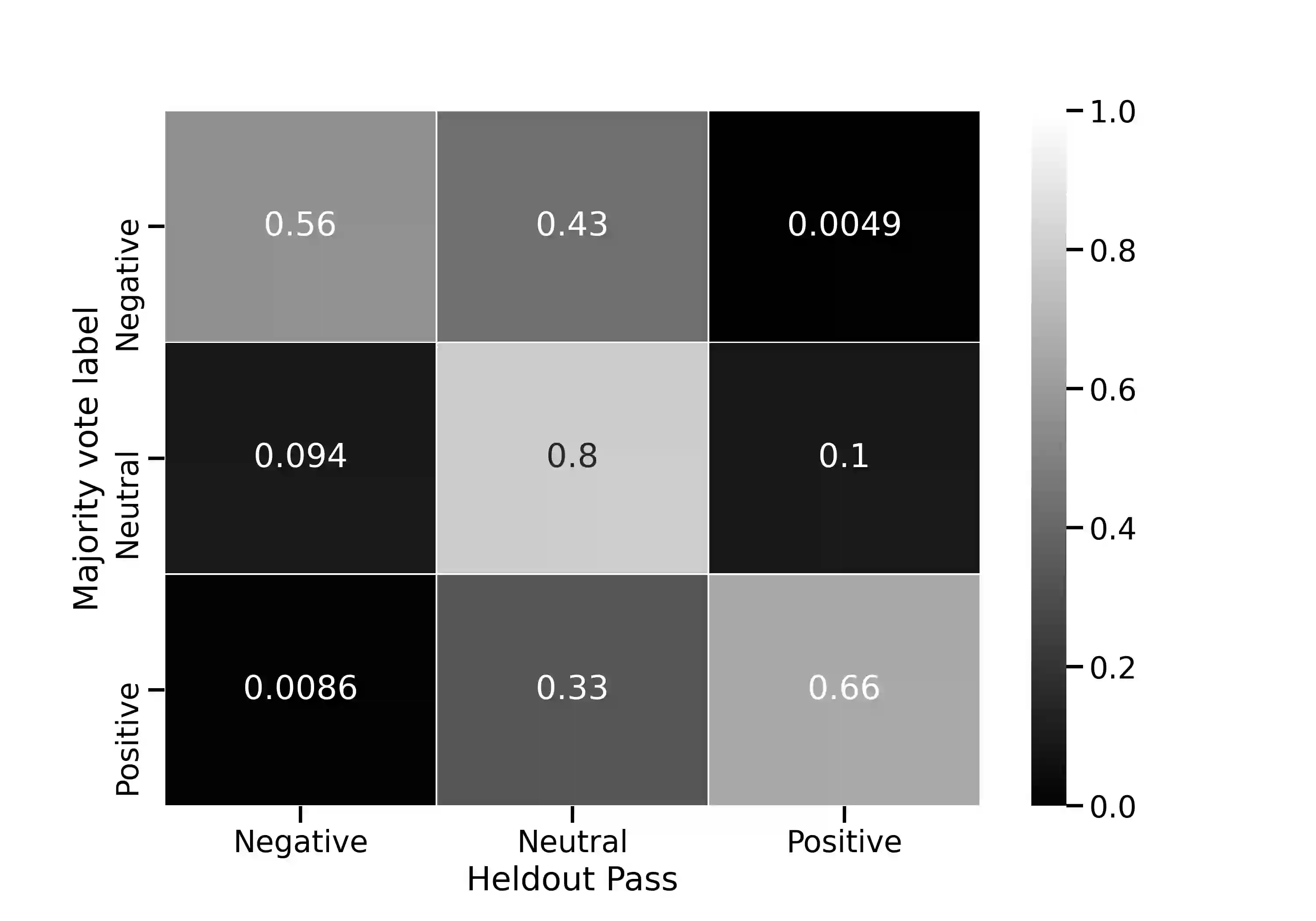
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
翻译:语音处理的进展得到共享数据集和基准的促进,历史上,这些都侧重于自动语音识别(ASR)、语音识别或其他较低层次的任务。对高层次口语理解任务的兴趣不断增加,包括使用端到端模式,但用于此类任务的附加说明的数据集较少。与此同时,最近的工作表明有可能采用相对较少的标签数据,对一些任务进行预培训通用代表,然后进行微调。我们提议为口语理解评价(SLUE)建立一套基准任务,包括有限规模的标签培训组和相应的评价组。这一资源将使研究界能够跟踪进展情况,评价经过预先培训的更高层次任务的表述,并研究诸如管道与端到端方法的效用等未决问题。我们介绍SLUE基准套件的第一阶段,其中包括名称实体识别、情绪分析以及对应数据集的ASR。我们侧重于自然制作的(不阅读或综合)语言理解演讲,以及可自由获取的新数据集。我们为Vox-Celex基准和基准和工具包结果的子集,我们提供了对Vox-Creas基准和基准和基准和基准结果进行新的评估。