本文介绍了在定制的 Pygame 仿真环境中开发的基于人工智能(AI)的战斗机智能体,旨在通过深度强化学习(DRL)解决多目标任务。喷气式战斗机的主要目标包括高效地在环境中导航、到达目标以及选择性地与敌人交战或躲避敌人。奖励函数平衡了这些目标,而优化的超参数则提高了学习效率。结果显示,任务完成率超过 80%,证明了决策的有效性。为了提高透明度,通过比较实际选择的行动(事实行动)和替代行动(反事实行动)的奖励,对喷气机的行动选择进行了分析,从而深入了解了决策原理。这项研究说明了 DRL 在利用可解释的人工智能解决多目标问题方面的潜力。
在定制模拟环境中开发了一个可解释的深度强化学习智能体,以透明决策的方式解决复杂的多目标任务。
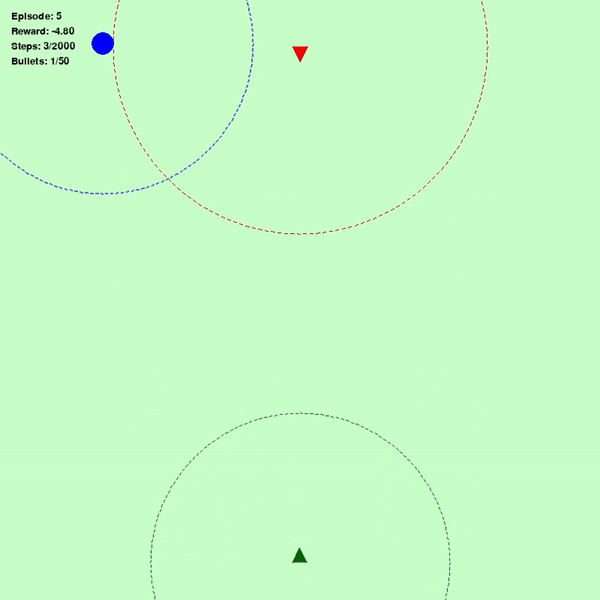
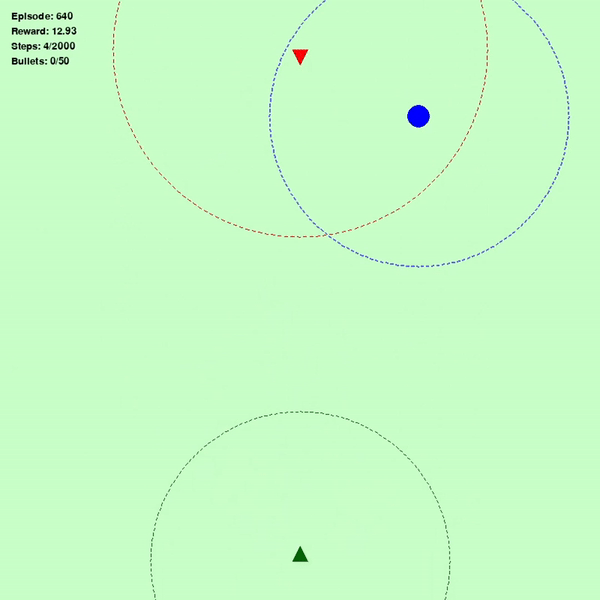
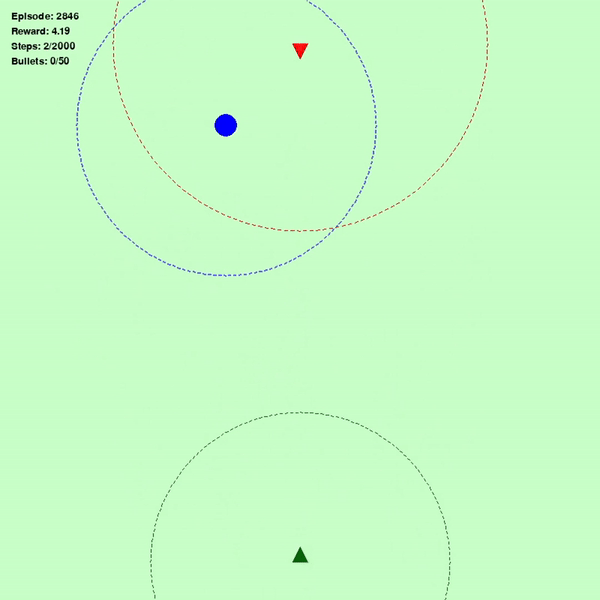
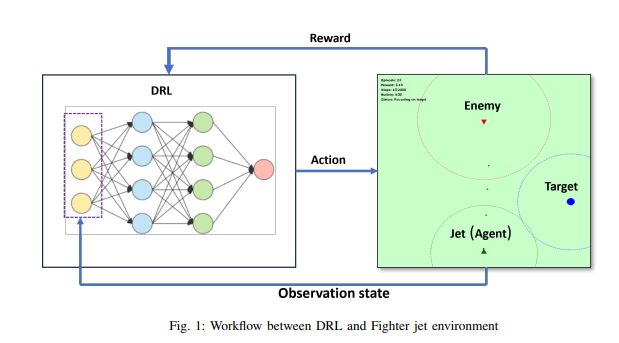
图 1(左)表示智能体最初阶段的表现(绿色三角形:智能体,红色三角形:敌人,蓝色圆圈:目标),图 2(中)表示智能体学习 640 次后的表现,图 3(右)表示智能体完全了解环境后的表现
贡献
-
复杂的奖励功能设计: 开发了一种全面的奖励功能,可平衡多种相互竞争的目标,如效率和资源管理。该功能整合了推动有效学习的各种因素,鼓励智能体优化任务完成和可用资源的使用。
-
在定制模拟环境中实施 DRL 智能体: 在一个定制的 Pygame 模拟环境中构建并训练了一个基于 DRL 的智能体,以解决一个具有多重目标的复杂问题--导航环境、击中指定目标以及适当地避开或与敌人交战。该智能体在超过 80% 的试验中成功完成了任务,展示了在各种场景下的强大决策能力。
-
全面的学习曲线分析: 对智能体的学习轨迹进行了详细分析,展示了从最初的表现不佳到任务完成效率提高的过程。该分析突出了智能体如何随着时间的推移完善其策略,有助于加深对 DRL 学习过程的理解。
-
推进多目标问题的可解释人工智能: 该项目证明 DRL 能够有效解决复杂的多目标问题。从奖励函数和决策分析中获得的见解有助于更广泛地理解和改进人工智能驱动过程中的可解释性。
-
通过事实和反事实分析实现可解释性: 通过研究事实和反事实行动与奖励,该项目提高了智能体决策过程的透明度。这种分析提供了重要的洞察力,让用户了解为什么会选择某些行动而不是其他行动,从而理解特定决策背后的原因,尤其是在需要快速反应的复杂场景中。