成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
强化学习
关注
5436
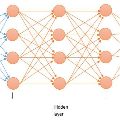
强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。 强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。 该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。
综合
百科
荟萃
VIP
热门
动态
论文
精华
【博士论文】受脑启发的规划:提升强化学习泛化能力
专知会员服务
14+阅读 · 11月13日
《基于强化学习、动态规划与列生成的大规模优化方法》MIT 博士论文
专知会员服务
30+阅读 · 11月8日
基于强化学习的智能体化搜索全面综述:基础、角色、优化、评估与应用
专知会员服务
21+阅读 · 10月22日
用于强化学习的扩散模型:基础、分类与发展
专知会员服务
23+阅读 · 10月15日
【NeurIPS2025】熵正则化与分布强化学习的收敛定理
专知会员服务
12+阅读 · 10月12日
【博士论文】面向排序与扩散模型的安全、高效与鲁棒强化学习
专知会员服务
13+阅读 · 10月6日
【NTU博士论文】利用强化学习与生成模型推动可靠且具备泛化能力的决策
专知会员服务
19+阅读 · 10月2日
强化学习遇见大语言模型:贯穿 LLM 生命周期的进展与应用综述
专知会员服务
37+阅读 · 9月23日
【NTU博士论文】利用强化学习与生成模型推进可靠且可泛化的决策
专知会员服务
23+阅读 · 9月22日
面向深度研究系统的强化学习基础:综述
专知会员服务
22+阅读 · 9月22日
《超视距空战强化学习智能体的深度学习表征能力评估》最新70页
专知会员服务
26+阅读 · 9月19日
面向大型推理模型的强化学习综述
专知会员服务
28+阅读 · 9月11日
深度研究系统的强化学习基础:综述
专知会员服务
29+阅读 · 9月10日
面向大语言模型的智能体化强化学习图景:综述
专知会员服务
50+阅读 · 9月3日
【CMU博士论文】以人为中心的强化学习
专知会员服务
21+阅读 · 8月16日
参考链接
维基百科
父主题
机器学习
数据挖掘
子主题
马尔可夫决策过程
UNREAL(DRL算法)
深度强化学习
预期回报
人工智能游戏
图强化学习
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top