串)本身之外,它还存储了整个基数和每个项目出现的频次(8字节)。使用了最多的内存,但支持了最广的功能。
这一项在底层使用了自定义的C哈希表来优化字符串的存储。当接近分配的最大内存时,它会移除低计数的对象,而不是扩展这个表。
更多详细内容,请参考API docstrings
英文版Wikipedia上的例子
让我们来计算一下在英文版Wikipedia语料库里所有双字出现的频次:
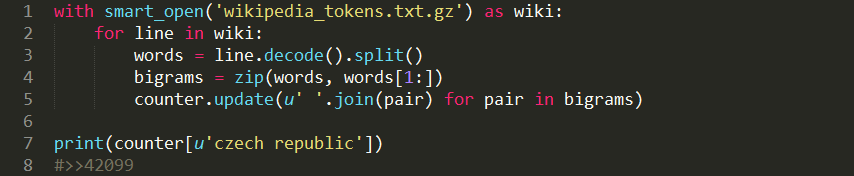
Wikipedia数据集包含了总数1,860,927,726单词里的7,661,318个去重单词,总数1,857,420,106双字里的179,413,989个去重双字。
为了测试Bounter的准确性, 我们自动化地从这些双字里抽取一些组合 (常用的多字表达,例如:"New York", "network license", "Supreme Court" or "elementary school")
我们把从Counter和Bounter里抽取出来的组合做了对比,并在以下展示了精度和回调:
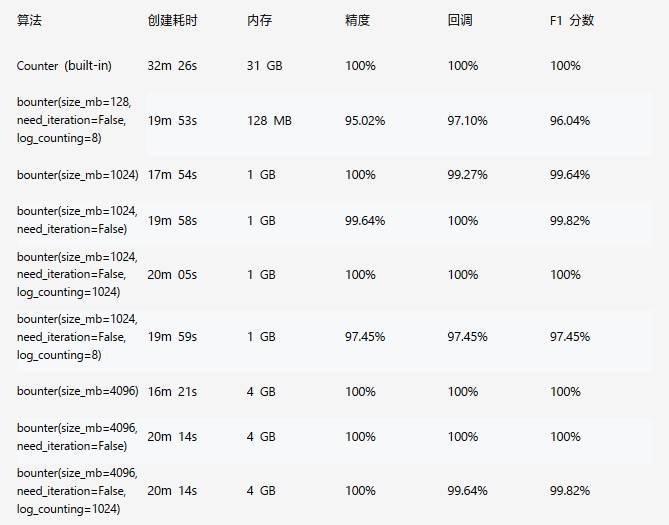
相比内建的Counter或dict, Bounter以少31倍的内存使用获得100%的完美F1分数。尽管只使用了128MB(少250倍内存)的内存,但仍然要快61%,而且F1分数还能达到96.04%。
支持
可以使用Github issues提交问题,如果有任何探讨和功能上的想法也可以发送邮件给我们。
Bounter是在MIT许可下发布的开源软件。
英文原文:https://github.com/RaRe-Technologies/bounter
译者:🐻大白




