

**摘要
近年来,随着多模态大型语言模型(MLLMs, Multimodal Large Language Models)的快速发展,人工智能领域取得了显著进展。然而,将静态的、预训练的 MLLM 适配于动态数据分布及多种任务,同时保证高效性和准确性,仍然是一项重大挑战。在针对特定任务对预训练 MLLM 进行微调(fine-tuning)时,模型在其原有知识领域中往往会出现明显的性能下降——这一现象被称为“灾难性遗忘(Catastrophic Forgetting)”。尽管该问题在持续学习(Continual Learning, CL)领域已被广泛研究,但在 MLLM 背景下仍然面临新的挑战。 作为首篇关于多模态大型模型持续学习的综述论文,本文对MLLM 持续学习的 440 篇相关研究进行了全面梳理与深入分析。在介绍基本概念的基础上,本文的综述结构分为四个主要部分:
- 多模态大型语言模型的最新研究进展涵盖各类模型创新策略、基准测试(benchmark)以及在不同领域的应用;
- 持续学习的最新研究进展分类及综述按研究对象划分为三大方向:
- 非大型语言模型(Non-LLM)单模态持续学习(Unimodal CL),
- 非大型语言模型多模态持续学习(Multimodal CL),
- 大型语言模型中的持续学习(CL in LLM)。
- MLLM 持续学习的现状分析涵盖主流基准测试、模型架构和方法的创新改进,并系统性地总结和回顾已有的理论与实证研究;
- 未来发展方向对 MLLM 持续学习领域的挑战与前景展开前瞻性讨论,旨在启发研究人员,并推动相关技术的进步。
本综述旨在系统性地连接基础设置、理论基础、方法创新和实际应用,全面展现多模态大型模型持续学习的研究进展和挑战,为该领域的研究人员提供有价值的参考,并促进相关技术的发展。
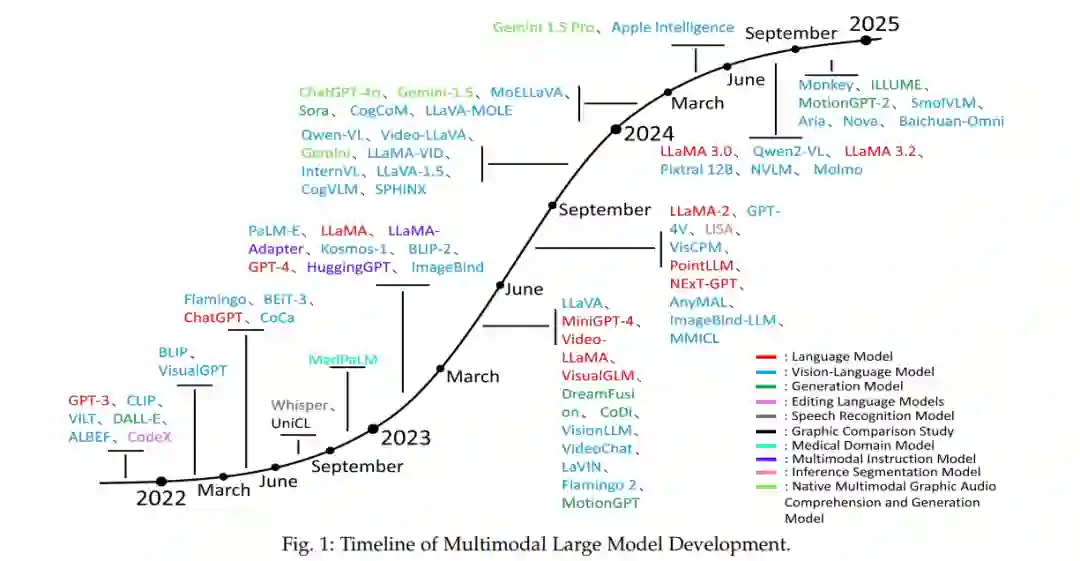
近年来,多模态大型语言模型(MLLM, Multimodal Large Language Models) 的研究取得了快速进展,并成为人工智能领域的重要研究方向之一 [1]-[10]。MLLM 通过融合语言、视觉、音频等多模态信息,展现出强大的跨模态理解与生成能力,为解决复杂的现实世界问题提供了创新性方案 [11]-[15]。 为了提升 MLLM 的性能,研究者提出了多种改进策略。首先,在跨模态信息融合方面,引入了更高效的架构设计 [16]-[18],例如基于 Transformer 的多模态联合编码器和解码器,以及轻量级跨模态注意力模块 [19]-[21]。其次,在预训练技术方面,进一步发展了多模态对比学习、跨模态一致性约束、自监督学习(self-supervised learning)等方法,大幅提升了模型的泛化能力和鲁棒性 [22]-[25]。此外,微调(fine-tuning)技术也不断优化,例如引入了参数高效调整方法(如 LoRA [27])和任务特定适配层设计,使得 MLLM 能够在较低计算成本下适应多样化的任务场景 [26]-[31]。 MLLM 的性能评估主要依赖于多模态基准测试(benchmark),这些测试涵盖多个任务类别(见图 1)。例如,在视觉-语言任务领域,主流基准包括视觉问答(VQA, Visual Question Answering) [32]-[36]、图像描述(Image Captioning) [37]-[42]、视觉指引(Visual Grounding) [43]-[46];在音频-语言任务领域,基准测试涵盖音频-文本对齐和音频生成 [47]-[49];此外,还有更复杂的跨模态推理任务等 [50]-[51]。MLLM 在医疗、教育、机器人、自主驾驶等实际应用中也展现出巨大潜力,并发挥着日益重要的作用 [52]-[54]。
1.1 持续学习与多模态大型模型的结合
持续学习(Continual Learning, CL) 旨在解决模型在面对动态变化的数据流时,如何在学习新任务的同时有效保留已有知识,从而缓解灾难性遗忘(Catastrophic Forgetting)问题 [55]-[57]。近年来,持续学习的研究不断深入,特别是在不同规模的模型及多模态学习场景下取得了显著进展 [58]-[63]。 在单模态持续学习(Unimodal CL) 研究中,主要关注缓解灾难性遗忘的算法设计,使模型在学习新任务的同时仍能保持对已有任务的良好性能 [64]-[69]。相比之下,多模态持续学习(Multimodal CL) 面临更大挑战,因为模型需要同时处理不同模态的特性及其跨模态交互 [61], [70]-[72]。研究者主要致力于跨模态特征提取、对齐和处理,以减少跨模态干扰、增强模态间一致性,并提升模型的泛化能力 [73]-[76]。 随着大型语言模型(LLM) 在自然语言处理(NLP)领域的广泛应用,其持续学习研究也成为新兴热点 [77]-[82]。由于 LLM 具有庞大的参数规模,并依赖于大规模预训练数据,传统的持续学习策略在应用于 LLM 时面临计算成本高、适应性受限等挑战。为此,研究者提出了一些优化方向,包括参数高效微调(PEFT, Parameter-Efficient Fine-Tuning) 方法(如 LoRA、Prefix Tuning 等)[27]-[31],以及基于提示学习(prompt learning)的方法。这些技术在开放领域问答、持续对话系统、跨领域文本生成等任务中展现出极大潜力 [83]-[85]。
1.2 研究挑战与综述目标
MLLM 的快速发展与持续学习研究的深入结合,为探索人工智能前沿方向提供了新的视角 [9], [14], [17], [24], [52], [65], [69], [79], [86]。该领域的关键挑战在于:如何在学习新任务的同时高效保持已有知识,并维持跨模态协同能力 [87]-[89]。这是目前持续学习与 MLLM 结合研究的核心问题之一。 基于现有研究,本文对多模态大型模型持续学习的研究进行系统性综述和总结,重点探讨模型架构与方法的创新,包括不同模型框架的设计、动态参数调整机制,以及支持任务适配的模块 [90]-[93]。这些技术不仅能有效缓解灾难性遗忘问题,还能显著提升 MLLM 的任务适应能力和泛化能力。 此外,本文还介绍了现有的多模态大型模型持续学习评测基准,这些基准测试对评估 MLLM 在持续学习任务中的表现起到重要支持作用 [94]-[97]。多模态大型模型的持续学习研究,不仅为跨模态任务的动态适应提供了新的技术手段,还能为智能教育、医疗、机器人交互等实际应用中的复杂任务提供创新性解决方案 [89], [98]-[100]。 最后,本文对多模态大型模型持续学习的挑战与未来发展趋势进行前瞻性讨论,包括灾难性遗忘问题、评测基准的改进与标准化、多模态持续学习的可解释性与透明度提升等方面。通过这些讨论,本文旨在为该领域的研究者提供有价值的研究洞见,并推动多模态大型模型持续学习技术的进一步发展与应用。
