

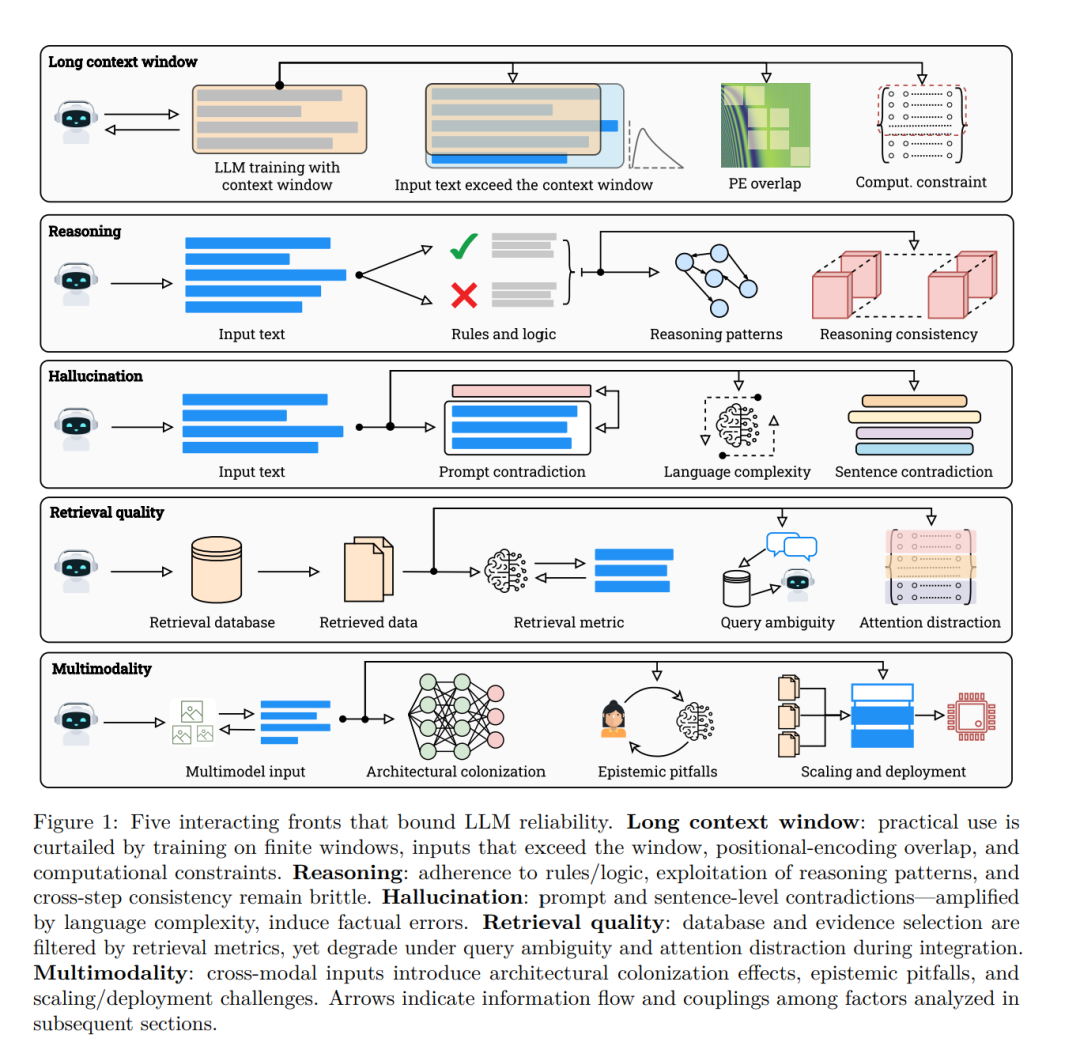
大规模语言模型(LLM)虽因规模扩展获益显著,但这些收益受限于五大根本性局限:(1)幻觉现象;(2)上下文压缩;(3)推理能力退化;(4)检索脆弱性;(5)多模态失准。现有研究虽从实证角度描述了这些现象,却缺乏将之与计算、信息及学习理论的基本限制相联系的严谨理论框架。本文通过提出一个基于证明的统一分析框架,构建了LLM规模扩展的固有理论天花板,填补了这一空白。 首先,可计算性与不可计算性决定了误差的不可消除性:对于任何可计算枚举的模型族,对角线法则必然构造出使某些模型失效的输入;而不可判定问题(如停机判定类任务)会导致所有可计算预测器产生无限失效集。其次,信息论与统计学约束即使在可判定任务上也限制了可达精度——有限描述长度必然引发压缩误差,长尾事实知识则需付出难以承受的样本复杂度。第三,几何与计算效应会显著压缩上下文长度:位置编码训练不足、表征衰减及Softmax拥挤效应共同导致有效上下文远低于名义长度。 我们进一步论证:基于似然训练的机制偏向模式补全而非逻辑推理;令牌限制下的检索会受语义漂移与耦合噪声干扰;多模态扩展仅能实现浅层跨模态对齐。通过结合定理推演与实证证据,我们系统划定了规模扩展的有效区、饱和区与不可突破区,并提出可行改进路径:包括有界预言检索、位置编码课程学习、稀疏注意力与层次化注意力等协同方案。
1 引言
过去五年间,大规模语言模型在规模与影响力上经历了前所未有的爆发式增长。模型参数量、训练数据集和算力预算均呈数量级提升,催生出的模型其涌现能力日益趋近通用推理系统。例如,OpenAI的GPT系列从GPT-1的1.17亿参数,发展到GPT-4的逾万亿参数,表征能力提升逾千倍。实证缩放定律表明,训练损失与下游性能随模型规模、数据量和算力增加而可预测地提升。以从GPT-3.5到GPT-4的转变为例,其在MMLU上的表现提升了16个百分点,在GSM-8K上更是跃升了35个百分点。这些成功催生了一种普遍信念,即规模本身能够无限扩展智能,并将所有失败模式都归结为可通过更多数据、参数或对齐来解决的工程障碍。 然而,随着模型步入万亿参数级别,驱动其成功的进程也暴露出规模所无法克服的根本性局限。更大的模型不仅性能更好,其失败也更为"自信":它们以日益系统化的方式产生幻觉、错误推理、遗忘和失准。即使在庞大数据下,这些痼疾依然存在,暗示着其背后更深层的计算与统计根源。本文认为,这些行为并非优化或数据筛选的暂时性缺陷,而是内在理论壁垒的体现,这些壁垒由可计算性、信息论及可学习性本身所施加。我们归纳了伴随规模扩展而持续存在的五类主要局限: (1)幻觉问题。LLM常生成流畅但虚构的内容。除数据或对齐缺陷外,我们证明幻觉具有必然性:对可枚举模型类的对角线化构造确保了每个模型至少存在一个失败输入;诸如停机问题等不可计算性问题会引发无限失败集;有限信息容量与压缩边界迫使模型对复杂或稀有事实产生失真。因此,任何可计算的LLM都无法在开放域查询中保持普适正确性。 (2)上下文压缩。即便拥有128K令牌的上下文窗口,位置编码训练不足、表征饱和及Softmax拥挤效应共同限制了有效上下文利用率,使其远低于名义容量。稀有位置的梯度衰减、正弦/RoPE编码的信号重叠消失,以及对数形式的分数边际增长,均表明有效上下文长度随名义长度呈次线性缩放。 (3)推理能力退化。尽管表面流畅,LLM更倾向于关联补全而非真值推理。基于似然的训练奖励局部连贯性而非逻辑蕴涵,导致产生句法而非语义的泛化。令牌级优化目标与显式推理损失的缺失,共同导致了分布外情境下系统性的"推理崩溃"。 (4)检索脆弱性。检索增强模型继承了理论脆弱性:有限的令牌预算引发语义漂移、排序噪声及检索文本与生成文本间的弱耦合。从信息论视角,随着检索广度增加,其与目标之间的互信息会衰减,从而为事实锚定设定了上限。 (5)多模态失准。视觉-语言联合模型存在跨模态不平衡:语言通道主导梯度,而视觉特征适应不足。不同的模态熵及未对齐的潜空间流形会导致感知错觉与符号混淆,表明多模态缩放放大了而非消除了单模态的脆弱性。 纵观这些维度,我们揭示了一个统一原理:LLM的失败随其能力而扩展,因为它们根植于语言建模本身的理论基础。每种失败模式都反映了同一底层三重限制的投射:计算不可判定性、统计样本不足及有限信息容量。尽管已有大量实证记录,先前综述仍停留在描述性层面,缺乏将这些观察与计算及学习的数学基础相联系的正式综合。我们通过一个基于证明的框架填补了这一空白,该框架推导出一系列不可行性与饱和性结果,共同刻画了规模扩展何时有效、何时饱和以及何时被证明无法推进。具体而言,我们证明了受可计算性与对角线化限制,不存在一个可枚举的模型类能够完全避免幻觉;我们也证明了有限描述长度与样本复杂度导致了不可约减的泛化误差,反映了可学习性的信息论边界;最后,我们还证明了上下文、推理、检索及多模态锚定各自遵循由架构约束与数据熵决定的可识别退化规律。 这些成果共同将规模扩展重新界定为一个受内在计算与认知约束限制的过程,而非一个无界的工程问题。本文余下部分将系统性地形式化每一局限:第2节证明幻觉的必然性;第3节推导长上下文压缩定律;第4节分析推理与复述的对立;第5节剖析检索脆弱性;第6节将论证延伸至多模态模型;第7节指出现有评估基准的局限性;第8节综合这些发现,界定在哪些领域进一步的参数、数据或模态扩展将不再带来有意义的进展;最后,第9节总结论文核心要素并展望未来研究方向。
