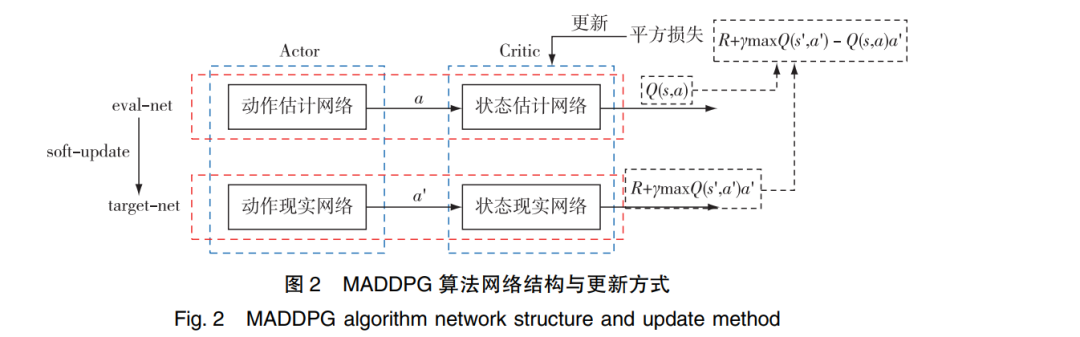
近年来,基于深度强化学习的机器学习技术突破性进展为智能博弈对抗提供了新的技术发展方向。针对智能对抗中异构多智能体强化学习算法训练收敛速度慢,训练效果差异大等问题,提出了一种先验知识驱动的多智能体强化学习博弈对抗算法PK-MADDPG,构建了双重Critic框架下的MADDPG模型。该模型使用了经验优先回放技术来优化先验知识提取,在博弈对抗训练中取得显著的效果。论文成果应用于MaCA异构多智能体博弈对抗全国竞赛,将PK-MADDPG算法与经典规则算法的博弈对抗结果进行比较,验证了所提算法的有效性。
目前,基于深度强化学习的机器学习方法受到越 来越多的关注,更多的游戏通过训练智能体的方式与 人类进行人机对抗,典型代表有在围棋领域获得成功 的 AlphaGo 以及在游戏《星际争霸》人机对抗赛中获得 成功的 AlphaStar 等,越来越多的研究将深度强化学习 方法融入 RTS 游戏领域[1⁃3] 。 如 Ye D 尝试利用改进的 PPO 算法训练王者荣耀游戏中的英雄 AI,取得了较好 的训练效果[4] 。 Silver D 设计了一种基于强化学习算 法的训练框架,不需要游戏规则以外的任何人类知识, 可以让 AlphaGo 自己训练,同样达到了很高的智能 性[5] 。 Barriga N 利用深度强化学习技术和监督策略学 习改善 RTS 游戏的 AI 性能,取得了击败游戏内置 AI 的成果[6] 。 大数据和人工智能技术加速运用于战略问 题研究,战略博弈推演的智能化特征凸显[7⁃8] 。 研究表 明,人工智能在智能博弈对抗与推演方面受到广泛关 注,并在近年成为研究热点[9⁃11] 。 但是,对宽泛条件下 的收敛问题以及收敛速度问题,仍然缺乏有效的解决 方法,特别是在对抗方面,采用强化学习算法使其具有 高水平的智能性仍是当前研究的难点。 本文分析了当前主流且成熟的多智能体强化学习 算法,将先验知识与强化学习算法相结合,解决了强化 学习算法在多智能体对抗训练初期效果一般且不能快 速收敛的问题,提升了多智能体博弈对抗中的算子智 能性,同时,在实验平台中进行仿真实验,结果表明, PK⁃MADDPG 在 MaCA 多智能体博弈平台训练效果与 收敛速度方面均有提升。