

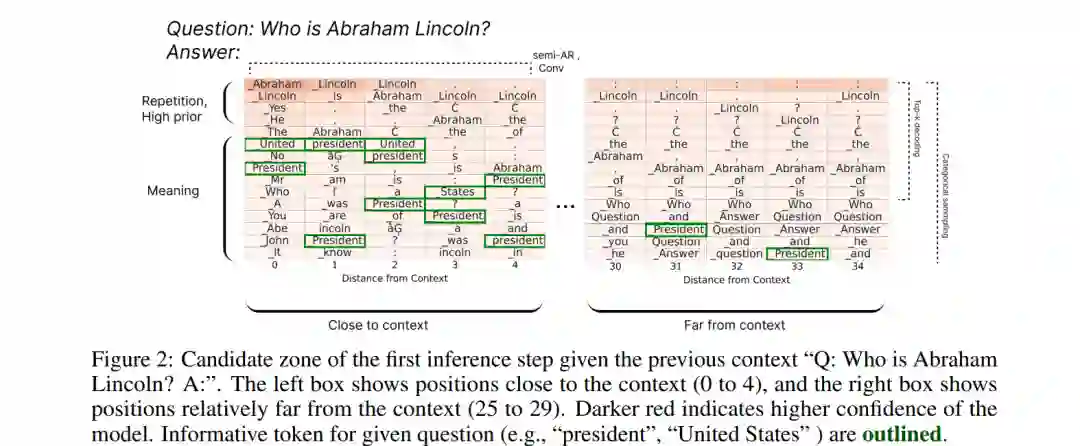
自回归(Autoregressive, AR)语言模型以逐 token 的方式生成文本,这限制了其推理速度。扩散式语言模型(Diffusion-based LMs)提供了一种有前景的替代方案,因为它们可以并行解码多个 token。然而,我们发现现有扩散语言模型存在一个关键瓶颈:长解码窗口问题,即生成位置远离输入上下文的 token 往往变得无关或重复。以往的解决方案(如半自回归方法)通过将窗口划分为块来缓解该问题,但这会牺牲速度与双向性,从而削弱扩散模型的主要优势。 为解决这一问题,我们提出了卷积解码(Convolutional decoding, Conv),这是一种基于归一化的方法,可在无需硬性分段的情况下缩小解码窗口,从而提升流畅性与灵活性。此外,我们引入了拒斥规则微调(Rejecting Rule-based Fine-Tuning, R2FT),这是一种后处理训练机制,能够更好地对齐远离上下文位置的 token。 在开放式生成基准(如 AlpacaEval)上的实验结果表明,我们的方法在扩散语言模型的基线中取得了最新最优性能,并显著减少了步长,相较于以往工作同时实现了速度与质量的提升。代码已在 GitHub 上公开。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日