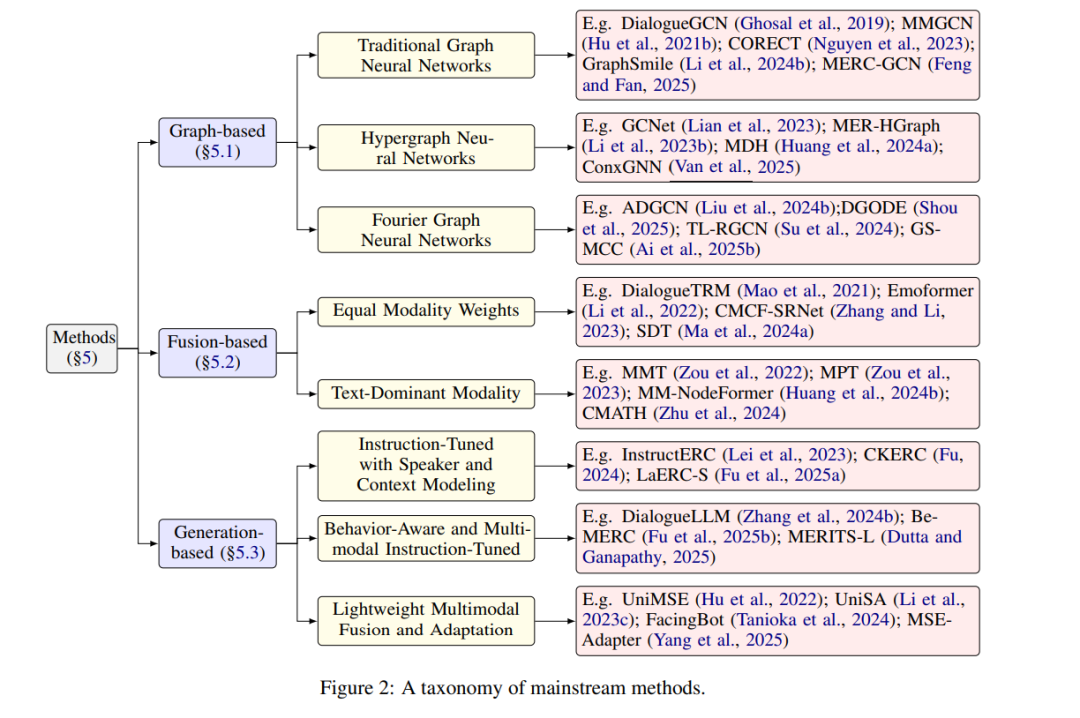
尽管基于文本的情感识别方法已取得显著成果,但现实世界中的对话系统往往需要比单一模态所能提供的更细腻的情感理解。因此,「多模态对话情感识别(MERC)」已成为提升人机交互自然性和情感理解能力的重要研究方向。其目标是通过融合文本、语音和视觉信号等多种模态的信息,准确识别用户情感。 本综述系统性地回顾了MERC的研究现状,包括其研究动机、核心任务、代表性方法和评估策略。我们还进一步探讨了该领域的最新发展趋势,指出了面临的关键挑战,并展望了未来研究方向。随着对情感智能系统的关注日益增加,本综述为推动MERC研究提供了及时而有价值的参考。
1 引言
对话情感识别(Emotion Recognition in Conversations, ERC)(Peng 等, 2022;Deng 和 Ren, 2023)是自然语言处理(NLP)中日益重要的研究任务,旨在识别对话中每个发言所表达的情绪状态。与传统的孤立句子情感分类不同,ERC 需要理解各个发言之间的相互关系,并跟踪对话过程中特定说话人的上下文信息(Gao 等, 2024)。
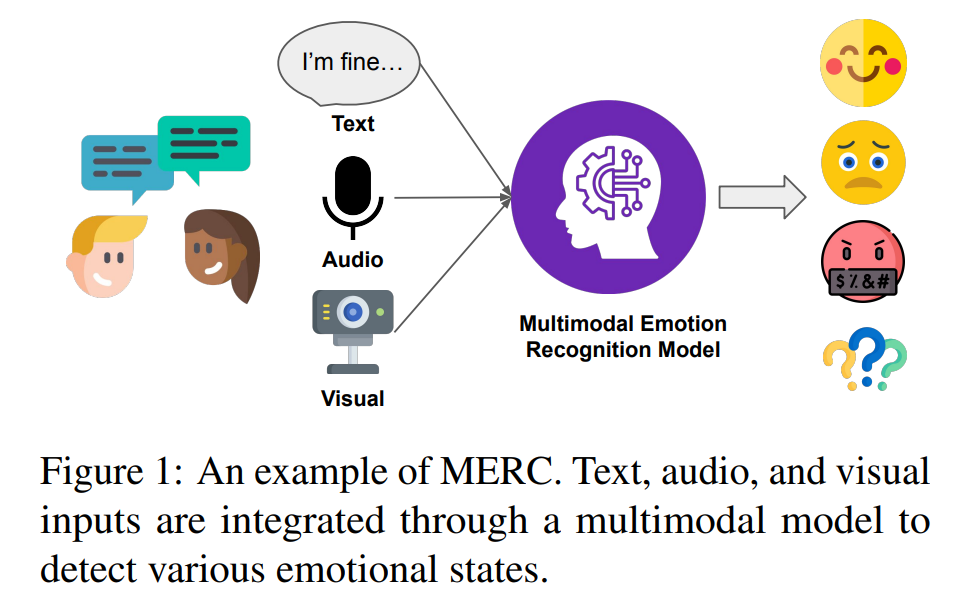
ERC 的研究热度不断上升,源于其在多个现实应用场景中的潜力,例如社交媒体监测(Kumar 等, 2015)、智能医疗服务(Hu 等, 2021b)以及情感感知对话系统的设计(Jiao 等, 2020;Gong 等, 2023)。 然而,人类情绪通常通过多种感知通道传达,包括听觉、视觉和语言。因此,近年来的研究(如 Ma 等, 2024a;Van 等, 2025;Dutta 和 Ganapathy, 2025)越来越多地聚焦于多模态对话场景,这一方向被称为「多模态对话情感识别」(Multimodal Emotion Recognition in Conversations, MERC)。研究者试图通过融合来自不同模态的上下文信息,识别特定发言的情绪状态,这些状态通常包括诸如快乐、愤怒和憎恨等细腻的个体情感(Poria 等, 2019b;Gong 等, 2024),从而提升对话中情感识别的效果。图1展示了一个结合文本、音频和视觉输入的ERC示例。
多模态情感识别(Multimodal Emotion Recognition, MER)本身也日益受到关注,主要源于多模态融合的挑战性,促使研究扩展到非对话和对话两种场景。现有综述(如 A.V. 等, 2024;Aruna Gladys 和 Vetriselvi, 2023)主要聚焦于非对话场景的MER,忽略了对话者建模和上下文建模等关键问题。Fu 等(2023)回顾了单模态与多模态的对话情感识别,但其主要聚焦于特征融合,未能深入探讨跨模态对齐、推理能力、模态缺失和模态冲突等核心挑战。 尽管MERC受到越来越多的关注,但该任务仍相对缺乏深入研究。现有综述(Fu 等, 2023;Zhang 和 Tan, 2024)在某些方面已滞后于最新进展,尤其是在多模态大语言模型(Multimodal Large Language Models, MLLMs)崛起之后。为填补这一空白,本文对MERC进行了全面而及时的综述。我们首先介绍任务定义与综述方法(第§2节)、基准数据集与评估方法(第§3节),接着回顾预处理技术(第§4节),分类整理近期研究方法(第§5节),并分析面临的关键挑战及未来发展方向(第§6节)。 总之,本文的主要贡献包括三方面: * 汇总近期MERC研究进展:系统回顾并整合近年来MERC领域的最新研究成果,涵盖多样化的数据集与方法。 * 总结与比较不同MERC方法:评估多种MERC方法的优劣,提供理论洞见与实践指导,帮助研究者与工程师选择适合的解决方案。 * 提出挑战与未来方向:识别当前MERC领域中的关键开放问题,并提出若干潜在的研究方向,以指导今后的研究与开发工作。