摘要: 大型语言模型(LLMs)正迅速从文本生成器演化为强大的问题求解器。然而,许多开放任务要求具备批判性思维、多来源信息整合以及可验证的输出,这些超出了单轮提示或标准的检索增强生成(RAG)所能实现的能力。近期,大量研究开始探索 Deep Research(深度研究,DR),其目标是将 LLM 的推理能力与外部工具(如搜索引擎)相结合,从而使 LLM 具备作为研究型智能体执行复杂、开放式任务的能力。 本综述系统而全面地审视了深度研究系统,包括清晰的发展路线图、基础组成模块、实践层面的实现技术、关键挑战以及未来方向。具体而言,我们的主要贡献如下: (i) 我们形式化提出了一个三阶段的发展路线图,并将深度研究与相关范式区分开来; (ii) 我们介绍了四个关键组成部分:查询规划、信息获取、记忆管理与答案生成,并为每一部分提供了细粒度的子类目体系; (iii) 我们总结了优化技术,包括提示工程、监督微调以及智能体强化学习; (iv) 我们统一整理了评测标准与开放挑战,旨在为未来发展提供指导与推动。 随着深度研究领域的快速演进,我们将持续更新本综述,以反映该领域的最新进展。

1. 引言
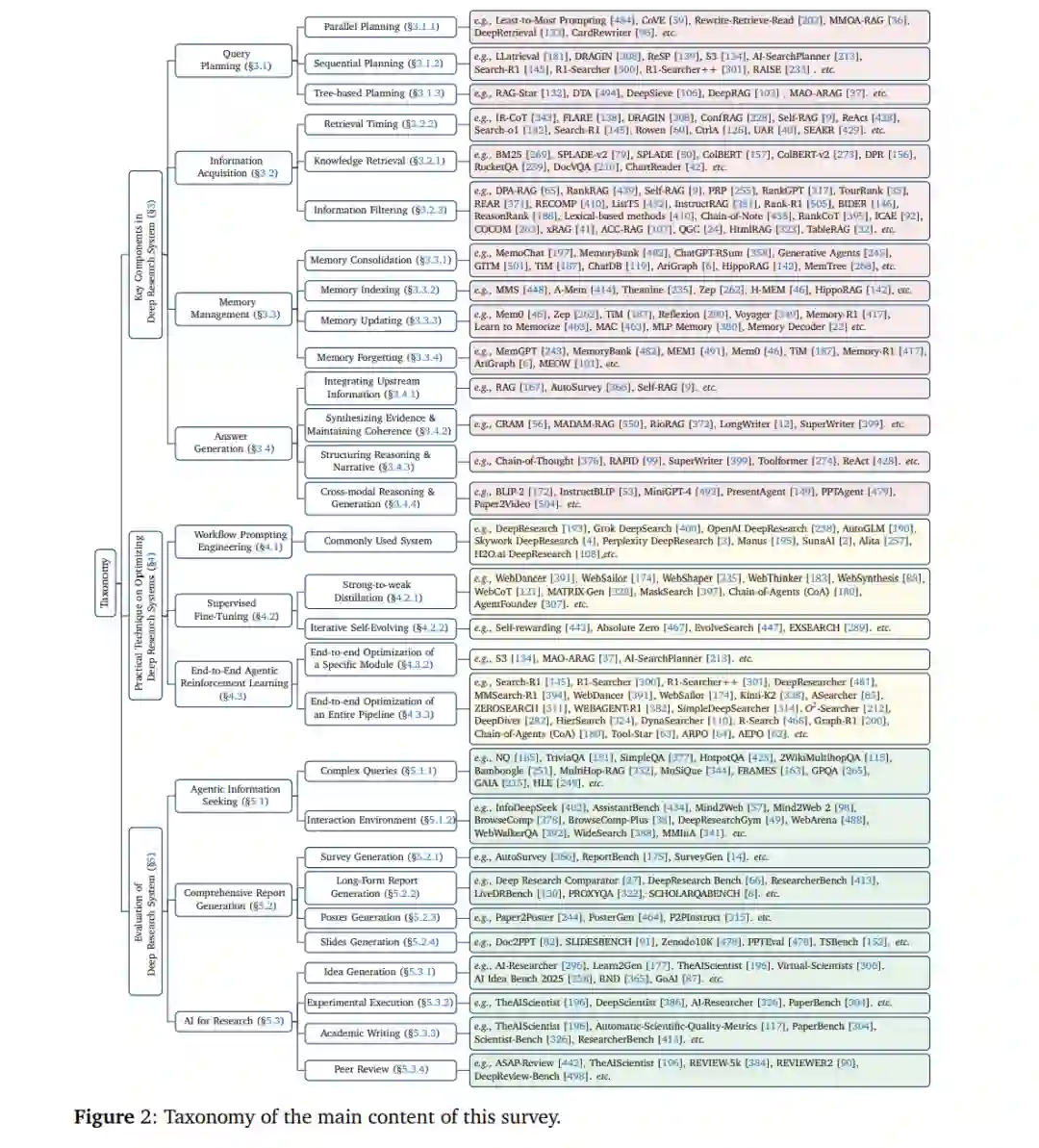
经过大规模网页语料训练的大型语言模型(LLMs)正迅速从流畅的文本生成器演化为能够在实际复杂应用中执行长程推理的自主智能体 [224, 83, 465, 288]。它们在多个领域展现出强泛化能力,包括数学推理 [112, 466]、创造性写作 [95] 以及实用的软件工程 [118, 140, 166]。许多现实世界任务本质上是开放式的,要求批判性思维、基于事实的信息,以及能够独立成文的回应。这远远超出了单轮提示或静态参数化知识所能提供的能力范围 [122, 183, 289]。为弥补这一能力缺口,**Deep Research(深度研究,DR)**范式 [237, 97, 66, 481, 125, 202] 应运而生。DR 将 LLM 纳入一个端到端的研究工作流中,该工作流迭代式地分解复杂问题、通过工具使用获取证据,并将经过验证的见解综合为连贯的长篇回答。 尽管该领域发展迅速,但仍缺乏对 DR 的关键组成、技术细节与开放挑战进行系统性分析的全面综述。现有工作 [458, 31] 多集中于相关领域的发展,如检索增强生成(RAG)与基于 Web 的智能体系统 [401, 200, 285, 456, 316]。然而,与 RAG [89, 72] 相比,DR 采用更灵活、更自主的工作流,不依赖手工构建的流水线,并旨在生成连贯且基于证据的报告。因此,对其技术图景进行清晰梳理已成为紧迫但仍具挑战性的任务。本综述通过提供对 DR 的全面综合来填补这一空白:将其核心组件映射到代表性的系统实现上,整合关键技术与评测方法,并为建立一致的基准测试和推动 AI 驱动的研究持续发展奠定基础。 在本综述中,我们提出了一个面向 DR 系统的三阶段发展路线图,展示其从智能体式信息寻求到自主科学发现等广泛应用。基于该路线图,我们总结了常见 DR 系统的任务求解工作流中的关键组成部分。具体而言,我们介绍 DR 的四个基础组件: (i) 查询规划:将初始输入查询分解成一系列更简单的子查询 [250, 426]; (ii) 信息获取:按需调用外部检索、网页浏览或多种工具 [167, 221]; (iii) 记忆管理:通过受控更新或折叠机制保证与任务求解相关的上下文 [243]; (iv) 答案生成:输出具有明确来源标注的综合性结果,例如科学报告。 这一范围区别于标准 RAG [89, 72] 技术,后者通常将检索视为启发式增强步骤,而不具备灵活的研究工作流或更广泛的行动空间。我们同时介绍如何优化 DR 系统以有效协调这些组件,并将现有方法划分为三类: (i) 工作流提示(workflow prompting); (ii) 监督微调(SFT); (iii) 端到端强化学习(RL)。 本文的结构安排如下:第 2 节给出 DR 的明确定义及其边界;第 3 节介绍 DR 的四个关键组成部分;第 4 节介绍构建 DR 系统的技术细节;第 5 节总结重要的评测数据集与资源;第 6 节讨论未来方向中的挑战。 综上,本综述的主要贡献如下: (i) 我们形式化了 DR 的三阶段路线图,并清晰地区分其与标准检索增强生成等相关技术的差异; (ii) 我们介绍了 DR 系统的四个关键组件,并为每一组件提供细粒度的子类目体系,以全面呈现研究循环; (iii) 我们总结了构建 DR 系统的详细优化方法,为工作流提示、监督微调与强化学习提供实践性洞见; (iv) 我们整合评测标准与开放挑战,旨在支持可比性报告并引导未来研究。
Deep Research 是什么?
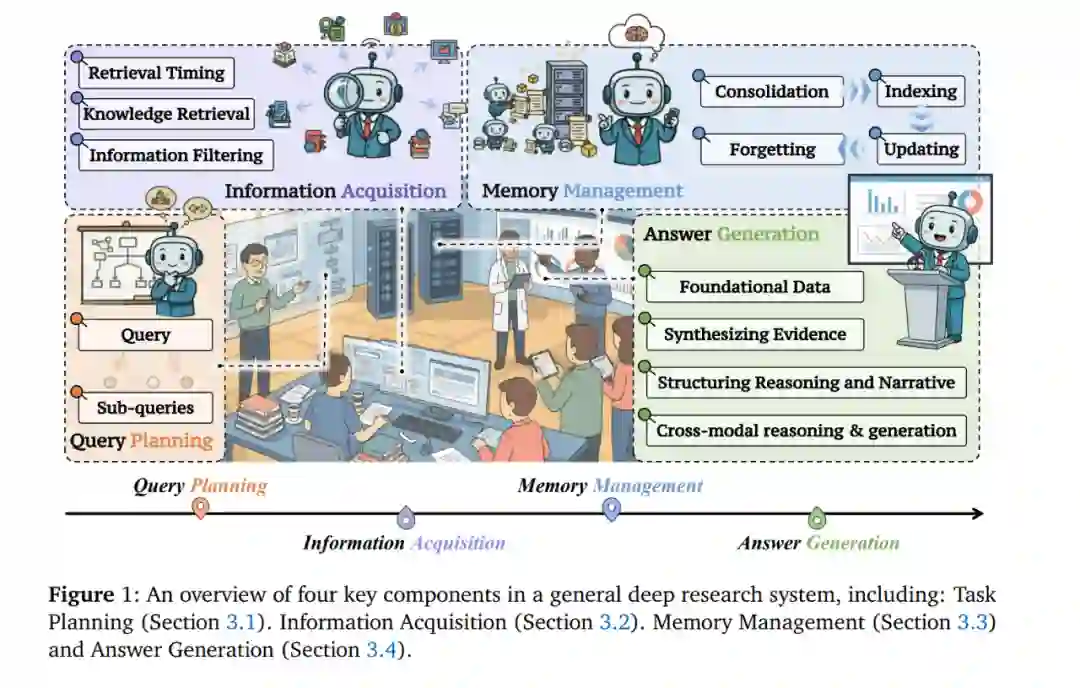
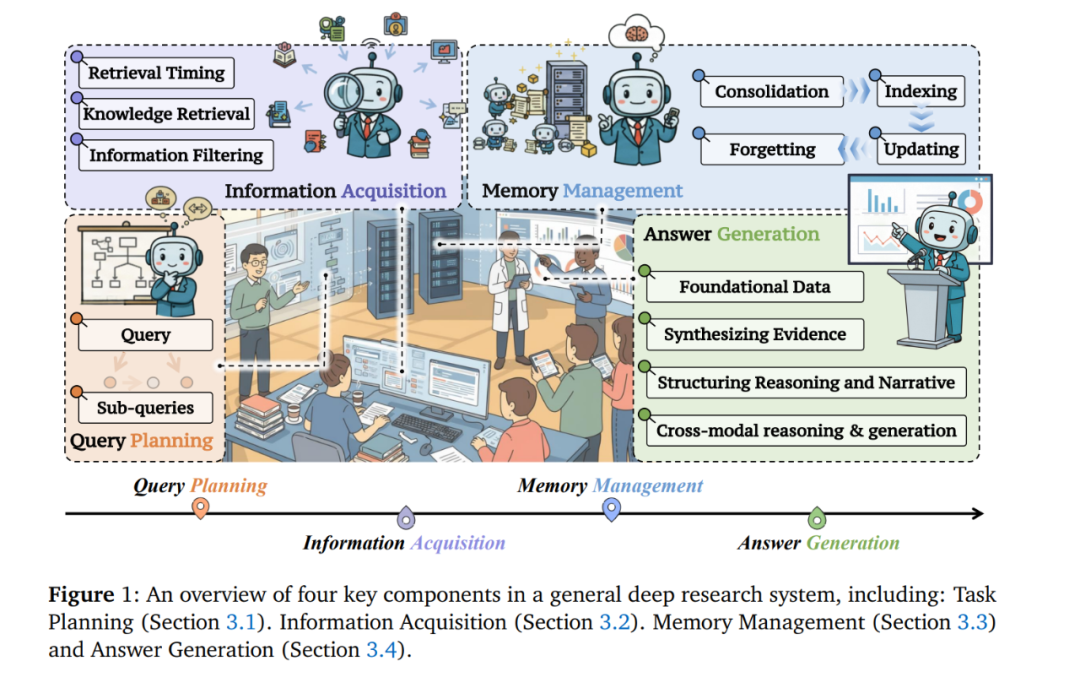
Deep Research(DR)旨在赋予大型语言模型(LLMs)一个端到端的研究工作流,使其能够作为智能体,以最少的人类监督生成连贯且基于来源证据的报告。此类系统自动化整个研究循环,涵盖规划、证据获取、分析与报告撰写。 在 DR 框架下,LLM 智能体负责规划查询、从异构来源(如网页、工具、本地文件)获取并过滤证据、维护和更新工作记忆,并综合生成具有可验证性且带有明确引用的回答。下面,我们正式介绍一个三阶段的发展路线图,用以刻画快速演进、以能力为导向的 DR 研究图景,并将其与传统 RAG 范式进行系统对比。
2.2 从三个阶段理解 Deep Research
我们将 DR 视为一种能力演进轨迹,而非价值层级。以下三个阶段描绘了系统可可靠执行的能力从“精确证据获取”到“可读分析整合”,再到“形成可辩护洞见”的逐步扩展。
Phase I:智能体式检索(Agentic Search)
第一阶段的系统主要擅长寻找正确的来源并提取答案,几乎不进行综合。这类系统通常会对用户查询进行重写或分解以提升召回率,检索并重排序候选文档,应用轻量过滤或压缩,并生成带有明确引用、简洁而准确的答案。核心强调点是:忠实于检索内容与可预测的运行效率。 典型应用包括开放域问答 [227, 165]、多跳问答 [425, 344, 265] 以及其他信息寻求任务 [271, 444, 333, 70, 215],这些任务的“真值”通常局限于少量可检索来源。 评测重点包括: * 检索 recall@k * 答案精确匹配 * 引文正确性 * 端到端延迟
体现了该阶段对每 token 的准确性与操作效率的关注。
Phase II:综合式研究(Integrated Research)
第二阶段的系统跳脱单点事实提取,能够生成连贯、结构化的报告,整合来自多个异构来源的证据,并处理冲突与不确定性。研究循环在此阶段变得显式迭代:系统规划子问题、从多种原始内容(如 HTML [323]、表格 [44, 226]、图表 [208, 208])检索与抽取关键证据,最终综合为叙事性报告。 典型应用包括市场与竞争分析 [469, 347]、政策简报 [356]、满足复杂约束的行程规划 [331],以及其他长程问答任务 [66, 434, 378, 49]。 评测重点从短文本的表层匹配转向长文本质量,包括: * 细粒度事实性 [43, 216] * 引文可验证性 [310, 86] * 结构连贯性 [21] * 关键点覆盖度 [379]
Phase II 以适度增加的计算与复杂度换取显著提升的清晰度、覆盖度与决策支持能力。
Phase III:全栈式 AI 科学家(Full-stack AI Scientist)
第三阶段代表着 DR 的更广阔、更具野心的发展方向,旨在让智能体推进科学理解与创造,而不仅仅是信息整合。在此阶段,DR 智能体不仅要汇聚证据,还需能够: * 生成假设 [490] * 执行实验验证或消融研究 [223] * 批判已有论点 [498] * 提出新的观点 [386]
典型应用包括论文审稿 [506, 248, 498]、科学发现 [460, 292, 291] 与实验自动化 [362, 472]。 评测重点包括: * 发现的创新性与洞见性 * 论证结构的连贯性 * 结论的可复现性(包括是否能够从引用来源或代码重新推导结果) * 不确定性校准与透明性
2.3 Deep Research 与 RAG 的对比
许多现实任务本质上是开放式的,需要批判性思维、基于事实的信息,以及可独立成文的回答。这些需求暴露出现有方法(包括传统 RAG 或简单扩大 LLM 参数规模)难以解决的核心局限。以下总结了三类关键挑战:
• 与数字世界的灵活交互
传统 RAG 工作流基于静态检索,依赖预先索引的语料库 [232, 225]。然而现实任务通常要求主动与动态环境交互,如搜索引擎、Web API、代码执行器等 [487, 223, 362]。 DR 系统扩展了这一范式,使 LLM 能够执行多步、工具增强的交互,从而获取最新信息、执行操作并在数字生态中验证假设。
• 自主工作流的长程规划
研究型任务通常包含多子任务协作 [378]、任务上下文管理 [411],以及中间过程的迭代优化 [290]。 DR 通过闭环控制与多轮推理支持智能体实现自主规划、修正与优化,以达成长程目标。
• 面向开放任务的可靠语言接口
LLM 在开放式任务中容易产生幻觉与不一致性 [109, 471, 123, 13, 52]。 DR 系统通过可验证机制,将自然语言输出与真实证据对齐,从而构建更可靠的人类—智能体交互接口。