导读 领域模型脱胎于通用大模型,两者有相似之处,但通用大模型在训练时使用的是通识数据集,缺少领域知识,导致企业在应用过程中会发现一些问题。比如,如果我们要做一个滴普科技的智能问答机器人,但通用大模型并没有学习到滴普科技的各种产品信息,缺少先验知识。目前这个问题有两种解决途径,一种是 RAG,通过外挂知识库来弥补通用大模型缺乏领域知识或知识更新较慢的问题;另一种是构建领域大模型,即在通用大模型的基础上使用领域数据集进行微调,使其能够识别或记住领域知识,以更好地为企业服务。本文将分享滴普科技在服务客户过程中积累下来的领域大模型构建指南。
文章将围绕下面六点展开:
- 领域大模型和通用大模型的区别
- 基于企业数据的领域数据集构建
- 模型训练方法的选择
- 验证集的构建及模型评估方法
- 国产硬件评测
- 问答环节 分享嘉宾|陈峰 北京滴普科技有限公司 Senior Research Fellow 编辑整理|于苗苗 内容校对|李瑶 出品社区|DataFun
01
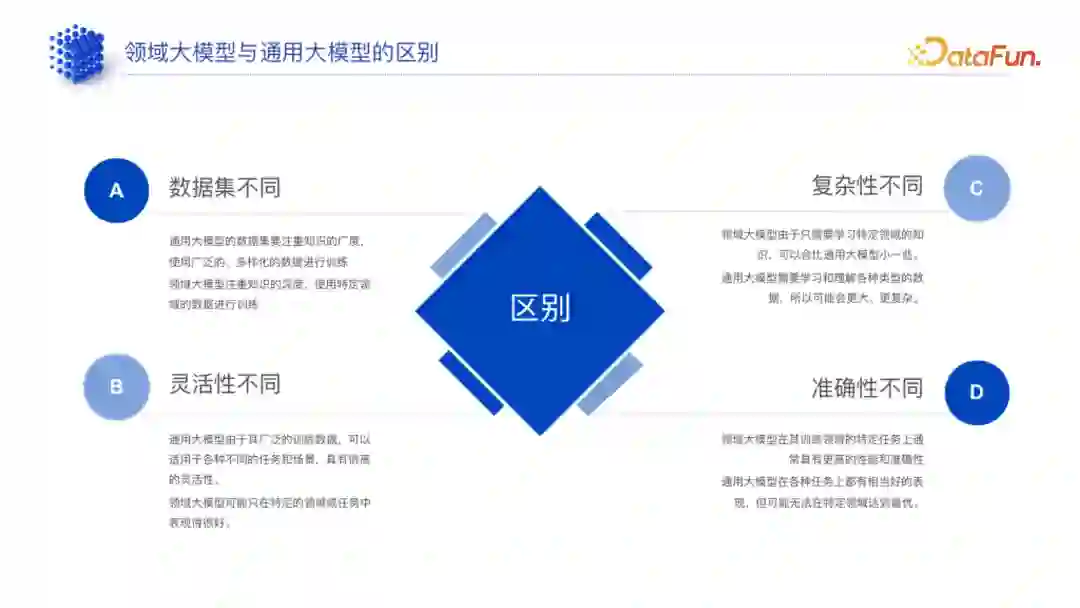
领域大模型与通用大模型的区别
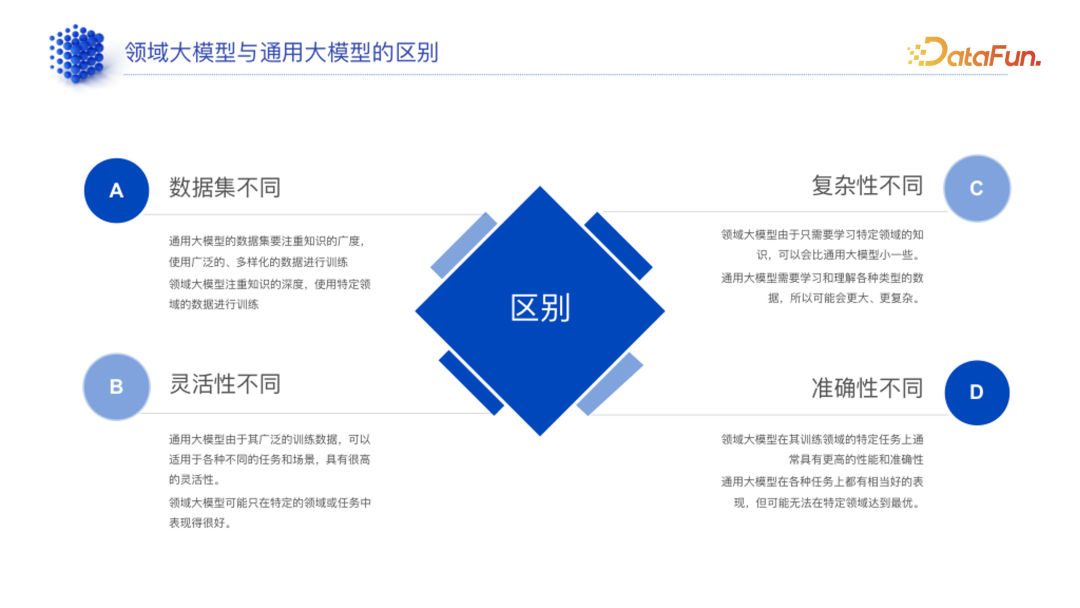
1. 数据集不同
通用大模型已有许多优秀的开源数据集,注重广度、覆盖各行各业,但在特定行业的深度不够,或只在某几个行业具备一定深度。比如 Code Llama(代码生成大模型)在 Python、Java 等代码层面有较多的数据集的积累,但其他冷门语言的数据集较少。 * 领域大模型可以使用通用数据,但不能完全使用,因此受限于行业。目前只有少数行业存在行业数据集,比如法律行业有裁判文书等开源数据集,但较多行业比如零售没有数据集。
2. 灵活性和准确性不同
灵活性不同:通用大模型具有较高的灵活性和泛化能力,可以通过 prompt 使其适用于各种不同的任务和场景。
准确性不同:在具体行业中,通用大模型的准确性不如领域大模型。
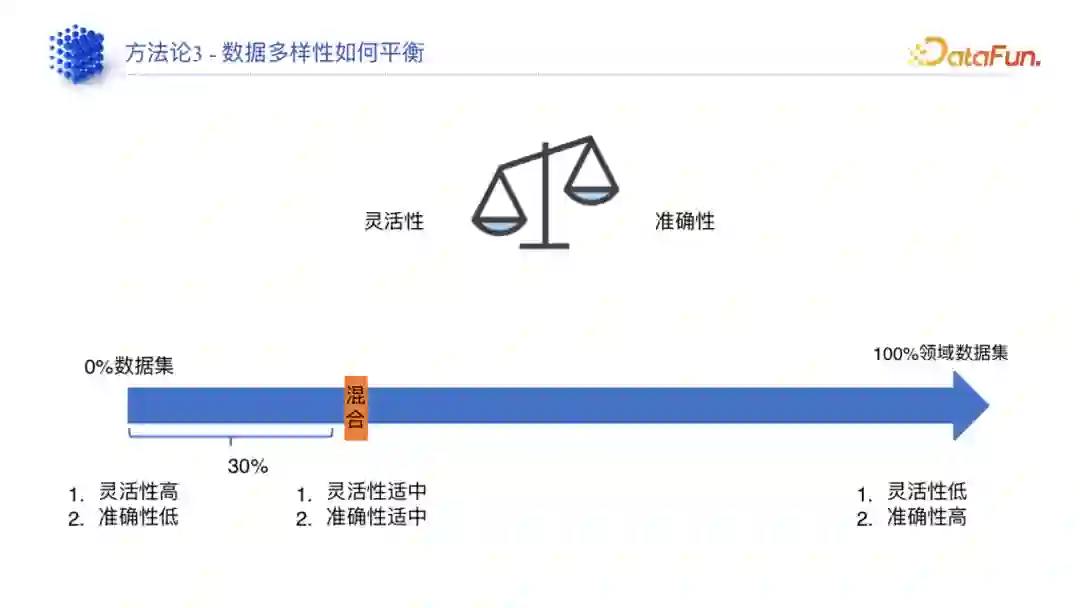
灵活性和准确性是天平的两端,如果追求高准确性,灵活性就会受限,相反若追求灵活性则准确性会受限。因此在模型训练过程中需要平衡灵活性和准确性。
3. 复杂性不同
通用大模型复杂度较高。
领域大模型更多用于企业内部,不需要追求像通用大模型那么强的泛化能力,且可以使用小参数的模型来满足客户需求,复杂度相对较低。
02
基于企业数据的领域数据集构建****
数据集准备是领域模型中最重要的环节,最终会影响领域模型的效果。
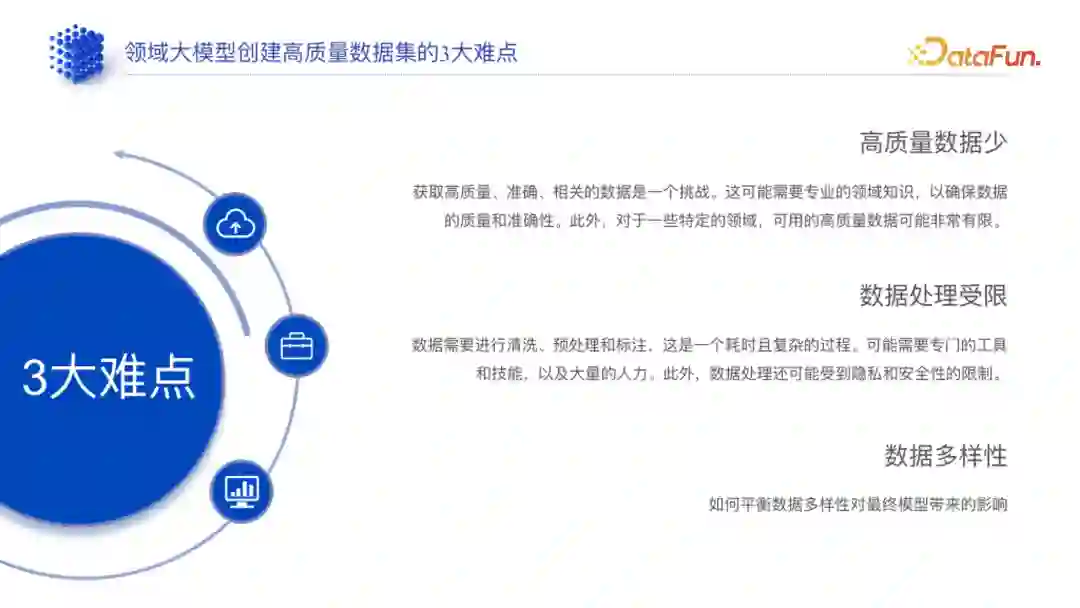
1. 高质量数据集创建难点
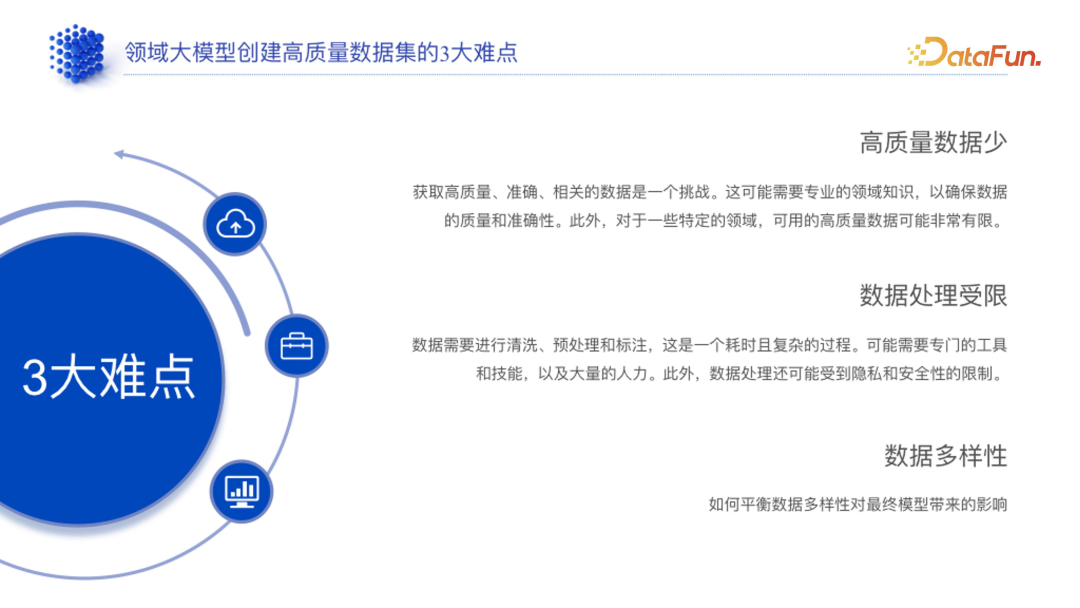
- 高质量数据集少:较多客户只有一个文档库,且这些文档大多是完全未经处理的。
- 数据处理受限:需要先对客户的数据进行处理,耗时、成本高。通用大模型处理数据时,优先会使用 ChatGPT 先做一些预处理,但为了保障企业数据隐私,此类数据处理方法无法使用,数据处理工具受限。
- 数据多样性:数据多样性的平衡会影响模型的灵活性和准确性,如果数据多样性低,模型的灵活性受限;如果多样性高,模型的准确性就可能会降低。
2. 高质量数据集创建方法论
(1)SFT****

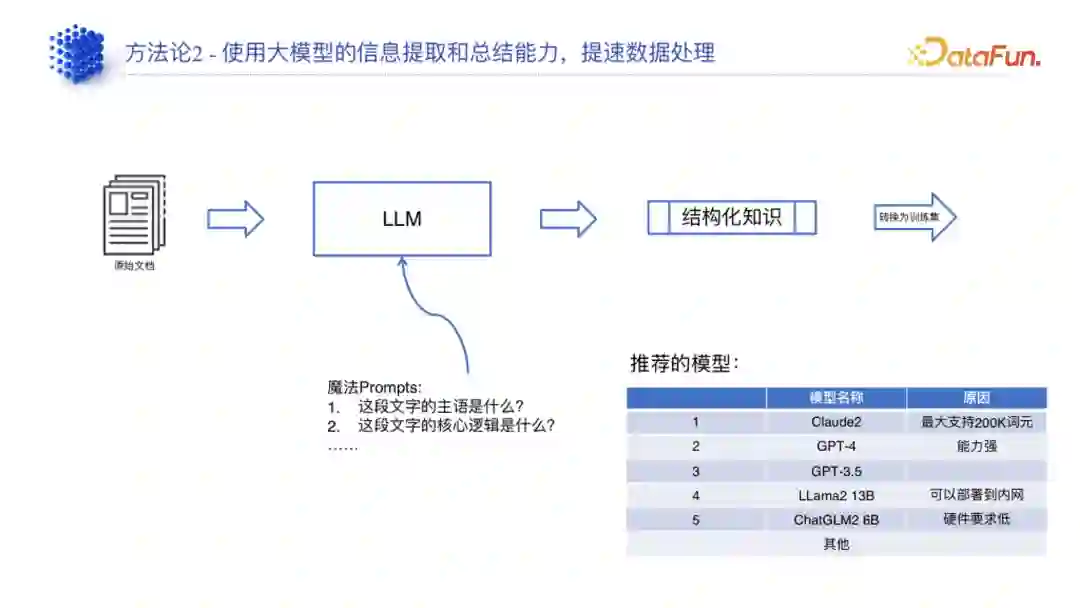
(2)使用大模型自身能力****
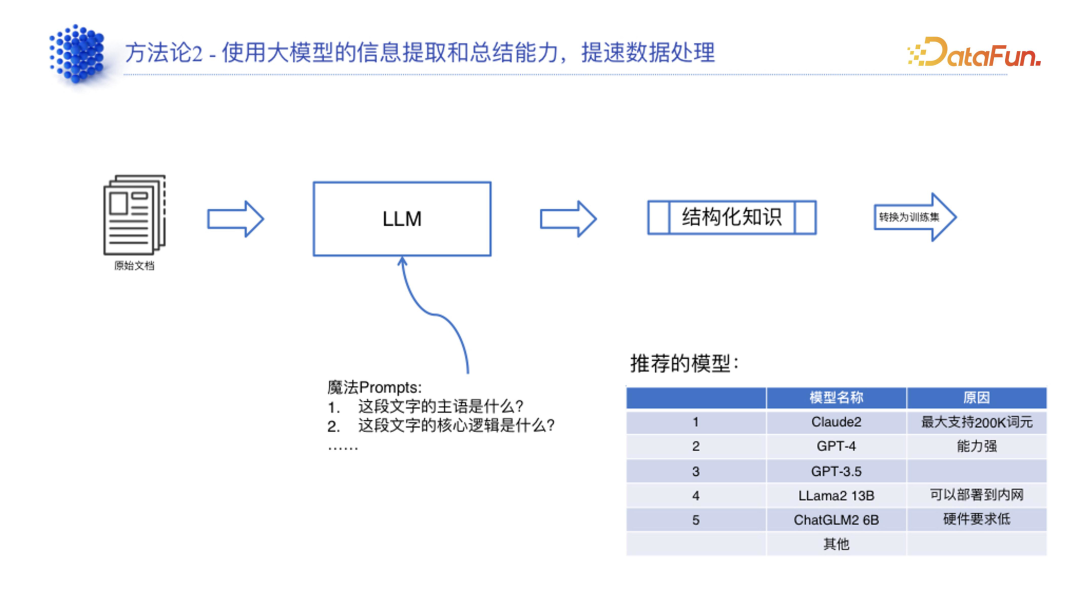
(3)数据多样性的平衡方法
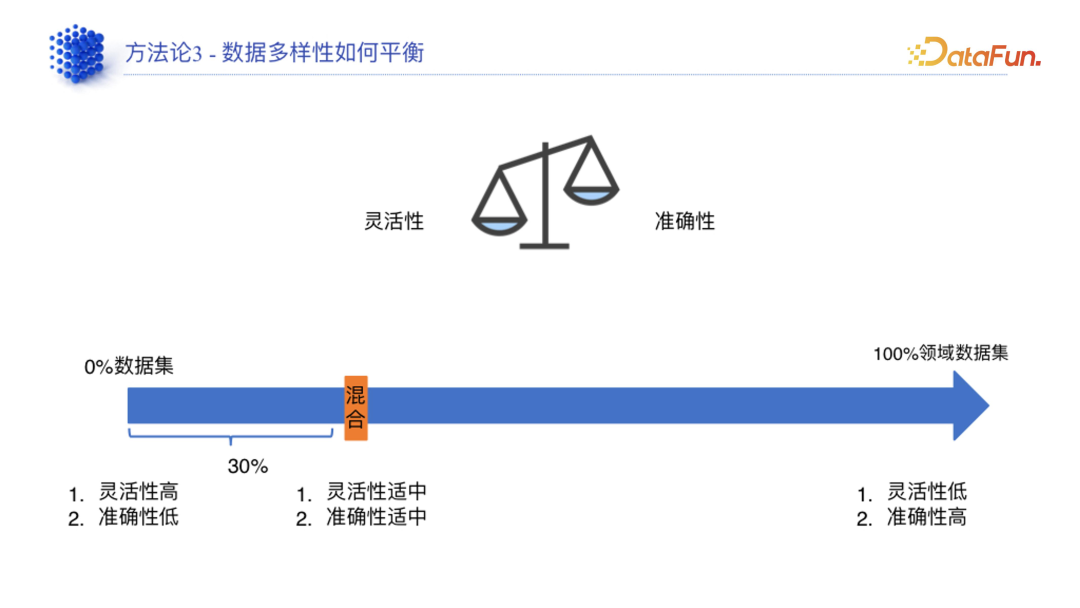
- 比如某个客户需求是做一个意图识别大模型,它不需要面向普通用户,而是面向程序,这种情况下是不需要考虑灵活性的,那么就可以把领域数据的比例直接拉到 100%。
- 又比如客户需要大模型对公司汽车产品的操作指南、操作手册去进行回答,用户遇到问题就可以询问大模型。对于这种客户,是需要应对客户需求、直接面向终端用户的,那么就需要把数据拉到 30%。
(4)总结
****
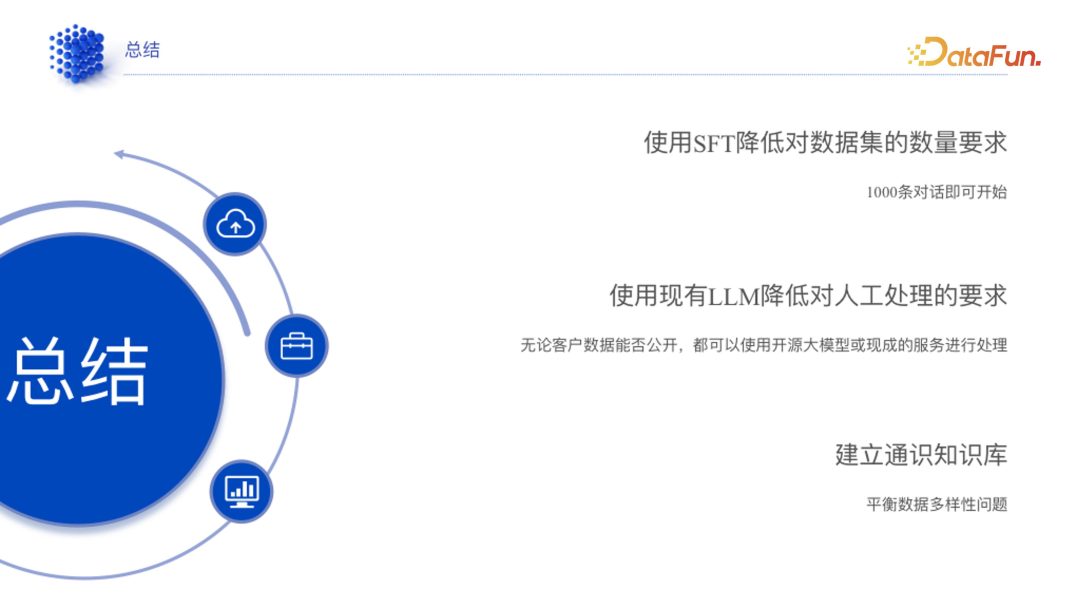
通过 SFT 降低对高质量数据集的要求,1000 高质量对话数据就可以满足领域大模型的训练。
充分利用现有大模型的手段来降低数据处理或者数据预处理(即知识提取)对人工处理的要求。
建立通用知识库,灵活地去调整比例,实现通用和领域数据的自动融合,最后得出来一个能够支持后续训练的数据集。
03
模型训练方法的选择
1. 不同训练方法的比较
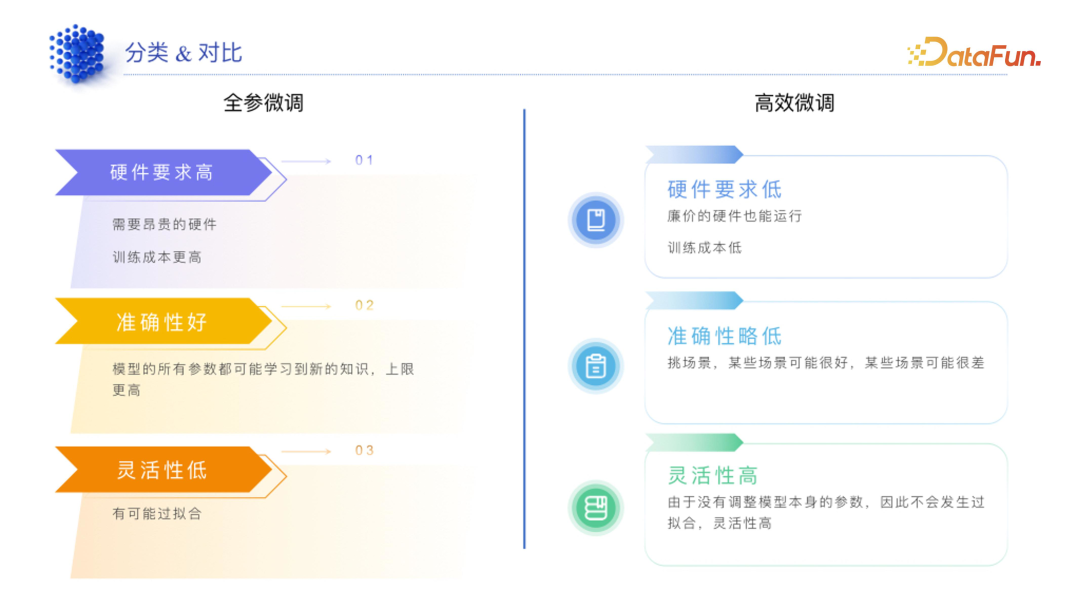
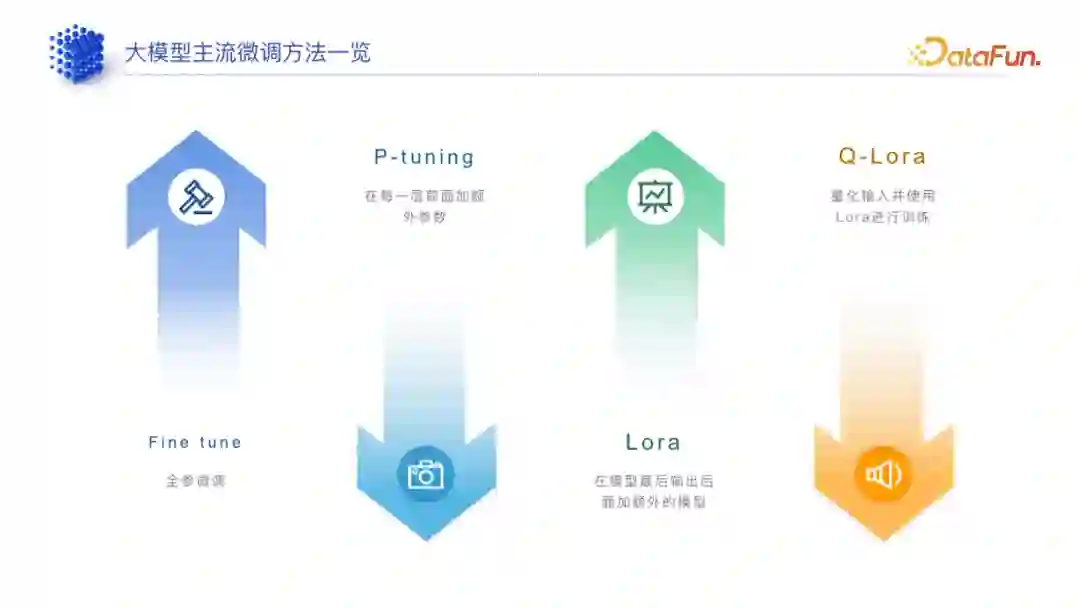
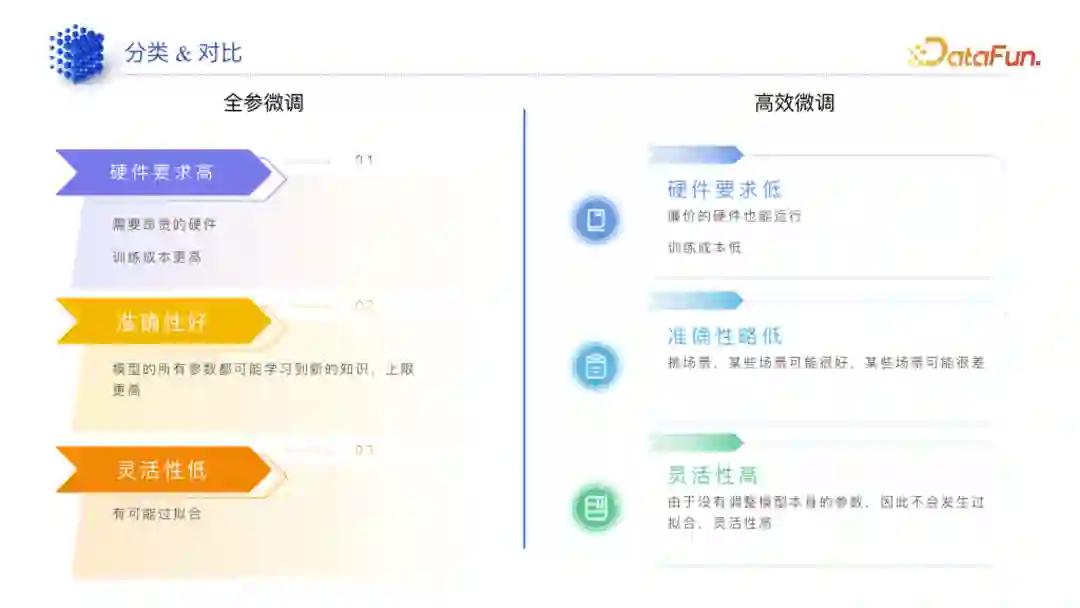
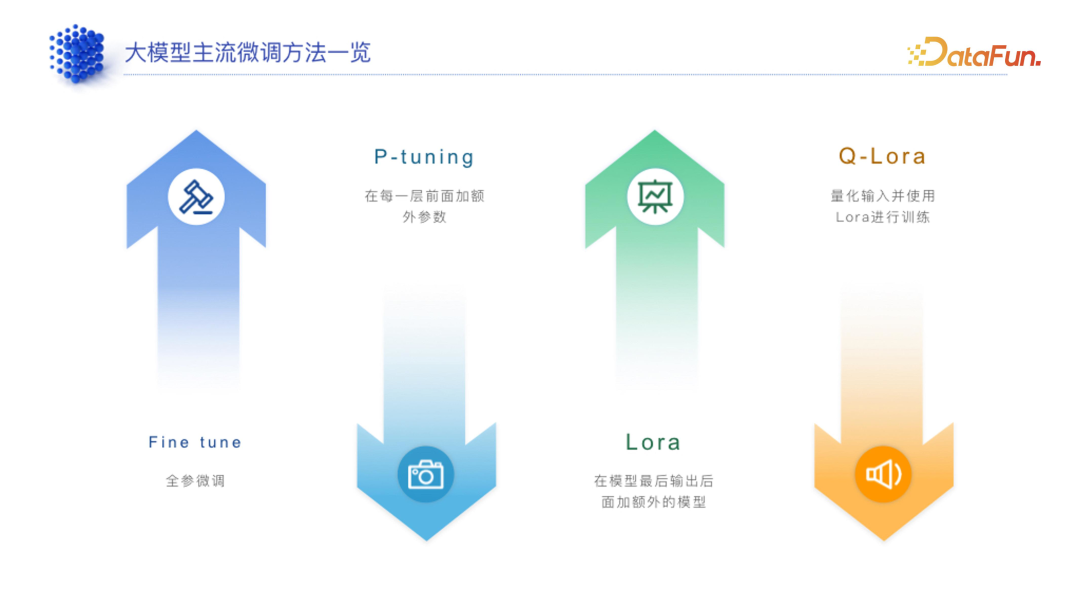
(1)全参微调
硬件要求高,比如训练 13B 模型至少需要 A800 硬件,普通的 A10、A20、A30、4090 等是无法胜任的。
成本高,不只是需要一块 A800,需要建立多机多卡集群,可能得有三十几台或二十几台且每台八块的 A800 才能去做一个比较大的全参微调。
准确性好,它动了所有的参数,因此准确性会比较好。
灵活性低,全参微调最重要的点是怎么解决过拟合的问题,如果过拟合,可能会让模型忘记之前的知识,因此灵活性降低。
(2)高效微调
硬件要求低,廉价的硬件也能跑。根据实测情况,很多LORA 等高效微调甚至可以跑在苹果笔记本上,一般 M1 Pro 芯片就能比较好的运行,4090 显卡要跑 Lora 也是很轻松的,甚至 3090 都可能。
准确低,Lora 等高效微调其实很挑场景,有些场景下效果会比较好,有些场景效果就上不去。
灵活性高,Lora 这种高效微调方式的一般逻辑是原有的大模型参数不动,加一些参数,训练其实也是训练最后增加的那部分参数,这也就意味着模型本身的能力并不会降低。
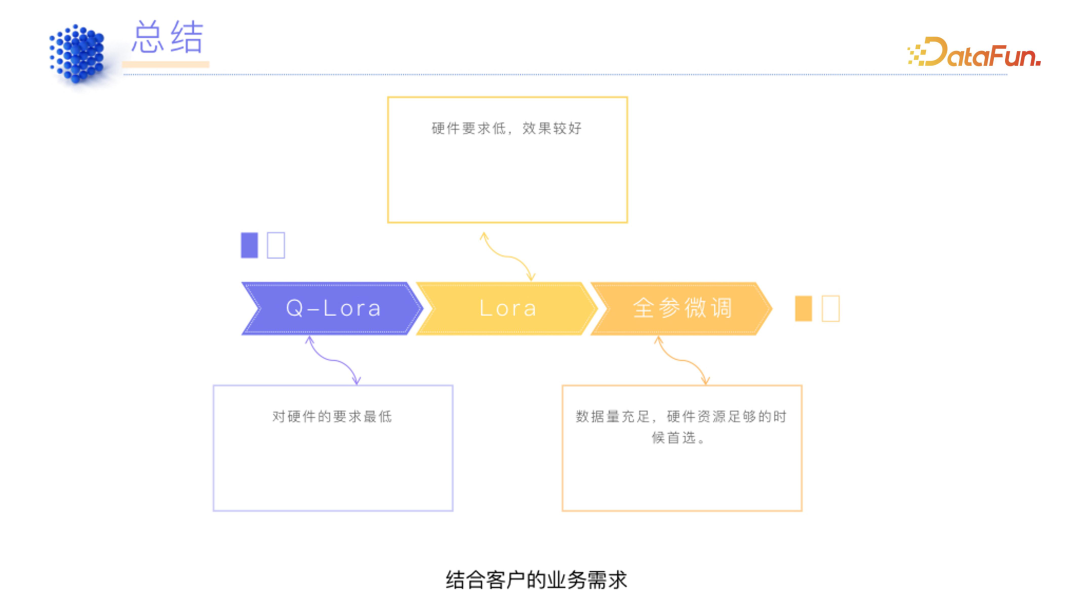
2. 选择方法

(1)从数据集特征入手

- 只是做一些输出格式的调整,不需要让大模型去记住新的知识时,选择高效微调方法。训练模型只是为了输出更符合客户需求的话术,或更符合客户要求的数据集,而并没有改变数据集本身的权重、记忆、知识结构时,Lora 的表现比较好。
- 需要让模型记住新的知识时,建议通过全量参数去微调。
(2)从硬件层面选择

(3)从效果层面选择

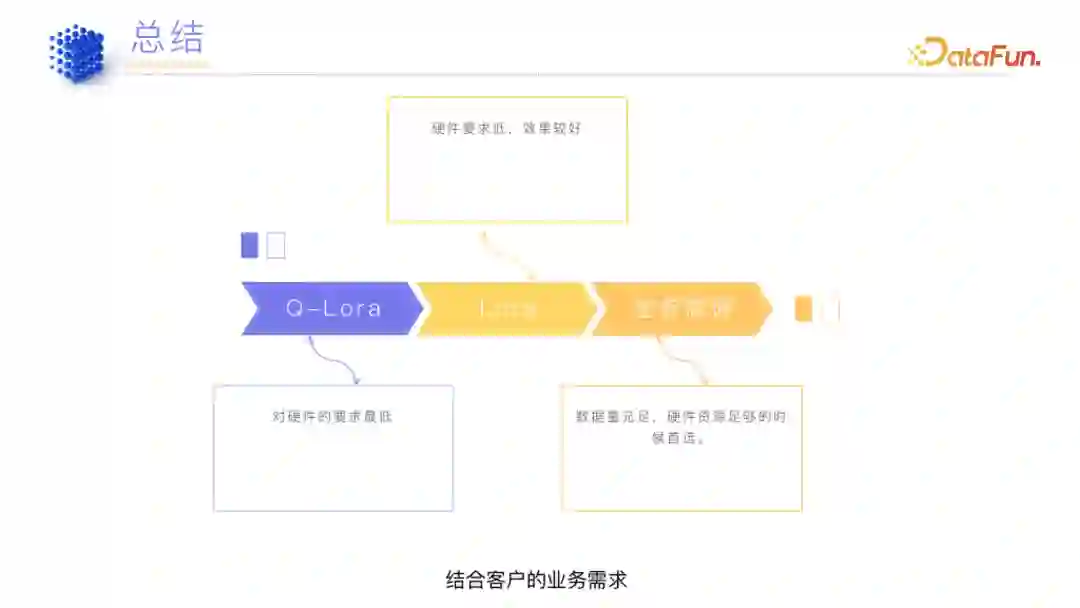
(4)总结****
04
验证集的构建及模型评估方法
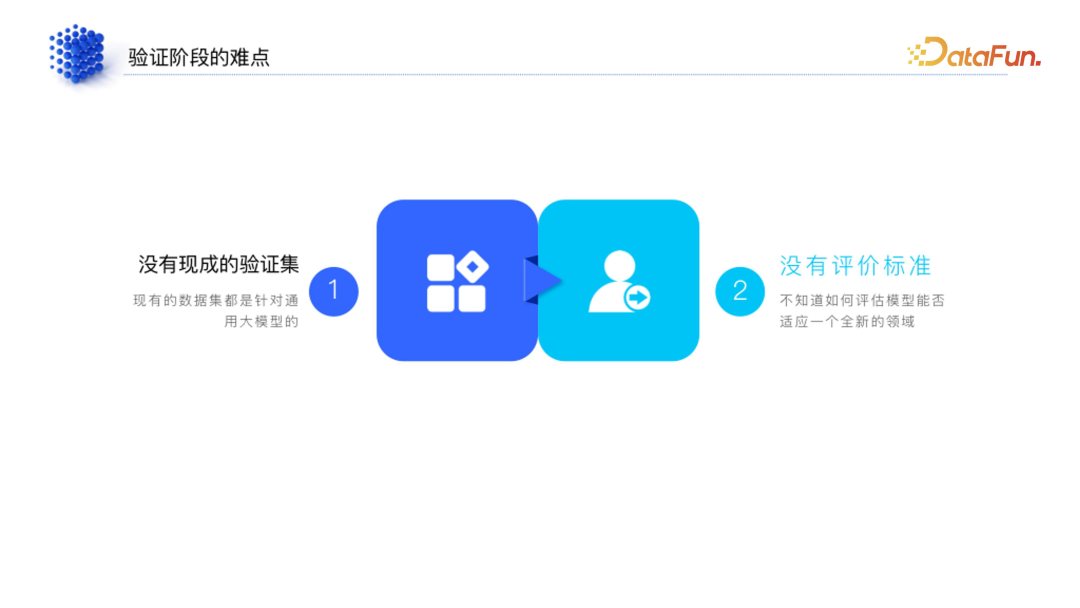
当我们辛辛苦苦用昂贵的硬件通过 72 小时甚至几百小时的训练之后,得到一个模型,迫切需要验证其是否可用,有没有记住数据集。首先模型一定是选择 loss 比较低、准确率比较高的,但是选择准确性最好的模型就行了吗?如果它发生了比较长的记忆遗忘的情况怎么办?因此,我们需要去验证一下模型是否合理。
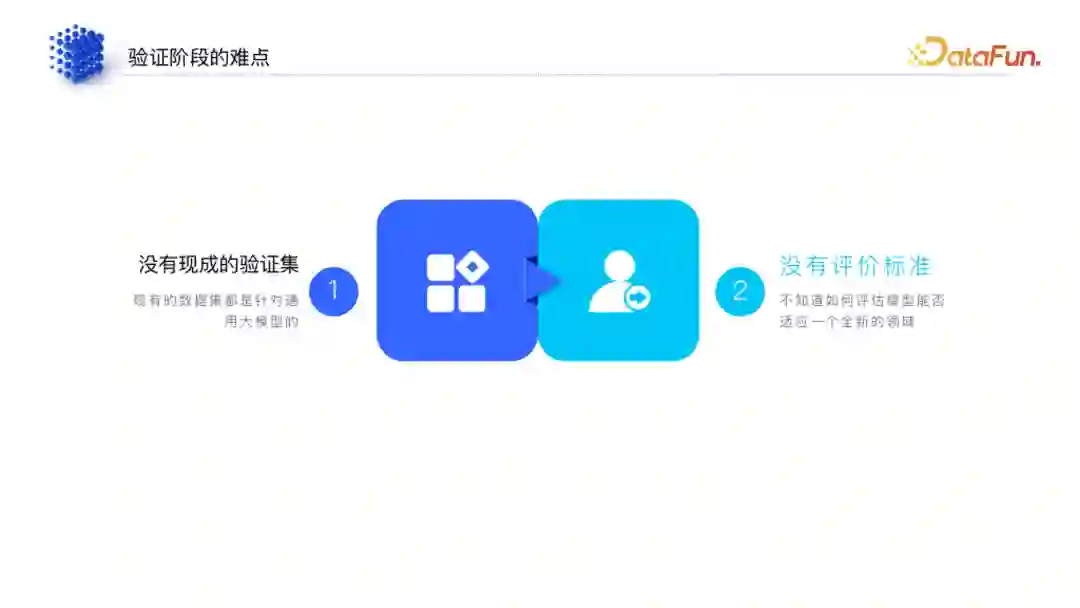
1. 领域大模型验证的难点
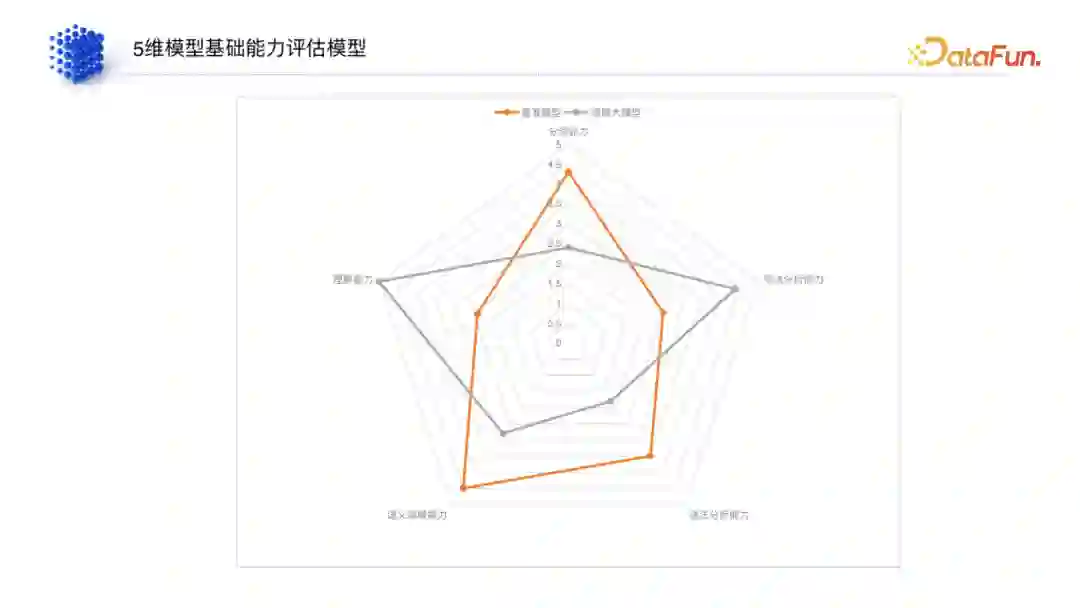
2. 五维模型能力评估
对于领域大模型如何构建验证集,到目前为止仍处在探索过程中,这里要讲的方法不一定是最优的,只是我们通过一些选择、实验发现的效果比较好的一种方法,并且评估方法也会不停迭代。 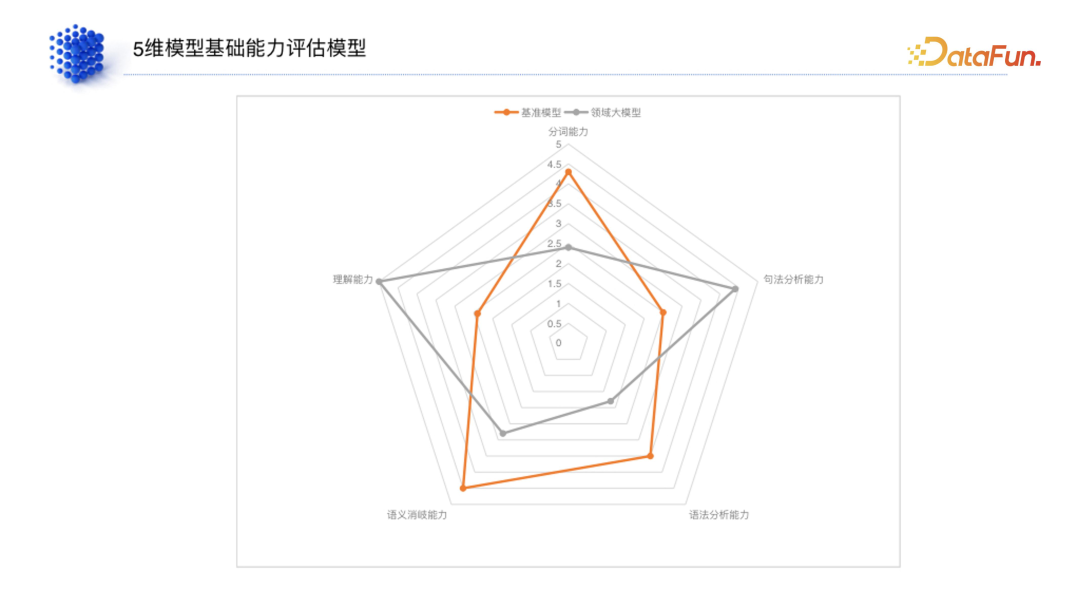
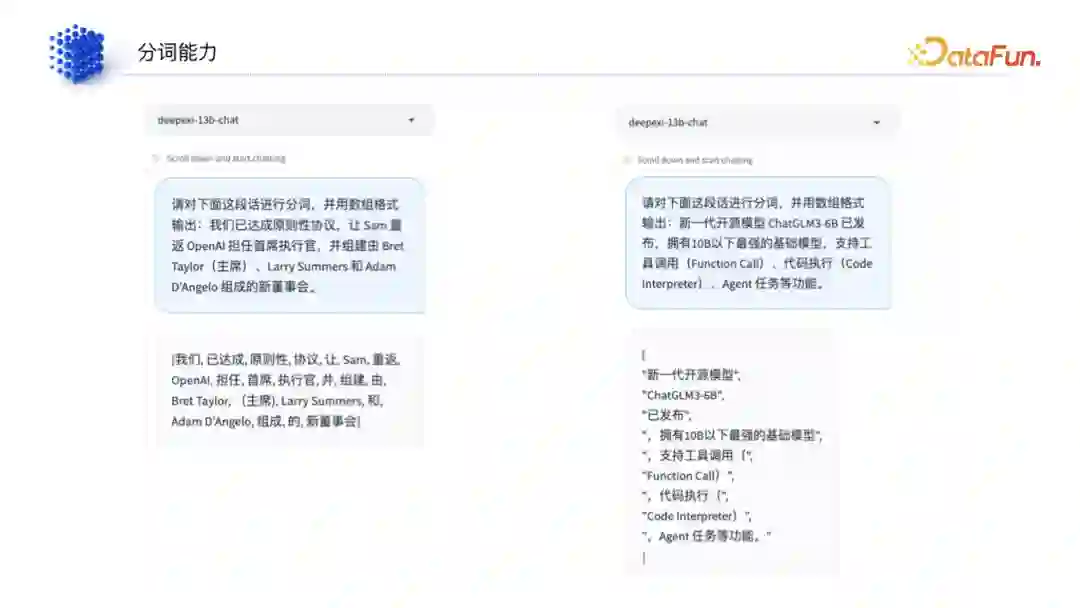
(1)分词能力
中文和英文不同,英文是一个单词接近于一个 token,但中文是通过单个字喂进去的。在这种情况下,模型本身的分词能力就非常重要。在没有大模型之前,分词本身就是一个非常难的事情,是靠人类写一些方法去实现的,其效果局限于分词模型的大小。但是在大模型时代,可以把单个字喂到大模型里,让大模型自己产生分词能力,分词能力已经从之前靠分词模型的能力变成了大模型本身的能力。所以我们首先就要去判断模型的分词能力是否及格。
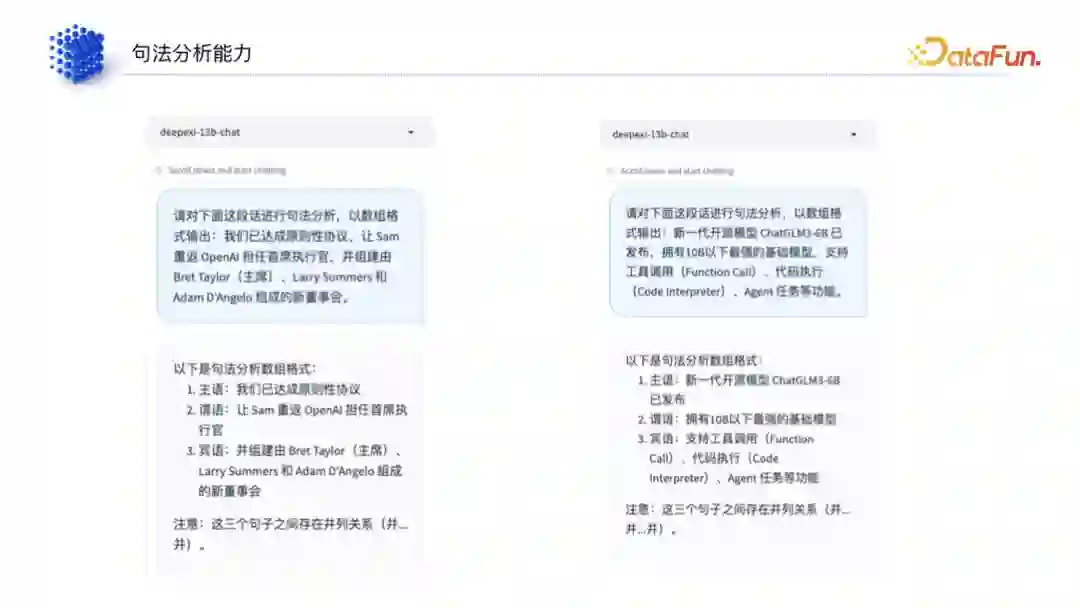
(2)句法分析、语法分析、语义消歧、理解能力
分完词后,要去判断它的句法分析能力,然后判断语法分析能力,以及语义消歧能力,最后判断其理解能力。从这个过程可以看出来,对于一个基本的文本,通过它的语料和元素,从最开始的一个字词变成一句话、再变成语法、再到语义消歧,整个阅读理解是从低到高的顺序。
3. 举例
(1)分词能力

(2)句法分析能力****

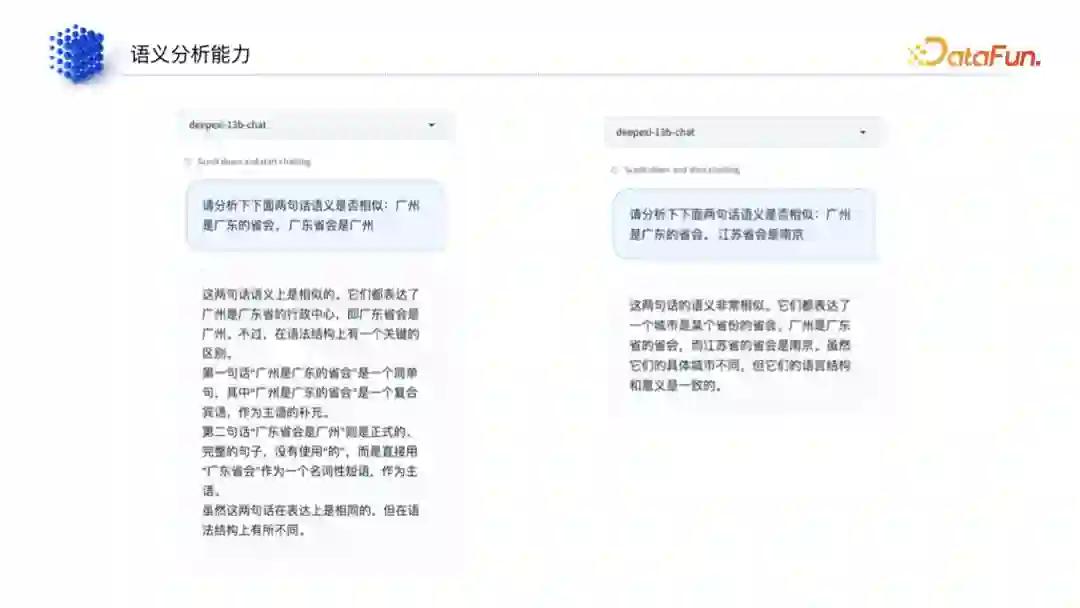
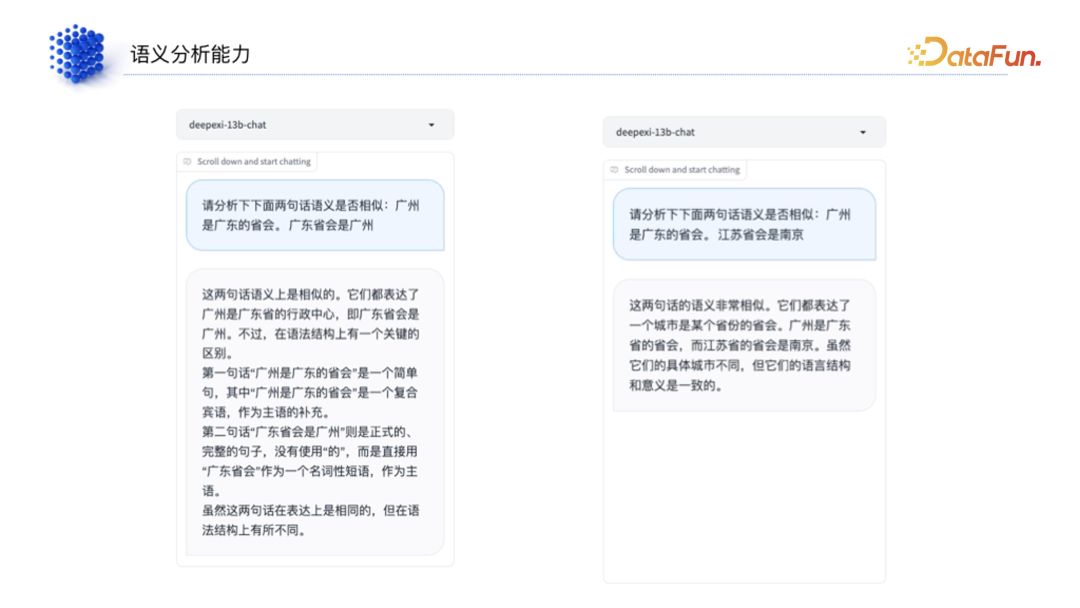
(3)语义分析能力
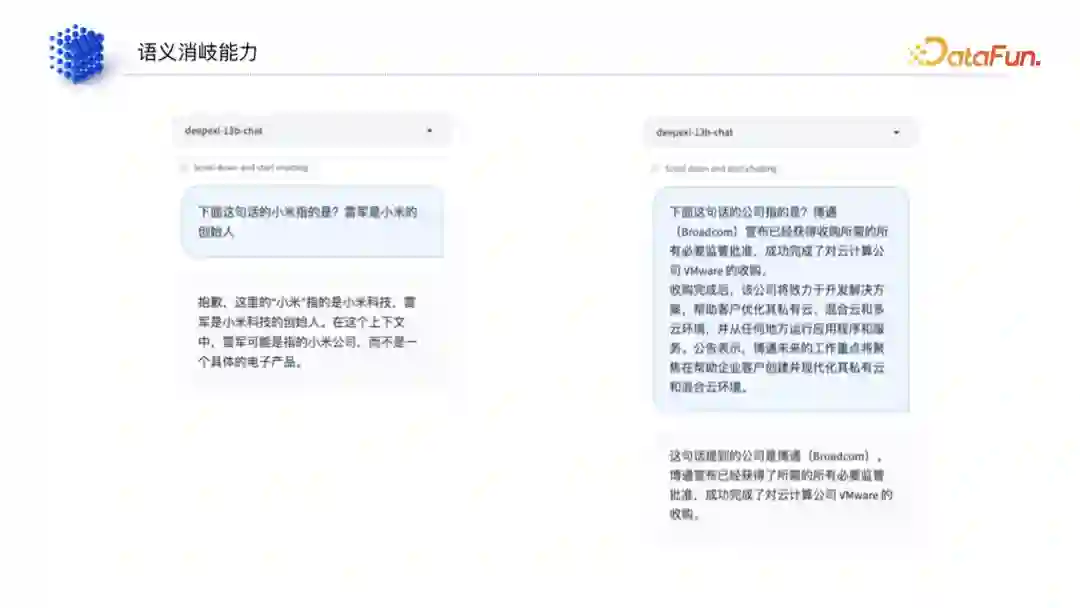
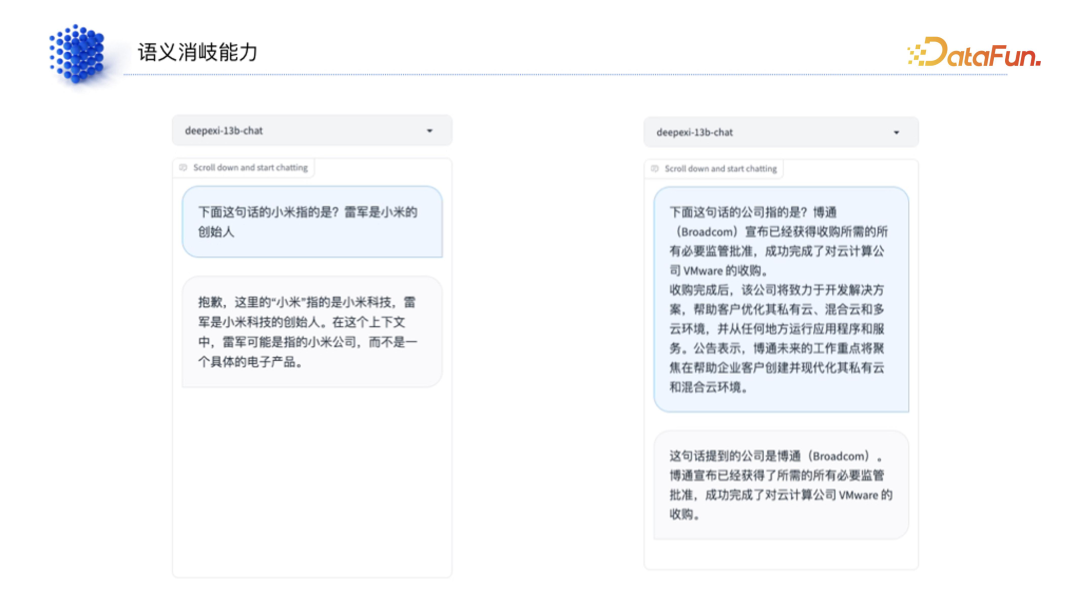
(4)语义消歧能力
(5)理解能力

4. 验证集准备方法论

****
事先准备通识验证数据集。 * 针对五个维度,客户准备具体领域的数据集。 * 准备一个基准模型,可以用 Llama2、chatGLM、百川之类的开源大模型做基准。如下图所示,将基准模型和我们模型的能力放到同一个雷达图上,得出两者之间面积的重合点以及两者的差距,这是一种横向对比的方法。
05
国产硬件评测

06
问答环节
Q1**:****模型验证还是要靠人工来看?能不能自动化?分数是怎么得出的?****A1:很多验证是可以通过脚本去干的。以分词为例,对比它的输出结果和标准答案之间的区别。prompt 写得好一点,告诉它应该输出什么样的格式,调整成代码能够接受的输出,就可以自动化去做判断。Q2:****拿比较少的数据去微调一个领域的模型,它在回答那种需要准确答案的场景下的效果是怎么样的?比如在法律领域,用一两千条去调完之后,问它刑罚的第二条第三款,它能够比较准确地回答吗?****A2:如果你问的问题已经在这 1000 条内容之间了,它只需要做一些简单的推理,这个是没问题的。如果说只训练了刑法的内容,但问他民法的内容,那肯定是回答不了的,会出现幻觉问题。所以如果需要的领域比较大,那肯定是要对应地增加这 1000 条数据集的。Q3:****比如用一两千条的数据来微调它,那么即使问的问题可能是在你的训练数据集里的,但问法稍微一变,它还能够准确的回答吗?比如说法律里的权利跟权力。这两个力是不一样的,那么它在回答的时候,可能你的数据集体原始答案是利的利,它会变成力量的力,它意思就完全变了,这种情况的话会不会出现以及怎么解决?****A3:会出现,其实这个问题就是全量微调里面非常头疼的问题,训着训着可能把它本身的一些能力给弱化掉了,这在全量微调的时候其实是非常容易出现的一个问题,并且还不是少数。这种情况下我觉得第一个点就是验证模型变得非常关键。比如说就像你刚刚问的,权利跟权力之间有什么区别。我们在准备数据集的时候,就把这一块的数据做成训练集训练进去。完全指望模型去做知识与知识之间的连接效果没有那么好。其次就是如果真的发现这种情况,那只能去不停地训练,只能通过准备数据集加上验证的方式,尽可能得去降低这一风险。但要完全避开这种问题,目前还是做不到的,可能得等整个模型界有一些新的技术出现才会解决,并不是通过工程化的方式能解决的。Q4:****您刚刚讲了整个做领域模型的 pipeline,我有一个小小的问题。因为您刚刚都是单轮的,从准备数据一直到训练、验证,假设验证效果不好,我们肯定要再继续来这个过程,那在这个过程中如果我们发现,比如准确性不高,我们可能想要把数据量变大、数据质量提高或者换一种训练方法等等。这个时候一般是怎样去考虑的?******A4:我们更多的也是通过验证的结果去看的。举个例子,如果说发现它的分词能力比较弱,那么已经不仅仅是训练集准备的问题了,可能是整个模型过拟合已经非常严重了。这种情况下基本上这个模型是需要重新训练的。如果只是理解能力或者语义消歧能力出现问题,可能只是数据集准备得不够到位。这种情况下就需要去补充数据集。我们发现大部分情况基本上是通过补充数据集或者调整数据集就能够解决的。以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION
陈峰
北京滴普科技有限公司

Senior Research Fellow
滴普科技高级研究员,《ClickHouse 性能之巅》作者。数据智能领域资深架构师,曾主导 OPPO 智能缺陷识别、威视智能瞳孔检测、百丽丽影等多个数据智能项目技术架构的设计工作,有丰富的大模型落地经验。目前着眼于大模型在不同领域上的工程化落地。