

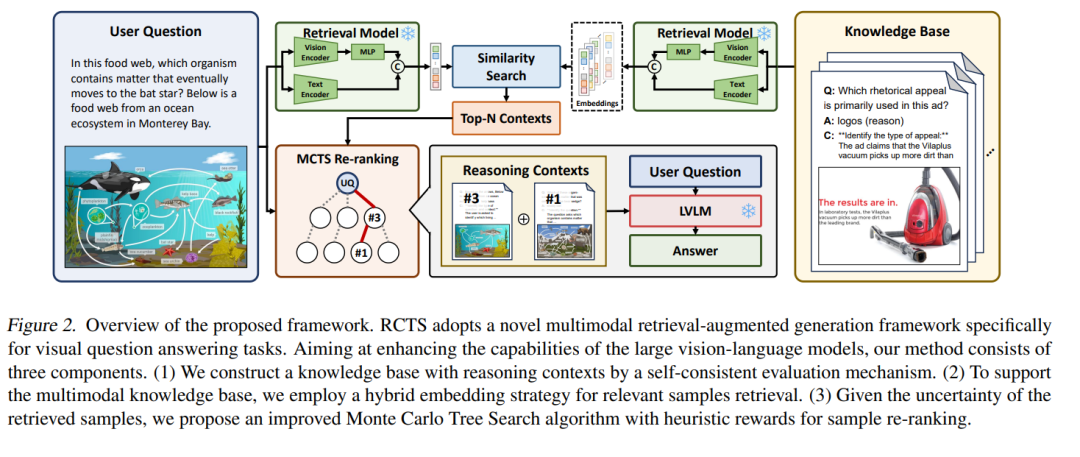
近年来,大型视觉语言模型(Large Vision Language Models, LVLMs)在视觉问答(Visual Question Answering, VQA)任务中的表现因多模态检索增强生成(Retrieval-Augmented Generation, RAG)方法而显著提升。然而,现有方法仍面临诸多挑战,例如包含推理示例的知识稀缺,以及检索到的知识响应不稳定等问题。为了解决这些问题,本文提出了一种多模态 RAG 框架,称为 RCTS,该框架通过构建富含推理上下文的知识库以及引入树搜索重排序方法来增强 LVLM 的推理能力。 具体而言,我们引入了一种自洽的评估机制,用于将内在的推理模式纳入知识库,从而丰富其内容。同时,我们提出了一种结合启发式奖励的蒙特卡洛树搜索算法(Monte Carlo Tree Search with Heuristic Rewards, MCTS-HR),用于优先选择与当前任务最相关的推理示例。这一机制确保了 LVLMs 能够利用高质量的上下文推理信息,生成更优且更一致的回答。
大量实验证明,我们提出的框架在多个 VQA 数据集上均取得了当前最优性能,显著优于上下文学习(In-Context Learning, ICL)和基础 RAG 方法(Vanilla-RAG)。这突显了我们所构建的知识库和重排序方法在提升 LVLM 表现方面的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
211+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
211+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日