点击蓝字,关注我们

撰写:杜若琳、王楠、刘辰阳 编辑:付家顺
摘要
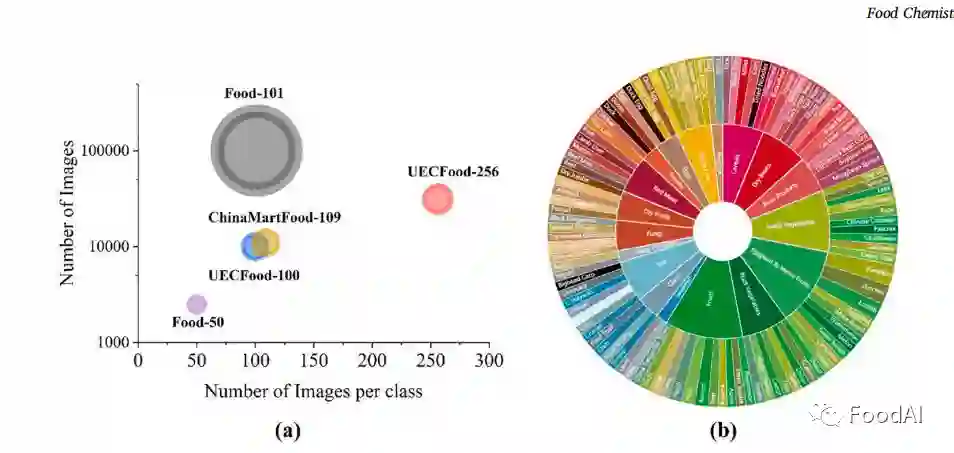
今天介绍一篇由来自中国人民大学农业经济与农村发展学院Peihua Ma 和生吉萍等人于2022年3月发表在Food Chemistry 上的一篇论文。该研究在视觉识别任务中利用了深度学习技术,并提出了一套大数据驱动的深度学习模型,从食物图像回归到营养估计,最大限度地发挥了深度学习模型的潜力,同时为未来将人工智能引入食品领域提供了基础。 1 介绍 在过去的几十年中,有数据显示全球超重和肥胖的患病率自1975年以来增长了两倍,而中国的情况更为值得注意。2004年第一份中国慢性病及危险因素监测报告称,一般肥胖的患病率为男性14.0%,女性14.1%。为了应对肥胖症的日益流行,先前的研究发现干预研究和行为改变计划对健康饮食和体育活动产生了一些影响。这个结果表明需要个性化的饮食管理工具。 传统的饮食摄入主要是基于纸质、电话或亲自评估的,这对于研究人员和个人来说都是不切实际、不太便利的,尤其是对于拥有庞大人口的中国而言。随着深度学习(DL)模型的商业化,基于智能手机图像的每日精确饮食记录成为可能。因此有一种新兴的膳食评估方法,引入了基于深度学习的智能手机工具,收集膳食回忆数据。 在过去十年,计算机视觉技术在桌面和移动应用程序中为食物识别和数量估计提供了视觉特征。深度学习(DL)作为当代机器学习的唯一优越框架,被广泛探索并探讨了食品图像识别的新阶段。最近的研究表明,DL 学习到的视觉特征比手工制作的视觉特征更强大、更具表现力。迄今为止,国外共有三个广泛使用的食品图像数据库,Food-101、 UECFood-100 和 UECFood-256。Food-101数据库是食品识别领域中最受欢迎的数据集,包括101个食品类别,每个类别1000张食品图像。UECFood-100包括100个日本食品类别,每个类别100张图像,且于2014年扩展至256类日本食品。基于这两个数据库,有研究进一步提供一个名为 Food-475的数据库。Food-475包含475类食物的247,636张图像。 因现有数据库均为国外食品图像数据库,其食品图像识别种类与营养估计不贴合中国人的饮食习惯,且尚未解决从食品图像中全自动估计食品营养素的问题,因此该研究根据《中国居民膳食指南》为食物图像数据库收集营养注释,优化和综合评估了几个现有的CNN模型用于食品图像识别的任务,在验证了基于CNN的营养估算方法的有效性和可接受的准确性的基础上建立并发布了中国市场上销售最广泛的109类食品的第一个食品形象数据库,命名为ChinaMartFood-109, 其中包含 10921 张图像、23种营养成分,涵盖18个主要食物组。此外,该研究比较了三种养分估计算法,通过归一化+AM与算术平均和调和平均的比较,得到了最佳的回归系数(R2),验证了实践和理论的适用性,为支持人工智能在食品分析领域提供了进一步的证据。 2 材料和方法 2.1 ChinaMartFood109 数据集 作者开发了ChinaMartFood109数据集,该数据集是根据农业部发布的食品订单清单制作而成,由中国市场上109类最大量的食品组成。该数据集涵盖18个主要类别,包括谷物、干豆、豆制品、根茎、叶菜、菌类、海菜、水果、干果、红肉、乳制品、家禽、蛋制品、爬行动物、贝类、鱼类、脂肪和油。并且其中对每一类食品都有详细的营养注释。 2.2 数据库属性 作者将该数据库与其他主流食品图像数据库的图像数量、类别和比例做了比较,所呈现的图像中圆的面积与每类的平均图像数量成正比,如图1。可以看出,Food-101 是最丰富的食物图像数据库,而 Fbod-101 的原始版本 Food-50 是最小的。此外,UECFood-256 包含的图像总数最多。
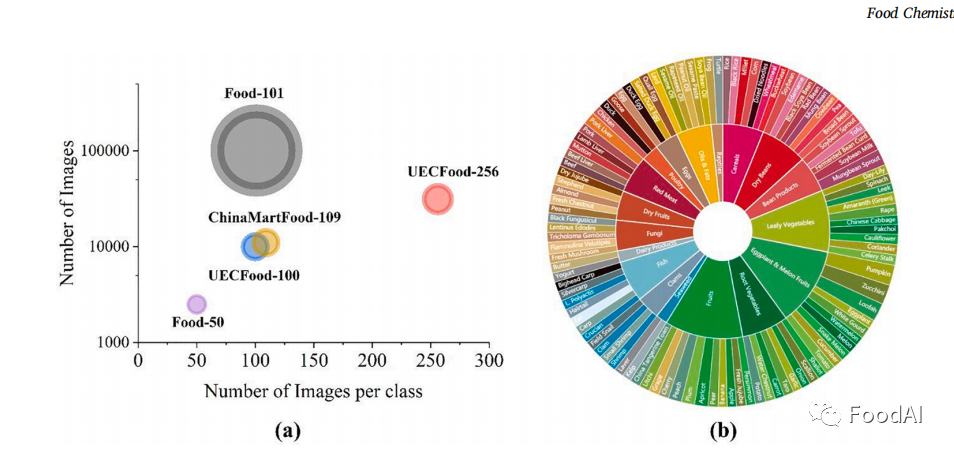
图1 各数据库图像总数与每类图像数量图和食品领域代表性图 2.3 网络架构 食品图像识别的学习方法的整体过程具有相同的四个步骤。第一步是从互联网上收集大量带有注释的食物图像。第二步是遵循一套标准的图像预处理,并且作者训练了一个使用深度卷积神经网络的食品分类系统来进行食品营养成分的估计。第三步是将数据集拆分为训练集和验证集。第四步是在训练集上训练CNN模型,并在验证集上评估结果。作者团队所选用的是VGG、ResNet、Wide Res Net和Inception V3四种不同的深度学习神经网络架构。这四种对数神经网络架构在最具挑战性的图像分类数据集 ImagcNct-1000 上实现了高准确度,该数据集总共包含大约 120 万张训练图像,包括 1000个不同类别的50,000张验证图像和 150,000 张测试图像。因此,这四种网络架构将是我们数据集的可靠的最佳选择。 2.4 分类和营养估计 通过微调在ImageNet上预训练的四种架构来训练我们的分类系统模型,并将最后一层改为输出109类,从而得到了数据库中的109类食品。并且通过相关公式计算数据库中109类中的期望营养成分含量。 2.5 评估指标 采用机器学习中常用的食品分类性能评价指标:top-1和top-5的分类精度。营养估计采用了五个评价指标:R2,RANSAC回归斜率,平均绝对百分比误差(MAPE),皮尔逊相关系数,斯皮尔曼相关系数。通过这些指标在检测预期值与真实值的差异大小。 2.6 图像片段可视化 为了研究分类器如何处理食物图像,应用梯度定位的深度神经网络可视化技术 Grad-CAM,来比较正确分类和错误分类的测试样本。 3 结果与讨论 3.1 基线结果 为了证明基线方法的有效性,作者在两个公开的食品数据库上对其进行了评估:UECFood-256和food-101。比较了三种基于深度CNN的方法的基线方法,然后在ChinaMartFood109数据集上评估了基线方法。如方法部分所述,数据集被分为训练子集和测试子集。采用top-1和top-5两项指标来评估基线方法的性能。比较结果如下表所示。InceptionV3模型显示了两个测试数据库的最高准确性。UECFood-256和Food-101的Top-1准确率分别为83.27%和73.77%。两种方法的前5位准确率分别为92.82%和94.79%。由于作者的计算平台的计算能力相对较弱,所以作者所得出的结果中每个模型的准确度都略低,但在误差范围内是可接受的。 表1 UEC256、Food101 和 ChinaMartFood-109 不同方法分类精度比较
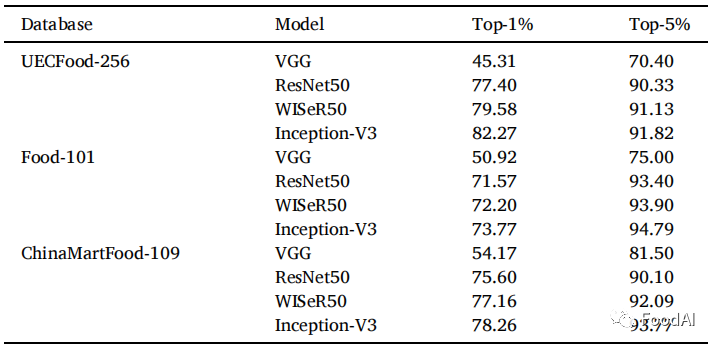
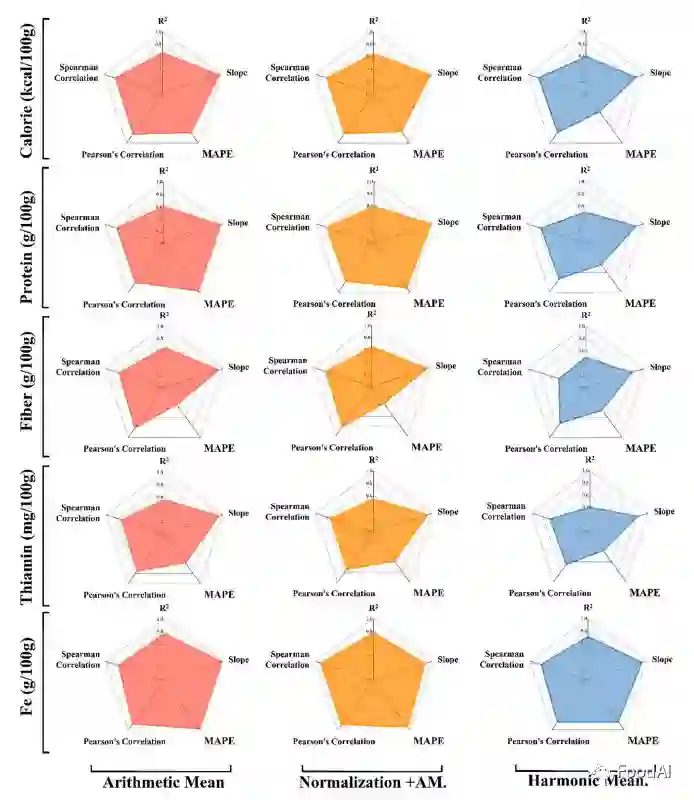
3.2 最佳性能CNN架构选择 从上表可以看到,Inception-V3在每个数据库中都体现出最高的准确度。所以Inception V3 是最适合用于食品图像分类任务的架构。 3.3 使用ChinaMartFood-109估算食品营养成分 估算营养价值的五个评估指标为热量、蛋白质、纤维、硫胺素和铁。所得的结果如图2所示。
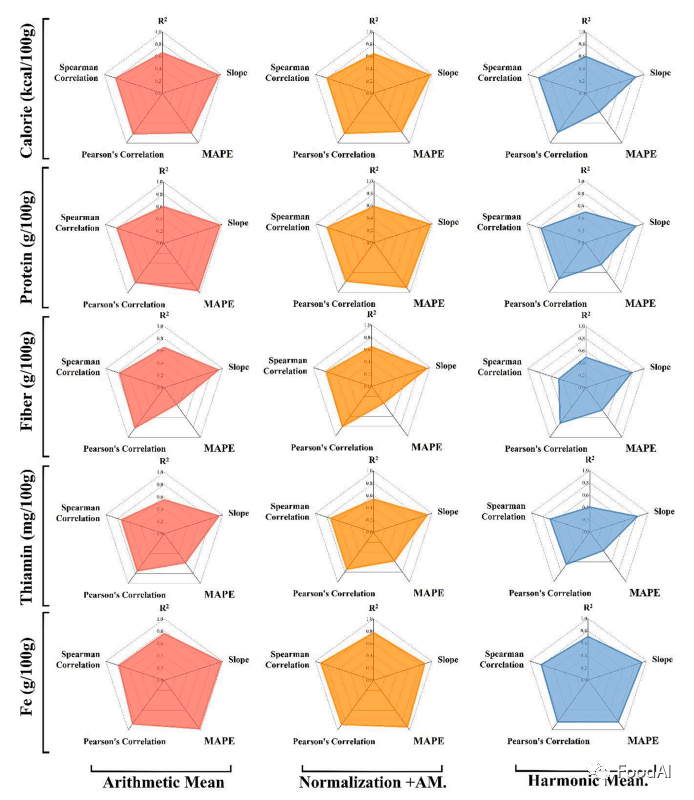
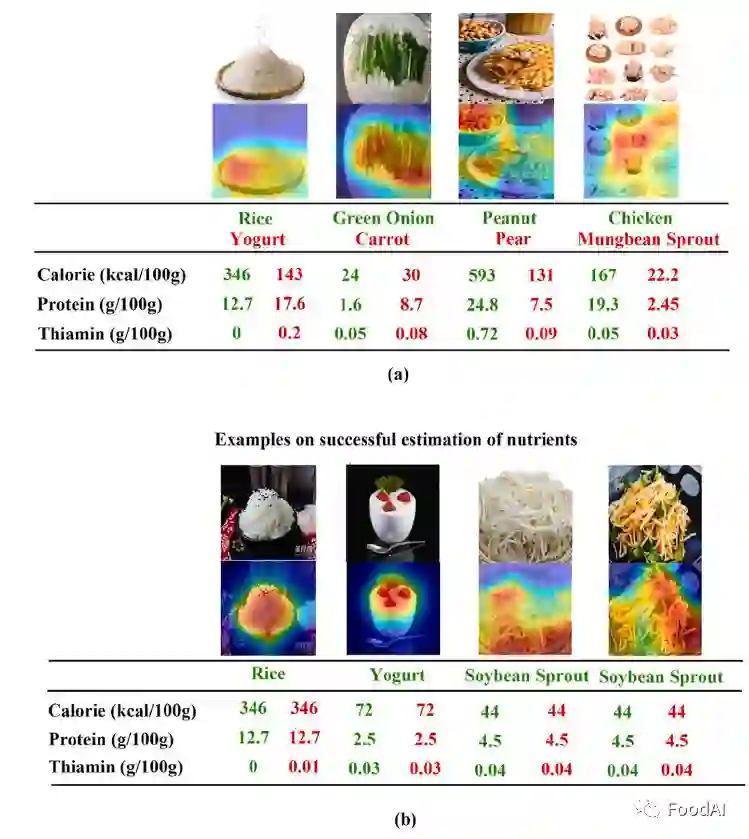
图2 不同算法在不同营养物质分析时的雷达图 此外,该研究还选用带有Nor+AM的深度CNN图像识别模型的Intercept V3来作为营养素估算的算法。图3分别显示了错误估计结果(如图a)和成功估计结果(如图b)的四个示例。对于四张具有代表性的成功评估图像,Grad CAM正确地突出显示了该区域。例如,在大米的第一张图像(1)中,该模型成功地识别了大米区域,而在大米的故障估计图像中,Grad Cam仅突出显示了大米的一部分。同时,识别区域越集中,识别准确率越高。因此,成功的图像识别的关键是从背景中分割出食物区域并精确地提取特征点。换言之,食物识别的成功与食物区域分割密切相关,营养素估计的准确性取决于识别精度。
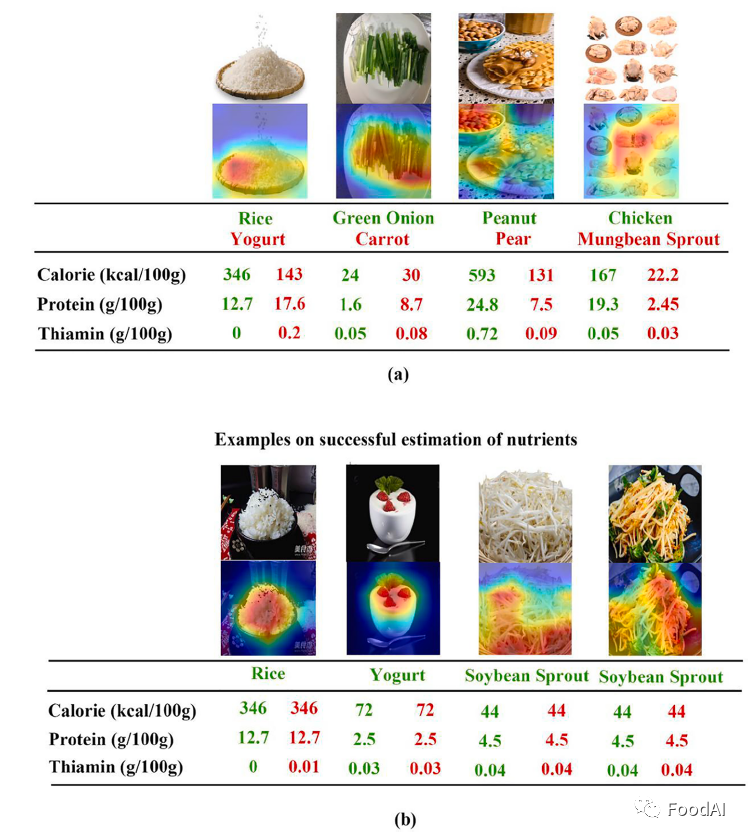
图3 食品识别和营养物质估计输出与基本真实值相比(a)失败和(b)营养价值成功估计的例子 3.4 结论 根据对于ChinaMartFood109数据库中食品营养成分的测量,我们可以得到以下结论: 1、模型中的Top-5分类性能是可靠的,即通过比较Top-5分类性能的准确度可以得到较为精确的结果。 2、比较不同营养素评估时,评估指标显示出显著差异。例如营养纤维在五个营养指标中显示出最低值,而Fe在评估指标中显示了最广泛和平衡覆盖范围。 3、同一类样品的复杂性和多样性极大地影响了分类精度。例如在草鱼类中,一些图像包含一条鱼,而其他图像可能包含多条鱼,这些样本会给模型的学习过程带来困难。 4、与不同的估算方法的结果相比,不同的营养物质是产生不同的主要因素。不同的估算方法所得结果的趋势是相同的,而产生不同的主要因素主要是营养物质的不同。 5、数据差异可能来源于数据类型不同,并且数据库越大准确度越高。与外国其他文本数据库的结果相对比,存在一定的数据差异。数据库中所含样本数量越大,所得结果更经得住验证,即准确度越高。 4 展望 4.1 缺陷 ChinaMartFood109数据库对某些营养素检测的准确度有待提升,并且目前CNN虽然在计算机科学方面应用广泛,但在食品科学上应用很少。 4.2 前景 该数据库的出现为从食品图像中全自动地估计营养成分提供了解决思路,并且为未来将人工智能引入食品领域提供了一定条件。 参考文献
参考文献:Peihua Ma, Chun Pong Lau, Ning Yu, An Li, Jiping Sheng*. Application of deep learning for image-based Chinese market food nutrients estimation. Food Chemistry 373 (2022) 130994.