超越GAN!OpenAI提出可逆生成模型,AI合成超逼真人像

新智元推荐
来源:OpenAI
编译:文强
【新智元导读】OpenAI最新提出的可逆生成模型Glow,可以使用相对少的数据,快速生成高清的逼真图像,具有GAN和VAE所不具备的精确操作潜在变量、需要内存少等优势。

OpenAI刚刚在博客介绍了他们的最新成果——Glow,一种使用可逆1x1卷积的可逆生成模型。
Glow 可以生成逼真的高分辨率图像,支持高效采样,并且可以自动学习图像中属性特征,比如人的五官。
先来看效果,加了胡子的Hinton,笑容调到最高,眼神也看起来更亮:

下图是使用Glow操纵两名研究人员面部图像的属性。模型在训练的时候并没有给出眼睛、年龄等属性标签,但自己学习了一个潜在空间,其中某些方向对应胡须密度,年龄,发色等属性的变化。

人脸混合过度的效果也十分自然:

这是使用30,000个高分辨率面部数据集进行训练后,Glow模型中的样本,可以说很逼真了。如果不说明,应该有不少人会觉得是真人照片。

再放大来看,这个效果至少是不输给GAN的:

Glow模型生成一个256 x 256的样本,在NVIDIA 1080 Ti GPU上只需要大约130ms。使用 reduced-temperature模型采样结果更好,上面展示的例子是温度0.7的结果。
Glow是一种可逆生成模型(reversible generative model),也被称为基于流的生成模型(flow-based generative model)。目前,学界还很少关注基于流的生成模型,因为GAN和VAE这些显而易见的原因。
OpenAI的研究人员在没有标签的情况下训练基于流的模型,然后将学习到的潜在表示用于下游任务,例如操纵输入图像的属性。这些属性可以是面部图像中的头发颜色,也可以是音乐的音调或者文本句子的情感。
上述过程只需要相对少量的标记数据,并且可以在模型训练完成后完成(训练时不需要标签)。使用GAN的工作需要单独训练编码器。而使用VAE的方法仅能确保解码器和编码器数据兼容。Cycle-GAN虽然可以直接学习表示变换的函数,但每次变换都需要进行重新训练。
训练基于流的生成模型操纵属性的简单代码:

OpenAI研究人员表示,这项工作是建立在非线性成分估计(Dinh L. et, NICE: Non-linear Independent Components Estimation)和RealNVP(Dinh L. et, Density estimation using Real NVP)的基础上。
他们的主要贡献是增加了可逆的1x1卷积,并且删除了RealNVP的其他组件,从而简化了整体架构。
RealNVP架构包含两种类型的层:一种是有棋盘格masking的层,一种是有channel-wise masking的层。OpenAI去掉了前一种棋盘格masking,简化了整体结构。
在Glow模型的工作中,具有channel-wise masking的层不断重复下列步骤:
通过在channel维度上反转输入的顺序来置换输入。
将输入在特征和维度的中间分为A和B两部分。
将A输入一个浅层的卷积神经网络,根据神经网络的输出线性变换B
连接A和B
将这些层链接起来,让A更新B,B更新A,然后A再更新B,以此往复。这种双向信息流非常rigid。研究人员发现,通过将步骤(1)的反向排列改变为(固定的)shuffle 排列还能改善模型性能。
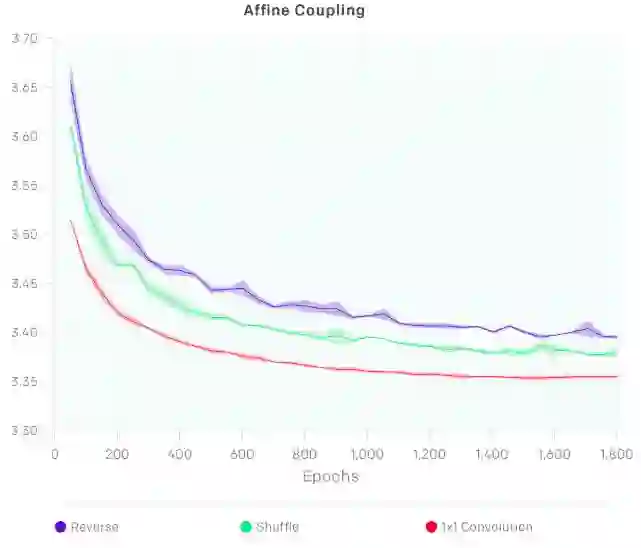
使用1x1卷积的效果要显著好于逆转和Shuffle
此外,他们还将批归一化(BN)换成了一个激活归一化层(activation normalization layer)。这个层能够转变和放大激活。因此,能将大图像最小的批量大小缩小到1,并扩大模型的大小。
这个架构结合了多种优化,例如梯度检查点(gradient checkpointing),使研究人员能够比平常更大规模地训练基于流的生成模型。他们还使用Horovod在多台机器的集群上训练模型,上面演示中使用的模型在5台机器上训练,每台有8个GPU。使用这种设置,他们训练了具有超过一亿个参数的模型。
OpenAI研究人员表示,他们在这项工作中表明,可以训练基于流的模型(flow-based)来生成逼真的高分辨率图像,并且学习可以轻松用于下游任务(如数据操作)的潜在表示。
基于流的生成模型有以下优点:
精确的潜变量推断和对数似然估计。在VAE中,只能近似推断出与某个数据点相对应的潜在变量的值。GAN则根本没有编码器来推断潜伏变量。但是,在可逆生成模型中,不仅可以实现准确的潜在变量推理,还可以优化数据的对数似然,而不是只是其下限。
高效的推理和有效的合成。自回归模型,例如PixelCNN,也是可逆的,但是这些模型的合成难以并行化,往往在并行硬件上效率很低。基于流的生成模型,比如Glow和RealNVP,可以有效地进行推理与合成的并行化。
下游任务的有用潜在空间。自回归模型的隐藏层边际分布式未知的,因此很难进行有效的数据操作。在GAN中,数据点通常不能直接在潜在空间中表示,因为它们没有编码器,可能不完全支持数据分布。但可逆生成模型和VAE,就能进行数据点之间的插值,对现有数据点进行有意义的修改等操作。
节省内存的巨大潜力。如RevNet论文所述,在可逆神经网络中计算梯度需要的内存是固定的,不会随着深度的增加而增加。
他们建议未来可以继续探索这两个方向:
自回归模型和VAE在对数似然性方面比基于流的模型表现更好,但它们分别具有采样低效和推理不精确的缺点。未来,可以将基于流的模型、VAE和自回归模型结合起来,权衡彼此优势,这将是一个有趣的方向。
改进架构来提高计算效率和参数效率。为了生成逼真的高分辨率图像,面部生成模型使用200M规模参数和大约600个卷积层,这需要花费很高的训练成本。深度较小的模型在学习长时间依赖(long-range dependencies)方面表现较差。使用self attention结构,或者用渐进式训练扩展到高分辨率,可以让训练流模型的计算成本更低。
编译来源:https://blog.openai.com/glow/
相关论文:https://d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





