
【导读】图像分割(Image Segmentation)是计算机视觉的经典问题之一,受到了广泛关注,每年在各大会议上都有大量的相关文章发表。在前深度学习时代有大量的方法提出,比如分水岭、GraphCut等。随着深度学习的兴起,大量的算法提出如R-CNN、Mask-RCNN等。最近来自Snapchat、滑铁卢大学、UCLA等学者发布了深度学习图像分割最新综述论文,涵盖20页pdf196篇参考文献,调研了截止2020年提出的100多种分割算法,共分为10类方法。对近几年深度学习图像分割进行了全面综述,对现有的深度学习图像分割研究进行梳理使其系统化,并提出7方面挑战,帮助读者更好地了解当前的研究现状和思路。可作为相关领域从业者的必备参考文献。
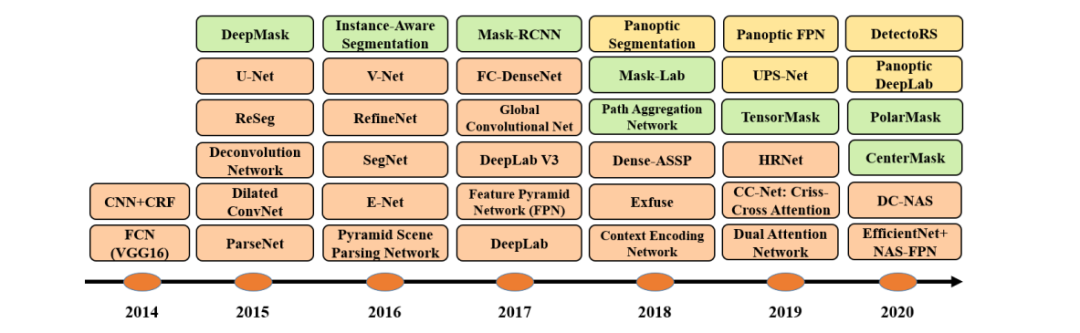
基于深度学习的二维图像分割算法的时间轴。橙色块表示语义块,绿色块表示实例块。
题目:Image Segmentation Using Deep Learning: A Survey
作者:Shervin Minaee, Member, IEEE, Yuri Boykov, Member, IEEE, Fatih Porikli, Fellow, IEEE, Antonio Plaza, Fellow, IEEE, Nasser Kehtarnavaz, Fellow, IEEE, and Demetri Terzopoulos, Fellow, IEEE

摘要
图像分割是图像处理和计算机视觉领域的一个重要课题,其应用领域包括场景理解、医学图像分析、机器人感知、视频监控、增强现实和图像压缩等。研究者们提出了各种图像分割算法。最近,由于深度学习模型在广泛的视觉应用中取得了成功,已经有大量的工作致力于开发使用深度学习模型的图像分割方法。在本次综述中,我们全面回顾了撰写本文时的论文,涵盖了语义级和实例级分割的广泛先驱工作,包括全卷积像素标记网络、编码器-解码器架构、基于多尺度和金字塔的方法、递归网络、视觉注意力模型和在对抗环境下的生成模型。我们调研了这些深度学习模型的相似性、优势和挑战,研究了最广泛使用的数据集,报告了性能,并讨论了该领域未来的研究方向。
1. 引言
从早期的[1]领域开始,图像分割就一直是计算机视觉的一个基本问题(第8章)。它涉及到将图像(或视频帧)分割成多个片段和目标2,并在广泛的应用领域3中发挥着核心作用,包括医学图像分析(如肿瘤边界提取和组织体积测量)、自动驾驶车辆(如可导航表面和行人检测)、视频监控,增强现实等等。从最早的阈值化[3]、基于直方图的分组、区域生长[4]、k-means聚类[5]、分水岭[6]等算法,到更先进的主动轮廓[7]、图割[8]、条件和马尔科夫随机域[9]、稀疏[10]-[11]等算法,文献中已经出现了许多图像分割算法。然而,在过去的几年里,深度学习(DL)网络已经产生了新一代的图像分割模型,其性能有了显著的提高——通常在流行的基准测试中获得了最高的准确率——致使许多人认为的该领域的范式转变。例如,图1展示了一个著名的深度学习模型DeepLabv3[12]的样本图像分割输出。

图1: DeepLabV3[12]对样本图像的分割结果。
图像分割可以表示为带有语义标签的像素分类问题(语义分割)或单个对象的分割问题(实例分割)。语义分割是对所有图像像素进行一组对象类别(如人、车、树、天空)的像素级标记,因此通常比图像分类更难,因为后者预测整个图像的单个标签。实例分割进一步扩展了语义分割的范围,通过检测和描绘图像中每个感兴趣的对象(例如,对个人的分割)。
我们的调研涵盖了图像分割的最新文献,并讨论了到2019年提出的一百多种基于深度学习的分割方法。我们对这些方法的不同方面提供了全面的回顾和见解,包括培训数据、网络架构的选择、损失功能、培训策略以及它们的关键贡献。我们对所述方法的性能进行了比较总结,并讨论了基于深度学习的图像分割模型的几个挑战和未来可能的方向。
我们将基于深度学习的工作根据其主要技术贡献分为以下几类:
- 完全卷积网络
- 卷积模型与图形模型
- Encoder-decoder基础模型
- 基于多尺度和金字塔网络的模型
- 基于R-CNN的模型(例如实例分割)
- 扩展卷积模型和DeepLab家族
- 基于递归神经网络的模型
- 基于注意力的模型
- 生成模型和对抗性训练
- 具有活动轮廓模型的卷积模型
- 其他模型
本综述论文的一些主要贡献可以总结如下:
- 我们对基于深度学习的图像分割算法进行了全面的回顾和分析;
- 概述了常用的图像分割数据集,分为2D和2.5D (RGB-D)图像;
- 我们总结了综述的分割方法在流行基准上的性能;
- 讨论了基于深度学习的图像分割的几个挑战和未来的研究方向。
该调研的其余部分组织如下: 第2节提供了流行的深度神经网络架构的概述,作为许多现代分割算法的主干。第3节全面概述了最重要的、最先进的、基于深度学习的细分模型。第四部分回顾了一些最流行的图像分割数据集及其特点。第5.1节回顾了评价基于深度学习的细分模型的流行指标。在5.2节中,我们报告了这些模型的定量结果和实验性能。在第6节中,我们将讨论基于深度学习的分割方法的主要挑战和未来的发展方向。最后,我们在第7节中提出我们的结论。
2 深度神经网络概述
本节概述计算机视觉社区使用的一些最著名的深度学习体系结构,包括卷积神经网络(CNNs)[13]、递归神经网络(RNNs)和长短时记忆(LSTM)[14]、编码器-解码器[15]和生成对抗网络(GANs)[16]。随着近年来深度学习的流行,一些其他的深度神经结构也被提出,如Transformer、Capsule网络、门控递归单元、空间变压器网络等,在此不再赘述。
2.1 卷积神经网络(CONVOLUTIONAL NEURAL NETWORKS, CNNS)
CNNs是深度学习社区中最成功和最广泛使用的架构之一,特别是在计算机视觉任务中。CNNs最初是由福岛在他的开创性论文“新认知元”[17]中提出的,基于Hubel和Wiesel提出的视觉皮层的分级接受域模型。随后,Waibel等人[18]引入了具有时间接受域权值共享的CNNs和用于音素识别的反向传播训练,LeCun等人[13]开发了用于文档识别的CNN架构(图2)。
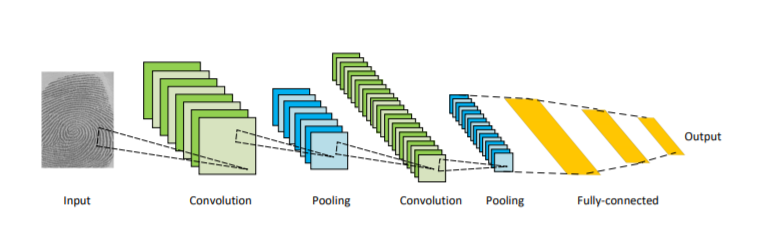
图 2 卷积神经网络的体系结构,从[13]。
CNNs主要包括三种类型的层: i)卷积层,在卷积层中,通过卷积一个权值的核(或过滤器)来提取特征;** ii)非线性层**,在特征图(通常是元素层面)上应用激活函数,通过网络对非线性函数进行建模; iii)池化层,用关于邻域的一些统计信息(平均值、最大值等)代替特征图的小邻域,并降低空间分辨率。各层单元局部连接; 也就是说,每一个单元都从一个叫做接受域的小邻域接受加权输入,这个邻域是前一层单元的感受野。通过堆叠层形成多分辨率的金字塔,高层次从越来越广泛的感受野学习特征。CNNs的主要计算优势是一个层中所有的接受域共享权值,这使得参数的数量明显小于全连通神经网络。一些最著名的CNN架构包括:AlexNet [19], VGGNet [20], ResNet [21], GoogLeNet [22], MobileNet[23],和DenseNet[24]。
2.2 递归神经网络(RNNS)和LSTM
RNNs[25]广泛用于处理顺序数据,如语音、文本、视频和时间序列,其中任意给定时间/位置的数据取决于以前遇到的数据。
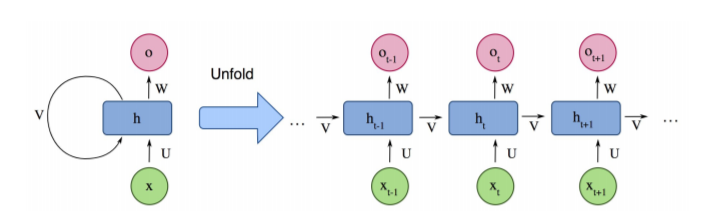
图 3 简单递归神经网络结构。
2.3 编码器-解码器和自动编码器模型
编码器-解码器模型是一组模型,这些模型通过两级网络将数据点从输入域映射到输出域: 编码器(由编码函数表示)将输入压缩到一个潜在空间表示;解码器的目标是预测潜在空间表示的输出。
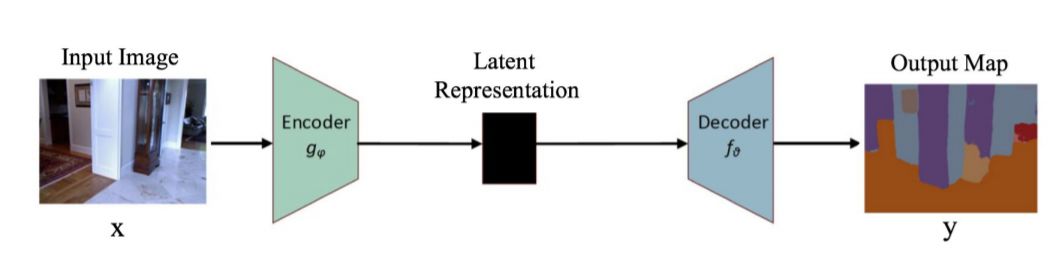
图 4 一个简单的编码器-解码器模型的结构。
2.4 生成式对抗网络(GANS)
GANs是一种较新的深度学习模型家族[16]。它们由两个网络组成——一个生成器和一个鉴别器(图6)。传统GAN中的生成器网络学习从噪声(带有先验分布)到目标分布的映射,这类似于“真实”样本。鉴别器网络试图将生成的样本(“假货”)与“真货”区分开来。
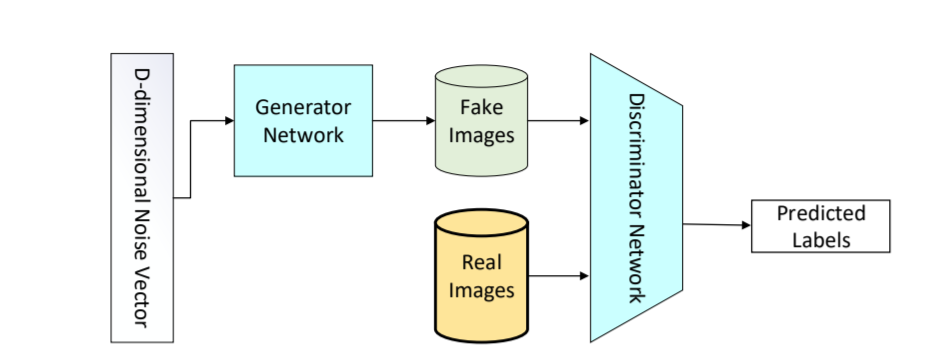
图 5. GAN架构
2.5 迁移学习
在某些情况下, 可以训练DL-models基于新的应用程序有足够多数据集(假设足够数量的标签的训练数据), 但在许多情况下没有足够的标签数据从头训练模型和一个可以使用迁移学习来解决这个问题。在迁移学习中,一个在一个任务上训练的模型被重新用于另一个(相关的)任务,通常是通过一些对新任务的适应过程。例如,可以设想将在ImageNet上训练的图像分类模型用于不同的任务,例如纹理分类或人脸识别。在图像分割的情况下,许多人使用在ImageNet(一个比大多数图像分割数据集更大的数据集)上训练的模型作为网络的编码器,并从这些初始权值重新训练他们的模型。这里的假设是,这些预先训练的模型应该能够捕获分割所需的图像的语义信息,从而使它们能够用较少标记的样本训练模型。
3 基于深度学习的图像分割模型
本节详细回顾了到2019年提出的100多种基于深度学习的细分方法,并将其分为10个类别。值得一提的是,有一些部件在这些工作中是很常见的,比如有编码器和解码器部分,跳连接,多尺度分析,以及最近使用的膨胀卷积。因此,很难提及每个工作的独特贡献,但是根据它们对先前工作的基础架构贡献将它们分组比较容易。
3.1 全卷积网络
Long等人利用全卷积网络(FCN)提出了最早的语义图像分割深度学习算法之一。FCN(图7)只包含卷积层,这使得它可以获取任意大小的图像并生成相同大小的分割图。作者修改了现有的CNN架构,比如VGG16和GoogLeNet,通过用全卷积层替换所有全连接层来管理非固定大小的输入和输出。因此,该模型输出的是空间分割地图,而不是分类分数。
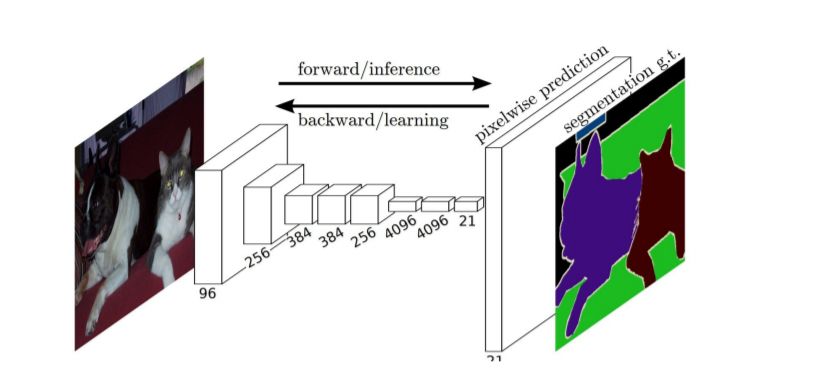
图 6 全卷积图像分割网络。FCN学习做出密集的像素级预测 [32]。
通过使用跳跃连接,将模型最后一层的特征图向上采样,并与较早一层的特征图融合,该模型结合了语义信息(来自较深、较粗的层)和外观信息(来自较浅、较细的层),以产生准确、详细的分段。该模型在PASCAL VOC、NYUDv2和SIFT Flow上进行了测试,获得了最优的分割性能。
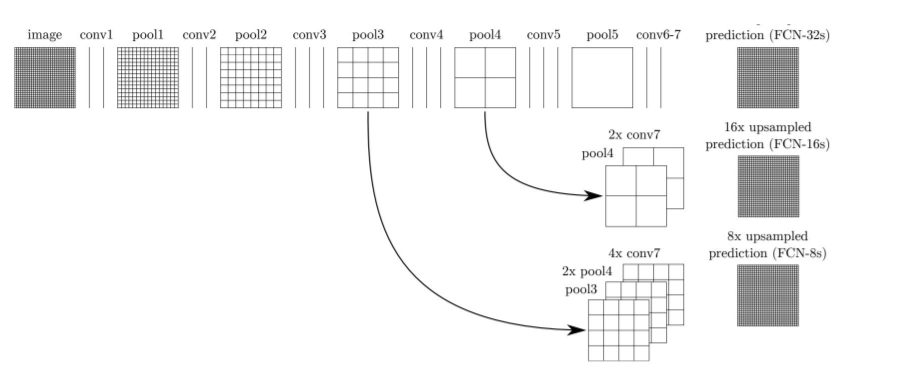
图 7: Skip连接将粗糙的高级信息和精细的低级信息结合起来。从[32]。
例如,Liu等人提出了一个名为ParseNet的模型,用于解决FCN忽略全局上下文信息的问题。ParseNet通过使用层的平均特性来增加每个位置的特性,从而将全局上下文添加到FCNs中。一个层的特征映射被合并到整个图像上,产生一个上下文向量。这个上下文向量被归一化和未合并,以生成与初始特征图大小相同的新特征图。然后将这些特征映射连接起来。简而言之,ParseNet是一个FCN,所描述的模块替换了卷积层。
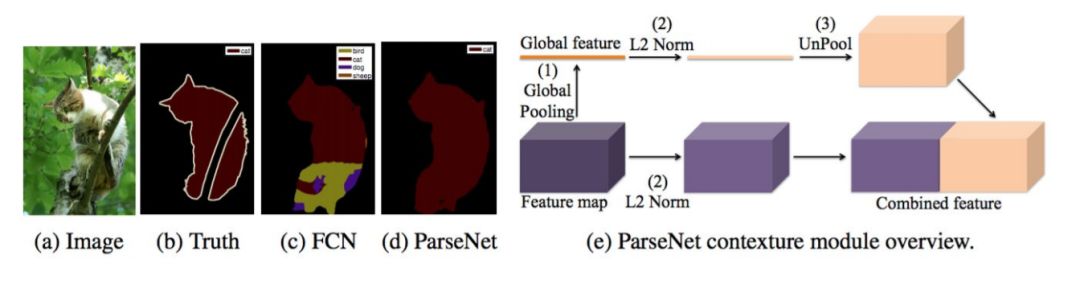
图 8: ParseNet,显示了使用额外的全局上下文来产生比FCN (c)更平滑的分割(d)。
FCNs已经应用于多种分割问题,如脑瘤分割[34],实例感知语义分割[35],皮损分割[36],虹膜分割[37]。
3.2 卷积模型与图形模型
如前所述,FCN忽略了可能有用的场景级语义上下文。为了集成更多的上下文,有几种方法将概率图形模型(如条件随机域(CRFs)和马尔可夫随机域(MRFs))合并到DL体系结构中。
Chen等人[38]提出了一种基于CNNs与全连通CRFs结合的语义分割算法(图9)。他们发现,来自深层CNNs的最后一层的响应并没有足够的本地化以进行精确的对象分割(这是由于CNNs的不变性使其适合于分类等高级任务)。为了克服深度CNNs定位性能差的问题,他们将最后一层的响应与全连接的CRF相结合。他们证明了他们的模型能够以比以前方法更高的准确率定位线段边界。
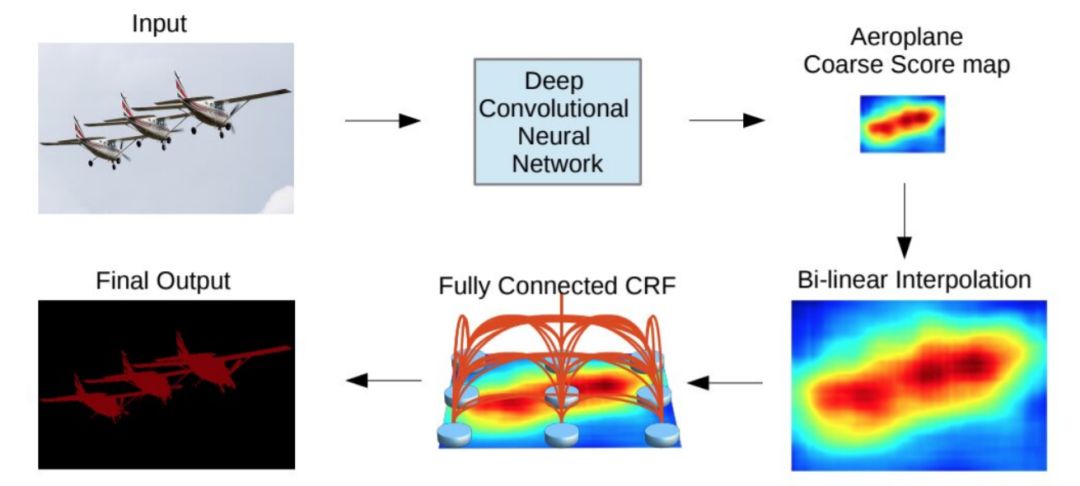
图 9: CNN+CRF模型。将CNN的粗分数图通过内插插值进行上采样,并将其反馈给一个全连通的CRF,对分割结果进行细化。从[38]。
3.3 基于编解码器的模型
另一种流行的图像分割深度模型是基于卷积编码-解码器结构。大多数基于dll的分割工作都使用了某种编解码器模型。我们将这些工作分为两类,用于一般分割的编码器-解码器模型和用于医学图像分割(以便更好地区分应用程序)。
通用分割的编码器-解码器模型
Noh等人[43]发表了一篇关于基于反卷积(又称置换卷积)的语义分割的早期论文。他们的模型(图10)由两个部分组成,一个编码器采用VGG 16层网络中的卷积层,另一个反卷积网络以特征向量为输入,生成像素级的类概率图。反卷积网络由反卷积层和反池层组成,它们识别像素级标签并预测分割掩码。
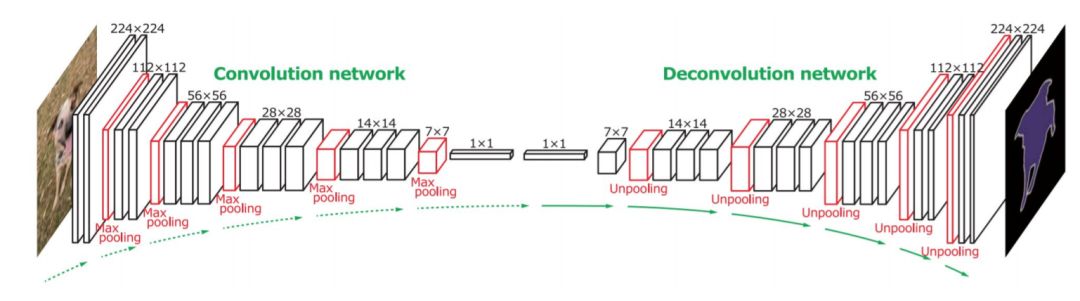
图 10: 反卷积语义分割。其次是基于VGG 16层网的卷积网络,是一个多层反卷积网络来生成精确的分割图。从[43]。
在另一个很有前途的工作被称为SegNet, Badrinarayanan等人的[44]提出了一个卷积编码器-解码器架构的图像分割。
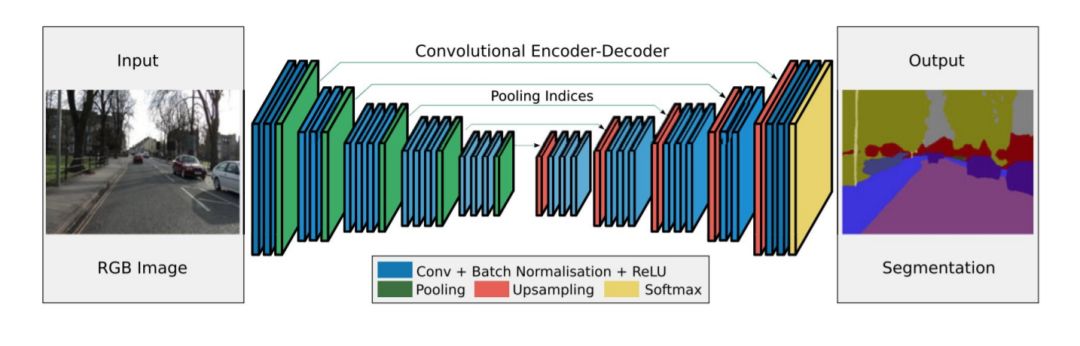
图 11: SegNet没有全连通层; 因此,该模型是完全卷积的。解码器使用从编码器传输的池索引对其输入进行上采样,以生成稀疏特征映射。从[44]。
用于医学和生物医学图像分割的编码器-解码器模型
受FCNs和编译码器模型的启发,有几种医学/生物医学图像分割的初步模型。U-Net[50]和V-Net[51]是两个著名的这样的架构,现在也在医疗领域之外使用。
Ronneberger等人提出了用于分割生物显微镜图像的u型网。他们的网络和训练策略依赖于使用数据扩充来更有效地从可用的带注释的图像中学习。U-Net体系结构(图13)由两部分组成,一部分是捕获上下文的收缩路径,另一部分是支持精确定位的对称扩展路径。
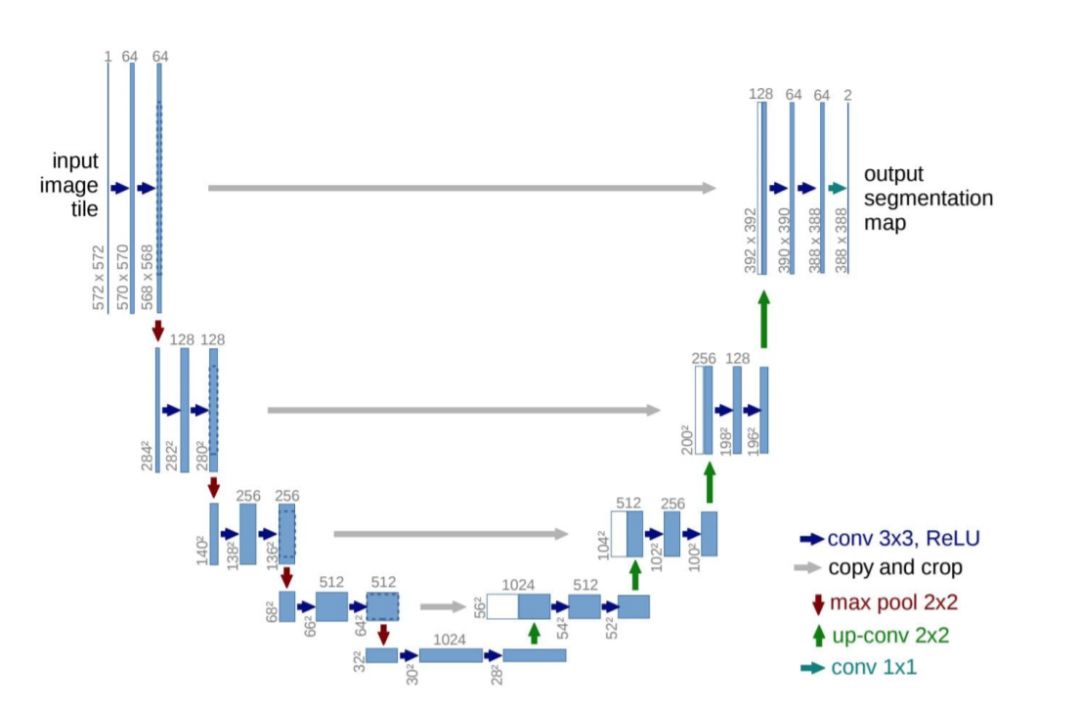
图 12: U-net模型。蓝色方框表示具有指定形状的feature map块。从[50]。

图 13 三维图像分割的V-net模型。从[51]。
V-Net(图14)是另一个著名的基于fcn的模型,由Milletari等人提出用于三维医学图像分割的[51]。在模型训练方面,他们引入了一种新的基于Dice系数的目标函数,使模型能够处理前景和背景中体素数量严重不平衡的情况。该网络被端对端地训练成描绘前列腺的MRI容积,并学会立即预测整个容积的分割。
3.4 基于多尺度和金字塔网络的模型
多尺度分析是图像处理中一个非常古老的概念,在各种神经网络结构中得到了广泛的应用。这类模型中最突出的是Lin等人提出的特征金字塔网络(Feature Pyramid Network, FPN),它主要用于目标检测,后来也被应用于分割。利用深锥神经网络固有的多尺度金字塔结构,构造边际额外成本的特征金字塔。为了融合低分辨率和高分辨率的特征,FPN由自下而上的通路、自上而下的通路和横向连接组成。然后通过3×3的卷积对拼接后的特征图进行处理,得到每个阶段的输出。最后,自顶向下路径的每个阶段生成一个预测来检测一个对象。对于图像分割,作者使用了两个多层感知器(MLPs)来生成掩码。
Zhao等人开发了金字塔场景解析网络(PSPN),这是一种多尺度网络,可以更好地学习场景的全局上下文表示。
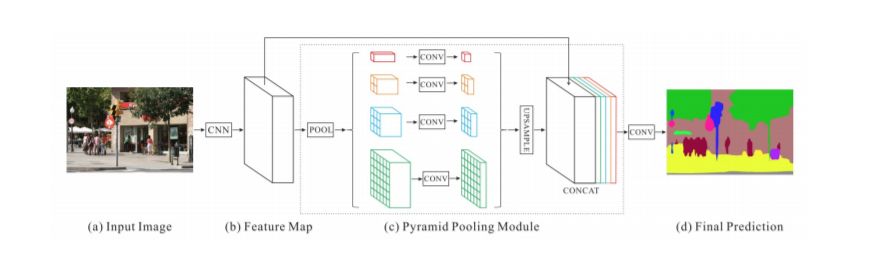
图 14: PSPN架构。CNN生成特征图,金字塔池模块聚合不同的子区域表示。利用上采样和拼接形成最终的特征表示,通过卷积得到最终的像素级预测。从[57]。
3.5 基于R-CNN的模型(实例分割)
区域卷积网络(R-CNN)及其扩展(Fast R-CNN、Faster R-CNN、Maksed-RCNN)已被证明在对象检测应用中是成功的。R-CNN的一些扩展被大量用于解决实例分割问题;即。的任务,同时执行对象检测和语义分割。特别是,更快的R-CNN[64]体系结构(图16)使用区域建议网络(RPN)提出边界框候选。RPN提取感兴趣区域(RoI), RoIPool层根据这些建议计算特征,以推断边界框坐标和对象的类。
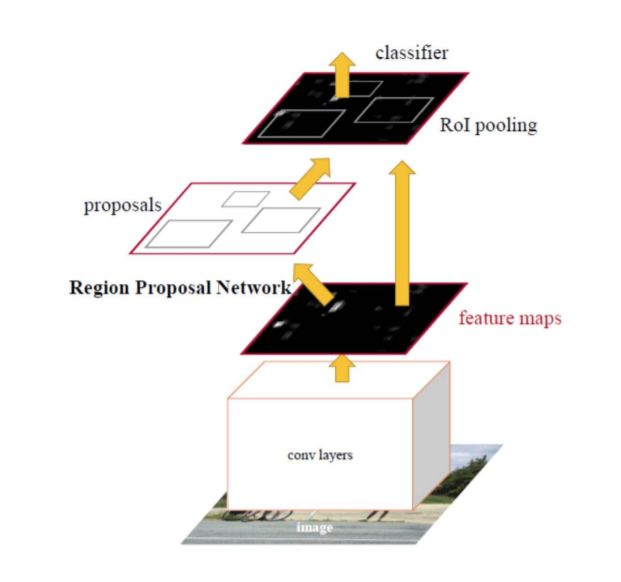
图15: 更快的R-CNN架构。
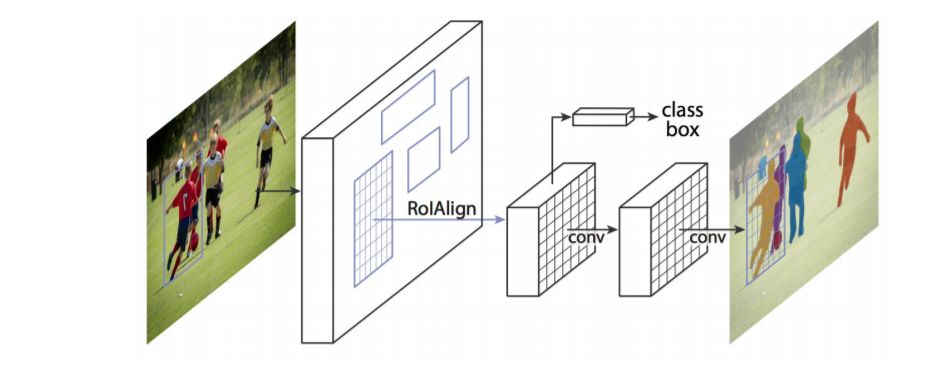
Fig. 15: Mask R-CNN architecture for instance segmentation. From [65]在该模型的一个扩展中,He等人[65]提出了一个用于对象实例分割的掩码R-CNN,它在许多COCO挑战中击败了之前所有的基准。该模型有效地检测图像中的目标,同时为每个实例生成高质量的分割掩码。很多基于R-CNN的实例分割模型已经被开发出来,例如为mask proposal开发的模型,包括R-FCN [71], DeepMask [72], SharpMask [73], PolarMask[74],以及边界感知的实例分割[75]。值得注意的是,还有一个很有前途的研究方向是尝试通过学习自底向上分割的分组线索来解决实例分割问题,如Deep Watershed Transform[76]和Semantic instance segmentation via Deep Metric learning[77]。
3.6 扩张卷积模型和DEEPLAB家族
膨胀卷积(atrous convolution)为卷积层引入了另一个参数,即膨胀率。
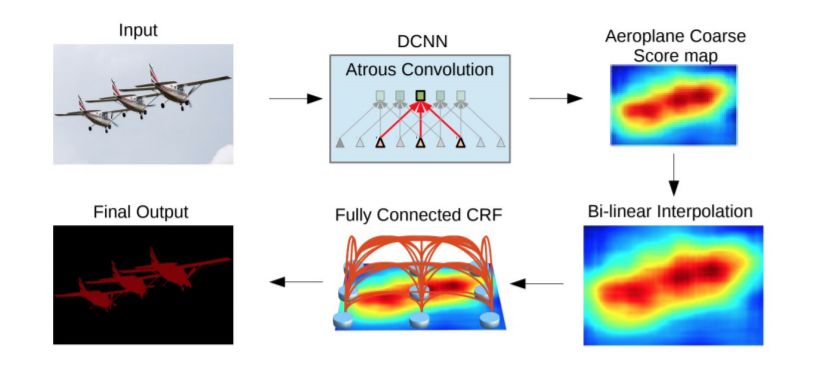
图16: DeepLab模型。VGG-16或ResNet-101等CNN模型采用全卷积方式,使用扩展卷积。双线性插值阶段将特征映射扩展到原始图像分辨率。最后,一个完全连接的CRF细化分割结果,以更好地捕捉对象边界。从[78]
3.7 基于递归神经网络的模型
虽然CNNs天生适合计算机视觉问题,但它们并不是唯一的可能性。RNNs在建模像素之间的短期/长期依赖关系时非常有用,可以(潜在地)改进分割图的估计。使用RNNs,像素可以链接在一起,并按顺序进行处理,从而对全局上下文建模,提高语义分割。不过,挑战之一是图像的自然2D结构。
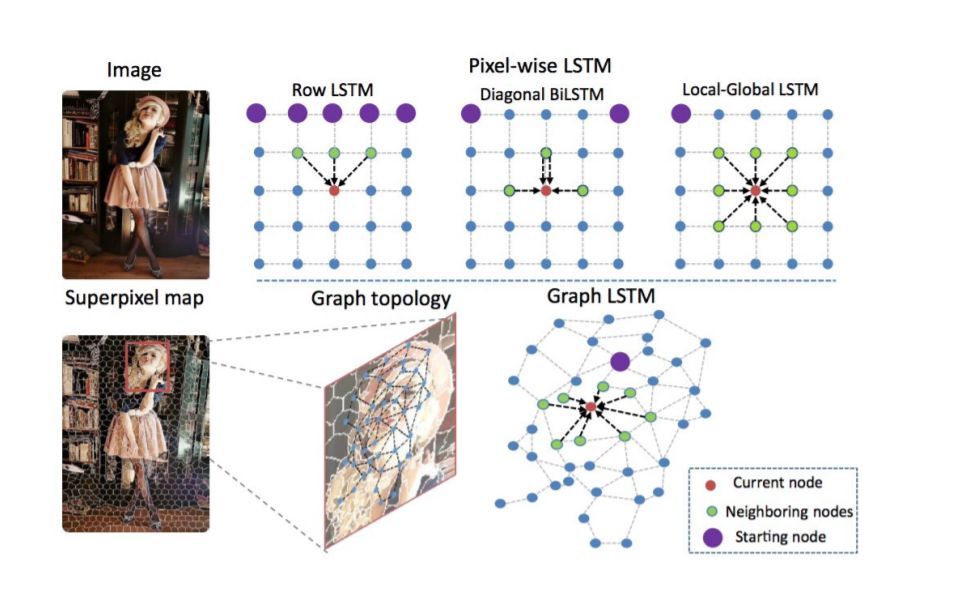
3.8 基于注意力的模型
多年来,计算机视觉中一直在探索注意力机制,因此,发现将这种机制应用于语义分割的出版物也就不足为奇了。Chen等人[90]提出了一种注意机制,该机制学会在每个像素位置对多尺度特征柔化加权。他们采用了一个强大的语义分割模型,并将其与多尺度图像和注意力模型联合训练(图32)。注意机制优于平均池和最大池,使模型能够在不同的位置和尺度上评估特征的重要性。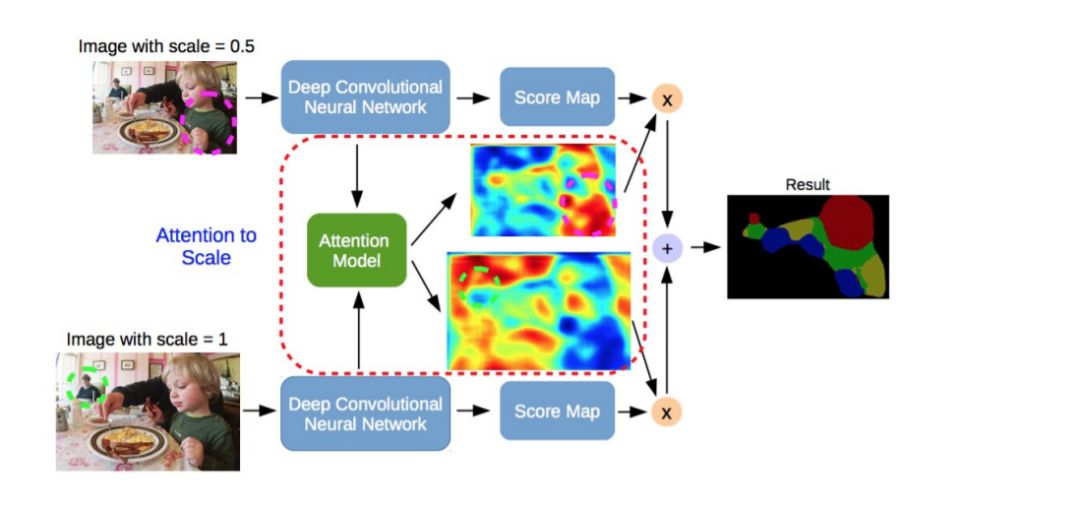
3.9 生成模型和对抗性训练
GANs自引入以来,在计算机视觉中得到了广泛的应用,并被用于图像分割。Luc等[99]提出了一种针对语义分割的对抗训练方法。他们训练了一个卷积语义分割网络(图34),同时还训练了一个对抗性网络,从分割网络生成的地物真值分割图中辨别地物真值分割图。他们表明,对抗性训练方法可以提高斯坦福背景和PASCAL VOC 2012数据集的准确性。
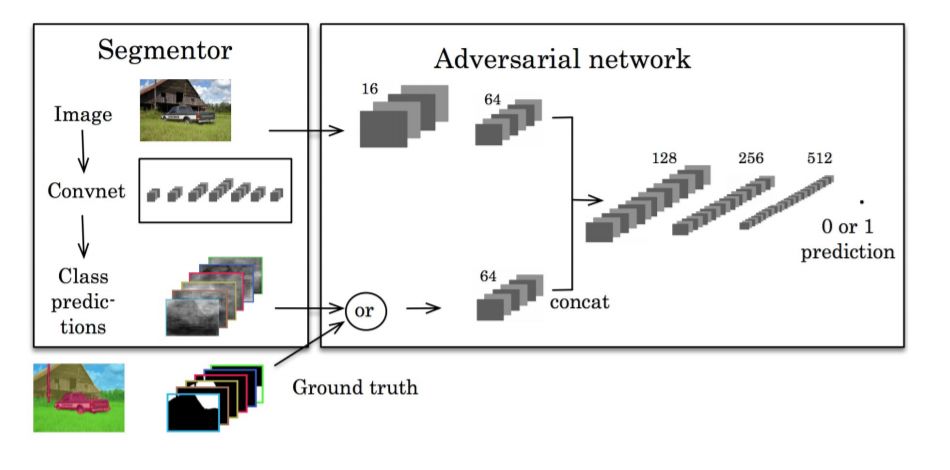
图19: 用于语义分割的GAN。从[99]。
3.10 主动轮廓模型的CNN模型
主动轮廓模型(ACMs)[7]与FCNs之间协同效应的研究是近年来备受关注的课题。一种方法是根据ACM原则制定新的损失函数。例如,Chen等人[106]受到[105]全球能量公式的启发,提出了一种监督损失层,该层在FCN训练时将预测面具的面积和大小信息合并在一起,解决了心脏MRI中心室分割的问题。**
3.11其他模型
除了上述模型外,还有其他几种流行的用于分割的DL架构,如:上下文编码网络(Context Encoding Network, EncNet),它使用一个基本的特征提取器,并将特征映射提供给上下文编码模块[113]。RefineNet[114]是一个多路径优化网络,它明确地利用了下行采样过程中可用的所有信息,利用远程剩余连接实现高分辨率预测。种子网路[115],介绍了一种自动种子生成技术与深度强化学习,学会解决交互式分割问题,Feedforward-Net[116]映射图像super-pixels丰富的特性表示从一个序列中提取的嵌套区域增加程度和利用统计结构标签空间的形象,没有建立明确的结构化预测机制。但额外的模型包括BoxSup[117],图卷积网络[118],宽ResNet [119], Exfuse(增强低级和高级特性融合)[120],双重图像分割(DIS) [121], FoveaNet (Perspective-aware场景解析)[122],梯子DenseNet[123],两国分割网络(BiSeNet)[124],语义预测指导现场解析(SPGNet)[125],封闭的形状cnn[126],自适应背景下网络(AC-Net) [127],动态结构语义传播网络(DSSPN)[128],符号图推理(SGR)[129],级联网络(CascadeNet)[130],尺度自适应卷积(SAC)[131],统一感知解析(UperNet)[132]。泛光分割[133]也是一个越来越受欢迎的有趣的分割问题,这方面已经有了一些有趣的研究,包括泛光特征金字塔网络[134]、用于泛光分割的注意力引导网络[135]和无缝场景分割[136]。
4 图像分割数据集
在本节中,我们提供了一些最广泛使用的图像分割数据集的摘要。我们将这些数据集分为3类: 2d图像、2.5D RGB-D(颜色+深度)图像和3D图像,并提供了关于每个数据集的特征的详细信息。列出的数据集有像素级的标签,可以用来评估模型的性能。
4.1 二维数据集
图像分割的研究主要集中在二维图像上;因此,许多二维图像分割数据集是可用的。以下是一些最流行的:
**PASCAL Visual Object Classes (VOC) ** PASCAL Context **Microsoft Common Objects in Context (MS COCO) ** Cityscapes **ADE20K / MIT Scene Parsing (SceneParse150) ** *SiftFlow ** Stanford background Berkeley Segmentation Dataset (BSD) Youtube-Objects KITTI Semantic Boundaries Dataset (SBD) PASCAL Part SYNTHIA Adobe’s Portrait Segmentation

4.2 2.5 d的数据集
RGB-D图像在研究和工业应用中变得流行起来。以下是一些最流行的RGB-D数据集:
NYU-D V2 SUN-3D SUN RGB-D UW RGB-D Object Dataset ScanNet
4.3 三维数据集
三维图像数据集在机器人、医学图像分析、三维场景分析和建筑应用中很受欢迎。三维图像通常是通过网格或其他体积表示,如点云。在这里,我们提到一些流行的3D数据集。
Stanford 2D-3D ShapeNet Core Sydney Urban Objects Dataset
5 性能评估
在这一节中,我们首先总结了一些用于评估分割模型性能的流行指标,然后我们提供了在流行数据集上有前景的基于dll的分割模型的定量性能。 * Pixel accuracy
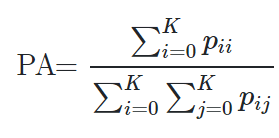
Mean Pixel Accuracy (MPA)
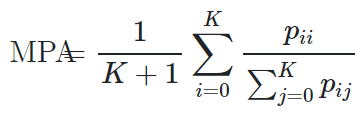
Intersection over Union (IoU)
Mean-IoU Precision / Recall / F1 score Dice coefficient
基于dll的模型的定量性能

表一: PASCAL VOC测试集上分割模型的准确性
6 挑战与机遇
毫无疑问,图像分割已经从深度学习中受益良多,但仍存在一些挑战。接下来,我们将介绍一些有前景的研究方向,我们相信这将有助于进一步推进图像分割算法。
6.1 更具挑战性的数据集
为了实现图像的语义分割和实例分割,建立了多个大规模的图像数据集。然而,仍然需要更有挑战性的数据集,以及不同类型的图像数据集。对于静态图像,具有大量对象和重叠对象的数据集非常有价值。这可以使训练模型更好地处理密集的对象场景,以及在真实场景中常见的对象之间的大量重叠。
随着三维图像分割尤其是医学图像分析的日益普及,对大规模三维图像数据集的需求也越来越大。这些数据集比它们的低维度副本更难创建。现有的用于三维图像分割的数据集通常不够大,有些是合成的,因此更大、更具挑战性的三维图像数据集可能非常有价值。
6.2 可解释的深度模型
虽然基于dll的模型在具有挑战性的基准测试上取得了良好的性能,但是这些模型仍然存在一些问题。例如,深度模型究竟在学习什么?我们应该如何解释这些模型学到的特征?什么是最小的神经结构,可以达到一定的分割精度,在一个给定的数据集?虽然可以使用一些技术来可视化这些模型的学习卷积内核,但是缺乏对这些模型的底层行为/动态的具体研究。更好地理解这些模型的理论方面可以使模型朝着各种细分场景发展。
6.3 弱监督和非监督学习
弱监督学习和无监督学习正成为非常活跃的研究领域。这些技术有望成为图像分割的特别有价值的,因为收集标记样本分割问题在许多应用领域是有问题的,特别是在医学图像分析。转移学习方法是在一组大的标记样本(可能来自公共基准)上训练一个通用的图像分割模型,然后在一些特定目标应用程序的几个样本上微调该模型。自监督学习是另一个很有前途的方向,它在各个领域都很有吸引力。在自我监督学习的帮助下,图像中有许多细节可以用来训练分割模型,而训练样本要少得多。基于增强学习的模型也可能是另一个潜在的未来方向,因为它们在图像分割方面还没有得到足够的重视。例如,MOREL[168]提出了一种用于视频中移动目标分割的深度强化学习方法。
6.4 各种应用的实时模型
在许多应用中,准确性是最重要的因素; 然而,在一些应用中,分割模型也很重要,它可以运行在接近实时,或至少接近普通的相机帧率(至少每秒25帧)。这对于部署在自动驾驶汽车上的计算机视觉系统很有用。目前的大多数模型都远远达不到这一帧率;例如,FCN-8处理低分辨率图像大约需要100毫秒。基于扩展卷积的模型在一定程度上提高了分割模型的速度,但仍有很大的改进空间。
6.5 记忆效能模型
许多现代的分割模型甚至在推理阶段都需要大量的内存。到目前为止,许多努力都是为了提高这些模型的准确性,但是为了使它们适用于特定的设备,例如移动电话,网络必须简化。这可以通过使用更简单的模型来实现,也可以通过使用模型压缩技术来实现,甚至可以训练一个复杂的模型,然后使用知识蒸馏技术将其压缩成一个更小的、内存效率更高的网络来模拟复杂的模型。
6.6 三维点云分割
大量的工作集中在二维图像分割,但很少有涉及到三维点云分割。点云分割在三维建模、自动驾驶汽车、机器人、建筑建模等领域有着广泛的应用。处理三维无序和非结构化数据(如点云)带来了几个挑战。例如,在点云上应用CNNs和其他经典深度学习架构的最佳方式还不清楚。基于图的深度模型可能是点云分割的一个潜在探索领域,从而支持这些数据的附加工业应用。
7 结论
我们研究了基于深度学习模型的图像分割算法,这些算法在各种图像分割任务和基准中取得了令人印象深刻的性能,分为结构类,如: CNN和FCN、RNN、R-CNN、扩张CNN、基于注意力的模型、生成和对抗模型等。我们总结了这些模型在一些流行的基准上的定量性能,如PASCAL VOC、MS COCO、cityscape和ADE20k数据集。最后,我们讨论了基于深度学习的图像分割在未来几年面临的一些开放的挑战和有前景的研究方向。
参考文献:
[1] R. Szeliski, Computer vision: algorithms and applications. Springer Science & Business Media, 2010. [2] D. Forsyth and J. Ponce, Computer vision: a modern approach. Prentice Hall Professional Technical Reference, 2002. [3] N. Otsu, “A threshold selection method from gray-level histograms,” IEEE transactions on systems, man, and cybernetics, vol. 9, no. 1, pp. 62–66, 1979. [4] R. Nock and F. Nielsen, “Statistical region merging,” IEEE Transactions on pattern analysis and machine intelligence, vol. 26, no. 11, pp. 1452–1458, 2004. [5] N. Dhanachandra, K. Manglem, and Y. J. Chanu, “Image segmentation using k-means clustering algorithm and subtractive clustering algorithm,” Procedia Computer Science, vol. 54, pp. 764–771, 2015. [6] L. Najman and M. Schmitt, “Watershed of a continuous function,” Signal Processing, vol. 38, no. 1, pp. 99–112, 1994.



