人工智能(AI)是一种跨行业的趋势性技术,它在从民用日常生活到先进军事技术的许多方面都展示出了其性能和可能性。Tangredi 等人的著作[1]研究了人工智能在美国海军中的影响和应用。早前一篇关于军事科学领域的论文[2]研究了在芬兰特遣舰队中应用人工智能的可能性和限制,从通过融合、放大和自动对象分类来提高传感器的使用率,到支持战术框架中的决策。这两项研究的主要发现之一是,海军部队的某些功能会产生大量数据,只需加以适当利用即可。与此同时,许多功能,如战术决策,并不拥有大量可利用的数据。有关海战的数据主要是历史和传闻;福克兰战争[3]可被视为当前俄乌战争[4]中非对称海战之前现代海战的最新实例。尽管数百年来海战中应用了类似的一般原则,但可以说这些记录并不具备可用于应用人工智能来加强濒海环境中现代作战的数据,而这正是本文的重点。
Tangredi 等人[1]指出,人工智能的决策支持主要包括加强决策分析,因为人工智能解决方案能够处理大量数据。正如文献[2]所研究的那样,利用人工智能支持战术决策可以通过优化自身资源来应对已感知、已分析的威胁,也可以通过创建一个模拟器或游戏,使人们能够针对估计的对手行动方案测试行动计划,或解决一个可能显示任何一方不可预见的战术行动的一般优化问题。最佳行动方案可用于规划自己的战术行动。
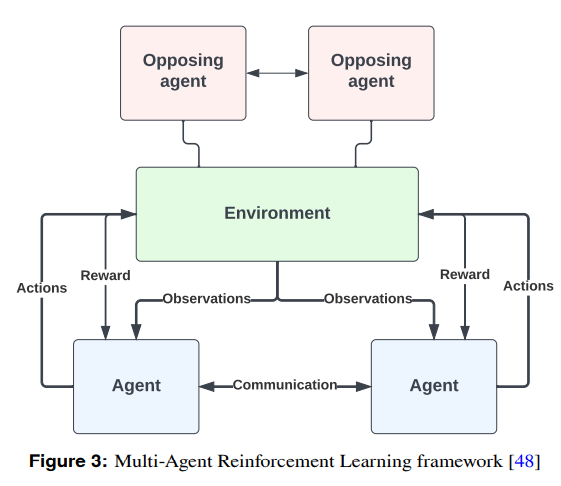
兵棋通常有不止一个玩家或智能体,通常分为两个或更多对立团队。战争包括相当大的不确定性,从人为因素到技术设备及其可靠性,再到天气和其他自然现象的影响,此外还有对手行动和意图的不确定性。这些特点与部分可观测性相结合:与下棋不同,战场或行动区域很少能被参与者完全观测到,至少不能连续观测到,而对手的能力和意图可能在整个行动期间都无法观测到。因此,制定战争场景的合适方法是部分可观测随机博弈(POSG)[5],这是一种将马尔可夫决策过程[6]扩展到多智能体和部分可观测性的数学模型。
在某些条件下,强化学习(RL)能够解决 POSG [5]。在同一游戏概念中,RL 在 DeepMind 的领导下在人工智能界引起了轰动。该公司创造的人工智能 AlphaGo [7] 在与世界冠军李世石的 GO 对弈中获胜。AlphaGo 的一个特别举动让李世石大吃一惊[8],起初似乎是个失误,这可以看作是一个例子,说明人工智能不仅有能力改进以前采用的方法和程序,而且还能想出全新的方法来解决问题,无论是偶然还是有意为之。自 AlphaGo 之后,DeepMind 进一步扩大范围,创建了 AlphaStar [9],它利用多智能体强化学习,在实时战略游戏《星际争霸 II》中跻身人类玩家的前 0.2%。
DeepMind 在将机器学习和强化学习应用于围棋和《星际争霸 II》环境方面表现出色,展示了人工智能在复杂游戏中的能力,但现代军队却缺乏这种能力。这似乎是因为缺乏合适的环境,因为现实世界非常复杂,尤其是在军事环境中。关于可观察性,在围棋比赛中,双方都能充分了解自己和对手的情况,这与军事冲突中双方都喜欢隐藏自己的行动或转移和分散对手注意力的情况截然不同。从这个意义上说,AlphaStar 的表现与《星际争霸 II》不相上下,因为《星际争霸 II》要求玩家侦察对手,并根据部分观察到的数据和不确定性做出决策。确实存在可用于军事领域的环境,例如《指挥》: 现代作战》,它可以模拟 “从二战后到现在及以后的每一次军事交战”[10]。该游戏有许多单元和功能,但如果用于支持决策,则需要大量工作才能与特定场景相匹配。
本文的主要贡献在于展示了如何将 RL 用作战术决策者的决策支持工具。具体做法是将现实世界中的问题制定成数字环境,并训练智能体学习不同的策略。
这些策略代表了可以根据结果进行定量评估的备选行动方案。这样做的目的是通过提供 RL 来加强导致决策的规划过程、
- 备选行动方案
- 对每种备选方案进行定量分析
- 反对规划者和决策者的偏见
- 规划过程的部分自动化和加速
- 拓展战术思维的新颖解决方案
必须起草和分析一组备选方案,为决策者提供支持。因此,RL 可用于学习对问题解决方案产生定量结果的策略。这些结果可用于分析备选方案,并在对特定行动方案的可能结果有了更可靠的了解后,选择最有利的行动方案。
这种方法可以摒弃规划者和决策者的偏见,在进行分析和选定行动方案时,不考虑主观的文化心态,从而得出备选方案。正如约翰-博伊德(John Boyd)上校在其广为人知的 OODA(观察-定向-决策-行动)[26] 理论或决策过程模型中所指出的,定向是 “由遗传基因、文化传统、以往经验和不断发展的环境相互作用形成的”。换言之,决策者的个人特质在决策过程中发挥着不可否认的作用。因此,独立的决策支持系统应能识别不利的偏向,并在客观上实施更好的解决方案。
据笔者所知,在这种情况下还没有进行过类似的研究,在学术上,这是首次展示如何利用 RL 支持濒海海战决策。